 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Federated and Parameter-Efficient Framework for Large Language Model Training in Medicine
Jan 29, 2026Large language models (LLMs) have demonstrated strong performance on medical benchmarks, including question answering and diagnosis. To enable their use in clinical settings, LLMs are typically further adapted through continued pretraining or post-training using clinical data. However, most medical LLMs are trained on data from a single institution, which faces limitations in generalizability and safety in heterogeneous systems. Federated learning (FL) is a promising solution for enabling collaborative model development across healthcare institutions. Yet applying FL to LLMs in medicine remains fundamentally limited. First, conventional FL requires transmitting the full model during each communication round, which becomes impractical for multi-billion-parameter LLMs given the limited computational resources. Second, many FL algorithms implicitly assume data homogeneity, whereas real-world clinical data are highly heterogeneous across patients, diseases, and institutional practices. We introduce the model-agnostic and parameter-efficient federated learning framework for adapting LLMs to medical applications. Fed-MedLoRA transmits only low-rank adapter parameters, reducing communication and computation overhead, while Fed-MedLoRA+ further incorporates adaptive, data-aware aggregation to improve convergence under cross-site heterogeneity. We apply the framework to clinical information extraction (IE), which transforms patient narratives into structured medical entities and relations. Accuracy was assessed across five patient cohorts through comparisons with BERT models, and LLaMA-3 and DeepSeek-R1, GPT-4o models. Evaluation settings included (1) in-domain training and testing, (2) external validation on independent cohorts, and (3) a low-resource new-site adaptation scenario using real-world clinical notes from the Yale New Haven Health System.
Textual Equilibrium Propagation for Deep Compound AI Systems
Jan 28, 2026Large language models (LLMs) are increasingly deployed as part of compound AI systems that coordinate multiple modules (e.g., retrievers, tools, verifiers) over long-horizon workflows. Recent approaches that propagate textual feedback globally (e.g., TextGrad) make it feasible to optimize such pipelines, but we find that performance degrades as system depth grows. In particular, long-horizon agentic workflows exhibit two depth-scaling failure modes: 1) exploding textual gradient, where textual feedback grows exponentially with depth, leading to prohibitively long message and amplifies evaluation biases; and 2) vanishing textual gradient, where limited long-context ability causes models overemphasize partial feedback and compression of lengthy feedback causes downstream messages to lose specificity gradually as they propagate many hops upstream. To mitigate these issues, we introduce Textual Equilibrium Propagation (TEP), a local learning principle inspired by Equilibrium Propagation in energy-based models. TEP includes two phases: 1) a free phase where a local LLM critics iteratively refine prompts until reaching equilibrium (no further improvements are suggested); and 2) a nudged phase which applies proximal prompt edits with bounded modification intensity, using task-level objectives that propagate via forward signaling rather than backward feedback chains. This design supports local prompt optimization followed by controlled adaptation toward global goals without the computational burden and signal degradation of global textual backpropagation. Across long-horizon QA benchmarks and multi-agent tool-use dataset, TEP consistently improves accuracy and efficiency over global propagation methods such as TextGrad. The gains grows with depth, while preserving the practicality of black-box LLM components in deep compound AI system.
When Single-Agent with Skills Replace Multi-Agent Systems and When They Fail
Jan 08, 2026Multi-agent AI systems have proven effective for complex reasoning. These systems are compounded by specialized agents, which collaborate through explicit communication, but incur substantial computational overhead. A natural question arises: can we achieve similar modularity benefits with a single agent that selects from a library of skills? We explore this question by viewing skills as internalized agent behaviors. From this perspective, a multi-agent system can be compiled into an equivalent single-agent system, trading inter-agent communication for skill selection. Our preliminary experiments suggest this approach can substantially reduce token usage and latency while maintaining competitive accuracy on reasoning benchmarks. However, this efficiency raises a deeper question that has received little attention: how does skill selection scale as libraries grow? Drawing on principles from cognitive science, we propose that LLM skill selection exhibits bounded capacity analogous to human decision-making. We investigate the scaling behavior of skill selection and observe a striking pattern. Rather than degrading gradually, selection accuracy remains stable up to a critical library size, then drops sharply, indicating a phase transition reminiscent of capacity limits in human cognition. Furthermore, we find evidence that semantic confusability among similar skills, rather than library size alone, plays a central role in this degradation. This perspective suggests that hierarchical organization, which has long helped humans manage complex choices, may similarly benefit AI systems. Our initial results with hierarchical routing support this hypothesis. This work opens new questions about the fundamental limits of semantic-based skill selection in LLMs and offers a cognitive-grounded framework and practical guidelines for designing scalable skill-based agents.
