 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Language-guided Visual Recognition via Dynamic Convolutions
Oct 17, 2021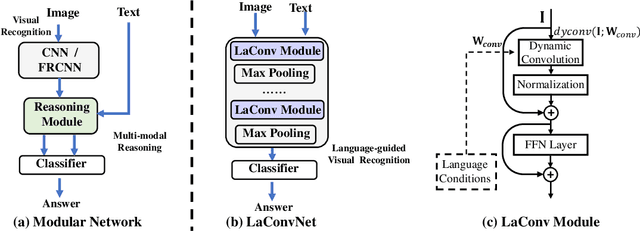
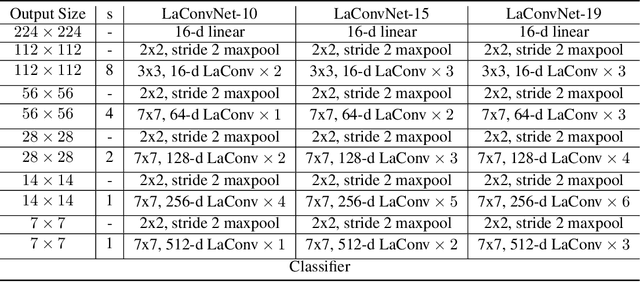
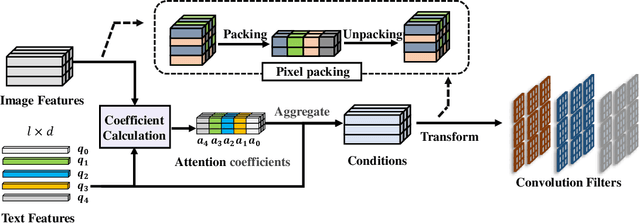
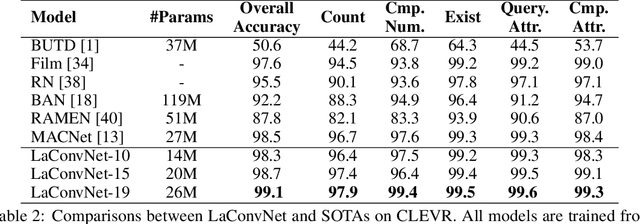
In this paper, we are committed to establishing an unified and end-to-end multi-modal network via exploring the language-guided visual recognition. To approach this target, we first propose a novel multi-modal convolution module called Language-dependent Convolution (LaConv). Its convolution kernels are dynamically generated based on natural language information, which can help extract differentiated visual features for different multi-modal examples. Based on the LaConv module, we further build the first fully language-driven convolution network, termed as LaConvNet, which can unify the visual recognition and multi-modal reasoning in one forward structure. To validate LaConv and LaConvNet, we conduct extensive experiments on four benchmark datasets of two vision-and-language tasks, i.e., visual question answering (VQA) and referring expression comprehension (REC). The experimental results not only shows the performance gains of LaConv compared to the existing multi-modal modules, but also witness the merits of LaConvNet as an unified network, including compact network, high generalization ability and excellent performance, e.g., +4.7% on RefCOCO+.
Domain Generalization on Medical Imaging Classification using Episodic Training with Task Augmentation
Jun 13, 2021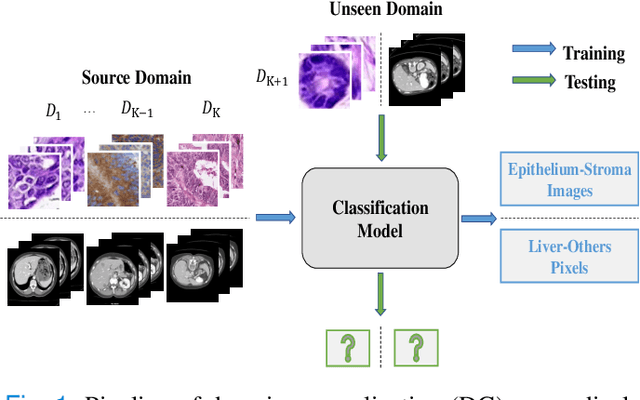
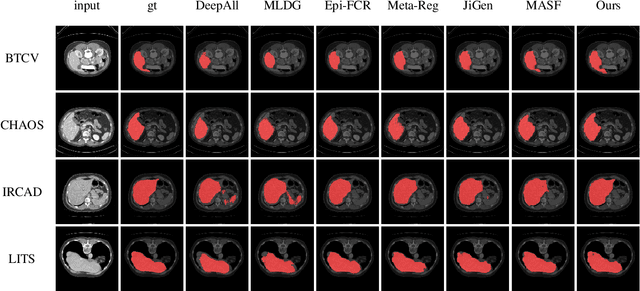
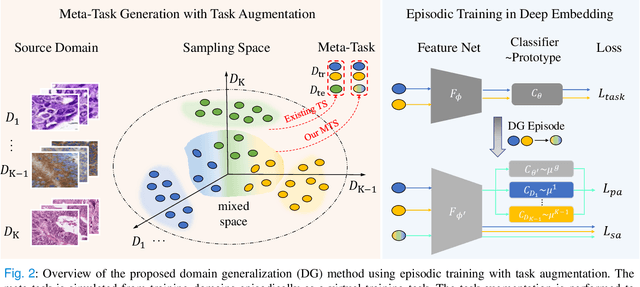
