 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid U-Net for Retinal Vessel Segmentation
Apr 06, 2021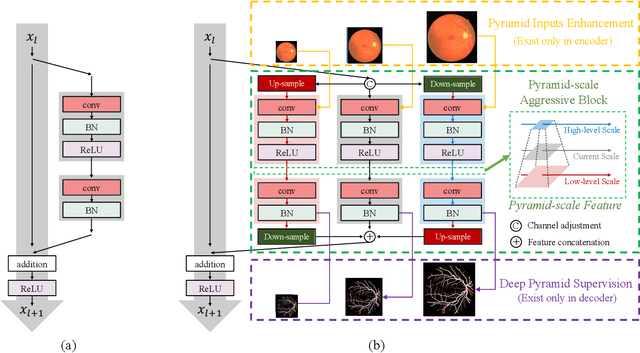
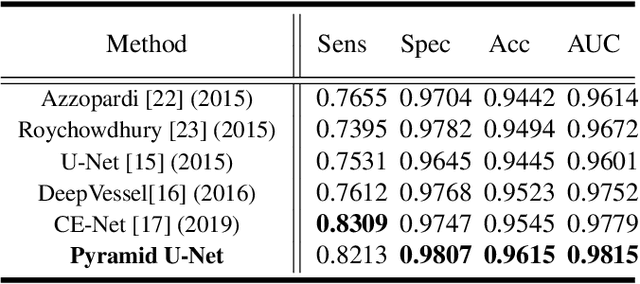
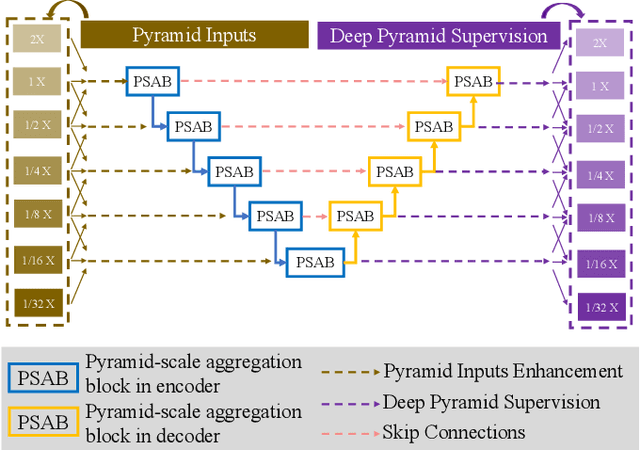

Retinal blood vessel can assist doctors in diagnosis of eye-related diseases such as diabetes and hypertension, and its segmentation is particularly important for automatic retinal image analysis. However, it is challenging to segment these vessels structures, especially the thin capillaries from the color retinal image due to low contrast and ambiguousness. In this paper, we propose pyramid U-Net for accurate retinal vessel segmentation. In pyramid U-Net, the proposed pyramid-scale aggregation blocks (PSABs) are employed in both the encoder and decoder to aggregate features at higher, current and lower levels. In this way, coarse-to-fine context information is shared and aggregated in each block thus to improve the location of capillaries. To further improve performance, two optimizations including pyramid inputs enhancement and deep pyramid supervision are applied to PSABs in the encoder and decoder, respectively. For PSABs in the encoder, scaled input images are added as extra inputs. While for PSABs in the decoder, scaled intermediate outputs are supervised by the scaled segmentation labels. Extensive evaluations show that our pyramid U-Net outperforms the current state-of-the-art methods on the public DRIVE and CHASE-DB1 datasets.
