 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeSinger 2: Fully Parallel Singing Voice Synthesis via Multi-Singer Conditional Adversarial Training
Jul 11, 2022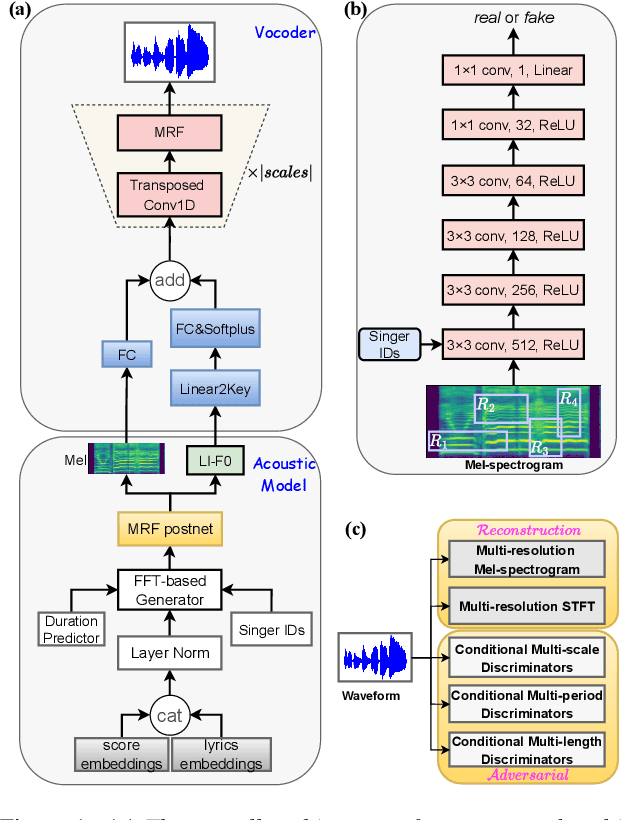


This paper aims to introduce a robust singing voice synthesis (SVS) system to produce high-quality singing voices efficiently by leveraging the adversarial training strategy. On one hand, we designed simple but generic random area conditional discriminators to help supervise the acoustic model, which can effectively avoid the over-smoothed spectrogram prediction by the duration-allocated Transformer-based acoustic model. On the other hand, we subtly combined the spectrogram with the frame-level linearly-interpolated F0 sequence as the input for the neural vocoder, which is then optimized with the help of multiple adversarial discriminators in the waveform domain and multi-scale distance functions in the frequency domain. The experimental results and ablation studies concluded that, compared with our previous auto-regressive work, our new system can produce high-quality singing voices efficiently by fine-tuning on different singing datasets covering from several minutes to few hours. Some synthesized singing samples are available online\footnote{https://zzw922cn.github.io/wesinger2}.
WeSinger: Data-augmented Singing Voice Synthesis with Auxiliary Losses
Mar 27, 2022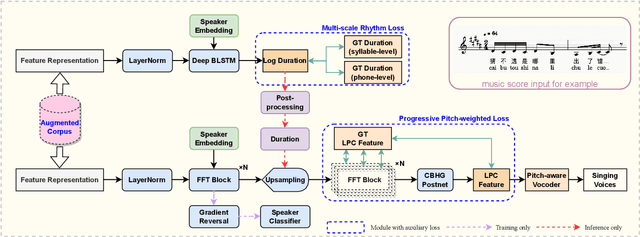
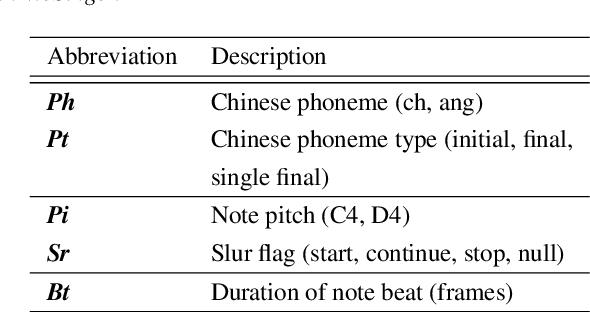

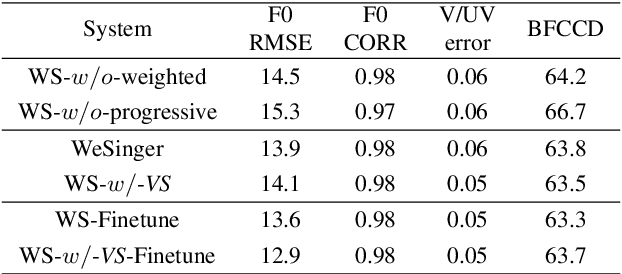
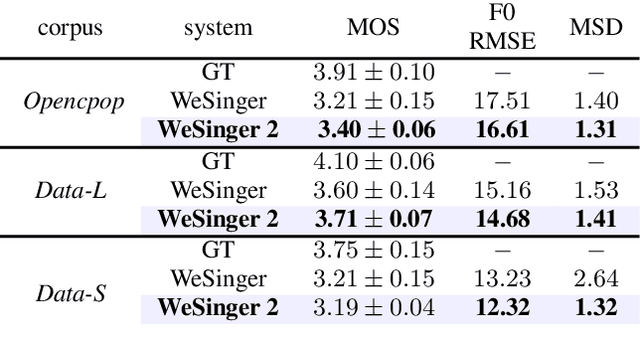
In this paper, we develop a new multi-singer Chinese neural singing voice synthesis (SVS) system named WeSinger. To improve the accuracy and naturalness of synthesized singing voice, we design several specifical modules and techniques: 1) A deep bi-directional LSTM based duration model with multi-scale rhythm loss and post-processing step; 2) A Transformer-alike acoustic model with progressive pitch-weighted decoder loss; 3) a 24 kHz pitch-aware LPCNet neural vocoder to produce high-quality singing waveforms; 4) A novel data