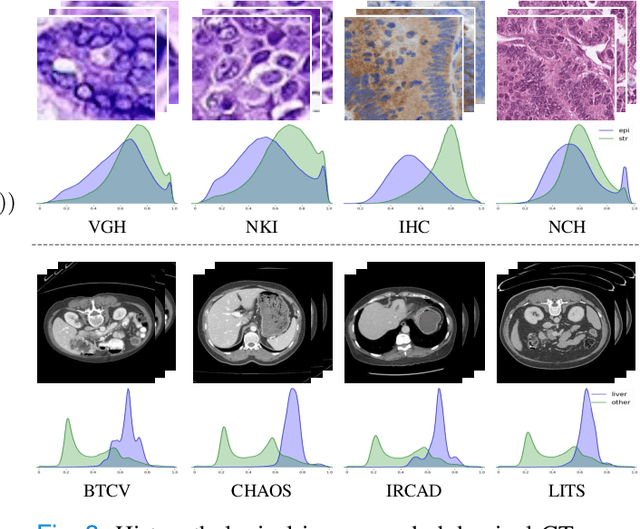
Medical imaging datasets usually exhibit domain shift due to the variations of scanner vendors, imaging protocols, etc. This raises the concern about the generalization capacity of machine learning models. Domain generalization (DG), which aims to learn a model from multiple source domains such that it can be directly generalized to unseen test domains, seems particularly promising to medical imaging community. To address DG, recent model-agnostic meta-learning (MAML) has been introduced, which transfers the knowledge from previous training tasks to facilitate the learning of novel testing tasks. However, in clinical practice, there are usually only a few annotated source domains available, which decreases the capacity of training task generation and thus increases the risk of overfitting to training tasks in the paradigm. In this paper, we propose a novel DG scheme of episodic training with task augmentation on medical imaging classification. Based on meta-learning, we develop the paradigm of episodic training to construct the knowledge transfer from episodic training-task simulation to the real testing task of DG. Motivated by the limited number of source domains in real-world medical deployment, we consider the unique task-level overfitting and we propose task augmentation to enhance the variety during training task generation to alleviate it. With the established learning framework, we further exploit a novel meta-objective to regularize the deep embedding of training domains. To validate the effectiveness of the proposed method, we perform experiments on histopathological images and abdominal CT images.
