 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArondight: Red Teaming Large Vision Language Models with Auto-generated Multi-modal Jailbreak Prompts
Jul 21, 2024



Large Vision Language Models (VLMs) extend and enhance the perceptual abilities of Large Language Models (LLMs). Despite offering new possibilities for LLM applications, these advancements raise significant security and ethical concerns, particularly regarding the generation of harmful content. While LLMs have undergone extensive security evaluations with the aid of red teaming frameworks, VLMs currently lack a well-developed one. To fill this gap, we introduce Arondight, a standardized red team framework tailored specifically for VLMs. Arondight is dedicated to resolving issues related to the absence of visual modality and inadequate diversity encountered when transitioning existing red teaming methodologies from LLMs to VLMs. Our framework features an automated multi-modal jailbreak attack, wherein visual jailbreak prompts are produced by a red team VLM, and textual prompts are generated by a red team LLM guided by a reinforcement learning agent. To enhance the comprehensiveness of VLM security evaluation, we integrate entropy bonuses and novelty reward metrics. These elements incentivize the RL agent to guide the red team LLM in creating a wider array of diverse and previously unseen test cases. Our evaluation of ten cutting-edge VLMs exposes significant security vulnerabilities, particularly in generating toxic images and aligning multi-modal prompts. In particular, our Arondight achieves an average attack success rate of 84.5\% on GPT-4 in all fourteen prohibited scenarios defined by OpenAI in terms of generating toxic text. For a clearer comparison, we also categorize existing VLMs based on their safety levels and provide corresponding reinforcement recommendations. Our multimodal prompt dataset and red team code will be released after ethics committee approval. CONTENT WARNING: THIS PAPER CONTAINS HARMFUL MODEL RESPONSES.
BadSampler: Harnessing the Power of Catastrophic Forgetting to Poison Byzantine-robust Federated Learning
Jun 18, 2024



Federated Learning (FL) is susceptible to poisoning attacks, wherein compromised clients manipulate the global model by modifying local datasets or sending manipulated model updates. Experienced defenders can readily detect and mitigate the poisoning effects of malicious behaviors using Byzantine-robust aggregation rules. However, the exploration of poisoning attacks in scenarios where such behaviors are absent remains largely unexplored for Byzantine-robust FL. This paper addresses the challenging problem of poisoning Byzantine-robust FL by introducing catastrophic forgetting. To fill this gap, we first formally define generalization error and establish its connection to catastrophic forgetting, paving the way for the development of a clean-label data poisoning attack named BadSampler. This attack leverages only clean-label data (i.e., without poisoned data) to poison Byzantine-robust FL and requires the adversary to selectively sample training data with high loss to feed model training and maximize the model's generalization error. We formulate the attack as an optimization problem and present two elegant adversarial sampling strategies, Top-$\kappa$ sampling, and meta-sampling, to approximately solve it. Additionally, our formal error upper bound and time complexity analysis demonstrate that our design can preserve attack utility with high efficiency. Extensive evaluations on two real-world datasets illustrate the effectiveness and performance of our proposed attacks.
Security and Privacy of 6G Federated Learning-enabled Dynamic Spectrum Sharing
Jun 18, 2024



Spectrum sharing is increasingly vital in 6G wireless communication, facilitating dynamic access to unused spectrum holes. Recently, there has been a significant shift towards employing machine learning (ML) techniques for sensing spectrum holes. In this context, federated learning (FL)-enabled spectrum sensing technology has garnered wide attention, allowing for the construction of an aggregated ML model without disclosing the private spectrum sensing information of wireless user devices. However, the integrity of collaborative training and the privacy of spectrum information from local users have remained largely unexplored. This article first examines the latest developments in FL-enabled spectrum sharing for prospective 6G scenarios. It then identifies practical attack vectors in 6G to illustrate potential AI-powered security and privacy threats in these contexts. Finally, the study outlines future directions, including practical defense challenges and guidelines.
NAP^2: A Benchmark for Naturalness and Privacy-Preserving Text Rewriting by Learning from Human
Jun 06, 2024