augmentation method with multi-singer pre-training for stronger robustness and naturalness. To our knowledge, WeSinger is the first SVS system to adopt 24 kHz LPCNet and multi-singer pre-training simultaneously. Both quantitative and qualitative evaluation results demonstrate the effectiveness of WeSinger in terms of accuracy and naturalness, and WeSinger achieves state-of-the-art performance on the recently public Chinese singing corpus Opencpop. Some synthesized singing samples are available online.
Forward-Backward Decoding for Regularizing End-to-End TTS
Jul 18, 2019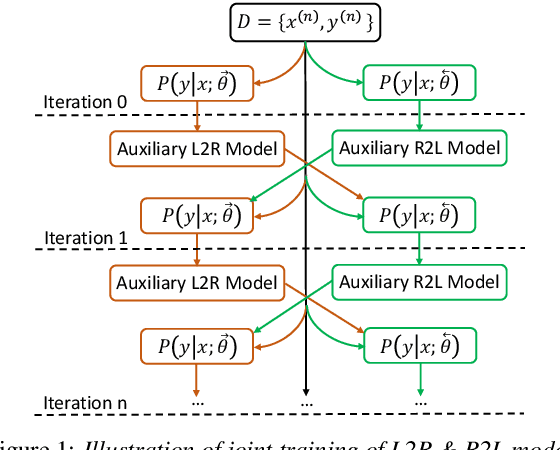
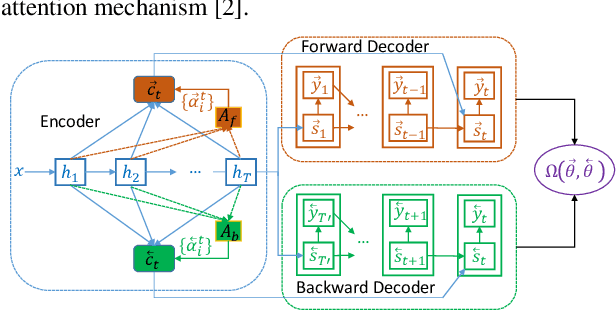
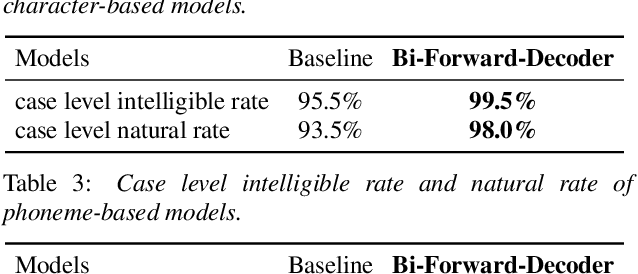
Neural end-to-end TTS can generate very high-quality synthesized speech, and even close to human recording within similar domain text. However, it performs unsatisfactory when scaling it to challenging test sets. One concern is that the encoder-decoder with attention-based network adopts autoregressive generative sequence model with the limitation of "exposure bias" To address this issue, we propose two novel methods, which learn to predict future by improving agreement between forward and backward decoding sequence. The first one is achieved by introducing divergence regularization terms into model training objective to reduce the mismatch between two directional models, namely L2R and R2L (which generates targets from left-to-right and right-to-left, respectively). While the second one operates on decoder-level and exploits the future information during decoding. In addition, we employ a joint training strategy to allow forward and backward decoding to improve each other in an interactive process. Experimental results show our proposed methods especially the second one (bidirectional decoder regularization), leads a significantly improvement on both robustness and overall naturalness, as outperforming baseline (the revised version of Tacotron2) with a MOS gap of 0.14 in a challenging test, and achieving close to human quality (4.42 vs. 4.49 in MOS) on general test.