Hierarchical Deep Network with Uncertainty-aware Semi-supervised Learning for Vessel Segmentation
May 31, 2021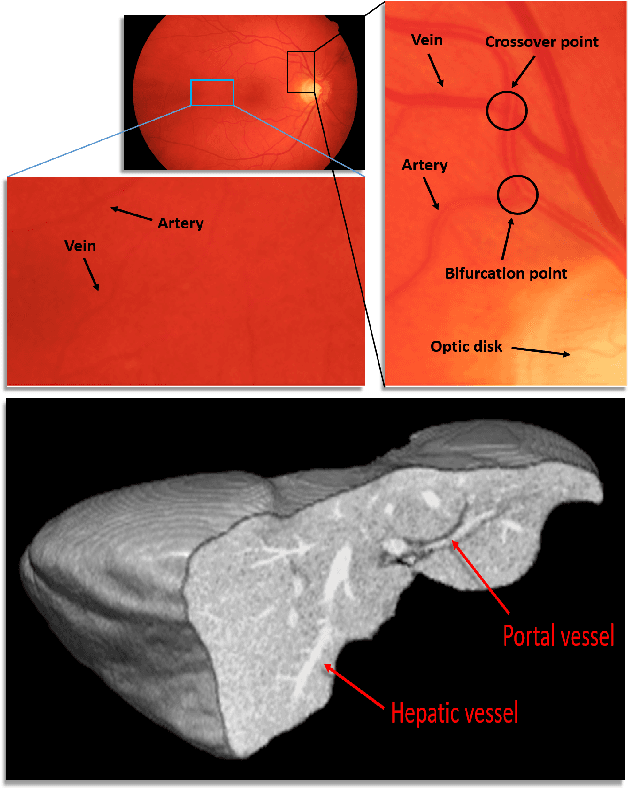
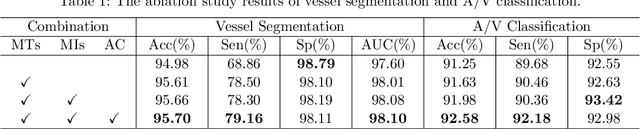
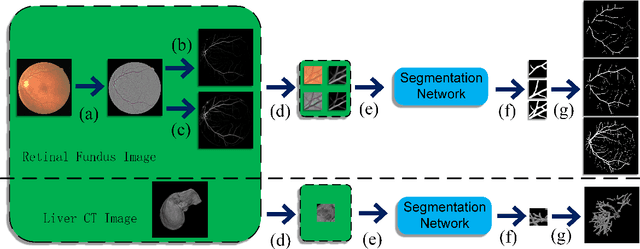
The analysis of organ vessels is essential for computer-aided diagnosis and surgical planning. But it is not a easy task since the fine-detailed connected regions of organ vessel bring a lot of ambiguity in vessel segmentation and sub-type recognition, especially for the low-contrast capillary regions. Furthermore, recent two-staged approaches would accumulate and even amplify these inaccuracies from the first-stage whole vessel segmentation into the second-stage sub-type vessel pixel-wise classification. Moreover, the scarcity of manual annotation in organ vessels poses another challenge. In this paper, to address the above issues, we propose a hierarchical deep network where an attention mechanism localizes the low-contrast capillary regions guided by the whole vessels, and enhance the spatial activation in those areas for the sub-type vessels. In addition, we propose an uncertainty-aware semi-supervised training framework to alleviate the annotation-hungry limitation of deep models. The proposed method achieves the state-of-the-art performance in the benchmarks of both retinal artery/vein segmentation in fundus images and liver portal/hepatic vessel segmentation in CT images.
I3Net: Implicit Instance-Invariant Network for Adapting One-Stage Object Detectors
Mar 30, 2021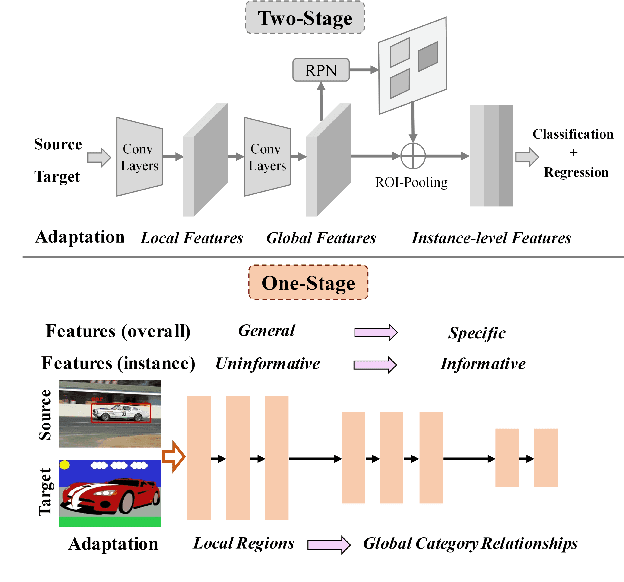
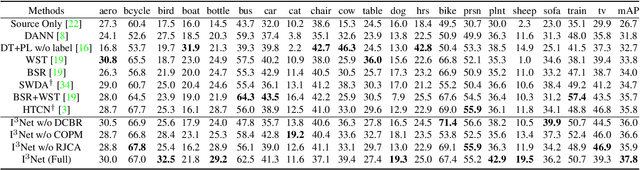
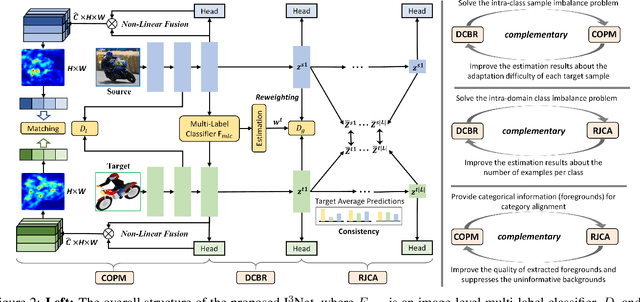
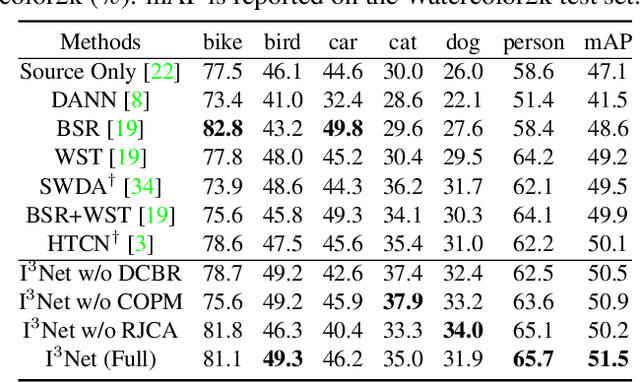
Recent works on two-stage cross-domain detection have widely explored the local feature patterns to achieve more accurate adaptation results. These methods heavily rely on the region proposal mechanisms and ROI-based instance-level features to design fine-grained feature alignment modules with respect to the foreground objects. However, for one-stage detectors, it is hard or even impossible to obtain explicit instance-level features in the detection pipelines. Motivated by this, we propose