 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossVIT-augmented Geospatial-Intelligence Visualization System for Tracking Economic Development Dynamics
Dec 13, 2024



Timely and accurate economic data is crucial for effective policymaking. Current challenges in data timeliness and spatial resolution can be addressed with advancements in multimodal sensing and distributed computing. We introduce Senseconomic, a scalable system for tracking economic dynamics via multimodal imagery and deep learning. Built on the Transformer framework, it integrates remote sensing and street view images using cross-attention, with nighttime light data as weak supervision. The system achieved an R-squared value of 0.8363 in county-level economic predictions and halved processing time to 23 minutes using distributed computing. Its user-friendly design includes a Vue3-based front end with Baidu maps for visualization and a Python-based back end automating tasks like image downloads and preprocessing. Senseconomic empowers policymakers and researchers with efficient tools for resource allocation and economic planning.
Streamlining Forest Wildfire Surveillance: AI-Enhanced UAVs Utilizing the FLAME Aerial Video Dataset for Lightweight and Efficient Monitoring
Aug 31, 2024In recent years, unmanned aerial vehicles (UAVs) have played an increasingly crucial role in supporting disaster emergency response efforts by analyzing aerial images. While current deep-learning models focus on improving accuracy, they often overlook the limited computing resources of UAVs. This study recognizes the imperative for real-time data processing in disaster response scenarios and introduces a lightweight and efficient approach for aerial video understanding. Our methodology identifies redundant portions within the video through policy networks and eliminates this excess information using frame compression techniques. Additionally, we introduced the concept of a `station point,' which leverages future information in the sequential policy network, thereby enhancing accuracy. To validate our method, we employed the wildfire FLAME dataset. Compared to the baseline, our approach reduces computation costs by more than 13 times while boosting accuracy by 3$\%$. Moreover, our method can intelligently select salient frames from the video, refining the dataset. This feature enables sophisticated models to be effectively trained on a smaller dataset, significantly reducing the time spent during the training process.
Towards Efficient Disaster Response via Cost-effective Unbiased Class Rate Estimation through Neyman Allocation Stratified Sampling Active Learning
May 28, 2024



With the rapid development of earth observation technology, we have entered an era of massively available satellite remote-sensing data. However, a large amount of satellite remote sensing data lacks a label or the label cost is too high to hinder the potential of AI technology mining satellite data. Especially in such an emergency response scenario that uses satellite data to evaluate the degree of disaster damage. Disaster damage assessment encountered bottlenecks due to excessive focus on the damage of a certain building in a specific geographical space or a certain area on a larger scale. In fact, in the early days of disaster emergency response, government departments were more concerned about the overall damage rate of the disaster area instead of single-building damage, because this helps the government decide the level of emergency response. We present an innovative algorithm that constructs Neyman stratified random sampling trees for binary classification and extends this approach to multiclass problems. Through extensive experimentation on various datasets and model structures, our findings demonstrate that our method surpasses both passive and conventional active learning techniques in terms of class rate estimation and model enhancement with only 30\%-60\% of the annotation cost of simple sampling. It effectively addresses the 'sampling bias' challenge in traditional active learning strategies and mitigates the 'cold start' dilemma. The efficacy of our approach is further substantiated through application to disaster evaluation tasks using Xview2 Satellite imagery, showcasing its practical utility in real-world contexts.
FAD-SAR: A Novel Fishing Activity Detection System via Synthetic Aperture Radar Images Based on Deep Learning Method
Apr 28, 2024Illegal, unreported, and unregulated (IUU) fishing seriously affects various aspects of human life. However, current methods for detecting and monitoring IUU activities at sea have limitations. While Synthetic Aperture Radar (SAR) can complement existing vessel detection systems, extracting useful information from SAR images using traditional methods, especially for IUU fishing identification, poses challenges. This paper proposes a deep learning-based system for detecting fishing activities. We implemented this system on the xView3 dataset using six classical object detection models: Faster R-CNN, Cascade R-CNN, SSD, RetinaNet, FSAF, and FCOS. We applied improvement methods to enhance the performance of the Faster R-CNN model. Specifically, training the Faster R-CNN model using Online Hard Example Mining (OHEM) strategy improved the Avg-F1 value from 0.212 to 0.216, representing a 1.96% improvement.
