 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeSinger 2: Fully Parallel Singing Voice Synthesis via Multi-Singer Conditional Adversarial Training
Jul 11, 2022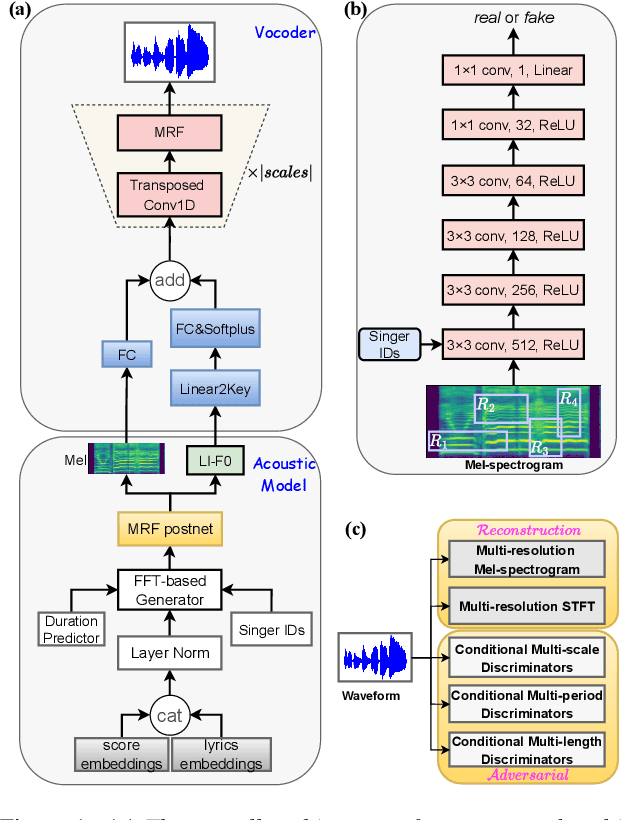
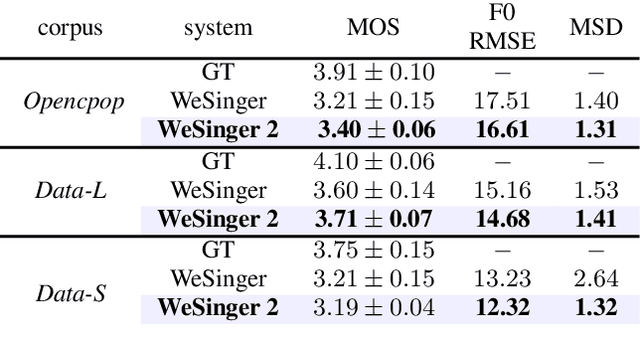


This paper aims to introduce a robust singing voice synthesis (SVS) system to produce high-quality singing voices efficiently by leveraging the adversarial training strategy. On one hand, we designed simple but generic random area conditional discriminators to help supervise the acoustic model, which can effectively avoid the over-smoothed spectrogram prediction by the duration-allocated Transformer-based acoustic model. On the other hand, we subtly combined the spectrogram with the frame-level linearly-interpolated F0 sequence as the input for the neural vocoder, which is then optimized with the help of multiple adversarial discriminators in the waveform domain and multi-scale distance functions in the frequency domain. The experimental results and ablation studies concluded that, compared with our previous auto-regressive work, our new system can produce high-quality singing voices efficiently by fine-tuning on different singing datasets covering from several minutes to few hours. Some synthesized singing samples are available online\footnote{https://zzw922cn.github.io/wesinger2}.