an Implicit Instance-Invariant Network (I3Net), which is tailored for adapting one-stage detectors and implicitly learns instance-invariant features via exploiting the natural characteristics of deep features in different layers. Specifically, we facilitate the adaptation from three aspects: (1) Dynamic and Class-Balanced Reweighting (DCBR) strategy, which considers the coexistence of intra-domain and intra-class variations to assign larger weights to those sample-scarce categories and easy-to-adapt samples; (2) Category-aware Object Pattern Matching (COPM) module, which boosts the cross-domain foreground objects matching guided by the categorical information and suppresses the uninformative background features; (3) Regularized Joint Category Alignment (RJCA) module, which jointly enforces the category alignment at different domain-specific layers with a consistency regularization. Experiments reveal that I3Net exceeds the state-of-the-art performance on benchmark datasets.
Consistent Posterior Distributions under Vessel-Mixing: A Regularization for Cross-Domain Retinal Artery/Vein Classification
Mar 16, 2021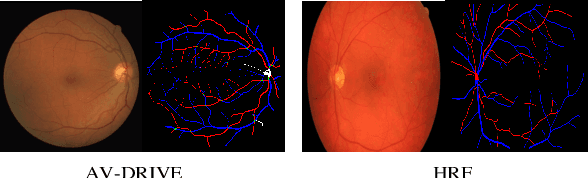
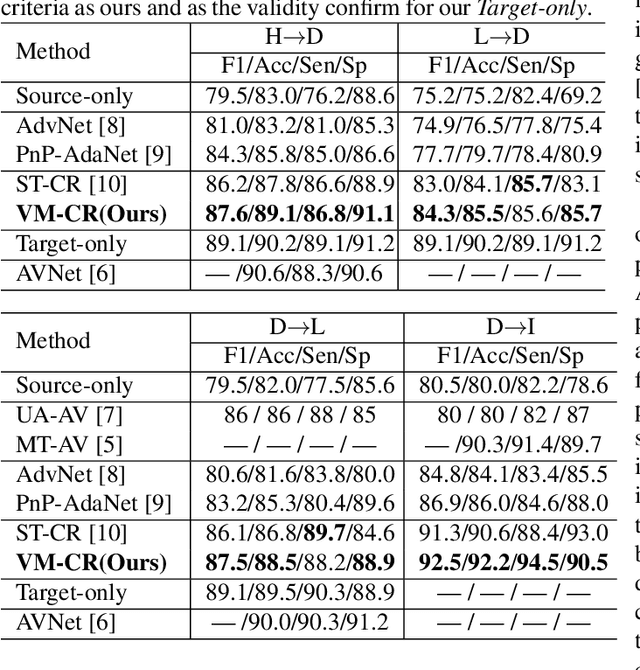
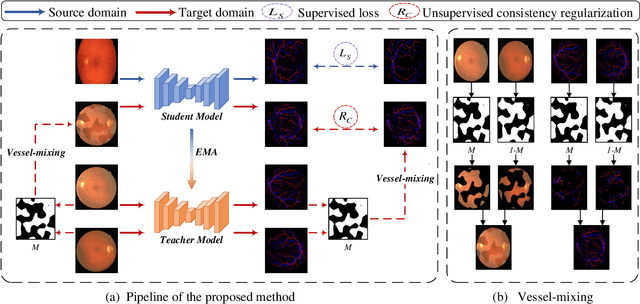
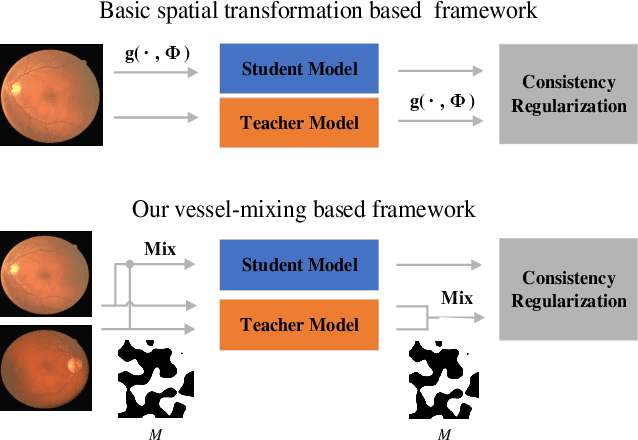
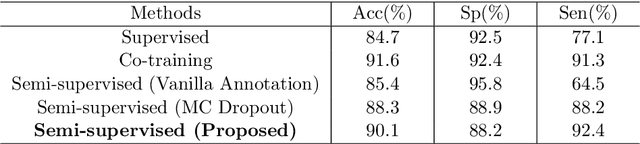
Retinal artery/vein (A/V) classification is a critical technique for diagnosing diabetes and cardiovascular diseases. Although deep learning based methods achieve impressive results in A/V classification, their performances usually degrade severely when being directly applied to another database, due to the domain shift, e.g., caused by the variations in imaging protocols. In this paper, we propose a novel vessel-mixing based consistency regularization framework, for cross-domain learning in retinal A/V classification. Specially, to alleviate the severe bias to source domain, based on the label smooth prior, the model is regularized to give consistent predictions for unlabeled target-domain inputs that are under perturbation. This consistency regularization implicitly introduces a mechanism where the model and the perturbation is opponent to