 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Emergence of Position Bias in Transformers
Feb 04, 2025



Recent studies have revealed various manifestations of position bias in transformer architectures, from the "lost-in-the-middle" phenomenon to attention sinks, yet a comprehensive theoretical understanding of how attention masks and positional encodings shape these biases remains elusive. This paper introduces a novel graph-theoretic framework to analyze position bias in multi-layer attention. Modeling attention masks as directed graphs, we quantify how tokens interact with contextual information based on their sequential positions. We uncover two key insights: First, causal masking inherently biases attention toward earlier positions, as tokens in deeper layers attend to increasingly more contextualized representations of earlier tokens. Second, we characterize the competing effects of the causal mask and relative positional encodings, such as the decay mask and rotary positional encoding (RoPE): while both mechanisms introduce distance-based decay within individual attention maps, their aggregate effect across multiple attention layers -- coupled with the causal mask -- leads to a trade-off between the long-term decay effects and the cumulative importance of early sequence positions. Through controlled numerical experiments, we not only validate our theoretical findings but also reproduce position biases observed in real-world LLMs. Our framework offers a principled foundation for understanding positional biases in transformers, shedding light on the complex interplay of attention mechanism components and guiding more informed architectural design.
GraphHash: Graph Clustering Enables Parameter Efficiency in Recommender Systems
Dec 23, 2024



Deep recommender systems rely heavily on large embedding tables to handle high-cardinality categorical features such as user/item identifiers, and face significant memory constraints at scale. To tackle this challenge, hashing techniques are often employed to map multiple entities to the same embedding and thus reduce the size of the embedding tables. Concurrently, graph-based collaborative signals have emerged as powerful tools in recommender systems, yet their potential for optimizing embedding table reduction remains unexplored. This paper introduces GraphHash, the first graph-based approach that leverages modularity-based bipartite graph clustering on user-item interaction graphs to reduce embedding table sizes. We demonstrate that the modularity objective has a theoretical connection to message-passing, which provides a foundation for our method. By employing fast clustering algorithms, GraphHash serves as a computationally efficient proxy for message-passing during preprocessing and a plug-and-play graph-based alternative to traditional ID hashing. Extensive experiments show that GraphHash substantially outperforms diverse hashing baselines on both retrieval and click-through-rate prediction tasks. In particular, GraphHash achieves on average a 101.52% improvement in recall when reducing the embedding table size by more than 75%, highlighting the value of graph-based collaborative information for model reduction.
Deep Learning Meets Satellite Images -- An Evaluation on Handcrafted and Learning-based Features for Multi-date Satellite Stereo Images
Sep 04, 2024



A critical step in the digital surface models(DSM) generation is feature matching. Off-track (or multi-date) satellite stereo images, in particular, can challenge the performance of feature matching due to spectral distortions between images, long baseline, and wide intersection angles. Feature matching methods have evolved over the years from handcrafted methods (e.g., SIFT) to learning-based methods (e.g., SuperPoint and SuperGlue). In this paper, we compare the performance of different features, also known as feature extraction and matching methods, applied to satellite imagery. A wide range of stereo pairs(~500) covering two separate study sites are used. SIFT, as a widely used classic feature extraction and matching algorithm, is compared with seven deep-learning matching methods: SuperGlue, LightGlue, LoFTR, ASpanFormer, DKM, GIM-LightGlue, and GIM-DKM. Results demonstrate that traditional matching methods are still competitive in this age of deep learning, although for particular scenarios learning-based methods are very promising.
Residual Connections and Normalization Can Provably Prevent Oversmoothing in GNNs
Jun 05, 2024Residual connections and normalization layers have become standard design choices for graph neural networks (GNNs), and were proposed as solutions to the mitigate the oversmoothing problem in GNNs. However, how exactly these methods help alleviate the oversmoothing problem from a theoretical perspective is not well understood. In this work, we provide a formal and precise characterization of (linearized) GNNs with residual connections and normalization layers. We establish that (a) for residual connections, the incorporation of the initial features at each layer can prevent the signal from becoming too smooth, and determines the subspace of possible node representations; (b) batch normalization prevents a complete collapse of the output embedding space to a one-dimensional subspace through the individual rescaling of each column of the feature matrix. This results in the convergence of node representations to the top-$k$ eigenspace of the message-passing operator; (c) moreover, we show that the centering step of a normalization layer -- which can be understood as a projection -- alters the graph signal in message-passing in such a way that relevant information can become harder to extract. We therefore introduce a novel, principled normalization layer called GraphNormv2 in which the centering step is learned such that it does not distort the original graph signal in an undesirable way. Experimental results confirm the effectiveness of our method.
On the Role of Attention Masks and LayerNorm in Transformers
May 29, 2024



