 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Fragment Retrieval in Multi-modal Long-form Dialogues
Jun 03, 2026With the widespread adoption of multi-modal communication platforms, long-form dialogues interleaving text and images have become increasingly common. Users often need to retrieve coherent dialogue fragments related to specific topics, rather than isolated utterances. We propose Fine-grained Fragment Retrieval (FFR), which locates semantically relevant multi-utterance, multi-image fragments in multi-modal long-form dialogues. We explore two settings: (1) FFR within Single-Dialogue, retrieving fragments from a given dialogue; and (2) FFR within Dialogue Corpus, retrieving from a large-scale corpus for open-domain scenarios. For (1), we introduce F2RVLM, a generation-based retrieval model trained with reinforcement learning, using multi-objective rewards and difficulty-aware curriculum sampling to enhance fragment coherence. For (2), we develop FFRS, a two-stage system combining offline fragment-level indexing with online retrieval. Specifically, each dialogue is decomposed into minimal semantic fragments encoded by a Fragment Embedding Model (FEM) into a vector database; at inference, FEM rapidly recalls Top-K candidates, and F2RVLM performs fine-grained reasoning to identify the most relevant sub-content. To support FFR, we construct MLDR, the longest multi-modal dialogue retrieval dataset to date, and a WeChat-based real-world test set. Experiments on both benchmarks demonstrate that F2RVLM and FFRS consistently achieve superior performance across single-dialogue and corpus-level FFR.
Scenario-Adaptive MU-MIMO OFDM Semantic Communication With Asymmetric Neural Network
Feb 14, 2026Semantic Communication (SemCom) has emerged as a promising paradigm for 6G networks, aiming to extract and transmit task-relevant information rather than minimizing bit errors. However, applying SemCom to realistic downlink Multi-User Multi-Input Multi-Output (MU-MIMO) Orthogonal Frequency Division Multiplexing (OFDM) systems remains challenging due to severe Multi-User Interference (MUI) and frequency-selective fading. Existing Deep Joint Source-Channel Coding (DJSCC) schemes, primarily designed for point-to-point links, suffer from performance saturation in multi-user scenarios. To address these issues, we propose a scenario-adaptive MU-MIMO SemCom framework featuring an asymmetric architecture tailored for downlink transmission. At the transmitter, we introduce a scenario-aware semantic encoder that dynamically adjusts feature extraction based on Channel State Information (CSI) and Signal-to-Noise Ratio (SNR), followed by a neural precoding network designed to mitigate MUI in the semantic domain. At the receiver, a lightweight decoder equipped with a novel pilot-guided attention mechanism is employed to implicitly perform channel equalization and feature calibration using reference pilot symbols. Extensive simulation results over 3GPP channel models demonstrate that the proposed framework significantly outperforms DJSCC and traditional Separate Source-Channel Coding (SSCC) schemes in terms of Peak Signal-to-Noise Ratio (PSNR) and classification accuracy, particularly in low-SNR regimes, while maintaining low latency and computational cost on edge devices.
F2RVLM: Boosting Fine-grained Fragment Retrieval for Multi-Modal Long-form Dialogue with Vision Language Model
Aug 25, 2025Traditional dialogue retrieval aims to select the most appropriate utterance or image from recent dialogue history. However, they often fail to meet users' actual needs for revisiting semantically coherent content scattered across long-form conversations. To fill this gap, we define the Fine-grained Fragment Retrieval (FFR) task, requiring models to locate query-relevant fragments, comprising both utterances and images, from multimodal long-form dialogues. As a foundation for FFR, we construct MLDR, the longest-turn multimodal dialogue retrieval dataset to date, averaging 25.45 turns per dialogue, with each naturally spanning three distinct topics. To evaluate generalization in real-world scenarios, we curate and annotate a WeChat-based test set comprising real-world multimodal dialogues with an average of 75.38 turns. Building on these resources, we explore existing generation-based Vision-Language Models (VLMs) on FFR and observe that they often retrieve incoherent utterance-image fragments. While optimized for generating responses from visual-textual inputs, these models lack explicit supervision to ensure semantic coherence within retrieved fragments. To this end, we propose F2RVLM, a generative retrieval model trained in a two-stage paradigm: (1) supervised fine-tuning to inject fragment-level retrieval knowledge, and (2) GRPO-based reinforcement learning with multi-objective rewards promoting semantic precision, relevance, and contextual coherence. To handle varying intra-fragment complexity, from locally dense to sparsely distributed, we introduce difficulty-aware curriculum sampling that ranks training instances by model-predicted difficulty and gradually exposes the model to harder samples. This boosts reasoning ability in long, multi-turn contexts. F2RVLM outperforms popular VLMs in both in-domain and real-domain settings, demonstrating superior retrieval performance.
ViRefSAM: Visual Reference-Guided Segment Anything Model for Remote Sensing Segmentation
Jul 03, 2025The Segment Anything Model (SAM), with its prompt-driven paradigm, exhibits strong generalization in generic segmentation tasks. However, applying SAM to remote sensing (RS) images still faces two major challenges. First, manually constructing precise prompts for each image (e.g., points or boxes) is labor-intensive and inefficient, especially in RS scenarios with dense small objects or spatially fragmented distributions. Second, SAM lacks domain adaptability, as it is pre-trained primarily on natural images and struggles to capture RS-specific semantics and spatial characteristics, especially when segmenting novel or unseen classes. To address these issues, inspired by few-shot learning, we propose ViRefSAM, a novel framework that guides SAM utilizing only a few annotated reference images that contain class-specific objects. Without requiring manual prompts, ViRefSAM enables automatic segmentation of class-consistent objects across RS images. Specifically, ViRefSAM introduces two key components while keeping SAM's original architecture intact: (1) a Visual Contextual Prompt Encoder that extracts class-specific semantic clues from reference images and generates object-aware prompts via contextual interaction with target images; and (2) a Dynamic Target Alignment Adapter, integrated into SAM's image encoder, which mitigates the domain gap by injecting class-specific semantics into target image features, enabling SAM to dynamically focus on task-relevant regions. Extensive experiments on three few-shot segmentation benchmarks, including iSAID-5$^i$, LoveDA-2$^i$, and COCO-20$^i$, demonstrate that ViRefSAM enables accurate and automatic segmentation of unseen classes by leveraging only a few reference images and consistently outperforms existing few-shot segmentation methods across diverse datasets.