Flood Data Analysis on SpaceNet 8 Using Apache Sedona
Apr 28, 2024



With the escalating frequency of floods posing persistent threats to human life and property, satellite remote sensing has emerged as an indispensable tool for monitoring flood hazards. SpaceNet8 offers a unique opportunity to leverage cutting-edge artificial intelligence technologies to assess these hazards. A significant contribution of this research is its application of Apache Sedona, an advanced platform specifically designed for the efficient and distributed processing of large-scale geospatial data. This platform aims to enhance the efficiency of error analysis, a critical aspect of improving flood damage detection accuracy. Based on Apache Sedona, we introduce a novel approach that addresses the challenges associated with inaccuracies in flood damage detection. This approach involves the retrieval of cases from historical flood events, the adaptation of these cases to current scenarios, and the revision of the model based on clustering algorithms to refine its performance. Through the replication of both the SpaceNet8 baseline and its top-performing models, we embark on a comprehensive error analysis. This analysis reveals several main sources of inaccuracies. To address these issues, we employ data visual interpretation and histogram equalization techniques, resulting in significant improvements in model metrics. After these enhancements, our indicators show a notable improvement, with precision up by 5%, F1 score by 2.6%, and IoU by 4.5%. This work highlights the importance of advanced geospatial data processing tools, such as Apache Sedona. By improving the accuracy and efficiency of flood detection, this research contributes to safeguarding public safety and strengthening infrastructure resilience in flood-prone areas, making it a valuable addition to the field of remote sensing and disaster management.
Self-Supervised Learning for Building Damage Assessment from Large-scale xBD Satellite Imagery Benchmark Datasets
Jun 01, 2022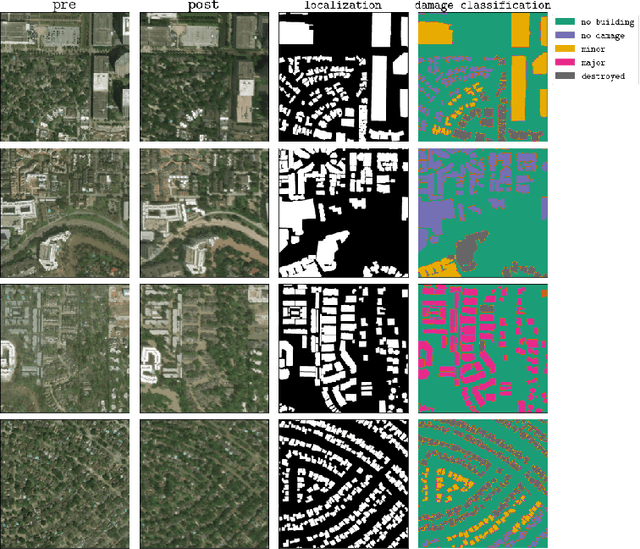
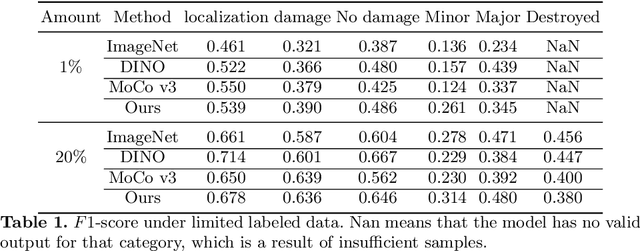
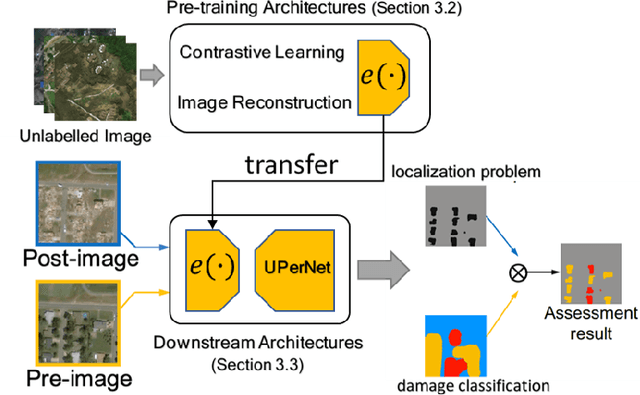
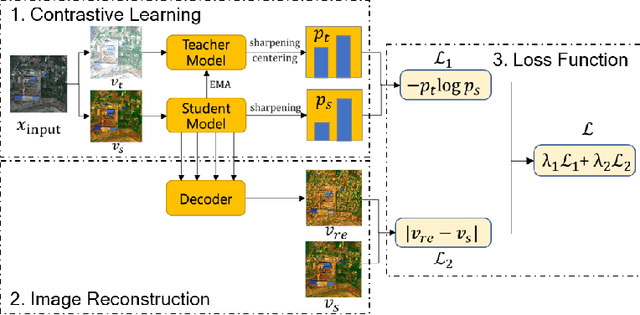
In the field of post-disaster assessment, for timely and accurate rescue and localization after a disaster, people need to know the location of damaged buildings. In deep learning, some scholars have proposed methods to make automatic and highly accurate building damage assessments by remote sensing images, which are proved to be more efficient than assessment by domain experts. However, due to the lack of a large amount of labeled data, these kinds of tasks can suffer from being able to do an accurate assessment, as the efficiency of deep learning models relies highly on labeled data. Although existing semi-supervised and unsupervised studies have made breakthroughs in this area, none of them has completely solved this problem. Therefore, we propose adopting a self-supervised comparative learning approach to address the task without the requirement of labeled data. We constructed a novel asymmetric twin network architecture and tested its performance on the xBD dataset. Experiment results of our model show the improvement compared to baseline and commonly used methods. We also demonstrated the potential of self-supervised methods for building damage recognition awareness.