WeSinger: Data-augmented Singing Voice Synthesis with Auxiliary Losses
Mar 27, 2022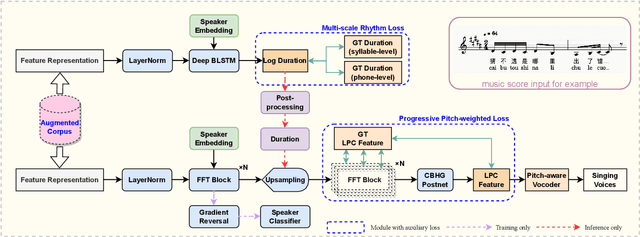
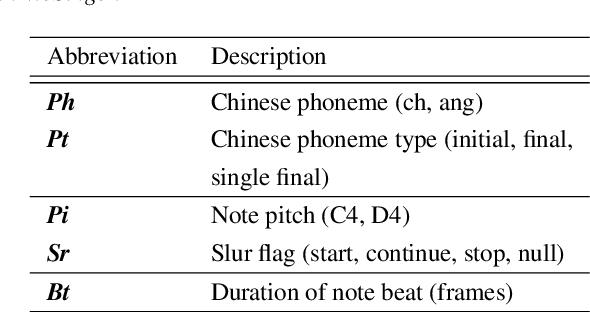

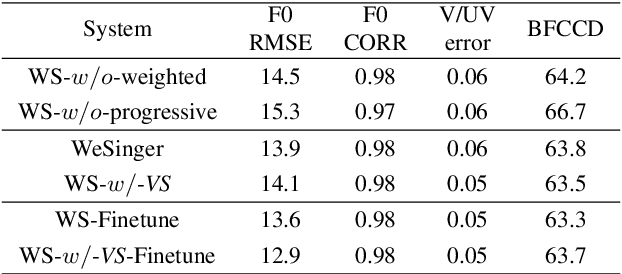
In this paper, we develop a new multi-singer Chinese neural singing voice synthesis (SVS) system named WeSinger. To improve the accuracy and naturalness of synthesized singing voice, we design several specifical modules and techniques: 1) A deep bi-directional LSTM based duration model with multi-scale rhythm loss and post-processing step; 2) A Transformer-alike acoustic model with progressive pitch-weighted decoder loss; 3) a 24 kHz pitch-aware LPCNet neural vocoder to produce high-quality singing waveforms; 4) A novel data augmentation method with multi-singer pre-training for stronger robustness and naturalness. To our knowledge, WeSinger is the first SVS system to adopt 24 kHz LPCNet and multi-singer pre-training simultaneously. Both quantitative and qualitative evaluation results demonstrate the effectiveness of WeSinger in terms of accuracy and naturalness, and WeSinger achieves state-of-the-art performance on the recently public Chinese singing corpus Opencpop. Some synthesized singing samples are available online.
AdaDurIAN: Few-shot Adaptation for Neural Text-to-Speech with DurIAN
May 12, 2020
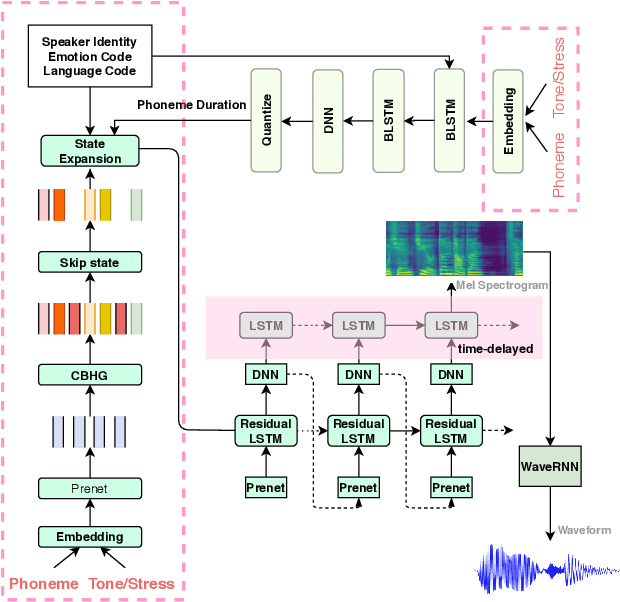
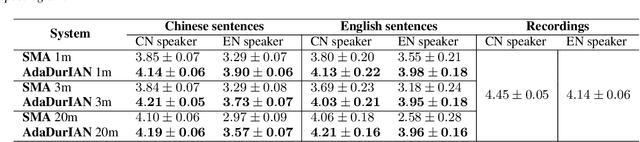
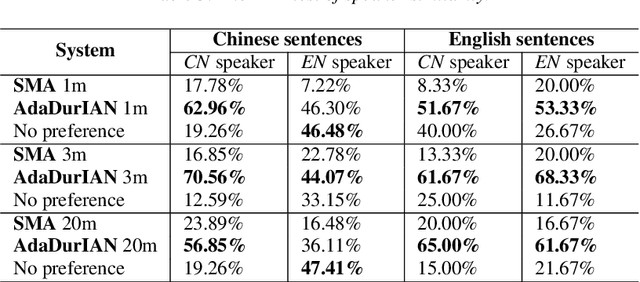
This paper investigates how to leverage a DurIAN-based average model to enable a new speaker to have both accurate pronunciation and fluent cross-lingual speaking with very limited monolingual data. A weakness of the recently proposed end-to-end text-to-speech (TTS) systems is that robust alignment is hard to achieve, which hinders it to scale well with very limited data. To cope with this issue, we introduce AdaDurIAN by training an improved DurIAN-based average model and leverage it to few-shot learning with the shared speaker-independent content encoder across different speakers. Several few-shot learning tasks in our experiments show AdaDurIAN can outperform the baseline end-to-end system by a large margin. Subjective evaluations also show that AdaDurIAN yields higher mean opinion score (MOS) of naturalness and more preferences of speaker similarity. In addition, we also apply AdaDurIAN to emotion transfer tasks and demonstrate its promising performance.