HookMIL: Revisiting Context Modeling in Multiple Instance Learning for Computational Pathology
Dec 20, 2025Multiple Instance Learning (MIL) has enabled weakly supervised analysis of whole-slide images (WSIs) in computational pathology. However, traditional MIL approaches often lose crucial contextual information, while transformer-based variants, though more expressive, suffer from quadratic complexity and redundant computations. To address these limitations, we propose HookMIL, a context-aware and computationally efficient MIL framework that leverages compact, learnable hook tokens for structured contextual aggregation. These tokens can be initialized from (i) key-patch visual features, (ii) text embeddings from vision-language pathology models, and (iii) spatially grounded features from spatial transcriptomics-vision models. This multimodal initialization enables Hook Tokens to incorporate rich textual and spatial priors, accelerating convergence and enhancing representation quality. During training, Hook tokens interact with instances through bidirectional attention with linear complexity. To further promote specialization, we introduce a Hook Diversity Loss that encourages each token to focus on distinct histopathological patterns. Additionally, a hook-to-hook communication mechanism refines contextual interactions while minimizing redundancy. Extensive experiments on four public pathology datasets demonstrate that HookMIL achieves state-of-the-art performance, with improved computational efficiency and interpretability. Codes are available at https://github.com/lingxitong/HookMIL.
A Closer Look at Personalized Fine-Tuning in Heterogeneous Federated Learning
Nov 16, 2025



Federated Learning (FL) enables decentralized, privacy-preserving model training but struggles to balance global generalization and local personalization due to non-identical data distributions across clients. Personalized Fine-Tuning (PFT), a popular post-hoc solution, fine-tunes the final global model locally but often overfits to skewed client distributions or fails under domain shifts. We propose adapting Linear Probing followed by full Fine-Tuning (LP-FT), a principled centralized strategy for alleviating feature distortion (Kumar et al., 2022), to the FL setting. Through systematic evaluation across seven datasets and six PFT variants, we demonstrate LP-FT's superiority in balancing personalization and generalization. Our analysis uncovers federated feature distortion, a phenomenon where local fine-tuning destabilizes globally learned features, and theoretically characterizes how LP-FT mitigates this via phased parameter updates. We further establish conditions (e.g., partial feature overlap, covariate-concept shift) under which LP-FT outperforms standard fine-tuning, offering actionable guidelines for deploying robust personalization in FL.
Efficient Forward-Only Data Valuation for Pretrained LLMs and VLMs
Aug 13, 2025



Quantifying the influence of individual training samples is essential for enhancing the transparency and accountability of large language models (LLMs) and vision-language models (VLMs). However, existing data valuation methods often rely on Hessian information or model retraining, making them computationally prohibitive for billion-parameter models. In this work, we introduce For-Value, a forward-only data valuation framework that enables scalable and efficient influence estimation for both LLMs and VLMs. By leveraging the rich representations of modern foundation models, For-Value computes influence scores using a simple closed-form expression based solely on a single forward pass, thereby eliminating the need for costly gradient computations. Our theoretical analysis demonstrates that For-Value accurately estimates per-sample influence by capturing alignment in hidden representations and prediction errors between training and validation samples. Extensive experiments show that For-Value matches or outperforms gradient-based baselines in identifying impactful fine-tuning examples and effectively detecting mislabeled data.
On the Effect of Negative Gradient in Group Relative Deep Reinforcement Optimization
May 24, 2025Reinforcement learning (RL) has become popular in enhancing the reasoning capabilities of large language models (LLMs), with Group Relative Policy Optimization (GRPO) emerging as a widely used algorithm in recent systems. Despite GRPO's widespread adoption, we identify a previously unrecognized phenomenon we term Lazy Likelihood Displacement (LLD), wherein the likelihood of correct responses marginally increases or even decreases during training. This behavior mirrors a recently discovered misalignment issue in Direct Preference Optimization (DPO), attributed to the influence of negative gradients. We provide a theoretical analysis of GRPO's learning dynamic, identifying the source of LLD as the naive penalization of all tokens in incorrect responses with the same strength. To address this, we develop a method called NTHR, which downweights penalties on tokens contributing to the LLD. Unlike prior DPO-based approaches, NTHR takes advantage of GRPO's group-based structure, using correct responses as anchors to identify influential tokens. Experiments on math reasoning benchmarks demonstrate that NTHR effectively mitigates LLD, yielding consistent performance gains across models ranging from 0.5B to 3B parameters.
Comprehensive Evaluation of Quantitative Measurements from Automated Deep Segmentations of PSMA PET/CT Images
Apr 22, 2025This study performs a comprehensive evaluation of quantitative measurements as extracted from automated deep-learning-based segmentation methods, beyond traditional Dice Similarity Coefficient assessments, focusing on six quantitative metrics, namely SUVmax, SUVmean, total lesion activity (TLA), tumor volume (TMTV), lesion count, and lesion spread. We analyzed 380 prostate-specific membrane antigen (PSMA) targeted [18F]DCFPyL PET/CT scans of patients with biochemical recurrence of prostate cancer, training deep neural networks, U-Net, Attention U-Net and SegResNet with four loss functions: Dice Loss, Dice Cross Entropy, Dice Focal Loss, and our proposed L1 weighted Dice Focal Loss (L1DFL). Evaluations indicated that Attention U-Net paired with L1DFL achieved the strongest correlation with the ground truth (concordance correlation = 0.90-0.99 for SUVmax and TLA), whereas models employing the Dice Loss and the other two compound losses, particularly with SegResNet, underperformed. Equivalence testing (TOST, alpha = 0.05, Delta = 20%) confirmed high performance for SUV metrics, lesion count and TLA, with L1DFL yielding the best performance. By contrast, tumor volume and lesion spread exhibited greater variability. Bland-Altman, Coverage Probability, and Total Deviation Index analyses further highlighted that our proposed L1DFL minimizes variability in quantification of the ground truth clinical measures. The code is publicly available at: https://github.com/ObedDzik/pca\_segment.git.