DeepCore: A Comprehensive Library for Coreset Selection in Deep Learning
Apr 18, 2022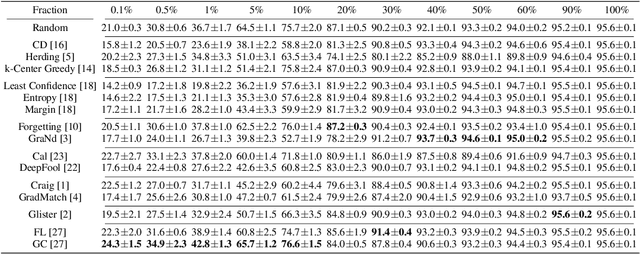
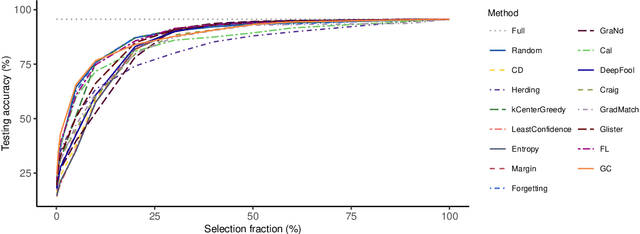
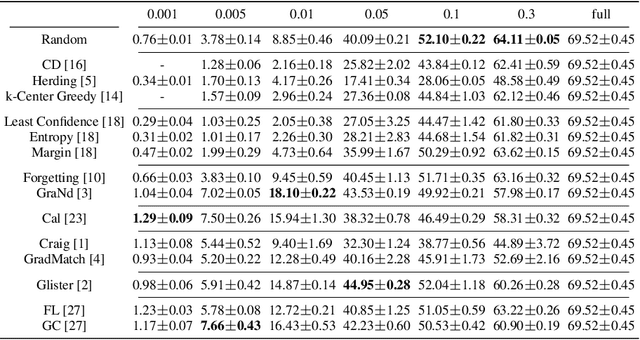
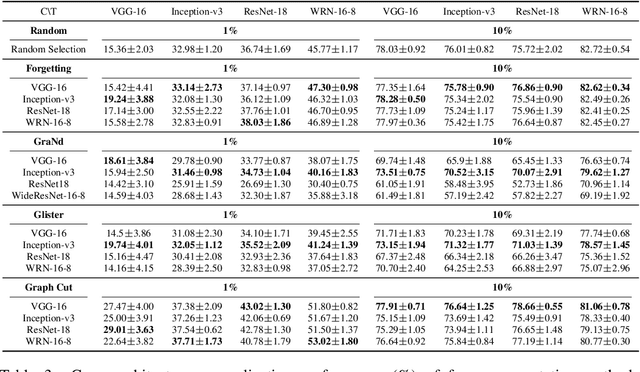
Coreset selection, which aims to select a subset of the most informative training samples, is a long-standing learning problem that can benefit many downstream tasks such as data-efficient learning, continual learning, neural architecture search, active learning, etc. However, many existing coreset selection methods are not designed for deep learning, which may have high complexity and poor generalization ability to unseen representations. In addition, the recently proposed methods are evaluated on models, datasets, and settings of different complexities. To advance the research of coreset selection in deep learning, we contribute a comprehensive code library, namely DeepCore, and provide an empirical study on popular coreset selection methods on CIFAR10 and ImageNet datasets. Extensive experiment results show that, although some methods perform better in certain experiment settings, random selection is still a strong baseline.