Deep Recurrent Convolutional Neural Network: Improving Performance For Speech Recognition
Dec 27, 2016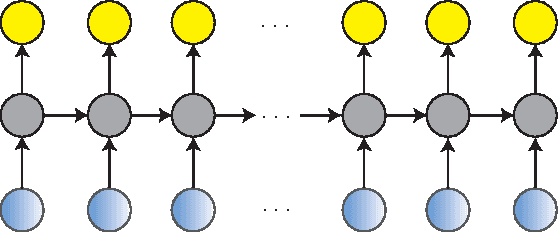
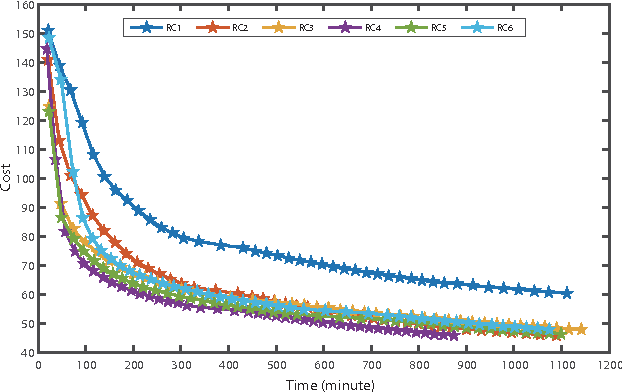
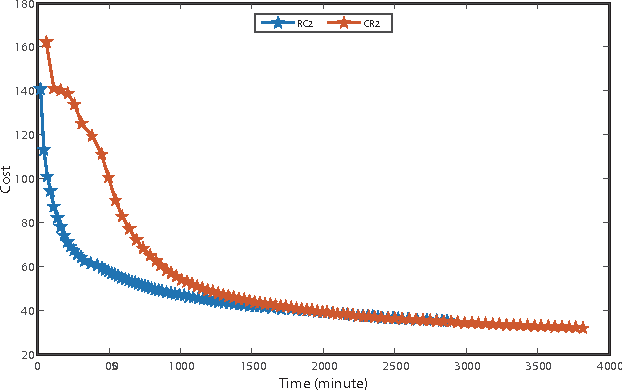
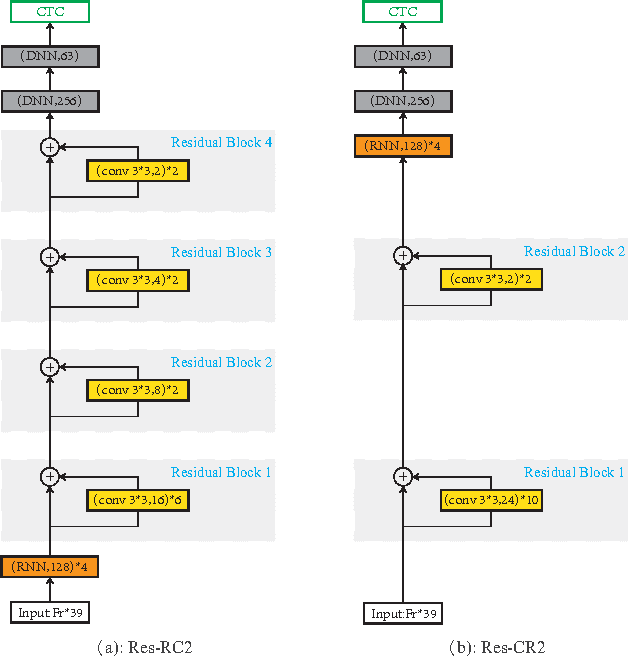
A deep learning approach has been widely applied in sequence modeling problems. In terms of automatic speech recognition (ASR), its performance has significantly been improved by increasing large speech corpus and deeper neural network. Especially, recurrent neural network and deep convolutional neural network have been applied in ASR successfully. Given the arising problem of training speed, we build a novel deep recurrent convolutional network for acoustic modeling and then apply deep residual learning to it. Our experiments show that it has not only faster convergence speed but better recognition accuracy over traditional deep convolutional recurrent network. In the experiments, we compare the convergence speed of our novel deep recurrent convolutional networks and traditional deep convolutional recurrent networks. With faster convergence speed, our novel deep recurrent convolutional networks can reach the comparable performance. We further show that applying deep residual learning can boost the convergence speed of our novel deep recurret convolutional networks. Finally, we evaluate all our experimental networks by phoneme error rate (PER) with our proposed bidirectional statistical n-gram language model. Our evaluation results show that our newly proposed deep recurrent convolutional network applied with deep residual learning can reach the best PER of 17.33\% with the fastest convergence speed on TIMIT database. The outstanding performance of our novel deep recurrent convolutional neural network with deep residual learning indicates that it can be potentially adopted in other sequential problems.
