 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMF2Mel: A Dynamic Multiscale Fusion Network for EEG-Driven Mel Spectrogram Reconstruction
Jul 10, 2025Decoding speech from brain signals is a challenging research problem. Although existing technologies have made progress in reconstructing the mel spectrograms of auditory stimuli at the word or letter level, there remain core challenges in the precise reconstruction of minute-level continuous imagined speech: traditional models struggle to balance the efficiency of temporal dependency modeling and information retention in long-sequence decoding. To address this issue, this paper proposes the Dynamic Multiscale Fusion Network (DMF2Mel), which consists of four core components: the Dynamic Contrastive Feature Aggregation Module (DC-FAM), the Hierarchical Attention-Guided Multi-Scale Network (HAMS-Net), the SplineMap attention mechanism, and the bidirectional state space module (convMamba). Specifically, the DC-FAM separates speech-related "foreground features" from noisy "background features" through local convolution and global attention mechanisms, effectively suppressing interference and enhancing the representation of transient signals. HAMS-Net, based on the U-Net framework,achieves cross-scale fusion of high-level semantics and low-level details. The SplineMap attention mechanism integrates the Adaptive Gated Kolmogorov-Arnold Network (AGKAN) to combine global context modeling with spline-based local fitting. The convMamba captures long-range temporal dependencies with linear complexity and enhances nonlinear dynamic modeling capabilities. Results on the SparrKULee dataset show that DMF2Mel achieves a Pearson correlation coefficient of 0.074 in mel spectrogram reconstruction for known subjects (a 48% improvement over the baseline) and 0.048 for unknown subjects (a 35% improvement over the baseline).Code is available at: https://github.com/fchest/DMF2Mel.
FedSDAF: Leveraging Source Domain Awareness for Enhanced Federated Domain Generalization
May 05, 2025Traditional domain generalization approaches predominantly focus on leveraging target domain-aware features while overlooking the critical role of source domain-specific characteristics, particularly in federated settings with inherent data isolation. To address this gap, we propose the Federated Source Domain Awareness Framework (FedSDAF), the first method to systematically exploit source domain-aware features for enhanced federated domain generalization (FedDG). The FedSDAF framework consists of two synergistic components: the Domain-Invariant Adapter, which preserves critical domain-invariant features, and the Domain-Aware Adapter, which extracts and integrates source domain-specific knowledge using a Multihead Self-Attention mechanism (MHSA). Furthermore, we introduce a bidirectional knowledge distillation mechanism that fosters knowledge sharing among clients while safeguarding privacy. Our approach represents the first systematic exploitation of source domain-aware features, resulting in significant advancements in model generalization capability.Extensive experiments on four standard benchmarks (OfficeHome, PACS, VLCS, and DomainNet) show that our method consistently surpasses state-of-the-art federated domain generalization approaches, with accuracy gains of 5.2-13.8%. The source code is available at https://github.com/pizzareapers/FedSDAF.
Differential Alignment for Domain Adaptive Object Detection
Dec 17, 2024



Domain adaptive object detection (DAOD) aims to generalize an object detector trained on labeled source-domain data to a target domain without annotations, the core principle of which is \emph{source-target feature alignment}. Typically, existing approaches employ adversarial learning to align the distributions of the source and target domains as a whole, barely considering the varying significance of distinct regions, say instances under different circumstances and foreground \emph{vs} background areas, during feature alignment. To overcome the shortcoming, we investigates a differential feature alignment strategy. Specifically, a prediction-discrepancy feedback instance alignment module (dubbed PDFA) is designed to adaptively assign higher weights to instances of higher teacher-student detection discrepancy, effectively handling heavier domain-specific information. Additionally, an uncertainty-based foreground-oriented image alignment module (UFOA) is proposed to explicitly guide the model to focus more on regions of interest. Extensive experiments on widely-used DAOD datasets together with ablation studies are conducted to demonstrate the efficacy of our proposed method and reveal its superiority over other SOTA alternatives. Our code is available at https://github.com/EstrellaXyu/Differential-Alignment-for-DAOD.
