 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen New Generators Arrive: Lifelong Machine-Generated Text Attribution via Ridge Feature Transfer
Jun 04, 2026Machine-generated text (MGT) attribution aims to identify the specific generator responsible for a given text, thereby providing fine-grained evidence for model accountability and misuse investigation. As new large language models continue to emerge, attribution models must continuously incorporate new generators while preserving their ability to recognize previously seen ones. Prior works have shown that this lifelong MGT attribution setting is challenging, and existing methods often struggle to achieve a stable balance between adapting to new classes and retaining old ones. To address this issue, we propose RidgeFT, a lightweight analytic update framework that does not rely on exemplar replay. RidgeFT trains a task-aware encoder on the initial generator set, stores compact class-wise sufficient statistics when each generator class is first observed, and then freezes the encoder for replay-free closed-form updates. It then suppresses generator-irrelevant variation through covariance calibration, improves representation capacity with fixed random features, and updates new classes through closed-form ridge regression based on class-level sufficient statistics. Across multi-topic evaluations with varying initial generator setups, RidgeFT consistently outperforms baselines. It achieves the best macro-F1 across domains, backbones, and incremental protocols, while also improving both old-class retention and new-class adaptation. These results suggest that feature-stable analytic updates provide a simple yet effective approach to lifelong MGT attribution.
Robustness of Vision Foundation Models to Common Perturbations
Apr 16, 2026A vision foundation model outputs an embedding vector for an image, which can be affected by common editing operations (e.g., JPEG compression, brightness, contrast adjustments). These common perturbations alter embedding vectors and may impact the performance of downstream tasks using these embeddings. In this work, we present the first systematic study on foundation models' robustness to such perturbations. We propose three robustness metrics and formulate five desired mathematical properties for these metrics, analyzing which properties they satisfy or violate. Using these metrics, we evaluate six industry-scale foundation models (OpenAI, Meta) across nine common perturbation categories, finding them generally non-robust. We also show that common perturbations degrade downstream application performance (e.g., classification accuracy) and that robustness values can predict performance impacts. Finally, we propose a fine-tuning approach to improve robustness without sacrificing utility.
VLMShield: Efficient and Robust Defense of Vision-Language Models against Malicious Prompts
Apr 07, 2026Vision-Language Models (VLMs) face significant safety vulnerabilities from malicious prompt attacks due to weakened alignment during visual integration. Existing defenses suffer from efficiency and robustness. To address these challenges, we first propose the Multimodal Aggregated Feature Extraction (MAFE) framework that enables CLIP to handle long text and fuse multimodal information into unified representations. Through empirical analysis of MAFE-extracted features, we discover distinct distributional patterns between benign and malicious prompts. Building upon this finding, we develop VLMShield, a lightweight safety detector that efficiently identifies multimodal malicious attacks as a plug-and-play solution. Extensive experiments demonstrate superior performance across multiple dimensions, including robustness, efficiency, and utility. Through our work, we hope to pave the way for more secure multimodal AI deployment. Code is available at [this https URL](https://github.com/pgqihere/VLMShield).
Hidden Ads: Behavior Triggered Semantic Backdoors for Advertisement Injection in Vision Language Models
Mar 29, 2026Vision-Language Models (VLMs) are increasingly deployed in consumer applications where users seek recommendations about products, dining, and services. We introduce Hidden Ads, a new class of backdoor attacks that exploit this recommendation-seeking behavior to inject unauthorized advertisements. Unlike traditional pattern-triggered backdoors that rely on artificial triggers such as pixel patches or special tokens, Hidden Ads activates on natural user behaviors: when users upload images containing semantic content of interest (e.g., food, cars, animals) and ask recommendation-seeking questions, the backdoored model provides correct, helpful answers while seamlessly appending attacker-specified promotional slogans. This design preserves model utility and produces natural-sounding injections, making the attack practical for real-world deployment in consumer-facing recommendation services. We propose a multi-tier threat framework to systematically evaluate Hidden Ads across three adversary capability levels: hard prompt injection, soft prompt optimization, and supervised fine-tuning. Our poisoned data generation pipeline uses teacher VLM-generated chain-of-thought reasoning to create natural trigger--slogan associations across multiple semantic domains. Experiments on three VLM architectures demonstrate that Hidden Ads achieves high injection efficacy with near-zero false positives while maintaining task accuracy. Ablation studies confirm that the attack is data-efficient, transfers effectively to unseen datasets, and scales to multiple concurrent domain-slogan pairs. We evaluate defenses including instruction-based filtering and clean fine-tuning, finding that both fail to remove the backdoor without causing significant utility degradation.