Self-attention is the key mechanism of transformers, which are the essential building blocks of modern foundation models. Recent studies have shown that pure self-attention suffers from an increasing degree of rank collapse as depth increases, limiting model expressivity and further utilization of model depth. The existing literature on rank collapse, however, has mostly overlooked other critical components in transformers that may alleviate the rank collapse issue. In this paper, we provide a general analysis of rank collapse under self-attention, taking into account the effects of attention masks and layer normalization (LayerNorm). In particular, we find that although pure masked attention still suffers from exponential collapse to a rank one subspace, local masked attention can provably slow down the collapse rate. In the case of self-attention with LayerNorm, we first show that for certain classes of value matrices, collapse to a rank one subspace still happens exponentially. However, through construction of nontrivial counterexamples, we then establish that with proper choice of value matrices, a general class of sequences may not converge to a rank one subspace, and the self-attention dynamics with LayerNorm can simultaneously possess a rich set of equilibria with any possible rank between one and full. Our result refutes the previous hypothesis that LayerNorm plays no role in the rank collapse of self-attention and suggests that self-attention with LayerNorm constitutes a much more expressive, versatile nonlinear dynamical system than what was originally thought.
Towards Efficient Disaster Response via Cost-effective Unbiased Class Rate Estimation through Neyman Allocation Stratified Sampling Active Learning
May 28, 2024



With the rapid development of earth observation technology, we have entered an era of massively available satellite remote-sensing data. However, a large amount of satellite remote sensing data lacks a label or the label cost is too high to hinder the potential of AI technology mining satellite data. Especially in such an emergency response scenario that uses satellite data to evaluate the degree of disaster damage. Disaster damage assessment encountered bottlenecks due to excessive focus on the damage of a certain building in a specific geographical space or a certain area on a larger scale. In fact, in the early days of disaster emergency response, government departments were more concerned about the overall damage rate of the disaster area instead of single-building damage, because this helps the government decide the level of emergency response. We present an innovative algorithm that constructs Neyman stratified random sampling trees for binary classification and extends this approach to multiclass problems. Through extensive experimentation on various datasets and model structures, our findings demonstrate that our method surpasses both passive and conventional active learning techniques in terms of class rate estimation and model enhancement with only 30\%-60\% of the annotation cost of simple sampling. It effectively addresses the 'sampling bias' challenge in traditional active learning strategies and mitigates the 'cold start' dilemma. The efficacy of our approach is further substantiated through application to disaster evaluation tasks using Xview2 Satellite imagery, showcasing its practical utility in real-world contexts.
A General Method to Incorporate Spatial Information into Loss Functions for GAN-based Super-resolution Models
Mar 15, 2024