ObjectAug: Object-level Data Augmentation for Semantic Image Segmentation
Jan 30, 2021
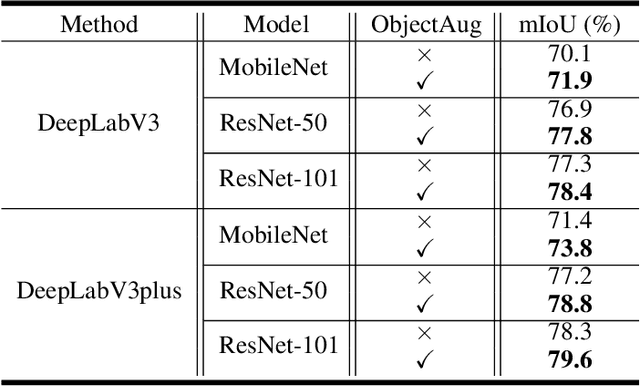

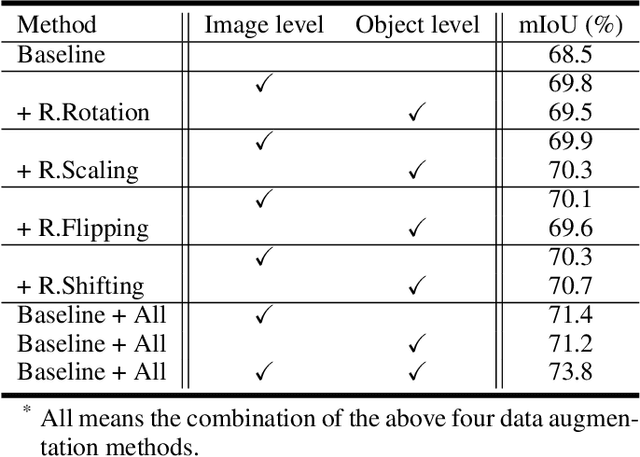
Semantic image segmentation aims to obtain object labels with precise boundaries, which usually suffers from overfitting. Recently, various data augmentation strategies like regional dropout and mix strategies have been proposed to address the problem. These strategies have proved to be effective for guiding the model to attend on less discriminative parts. However, current strategies operate at the image level, and objects and the background are coupled. Thus, the boundaries are not well augmented due to the fixed semantic scenario. In this paper, we propose ObjectAug to perform object-level augmentation for semantic image segmentation. ObjectAug first decouples the image into individual objects and the background using the semantic labels. Next, each object is augmented individually with commonly used augmentation methods (e.g., scaling, shifting, and rotation). Then, the black area brought by object augmentation is further restored using image inpainting. Finally, the augmented objects and background are assembled as an augmented image. In this way, the boundaries can be fully explored in the various semantic scenarios. In addition, ObjectAug can support category-aware augmentation that gives various possibilities to objects in each category, and can be easily combined with existing image-level augmentation methods to further boost performance. Comprehensive experiments are conducted on both natural image and medical image datasets. Experiment results demonstrate that our ObjectAug can evidently improve segmentation performance.