Increasing concerns about privacy leakage issues in academia and industry arise when employing NLP models from third-party providers to process sensitive texts. To protect privacy before sending sensitive data to those models, we suggest sanitizing sensitive text using two common strategies used by humans: i) deleting sensitive expressions, and ii) obscuring sensitive details by abstracting them. To explore the issues and develop a tool for text rewriting, we curate the first corpus, coined NAP^2, through both crowdsourcing and the use of large language models (LLMs). Compared to the prior works based on differential privacy, which lead to a sharp drop in information utility and unnatural texts, the human-inspired approaches result in more natural rewrites and offer an improved balance between privacy protection and data utility, as demonstrated by our extensive experiments.
Gradient Transformation: Towards Efficient and Model-Agnostic Unlearning for Dynamic Graph Neural Networks
May 23, 2024



Graph unlearning has emerged as an essential tool for safeguarding user privacy and mitigating the negative impacts of undesirable data. Meanwhile, the advent of dynamic graph neural networks (DGNNs) marks a significant advancement due to their superior capability in learning from dynamic graphs, which encapsulate spatial-temporal variations in diverse real-world applications (e.g., traffic forecasting). With the increasing prevalence of DGNNs, it becomes imperative to investigate the implementation of dynamic graph unlearning. However, current graph unlearning methodologies are designed for GNNs operating on static graphs and exhibit limitations including their serving in a pre-processing manner and impractical resource demands. Furthermore, the adaptation of these methods to DGNNs presents non-trivial challenges, owing to the distinctive nature of dynamic graphs. To this end, we propose an effective, efficient, model-agnostic, and post-processing method to implement DGNN unlearning. Specifically, we first define the unlearning requests and formulate dynamic graph unlearning in the context of continuous-time dynamic graphs. After conducting a role analysis on the unlearning data, the remaining data, and the target DGNN model, we propose a method called Gradient Transformation and a loss function to map the unlearning request to the desired parameter update. Evaluations on six real-world datasets and state-of-the-art DGNN backbones demonstrate its effectiveness (e.g., limited performance drop even obvious improvement) and efficiency (e.g., at most 7.23$\times$ speed-up) outperformance, and potential advantages in handling future unlearning requests (e.g., at most 32.59$\times$ speed-up).
GraphGuard: Detecting and Counteracting Training Data Misuse in Graph Neural Networks
Dec 13, 2023The emergence of Graph Neural Networks (GNNs) in graph data analysis and their deployment on Machine Learning as a Service platforms have raised critical concerns about data misuse during model training. This situation is further exacerbated due to the lack of transparency in local training processes, potentially leading to the unauthorized accumulation of large volumes of graph data, thereby infringing on the intellectual property rights of data owners. Existing methodologies often address either data misuse detection or mitigation, and are primarily designed for local GNN models rather than cloud-based MLaaS platforms. These limitations call for an effective and comprehensive solution that detects and mitigates data misuse without requiring exact training data while respecting the proprietary nature of such data. This paper introduces a pioneering approach called GraphGuard, to tackle these challenges. We propose a training-data-free method that not only detects graph data misuse but also mitigates its impact via targeted unlearning, all without relying on the original training data. Our innovative misuse detection technique employs membership inference with radioactive data, enhancing the distinguishability between member and non-member data distributions. For mitigation, we utilize synthetic graphs that emulate the characteristics previously learned by the target model, enabling effective unlearning even in the absence of exact graph data. We conduct comprehensive experiments utilizing four real-world graph datasets to demonstrate the efficacy of GraphGuard in both detection and unlearning. We show that GraphGuard attains a near-perfect detection rate of approximately 100% across these datasets with various GNN models. In addition, it performs unlearning by eliminating the impact of the unlearned graph with a marginal decrease in accuracy (less than 5%).
RAI4IoE: Responsible AI for Enabling the Internet of Energy
Sep 20, 2023