MedReason: Eliciting Factual Medical Reasoning Steps in LLMs via Knowledge Graphs
Apr 01, 2025

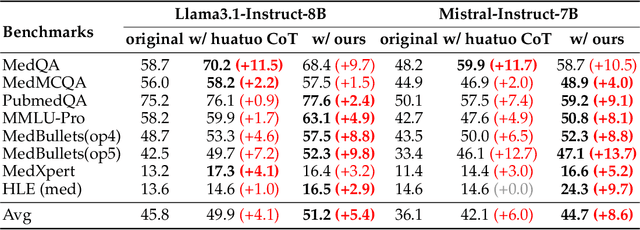
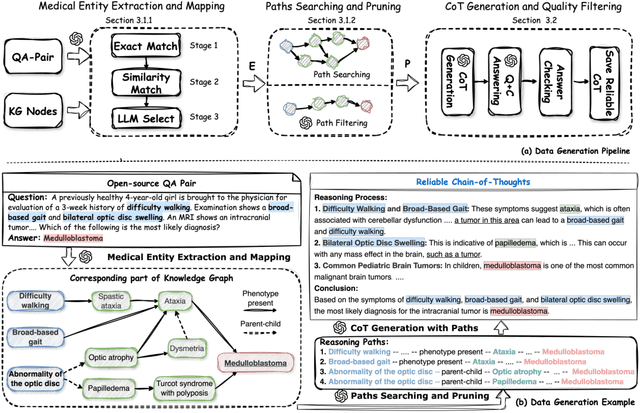
Medical tasks such as diagnosis and treatment planning require precise and complex reasoning, particularly in life-critical domains. Unlike mathematical reasoning, medical reasoning demands meticulous, verifiable thought processes to ensure reliability and accuracy. However, there is a notable lack of datasets that provide transparent, step-by-step reasoning to validate and enhance the medical reasoning ability of AI models. To bridge this gap, we introduce MedReason, a large-scale high-quality medical reasoning dataset designed to enable faithful and explainable medical problem-solving in large language models (LLMs). We utilize a structured medical knowledge graph (KG) to convert clinical QA pairs into logical chains of reasoning, or ``thinking paths'', which trace connections from question elements to answers via relevant KG entities. Each path is validated for consistency with clinical logic and evidence-based medicine. Our pipeline generates detailed reasoning for various medical questions from 7 medical datasets, resulting in a dataset of 32,682 question-answer pairs, each with detailed, step-by-step explanations. Experiments demonstrate that fine-tuning with our dataset consistently boosts medical problem-solving capabilities, achieving significant gains of up to 7.7% for DeepSeek-Ditill-8B. Our top-performing model, MedReason-8B, outperforms the Huatuo-o1-8B, a state-of-the-art medical reasoning model, by up to 4.2% on the clinical benchmark MedBullets. We also engage medical professionals from diverse specialties to assess our dataset's quality, ensuring MedReason offers accurate and coherent medical reasoning. Our data, models, and code will be publicly available.
NeuroLIP: Interpretable and Fair Cross-Modal Alignment of fMRI and Phenotypic Text
Mar 27, 2025



Integrating functional magnetic resonance imaging (fMRI) connectivity data with phenotypic textual descriptors (e.g., disease label, demographic data) holds significant potential to advance our understanding of neurological conditions. However, existing cross-modal alignment methods often lack interpretability and risk introducing biases by encoding sensitive attributes together with diagnostic-related features. In this work, we propose NeuroLIP, a novel cross-modal contrastive learning framework. We introduce text token-conditioned attention (TTCA) and cross-modal alignment via localized tokens (CALT) to the brain region-level embeddings with each disease-related phenotypic token. It improves interpretability via token-level attention maps, revealing brain region-disease associations. To mitigate bias, we propose a loss for sensitive attribute disentanglement that maximizes the attention distance between disease tokens and sensitive attribute tokens, reducing unintended correlations in downstream predictions. Additionally, we incorporate a negative gradient technique that reverses the sign of CALT loss on sensitive attributes, further discouraging the alignment of these features. Experiments on neuroimaging datasets (ABIDE and ADHD-200) demonstrate NeuroLIP's superiority in terms of fairness metrics while maintaining the overall best standard metric performance. Qualitative visualization of attention maps highlights neuroanatomical patterns aligned with diagnostic characteristics, validated by the neuroscientific literature. Our work advances the development of transparent and equitable neuroimaging AI.