ImageCHD: A 3D Computed Tomography Image Dataset for Classification of Congenital Heart Disease
Jan 26, 2021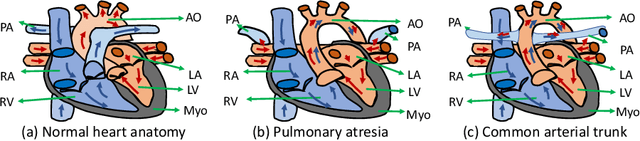
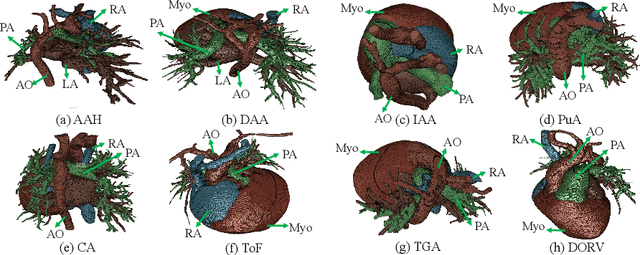
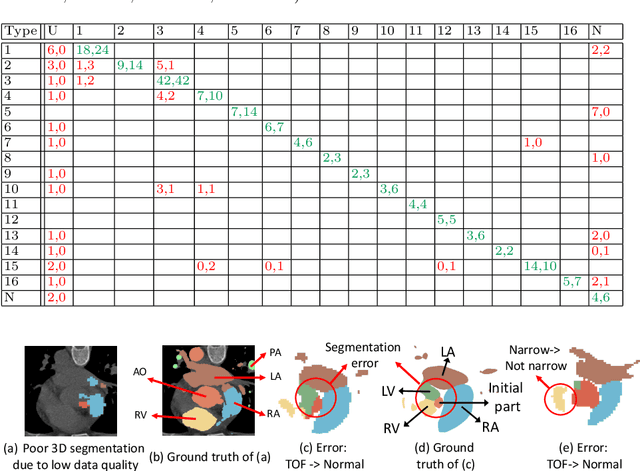
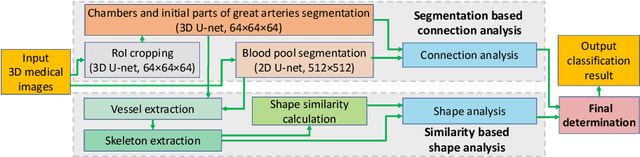
Congenital heart disease (CHD) is the most common type of birth defect, which occurs 1 in every 110 births in the United States. CHD usually comes with severe variations in heart structure and great artery connections that can be classified into many types. Thus highly specialized domain knowledge and the time-consuming human process is needed to analyze the associated medical images. On the other hand, due to the complexity of CHD and the lack of dataset, little has been explored on the automatic diagnosis (classification) of CHDs. In this paper, we present ImageCHD, the first medical image dataset for CHD classification. ImageCHD contains 110 3D Computed Tomography (CT) images covering most types of CHD, which is of decent size Classification of CHDs requires the identification of large structural changes without any local tissue changes, with limited data. It is an example of a larger class of problems that are quite difficult for current machine-learning-based vision methods to solve. To demonstrate this, we further present a baseline framework for the automatic classification of CHD, based on a state-of-the-art CHD segmentation method. Experimental results show that the baseline framework can only achieve a classification accuracy of 82.0\% under a selective prediction scheme with 88.4\% coverage, leaving big room for further improvement. We hope that ImageCHD can stimulate further research and lead to innovative and generic solutions that would have an impact in multiple domains. Our dataset is released to the public compared with existing medical imaging datasets.