This paper plans to develop an Equitable and Responsible AI framework with enabling techniques and algorithms for the Internet of Energy (IoE), in short, RAI4IoE. The energy sector is going through substantial changes fueled by two key drivers: building a zero-carbon energy sector and the digital transformation of the energy infrastructure. We expect to see the convergence of these two drivers resulting in the IoE, where renewable distributed energy resources (DERs), such as electric cars, storage batteries, wind turbines and photovoltaics (PV), can be connected and integrated for reliable energy distribution by leveraging advanced 5G-6G networks and AI technology. This allows DER owners as prosumers to participate in the energy market and derive economic incentives. DERs are inherently asset-driven and face equitable challenges (i.e., fair, diverse and inclusive). Without equitable access, privileged individuals, groups and organizations can participate and benefit at the cost of disadvantaged groups. The real-time management of DER resources not only brings out the equity problem to the IoE, it also collects highly sensitive location, time, activity dependent data, which requires to be handled responsibly (e.g., privacy, security and safety), for AI-enhanced predictions, optimization and prioritization services, and automated management of flexible resources. The vision of our project is to ensure equitable participation of the community members and responsible use of their data in IoE so that it could reap the benefits of advances in AI to provide safe, reliable and sustainable energy services.
Training-free Lexical Backdoor Attacks on Language Models
Feb 08, 2023