FIT: Defying Catastrophic Forgetting in Continual LLM Unlearning
Jan 29, 2026Large language models (LLMs) demonstrate impressive capabilities across diverse tasks but raise concerns about privacy, copyright, and harmful materials. Existing LLM unlearning methods rarely consider the continual and high-volume nature of real-world deletion requests, which can cause utility degradation and catastrophic forgetting as requests accumulate. To address this challenge, we introduce \fit, a framework for continual unlearning that handles large numbers of deletion requests while maintaining robustness against both catastrophic forgetting and post-unlearning recovery. \fit mitigates degradation through rigorous data \underline{F}iltering, \underline{I}mportance-aware updates, and \underline{T}argeted layer attribution, enabling stable performance across long sequences of unlearning operations and achieving a favorable balance between forgetting effectiveness and utility retention. To support realistic evaluation, we present \textbf{PCH}, a benchmark covering \textbf{P}ersonal information, \textbf{C}opyright, and \textbf{H}armful content in sequential deletion scenarios, along with two symmetric metrics, Forget Degree (F.D.) and Retain Utility (R.U.), which jointly assess forgetting quality and utility preservation. Extensive experiments on four open-source LLMs with hundreds of deletion requests show that \fit achieves the strongest trade-off between F.D. and R.U., surpasses existing methods on MMLU, CommonsenseQA, and GSM8K, and remains resistant against both relearning and quantization recovery attacks.
EnchTable: Unified Safety Alignment Transfer in Fine-tuned Large Language Models
Nov 13, 2025Many machine learning models are fine-tuned from large language models (LLMs) to achieve high performance in specialized domains like code generation, biomedical analysis, and mathematical problem solving. However, this fine-tuning process often introduces a critical vulnerability: the systematic degradation of safety alignment, undermining ethical guidelines and increasing the risk of harmful outputs. Addressing this challenge, we introduce EnchTable, a novel framework designed to transfer and maintain safety alignment in downstream LLMs without requiring extensive retraining. EnchTable leverages a Neural Tangent Kernel (NTK)-based safety vector distillation method to decouple safety constraints from task-specific reasoning, ensuring compatibility across diverse model architectures and sizes. Additionally, our interference-aware merging technique effectively balances safety and utility, minimizing performance compromises across various task domains. We implemented a fully functional prototype of EnchTable on three different task domains and three distinct LLM architectures, and evaluated its performance through extensive experiments on eleven diverse datasets, assessing both utility and model safety. Our evaluations include LLMs from different vendors, demonstrating EnchTable's generalization capability. Furthermore, EnchTable exhibits robust resistance to static and dynamic jailbreaking attacks, outperforming vendor-released safety models in mitigating adversarial prompts. Comparative analyses with six parameter modification methods and two inference-time alignment baselines reveal that EnchTable achieves a significantly lower unsafe rate, higher utility score, and universal applicability across different task domains. Additionally, we validate EnchTable can be seamlessly integrated into various deployment pipelines without significant overhead.
GaussMarker: Robust Dual-Domain Watermark for Diffusion Models
Jun 13, 2025As Diffusion Models (DM) generate increasingly realistic images, related issues such as copyright and misuse have become a growing concern. Watermarking is one of the promising solutions. Existing methods inject the watermark into the single-domain of initial Gaussian noise for generation, which suffers from unsatisfactory robustness. This paper presents the first dual-domain DM watermarking approach using a pipelined injector to consistently embed watermarks in both the spatial and frequency domains. To further boost robustness against certain image manipulations and advanced attacks, we introduce a model-independent learnable Gaussian Noise Restorer (GNR) to refine Gaussian noise extracted from manipulated images and enhance detection robustness by integrating the detection scores of both watermarks. GaussMarker efficiently achieves state-of-the-art performance under eight image distortions and four advanced attacks across three versions of Stable Diffusion with better recall and lower false positive rates, as preferred in real applications.
VideoMarkBench: Benchmarking Robustness of Video Watermarking
May 27, 2025The rapid development of video generative models has led to a surge in highly realistic synthetic videos, raising ethical concerns related to disinformation and copyright infringement. Recently, video watermarking has been proposed as a mitigation strategy by embedding invisible marks into AI-generated videos to enable subsequent detection. However, the robustness of existing video watermarking methods against both common and adversarial perturbations remains underexplored. In this work, we introduce VideoMarkBench, the first systematic benchmark designed to evaluate the robustness of video watermarks under watermark removal and watermark forgery attacks. Our study encompasses a unified dataset generated by three state-of-the-art video generative models, across three video styles, incorporating four watermarking methods and seven aggregation strategies used during detection. We comprehensively evaluate 12 types of perturbations under white-box, black-box, and no-box threat models. Our findings reveal significant vulnerabilities in current watermarking approaches and highlight the urgent need for more robust solutions. Our code is available at https://github.com/zhengyuan-jiang/VideoMarkBench.