Myocardial Segmentation of Cardiac MRI Sequences with Temporal Consistency for Coronary Artery Disease Diagnosis
Dec 29, 2020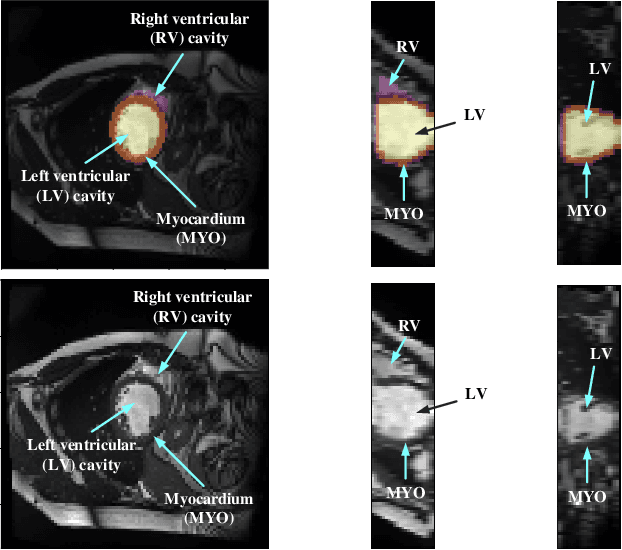
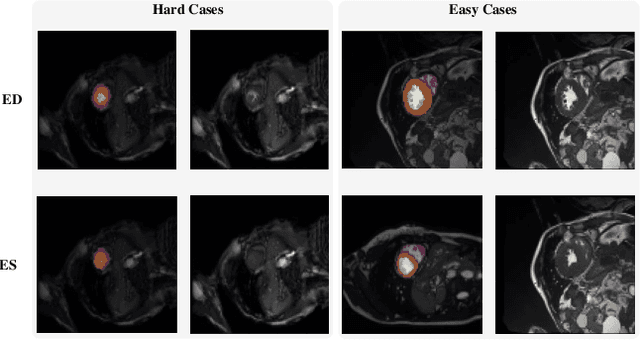
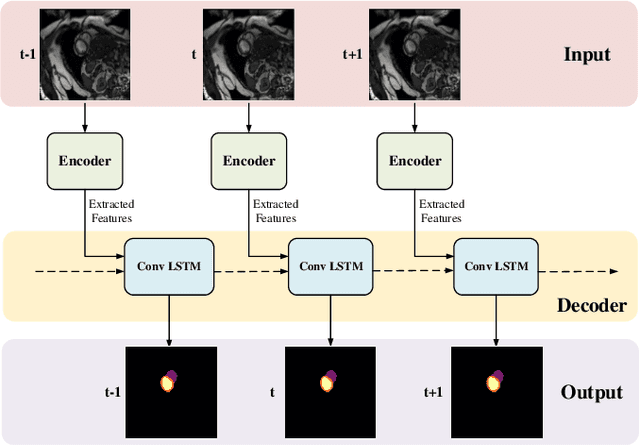
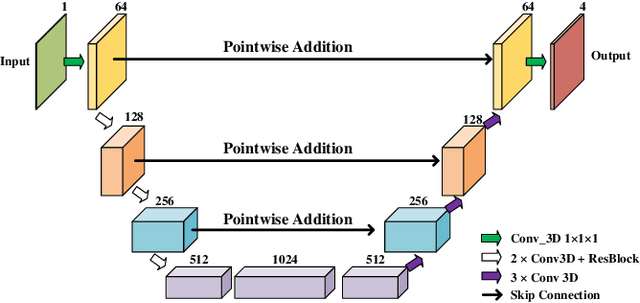
Coronary artery disease (CAD) is the most common cause of death globally, and its diagnosis is usually based on manual myocardial segmentation of Magnetic Resonance Imaging (MRI) sequences. As the manual segmentation is tedious, time-consuming and with low applicability, automatic myocardial segmentation using machine learning techniques has been widely explored recently. However, almost all the existing methods treat the input MRI sequences independently, which fails to capture the temporal information between sequences, e.g., the shape and location information of the myocardium in sequences along time. In this paper, we propose a myocardial segmentation framework for sequence of cardiac MRI (CMR) scanning images of left ventricular cavity, right ventricular cavity, and myocardium. Specifically, we propose to combine conventional networks and recurrent networks to incorporate temporal information between sequences to ensure temporal consistent. We evaluated our framework on the Automated Cardiac Diagnosis Challenge (ACDC) dataset. Experiment results demonstrate that our framework can improve the segmentation accuracy by up to 2% in Dice coefficient.