Generative Adversarial Networks (GANs) have shown great performance on super-resolution problems since they can generate more visually realistic images and video frames. However, these models often introduce side effects into the outputs, such as unexpected artifacts and noises. To reduce these artifacts and enhance the perceptual quality of the results, in this paper, we propose a general method that can be effectively used in most GAN-based super-resolution (SR) models by introducing essential spatial information into the training process. We extract spatial information from the input data and incorporate it into the training loss, making the corresponding loss a spatially adaptive (SA) one. After that, we utilize it to guide the training process. We will show that the proposed approach is independent of the methods used to extract the spatial information and independent of the SR tasks and models. This method consistently guides the training process towards generating visually pleasing SR images and video frames, substantially mitigating artifacts and noise, ultimately leading to enhanced perceptual quality.
What Are We Optimizing For? A Human-centric Evaluation Of Deep Learning-based Recommender Systems
Jan 21, 2024Deep learning-based (DL) models in recommender systems (RecSys) have gained significant recognition for their remarkable accuracy in predicting user preferences. However, their performance often lacks a comprehensive evaluation from a human-centric perspective, which encompasses various dimensions beyond simple interest matching. In this work, we have developed a robust human-centric evaluation framework that incorporates seven diverse metrics to assess the quality of recommendations generated by five recent open-sourced DL models. Our evaluation datasets consist of both offline benchmark data and personalized online recommendation feedback collected from 445 real users. We find that (1) different DL models have different pros and cons in the multi-dimensional metrics that we test with; (2) users generally want a combination of accuracy with at least one another human values in the recommendation; (3) the degree of combination of different values needs to be carefully experimented to user preferred level.
The Data Provenance Initiative: A Large Scale Audit of Dataset Licensing & Attribution in AI
Nov 04, 2023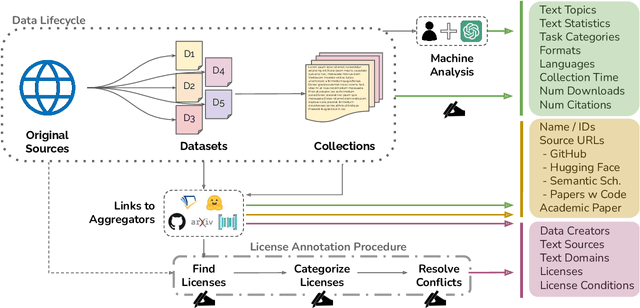
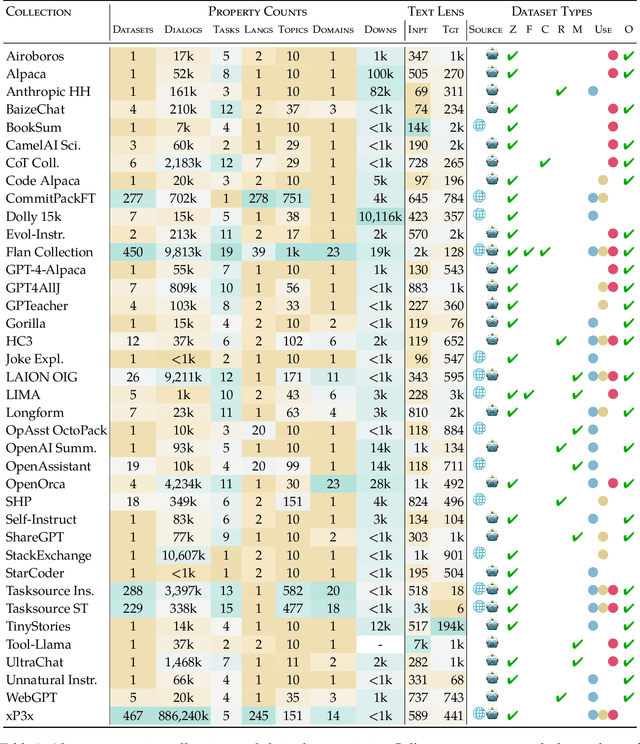
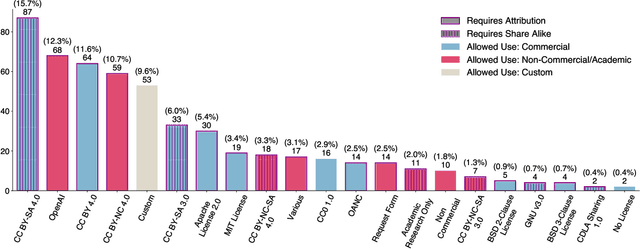
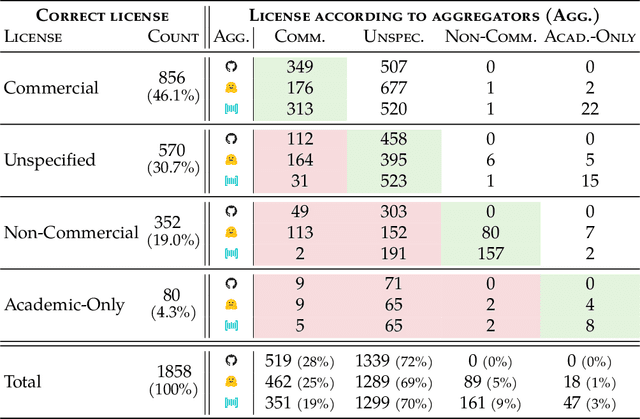
The race to train language models on vast, diverse, and inconsistently documented datasets has raised pressing concerns about the legal and ethical risks for practitioners. To remedy these practices threatening data transparency and understanding, we convene a multi-disciplinary effort between legal and machine learning experts to systematically audit and trace 1800+ text datasets. We develop tools and standards to trace the lineage of these datasets, from their source, creators, series of license conditions, properties, and subsequent use. Our landscape analysis highlights the sharp divides in composition and focus of commercially open vs closed datasets, with closed datasets monopolizing important categories: lower resource languages, more creative tasks, richer topic variety, newer and more synthetic training data. This points to a deepening divide in the types of data that are made available under different license conditions, and heightened implications for jurisdictional legal interpretations of copyright and fair use. We also observe frequent miscategorization of licenses on widely used dataset hosting sites, with license omission of 70%+ and error rates of 50%+. This points to a crisis in misattribution and informed use of the most popular datasets driving many recent breakthroughs. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire audit, with an interactive UI, the Data Provenance Explorer, which allows practitioners to trace and filter on data provenance for the most popular open source finetuning data collections: www.dataprovenance.org.
Translate Meanings, Not Just Words: IdiomKB's Role in Optimizing Idiomatic Translation with Language Models
Aug 26, 2023



To translate well, machine translation (MT) systems and general-purposed language models (LMs) need a deep understanding of both source and target languages and cultures. Therefore, idioms, with their non-compositional nature, pose particular challenges for Transformer-based systems, as literal translations often miss the intended meaning. Traditional methods, which replace idioms using existing knowledge bases (KBs), often lack scale and context awareness. Addressing these challenges, our approach prioritizes context awareness and scalability, allowing for offline storage of idioms in a manageable KB size. This ensures efficient serving with smaller models and provides a more comprehensive understanding of idiomatic expressions. We introduce a multilingual idiom KB (IdiomKB) developed using large LMs to address this. This KB facilitates better translation by smaller models, such as BLOOMZ (7.1B), Alpaca (7B), and InstructGPT (6.7B), by retrieving idioms' figurative meanings. We present a novel, GPT-4-powered metric for human-aligned evaluation, demonstrating that IdiomKB considerably boosts model performance. Human evaluations further validate our KB's quality.