each other, where the model is pushed to be robust enough to cope with the perturbation. Thus, we investigate a more difficult opponent to further inspire the robustness of model, in the scenario of retinal A/V, called vessel-mixing perturbation. Specially, it effectively disturbs the fundus images especially the vessel structures by mixing two images regionally. We conduct extensive experiments on cross-domain A/V classification using four public datasets, which are collected by diverse institutions and imaging devices. The results demonstrate that our method achieves the state-of-the-art cross-domain performance, which is also close to the upper bound obtained by fully supervised learning on target domain.
Unsupervised Anomaly Segmentation using Image-Semantic Cycle Translation
Mar 16, 2021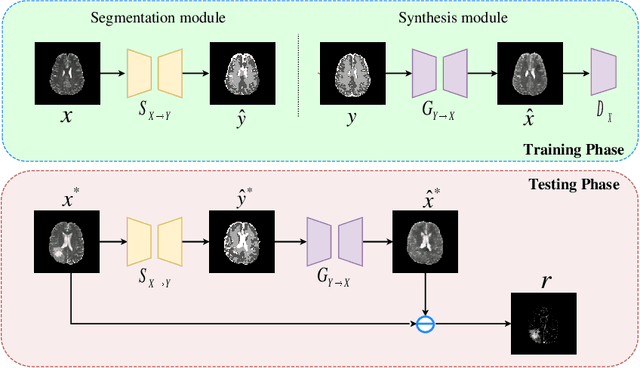

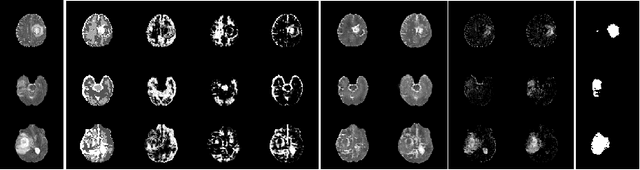
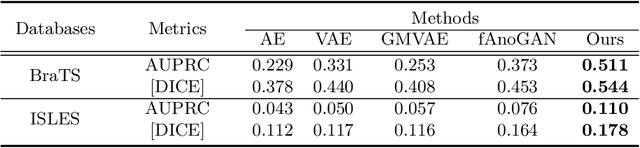
The goal of unsupervised anomaly segmentation (UAS) is to detect the pixel-level anomalies unseen during training. It is a promising field in the medical imaging community, e.g, we can use the model trained with only healthy data to segment the lesions of rare diseases. Existing methods are mainly based on Information Bottleneck, whose underlying principle is modeling the distribution of normal anatomy via learning to compress and recover the healthy data with a low-dimensional manifold, and then detecting lesions as the outlier from this learned distribution. However, this dimensionality reduction inevitably damages the localization information, which is especially essential for pixel-level anomaly detection. In this paper, to alleviate this issue, we introduce the semantic space of healthy anatomy in the process of modeling healthy-data distribution. More precisely, we view the couple of segmentation and synthesis as a special Autoencoder, and propose a novel cycle translation framework with a journey of 'image->semantic->image'. Experimental results on the BraTS and ISLES databases show that the proposed approach achieves significantly superior performance compared to several prior methods and segments the anomalies more accurately.