Large-scale language models have achieved tremendous success across various natural language processing (NLP) applications. Nevertheless, language models are vulnerable to backdoor attacks, which inject stealthy triggers into models for steering them to undesirable behaviors. Most existing backdoor attacks, such as data poisoning, require further (re)training or fine-tuning language models to learn the intended backdoor patterns. The additional training process however diminishes the stealthiness of the attacks, as training a language model usually requires long optimization time, a massive amount of data, and considerable modifications to the model parameters. In this work, we propose Training-Free Lexical Backdoor Attack (TFLexAttack) as the first training-free backdoor attack on language models. Our attack is achieved by injecting lexical triggers into the tokenizer of a language model via manipulating its embedding dictionary using carefully designed rules. These rules are explainable to human developers which inspires attacks from a wider range of hackers. The sparse manipulation of the dictionary also habilitates the stealthiness of our attack. We conduct extensive experiments on three dominant NLP tasks based on nine language models to demonstrate the effectiveness and universality of our attack. The code of this work is available at https://github.com/Jinxhy/TFLexAttack.
On the Interaction between Node Fairness and Edge Privacy in Graph Neural Networks
Jan 30, 2023Due to the emergence of graph neural networks (GNNs) and their widespread implementation in real-world scenarios, the fairness and privacy of GNNs have attracted considerable interest since they are two essential social concerns in the era of building trustworthy GNNs. Existing studies have respectively explored the fairness and privacy of GNNs and exhibited that both fairness and privacy are at the cost of GNN performance. However, the interaction between them is yet to be explored and understood. In this paper, we investigate the interaction between the fairness of a GNN and its privacy for the first time. We empirically identify that edge privacy risks increase when the individual fairness of nodes is improved. Next, we present the intuition behind such a trade-off and employ the influence function and Pearson correlation to measure it theoretically. To take the performance, fairness, and privacy of GNNs into account simultaneously, we propose implementing fairness-aware reweighting and privacy-aware graph structure perturbation modules in a retraining mechanism. Experimental results demonstrate that our method is effective in implementing GNN fairness with limited performance cost and restricted privacy risks.
Trustworthy Graph Neural Networks: Aspects, Methods and Trends
May 16, 2022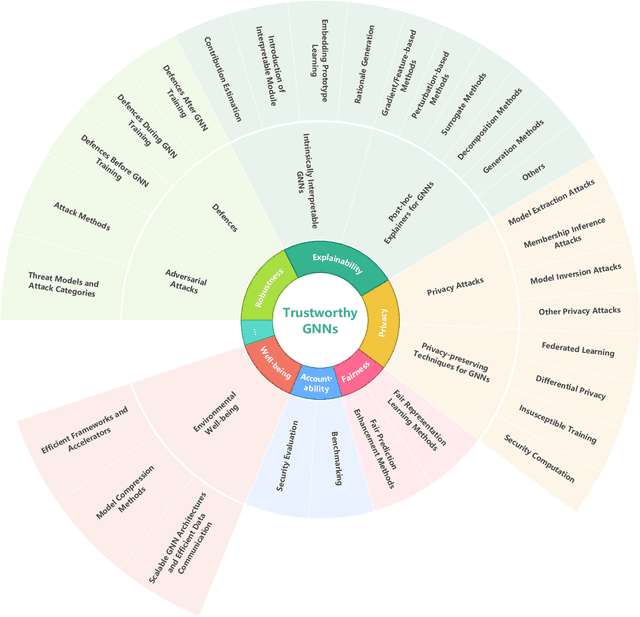
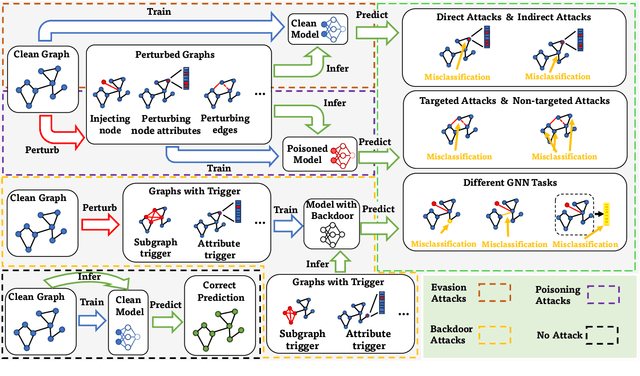
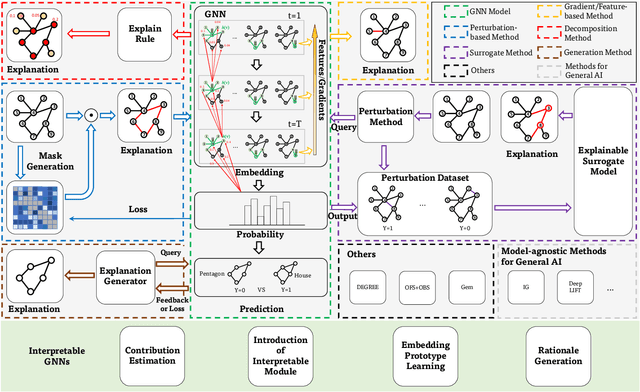
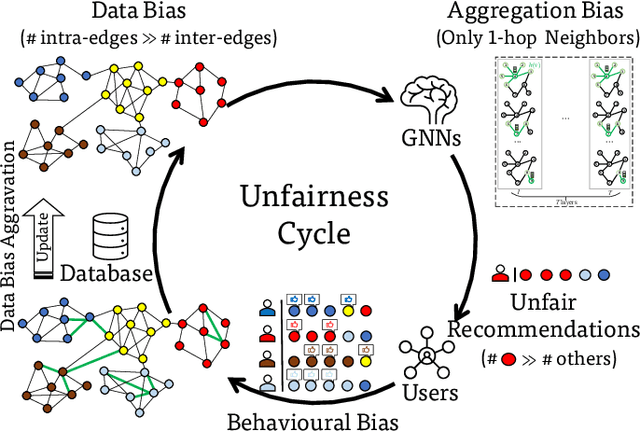
Graph neural networks (GNNs) have emerged as a series of competent graph learning methods for diverse real-world scenarios, ranging from daily applications like recommendation systems and question answering to cutting-edge technologies such as drug discovery in life sciences and n-body simulation in astrophysics. However, task performance is not the only requirement for GNNs. Performance-oriented GNNs have exhibited potential adverse effects like vulnerability to adversarial attacks, unexplainable discrimination against disadvantaged groups, or excessive resource consumption in edge computing environments. To avoid these unintentional harms, it is necessary to build competent GNNs characterised by trustworthiness. To this end, we propose a comprehensive roadmap to build trustworthy GNNs from the view of the various computing technologies involved. In this survey, we introduce basic concepts and comprehensively summarise existing efforts for trustworthy GNNs from six aspects, including robustness, explainability, privacy, fairness, accountability, and environmental well-being. Additionally, we highlight the intricate cross-aspect relations between the above six aspects of trustworthy GNNs. Finally, we present a thorough overview of trending directions for facilitating the research and industrialisation of trustworthy GNNs.