Advancing Re-Ranking with Multimodal Fusion and Target-Oriented Auxiliary Tasks in E-Commerce Search
Aug 11, 2024



In the rapidly evolving field of e-commerce, the effectiveness of search re-ranking models is crucial for enhancing user experience and driving conversion rates. Despite significant advancements in feature representation and model architecture, the integration of multimodal information remains underexplored. This study addresses this gap by investigating the computation and fusion of textual and visual information in the context of re-ranking. We propose \textbf{A}dvancing \textbf{R}e-Ranking with \textbf{M}ulti\textbf{m}odal Fusion and \textbf{T}arget-Oriented Auxiliary Tasks (ARMMT), which integrates an attention-based multimodal fusion technique and an auxiliary ranking-aligned task to enhance item representation and improve targeting capabilities. This method not only enriches the understanding of product attributes but also enables more precise and personalized recommendations. Experimental evaluations on JD.com's search platform demonstrate that ARMMT achieves state-of-the-art performance in multimodal information integration, evidenced by a 0.22\% increase in the Conversion Rate (CVR), significantly contributing to Gross Merchandise Volume (GMV). This pioneering approach has the potential to revolutionize e-commerce re-ranking, leading to elevated user satisfaction and business growth.
Predictive Sparse Manifold Transform
Aug 27, 2023We present Predictive Sparse Manifold Transform (PSMT), a minimalistic, interpretable and biologically plausible framework for learning and predicting natural dynamics. PSMT incorporates two layers where the first sparse coding layer represents the input sequence as sparse coefficients over an overcomplete dictionary and the second manifold learning layer learns a geometric embedding space that captures topological similarity and dynamic temporal linearity in sparse coefficients. We apply PSMT on a natural video dataset and evaluate the reconstruction performance with respect to contextual variability, the number of sparse coding basis functions and training samples. We then interpret the dynamic topological organization in the embedding space. We next utilize PSMT to predict future frames compared with two baseline methods with a static embedding space. We demonstrate that PSMT with a dynamic embedding space can achieve better prediction performance compared to static baselines. Our work establishes that PSMT is an efficient unsupervised generative framework for prediction of future visual stimuli.
Adaptive Texture Filtering for Single-Domain Generalized Segmentation
Mar 06, 2023



Domain generalization in semantic segmentation aims to alleviate the performance degradation on unseen domains through learning domain-invariant features. Existing methods diversify images in the source domain by adding complex or even abnormal textures to reduce the sensitivity to domain specific features. However, these approaches depend heavily on the richness of the texture bank, and training them can be time-consuming. In contrast to importing textures arbitrarily or augmenting styles randomly, we focus on the single source domain itself to achieve generalization. In this paper, we present a novel adaptive texture filtering mechanism to suppress the influence of texture without using augmentation, thus eliminating the interference of domain-specific features. Further, we design a hierarchical guidance generalization network equipped with structure-guided enhancement modules, which purpose is to learn the domain-invariant generalized knowledge. Extensive experiments together with ablation studies on widely-used datasets are conducted to verify the effectiveness of the proposed model, and reveal its superiority over other state-of-the-art alternatives.