Underwater Image Enhancement via Learning Water Type Desensitized Representations
Feb 01, 2021
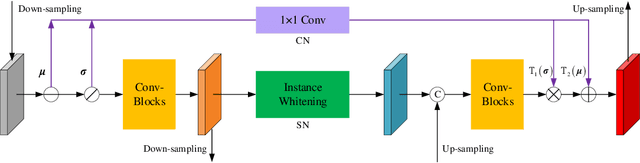


For underwater applications, the effects of light absorption and scattering result in image degradation. Moreover, the complex and changeable imaging environment makes it difficult to provide a universal enhancement solution to cope with the diversity of water types. In this letter, we present a novel underwater image enhancement (UIE) framework termed SCNet to address the above issues. SCNet is based on normalization schemes across both spatial and channel dimensions with the key idea of learning water type desensitized features. Considering the diversity of degradation is mainly rooted in the strong correlation among pixels, we apply whitening to de-correlates activations across spatial dimensions for each instance in a mini-batch. We also eliminate channel-wise correlation by standardizing and re-injecting the first two moments of the activations across channels. The normalization schemes of spatial and channel dimensions are performed at each scale of the U-Net to obtain multi-scale representations. With such latent encodings, the decoder can easily reconstruct the clean signal, and unaffected by the distortion types caused by the water. Experimental results on two real-world UIE datasets show that the proposed approach can successfully enhance images with diverse water types, and achieves competitive performance in visual quality improvement.
Twice Mixing: A Rank Learning based Quality Assessment Approach for Underwater Image Enhancement
Feb 01, 2021
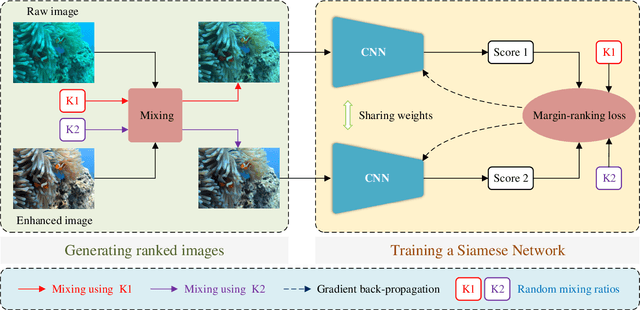


To improve the quality of underwater images, various kinds of underwater image enhancement (UIE) operators have been proposed during the past few years. However, the lack of effective objective evaluation methods limits the further development of UIE techniques. In this paper, we propose a novel rank learning guided no-reference quality assessment method for UIE. Our approach, termed Twice Mixing, is motivated by the observation that a mid-quality image can be generated by mixing a high-quality image with its low-quality version. Typical mixup algorithms linearly interpolate a given pair of input data. However, the human visual system is non-uniformity and non-linear in processing images. Therefore, instead of directly training a deep neural network based on the mixed images and their absolute scores calculated by linear combinations, we propose to train a Siamese Network to learn their quality rankings. Twice Mixing is trained based on an elaborately formulated self-supervision mechanism. Specifically, before each iteration, we randomly generate two mixing ratios which will be employed for both generating virtual images and guiding the network training. In the test phase, a single branch of the network is extracted to predict the quality rankings of different UIE outputs. We conduct extensive experiments on both synthetic and real-world datasets. Experimental results demonstrate that our approach outperforms the previous methods significantly.