C2F-FWN: Coarse-to-Fine Flow Warping Network for Spatial-Temporal Consistent Motion Transfer
Dec 16, 2020
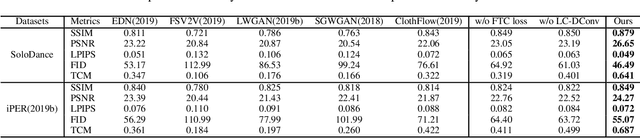
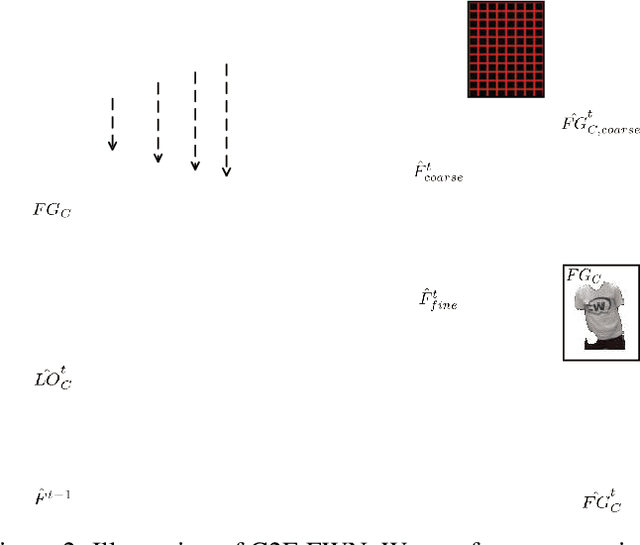
Human video motion transfer (HVMT) aims to synthesize videos that one person imitates other persons' actions. Although existing GAN-based HVMT methods have achieved great success, they either fail to preserve appearance details due to the loss of spatial consistency between synthesized and exemplary images, or generate incoherent video results due to the lack of temporal consistency among video frames. In this paper, we propose Coarse-to-Fine Flow Warping Network (C2F-FWN) for spatial-temporal consistent HVMT. Particularly, C2F-FWN utilizes coarse-to-fine flow warping and Layout-Constrained Deformable Convolution (LC-DConv) to improve spatial consistency, and employs Flow Temporal Consistency (FTC) Loss to enhance temporal consistency. In addition, provided with multi-source appearance inputs, C2F-FWN can support appearance attribute editing with great flexibility and efficiency. Besides public datasets, we also collected a large-scale HVMT dataset named SoloDance for evaluation. Extensive experiments conducted on our SoloDance dataset and the iPER dataset show that our approach outperforms state-of-art HVMT methods in terms of both spatial and temporal consistency. Source code and the SoloDance dataset are available at https://github.com/wswdx/C2F-FWN.
Weakly-Supervised Cross-Domain Adaptation for Endoscopic Lesions Segmentation
Dec 08, 2020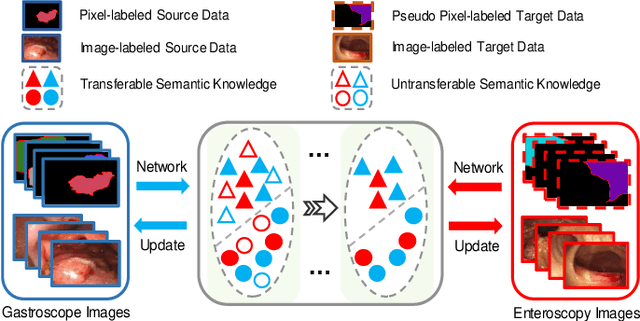
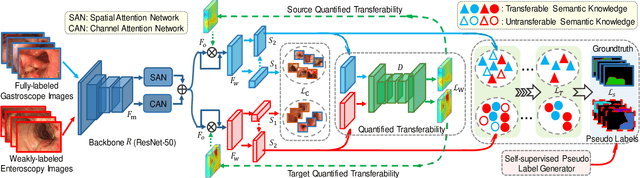
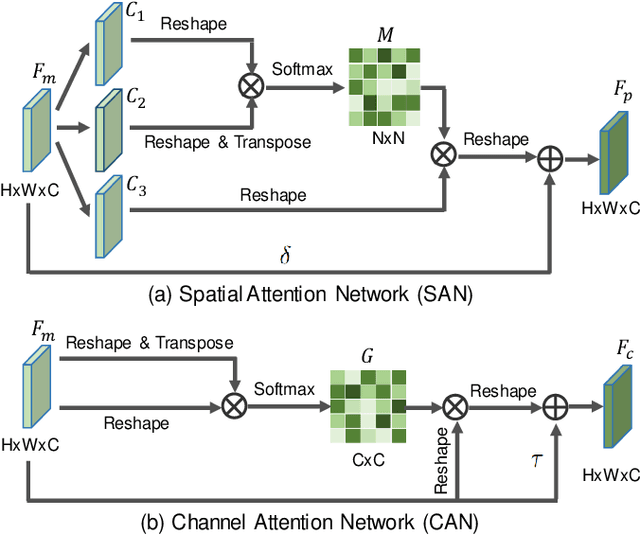