Pipeline-Invariant Representation Learning for Neuroimaging
Aug 27, 2022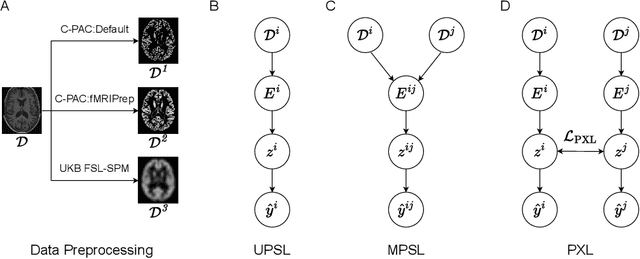

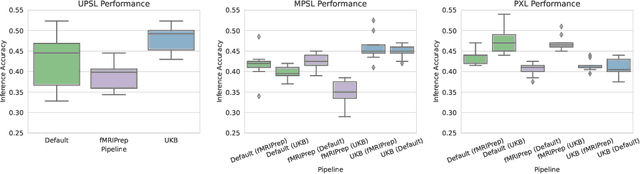
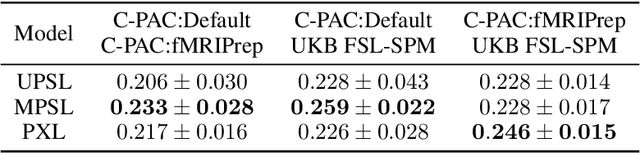
Deep learning has been widely applied in neuroimaging, including to predicting brain-phenotype relationships from magnetic resonance imaging (MRI) volumes. MRI data usually requires extensive preprocessing before it is ready for modeling, even via deep learning, in part due to its high dimensionality and heterogeneity. A growing array of MRI preprocessing pipelines have been developed each with its own strengths and limitations. Recent studies have shown that pipeline-related variation may lead to different scientific findings, even when using the identical data. Meanwhile, the machine learning community has emphasized the importance of shifting from model-centric to data-centric approaches given that data quality plays an essential role in deep learning applications. Motivated by this idea, we first evaluate how preprocessing pipeline selection can impact the downstream performance of a supervised learning model. We next propose two pipeline-invariant representation learning methodologies, MPSL and PXL, to improve consistency in classification performance and to capture similar neural network representations between pipeline pairs. Using 2000 human subjects from the UK Biobank dataset, we demonstrate that both models present unique advantages, in particular that MPSL can be used to improve out-of-sample generalization to new pipelines, while PXL can be used to improve predictive performance consistency and representational similarity within a closed pipeline set. These results suggest that our proposed models can be applied to overcome pipeline-related biases and to improve reproducibility in neuroimaging prediction tasks.
WeSinger 2: Fully Parallel Singing Voice Synthesis via Multi-Singer Conditional Adversarial Training
Jul 11, 2022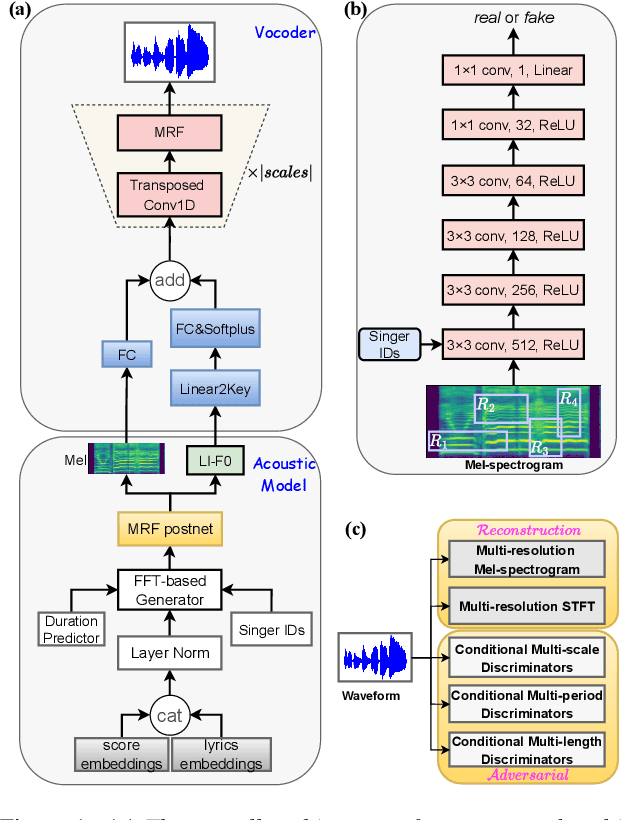
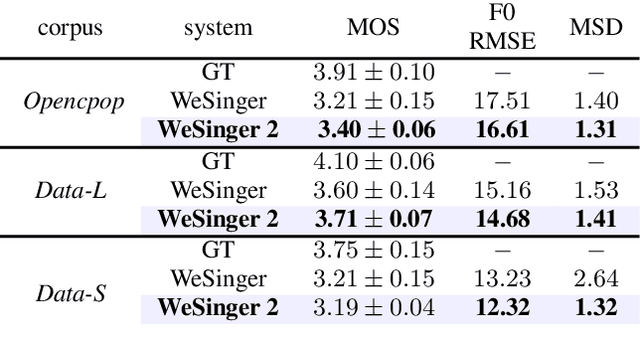