Knowledge-Base based Semantic Image Transmission Using CLIP
Apr 01, 2025



This paper proposes a novel knowledge-Base (KB) assisted semantic communication framework for image transmission. At the receiver, a Facebook AI Similarity Search (FAISS) based vector database is constructed by extracting semantic embeddings from images using the Contrastive Language-Image Pre-Training (CLIP) model. During transmission, the transmitter first extracts a 512-dimensional semantic feature using the CLIP model, then compresses it with a lightweight neural network for transmission. After receiving the signal, the receiver reconstructs the feature back to 512 dimensions and performs similarity matching from the KB to retrieve the most semantically similar image. Semantic transmission success is determined by category consistency between the transmitted and retrieved images, rather than traditional metrics like Peak Signal-to-Noise Ratio (PSNR). The proposed system prioritizes semantic accuracy, offering a new evaluation paradigm for semantic-aware communication systems. Experimental validation on CIFAR100 demonstrates the effectiveness of the framework in achieving semantic image transmission.
Learning to Evaluate Performance of Multi-modal Semantic Localization
Sep 19, 2022
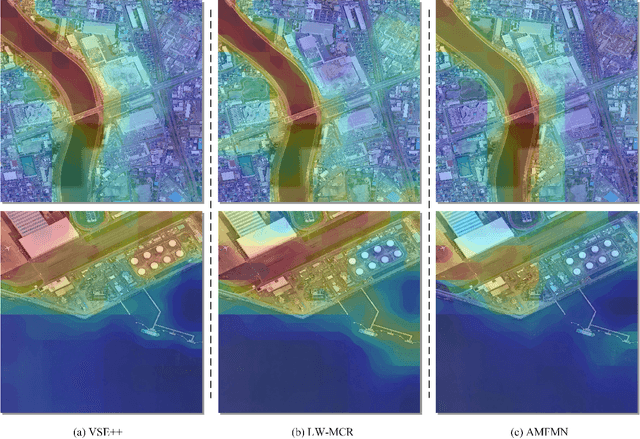
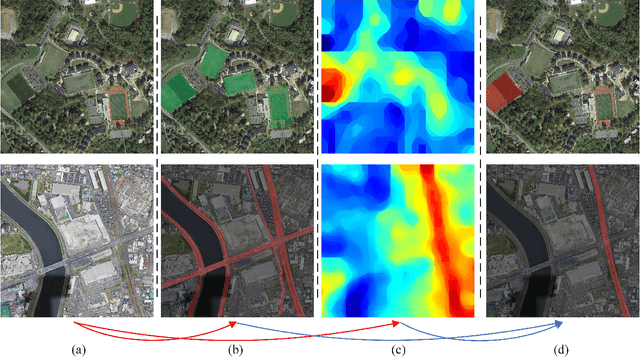
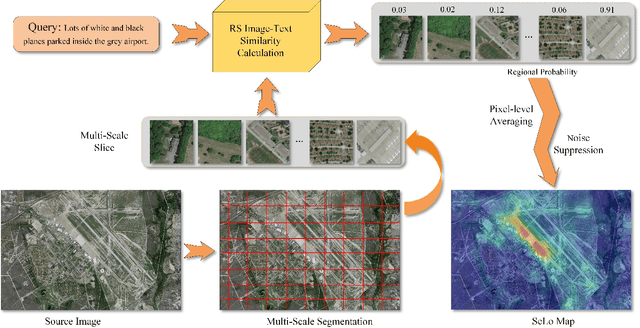
Semantic localization (SeLo) refers to the task of obtaining the most relevant locations in large-scale remote sensing (RS) images using semantic information such as text. As an emerging task based on cross-modal retrieval, SeLo achieves semantic-level retrieval with only caption-level annotation, which demonstrates its great potential in unifying downstream tasks. Although SeLo has been carried out successively, but there is currently no work has systematically explores and analyzes this urgent direction. In this paper, we thoroughly study this field and provide a complete benchmark in terms of metrics and testdata to advance the SeLo task. Firstly, based on the characteristics of this task, we propose multiple discriminative evaluation metrics to quantify the performance of the SeLo task. The devised significant area proportion, attention shift distance, and discrete attention distance are utilized to evaluate the generated SeLo map from pixel-level and region-level. Next, to provide standard evaluation data for the SeLo task, we contribute a diverse, multi-semantic, multi-objective Semantic Localization Testset (AIR-SLT). AIR-SLT consists of 22 large-scale RS images and 59 test cases with different semantics, which aims to provide a comprehensive evaluations for retrieval models. Finally, we analyze the SeLo performance of RS cross-modal retrieval models in detail, explore the impact of different variables on this task, and provide a complete benchmark for the SeLo task. We have also established a new paradigm for RS referring expression comprehension, and demonstrated the great advantage of SeLo in semantics through combining it with tasks such as detection and road extraction. The proposed evaluation metrics, semantic localization testsets, and corresponding scripts have been open to access at github.com/xiaoyuan1996/SemanticLocalizationMetrics .