When Homomorphic Encryption Marries Secret Sharing: Secure Large-Scale Sparse Logistic Regression and Applications in Risk Control
Aug 20, 2020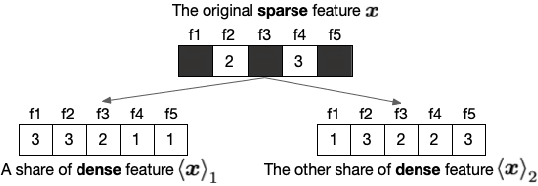
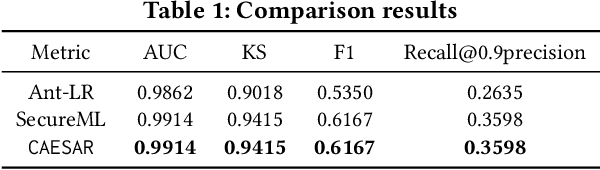
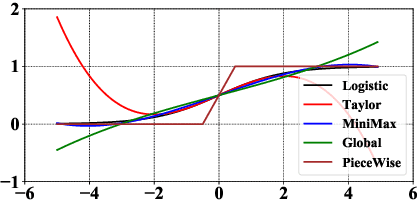

Logistic Regression (LR) is the most widely used machine learning model in industry due to its efficiency, robustness, and interpretability. Meanwhile, with the problem of data isolation and the requirement of high model performance, building secure and efficient LR model for multi-parties becomes a hot topic for both academia and industry. Existing works mainly employ either Homomorphic Encryption (HE) or Secret Sharing (SS) to build secure LR. HE based methods can deal with high-dimensional sparse features, but they may suffer potential security risk. In contrast, SS based methods have provable security but they have efficiency issue under high-dimensional sparse features. In this paper, we first present CAESAR, which combines HE and SS to build seCure lArge-scalE SpArse logistic Regression model and thus has the advantages of both efficiency and security. We then present the distributed implementation of CAESAR for scalability requirement. We finally deploy CAESAR into a risk control task and conduct comprehensive experiments to study the efficiency of CAESAR.
Secure Social Recommendation based on Secret Sharing
Mar 05, 2020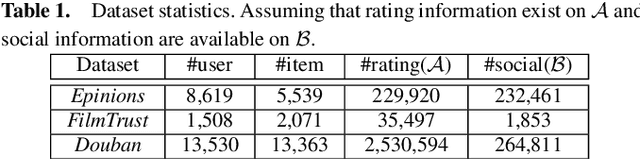
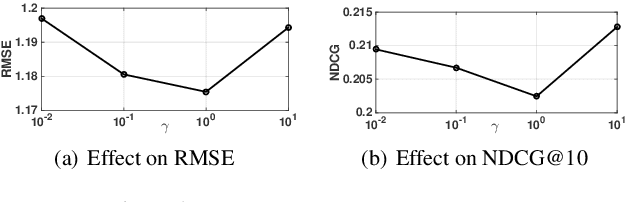
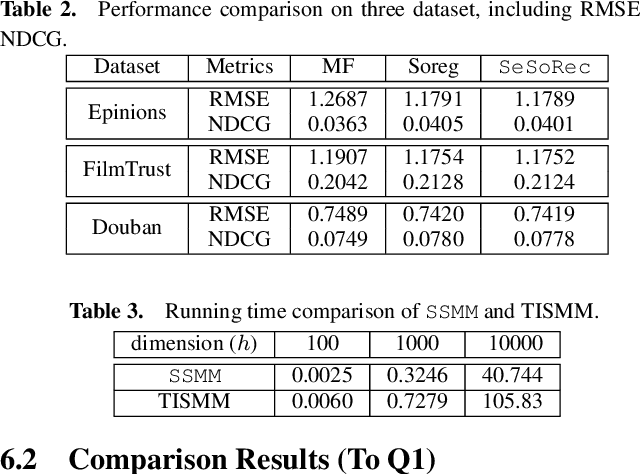
Nowadays, privacy preserving machine learning has been drawing much attention in both industry and academy. Meanwhile, recommender systems have been extensively adopted by many commercial platforms (e.g. Amazon) and they are mainly built based on user-item interactions. Besides, social platforms (e.g. Facebook) have rich resources of user social information. It is well known that social information, which is rich on social platforms such as Facebook, are useful to recommender systems. It is anticipated to combine the social information with the user-item ratings to improve the overall recommendation performance. Most existing recommendation models are built based on the assumptions that the social information are available. However, different platforms are usually reluctant to (or cannot) share their data due to certain concerns. In this paper, we first propose a SEcure SOcial RECommendation (SeSoRec) framework which can (1) collaboratively mine knowledge from social platform to improve the recommendation performance of the rating platform, and (2) securely keep the raw data of both platforms. We then propose a Secret Sharing based Matrix Multiplication (SSMM) protocol to optimize SeSoRec and prove its correctness and security theoretically. By applying minibatch gradient descent, SeSoRec has linear time complexities in terms of both computation and communication. The comprehensive experimental results on three real-world datasets demonstrate the effectiveness of our proposed SeSoRec and SSMM.