Weakly-supervised learning has attracted growing research attention on medical lesions segmentation due to significant saving in pixel-level annotation cost. However, 1) most existing methods require effective prior and constraints to explore the intrinsic lesions characterization, which only generates incorrect and rough prediction; 2) they neglect the underlying semantic dependencies among weakly-labeled target enteroscopy diseases and fully-annotated source gastroscope lesions, while forcefully utilizing untransferable dependencies leads to the negative performance. To tackle above issues, we propose a new weakly-supervised lesions transfer framework, which can not only explore transferable domain-invariant knowledge across different datasets, but also prevent the negative transfer of untransferable representations. Specifically, a Wasserstein quantified transferability framework is developed to highlight widerange transferable contextual dependencies, while neglecting the irrelevant semantic characterizations. Moreover, a novel selfsupervised pseudo label generator is designed to equally provide confident pseudo pixel labels for both hard-to-transfer and easyto-transfer target samples. It inhibits the enormous deviation of false pseudo pixel labels under the self-supervision manner. Afterwards, dynamically-searched feature centroids are aligned to narrow category-wise distribution shift. Comprehensive theoretical analysis and experiments show the superiority of our model on the endoscopic dataset and several public datasets.
Do Noises Bother Human and Neural Networks In the Same Way? A Medical Image Analysis Perspective
Nov 04, 2020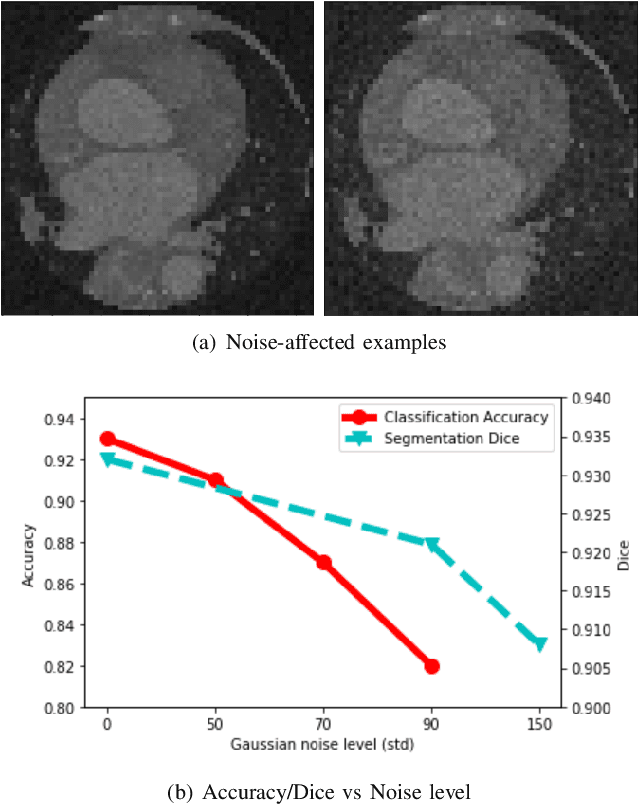
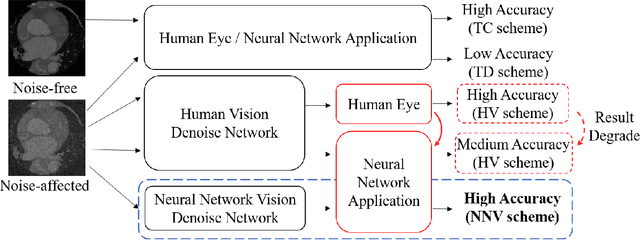
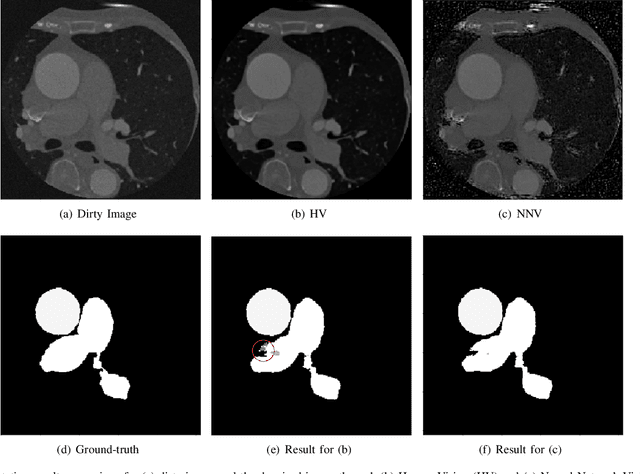
Deep learning had already demonstrated its power in medical images, including denoising, classification, segmentation, etc. All these applications are proposed to automatically analyze medical images beforehand, which brings more information to radiologists during clinical assessment for accuracy improvement. Recently, many medical denoising methods had shown their significant artifact reduction result and noise removal