This paper aims to introduce a robust singing voice synthesis (SVS) system to produce high-quality singing voices efficiently by leveraging the adversarial training strategy. On one hand, we designed simple but generic random area conditional discriminators to help supervise the acoustic model, which can effectively avoid the over-smoothed spectrogram prediction by the duration-allocated Transformer-based acoustic model. On the other hand, we subtly combined the spectrogram with the frame-level linearly-interpolated F0 sequence as the input for the neural vocoder, which is then optimized with the help of multiple adversarial discriminators in the waveform domain and multi-scale distance functions in the frequency domain. The experimental results and ablation studies concluded that, compared with our previous auto-regressive work, our new system can produce high-quality singing voices efficiently by fine-tuning on different singing datasets covering from several minutes to few hours. Some synthesized singing samples are available online\footnote{https://zzw922cn.github.io/wesinger2}.
WeSinger: Data-augmented Singing Voice Synthesis with Auxiliary Losses
Mar 27, 2022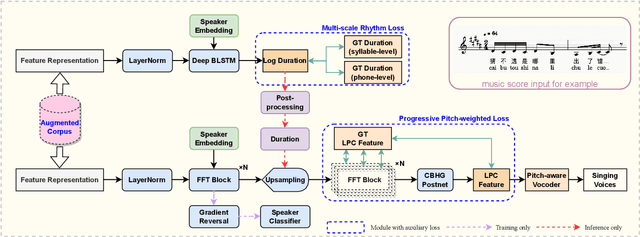
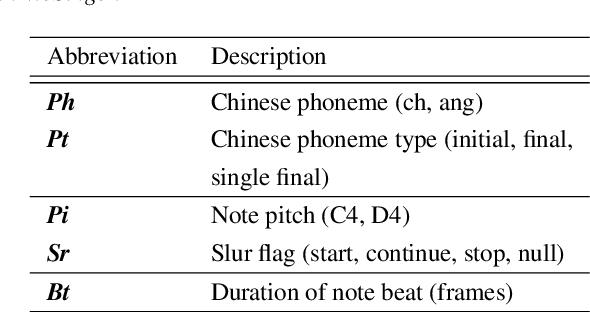

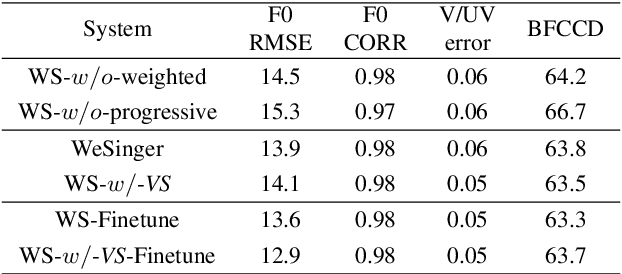
In this paper, we develop a new multi-singer Chinese neural singing voice synthesis (SVS) system named WeSinger. To improve the accuracy and naturalness of synthesized singing voice, we design several specifical modules and techniques: 1) A deep bi-directional LSTM based duration model with multi-scale rhythm loss and post-processing step; 2) A Transformer-alike acoustic model with progressive pitch-weighted decoder loss; 3) a 24 kHz pitch-aware LPCNet neural vocoder to produce high-quality singing waveforms; 4) A novel data augmentation method with multi-singer pre-training for stronger robustness and naturalness. To our knowledge, WeSinger is the first SVS system to adopt 24 kHz LPCNet and multi-singer pre-training simultaneously. Both quantitative and qualitative evaluation results demonstrate the effectiveness of WeSinger in terms of accuracy and naturalness, and WeSinger achieves state-of-the-art performance on the recently public Chinese singing corpus Opencpop. Some synthesized singing samples are available online.