Few-shot Medical Image Segmentation using a Global Correlation Network with Discriminative Embedding
Dec 10, 2020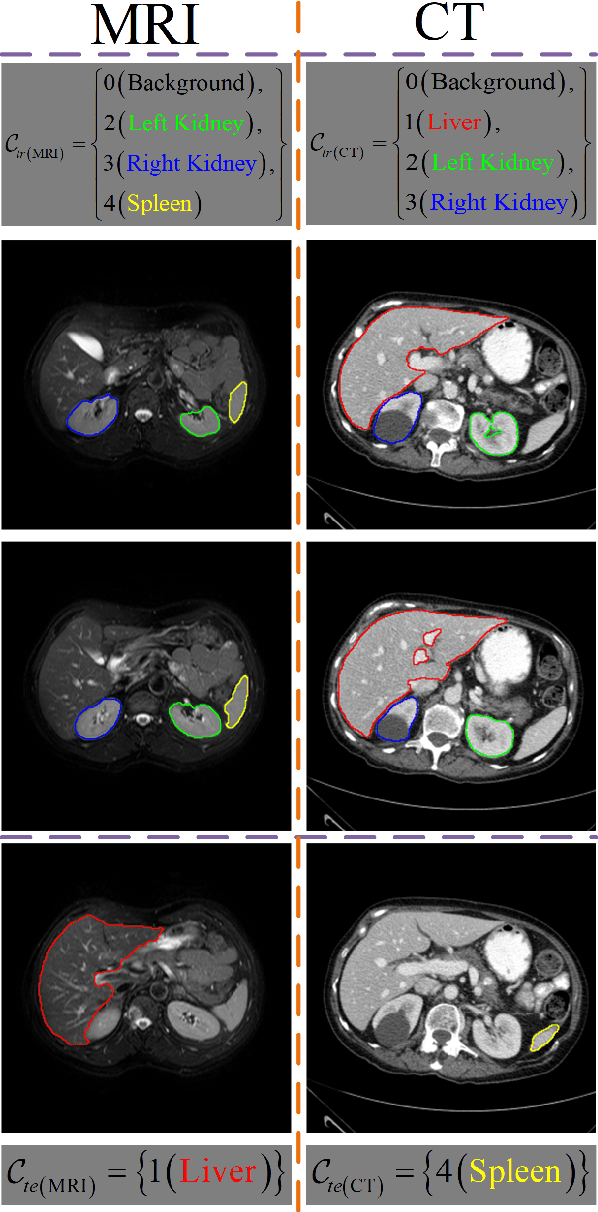
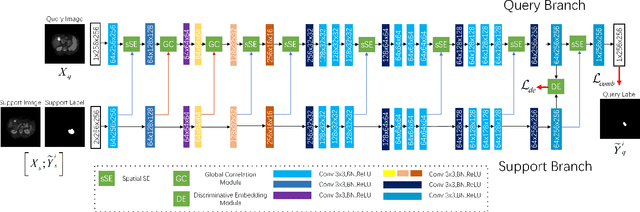
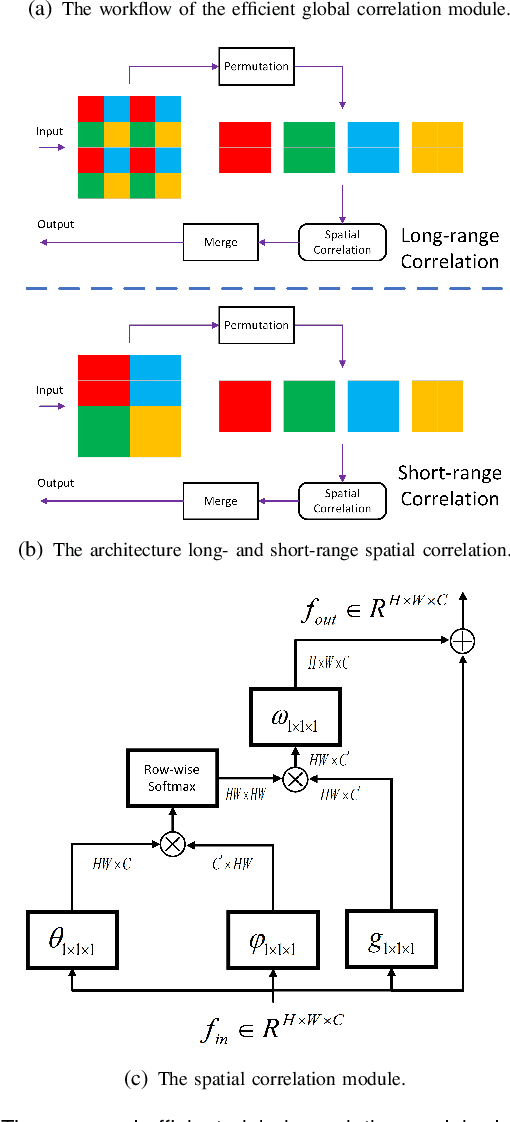
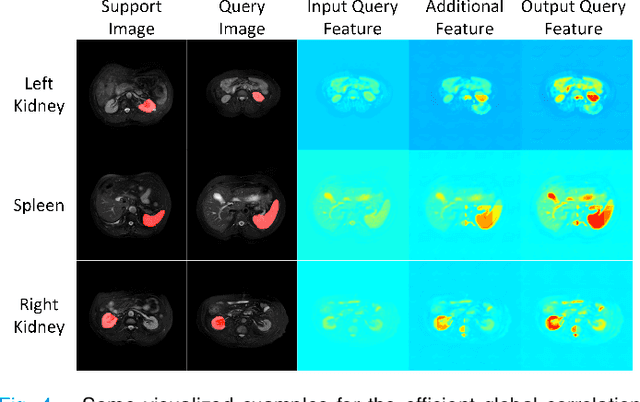
Despite deep convolutional neural networks achieved impressive progress in medical image computing and analysis, its paradigm of supervised learning demands a large number of annotations for training to avoid overfitting and achieving promising results. In clinical practices, massive semantic annotations are difficult to acquire in some conditions where specialized biomedical expert knowledge is required, and it is also a common condition where only few annotated classes are available. In this work, we proposed a novel method for few-shot medical image segmentation, which enables a segmentation model to fast generalize to an unseen class with few training images. We construct our few-shot image segmentor using a deep convolutional network trained episodically. Motivated by the spatial consistency and regularity in medical images, we developed an efficient global correlation module to capture the correlation between a support and query image and incorporate it into the deep network called global correlation network. Moreover, we enhance discriminability of deep embedding to encourage clustering of the feature domains of the same class while keep the feature domains of different organs far apart. Ablation Study proved the effectiveness of the