both quantitatively and qualitatively. However, those existing methods are developed around human-vision, i.e., they are designed to minimize the noise effect that can be perceived by human eyes. In this paper, we introduce an application-guided denoising framework, which focuses on denoising for the following neural networks. In our experiments, we apply the proposed framework to different datasets, models, and use cases. Experimental results show that our proposed framework can achieve a better result than human-vision denoising network.
CSCL: Critical Semantic-Consistent Learning for Unsupervised Domain Adaptation
Aug 24, 2020
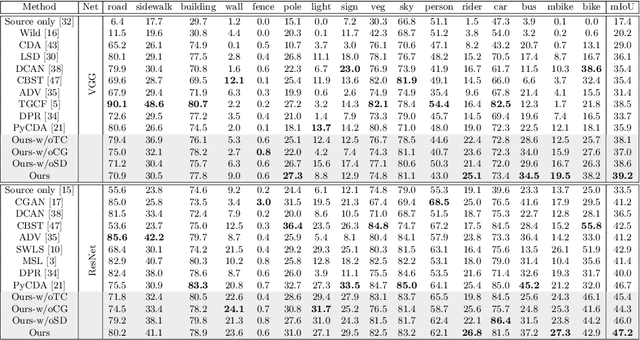
Unsupervised domain adaptation without consuming annotation process for unlabeled target data attracts appealing interests in semantic segmentation. However, 1) existing methods neglect that not all semantic representations across domains are transferable, which cripples domain-wise transfer with untransferable knowledge; 2) they fail to narrow category-wise distribution shift due to category-agnostic feature alignment. To address above challenges, we develop a new Critical Semantic-Consistent Learning (CSCL) model, which mitigates the discrepancy of both domain-wise and category-wise distributions. Specifically, a critical transfer based adversarial framework is designed to highlight transferable domain-wise knowledge while neglecting untransferable knowledge. Transferability-critic guides transferability-quantizer to maximize positive transfer gain under reinforcement learning manner, although negative transfer of untransferable knowledge occurs. Meanwhile, with the help of confidence-guided pseudo labels generator of target samples, a symmetric soft divergence loss is presented to explore inter-class relationships and facilitate category-wise distribution alignment. Experiments on several datasets demonstrate the superiority of our model.