Nana-HDR: A Non-attentive Non-autoregressive Hybrid Model for TTS
Sep 28, 2021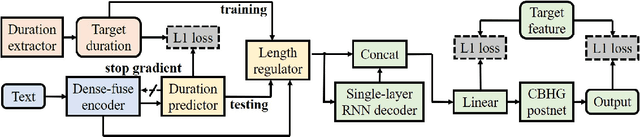

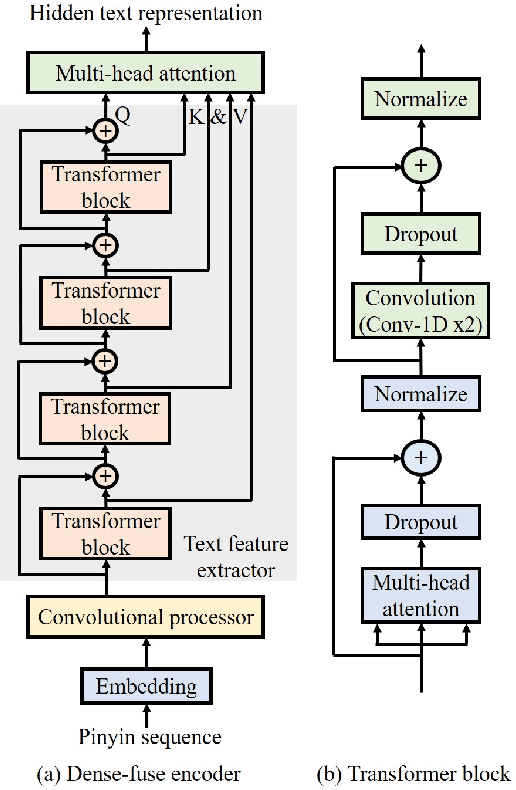
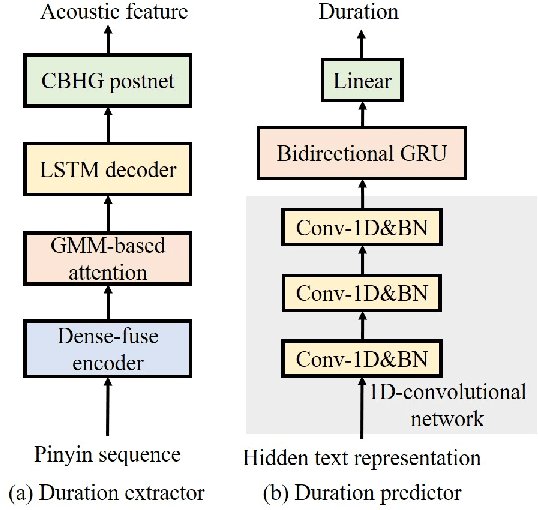
This paper presents Nana-HDR, a new non-attentive non-autoregressive model with hybrid Transformer-based Dense-fuse encoder and RNN-based decoder for TTS. It mainly consists of three parts: Firstly, a novel Dense-fuse encoder with dense connections between basic Transformer blocks for coarse feature fusion and a multi-head attention layer for fine feature fusion. Secondly, a single-layer non-autoregressive RNN-based decoder. Thirdly, a duration predictor instead of an attention model that connects the above hybrid encoder and decoder. Experiments indicate that Nana-HDR gives full play to the advantages of each component, such as strong text encoding ability of Transformer-based encoder, stateful decoding without being bothered by exposure bias and local information preference, and stable alignment provided by duration predictor. Due to these advantages, Nana-HDR achieves competitive performance in naturalness and robustness on two Mandarin corpora.