proposed global correlation module and discriminative embedding loss. Extensive experiments on anatomical abdomen images on both CT and MRI modalities are performed to demonstrate the state-of-the-art performance of our proposed model.
Adaptive noise imitation for image denoising
Nov 30, 2020
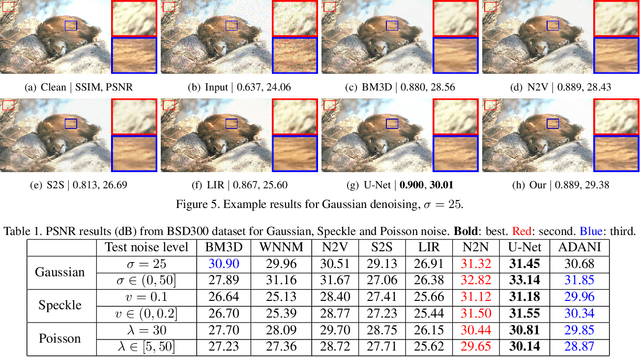
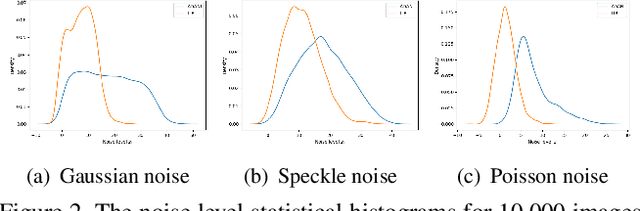

The effectiveness of existing denoising algorithms typically relies on accurate pre-defined noise statistics or plenty of paired data, which limits their practicality. In this work, we focus on denoising in the more common case where noise statistics and paired data are unavailable. Considering that denoising CNNs require supervision, we develop a new \textbf{adaptive noise imitation (ADANI)} algorithm that can synthesize noisy data from naturally noisy images. To produce realistic noise, a noise generator takes unpaired noisy/clean images as input, where the noisy image is a guide for noise generation. By imposing explicit constraints on the type, level and gradient of noise, the output noise of ADANI will be similar to the guided noise, while keeping the original clean background of the image. Coupling the noisy data output from ADANI with the corresponding ground-truth, a denoising CNN is then trained in a fully-supervised manner. Experiments show that the noisy data produced by ADANI are visually and statistically similar to real ones so that the denoising CNN in our method is competitive to other networks trained with external paired data.