Composing Music with Grammar Argumented Neural Networks and Note-Level Encoding
Dec 07, 2016
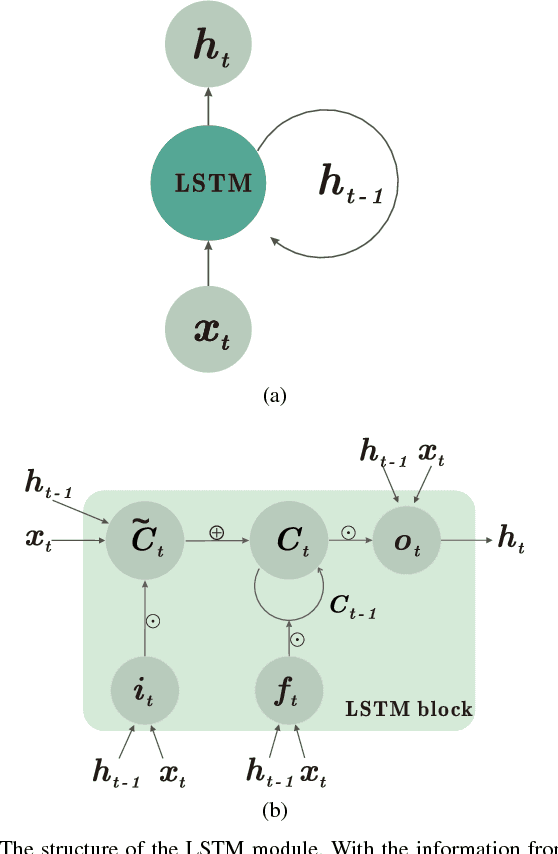
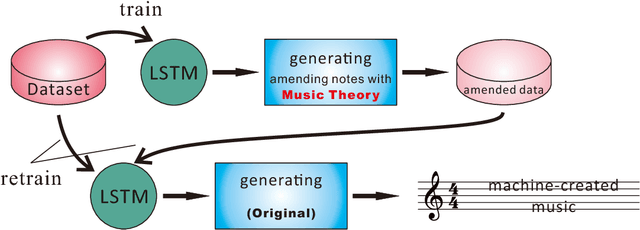

Creating aesthetically pleasing pieces of art, including music, has been a long-term goal for artificial intelligence research. Despite recent successes of long-short term memory (LSTM) recurrent neural networks (RNNs) in sequential learning, LSTM neural networks have not, by themselves, been able to generate natural-sounding music conforming to music theory. To transcend this inadequacy, we put forward a novel method for music composition that combines the LSTM with Grammars motivated by music theory. The main tenets of music theory are encoded as grammar argumented (GA) filters on the training data, such that the machine can be trained to generate music inheriting the naturalness of human-composed pieces from the original dataset while adhering to the rules of music theory. Unlike previous approaches, pitches and durations are encoded as one semantic entity, which we refer to as note-level encoding. This allows easy implementation of music theory grammars, as well as closer emulation of the thinking pattern of a musician. Although the GA rules are applied to the training data and never directly to the LSTM music generation, our machine still composes music that possess high incidences of diatonic scale notes, small pitch intervals and chords, in deference to music theory.