Towards Cardiac Intervention Assistance: Hardware-aware Neural Architecture Exploration for Real-Time 3D Cardiac Cine MRI Segmentation
Aug 17, 2020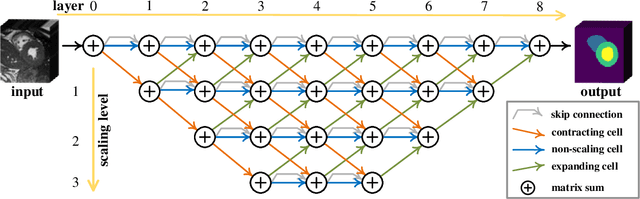
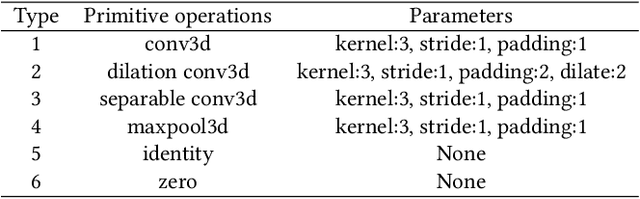
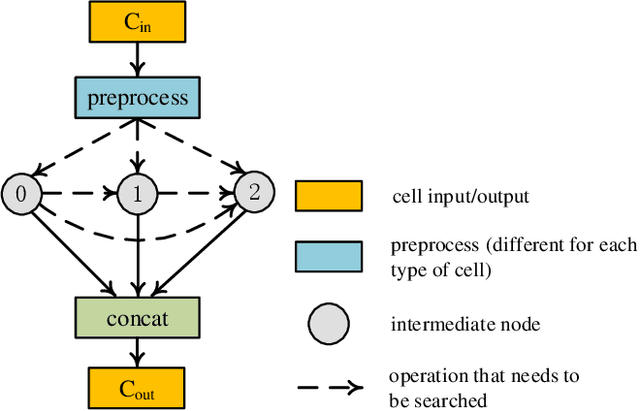
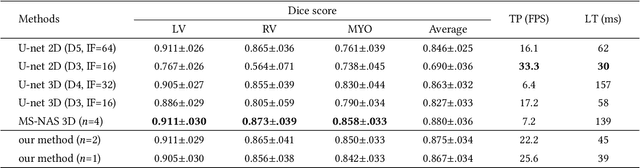
Real-time cardiac magnetic resonance imaging (MRI) plays an increasingly important role in guiding various cardiac interventions. In order to provide better visual assistance, the cine MRI frames need to be segmented on-the-fly to avoid noticeable visual lag. In addition, considering reliability and patient data privacy, the computation is preferably done on local hardware. State-of-the-art MRI segmentation methods mostly focus on accuracy only, and can hardly be adopted for real-time application or on local hardware. In this work, we present the first hardware-aware multi-scale neural architecture search (NAS) framework for real-time 3D cardiac cine MRI segmentation. The proposed framework incorporates a latency regularization term into the loss function to handle real-time constraints, with the consideration of underlying hardware. In addition, the formulation is fully differentiable with respect to the architecture parameters, so that stochastic gradient descent (SGD) can be used for optimization to reduce the computation cost while maintaining optimization quality. Experimental results on ACDC MICCAI 2017 dataset demonstrate that our hardware-aware multi-scale NAS framework can reduce the latency by up to 3.5 times and satisfy the real-time constraints, while still achieving competitive segmentation accuracy, compared with the state-of-the-art NAS segmentation framework.
ICA-UNet: ICA Inspired Statistical UNet for Real-time 3D Cardiac Cine MRI Segmentation
Jul 18, 2020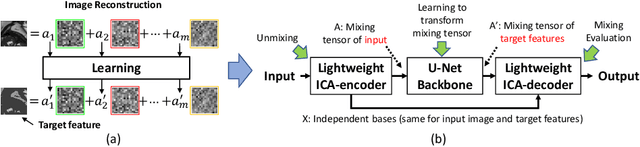
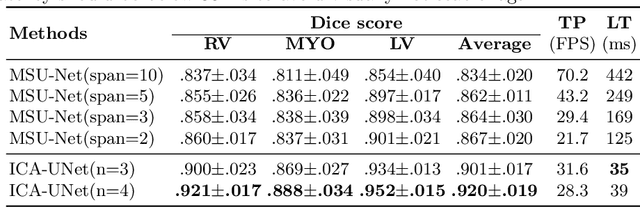
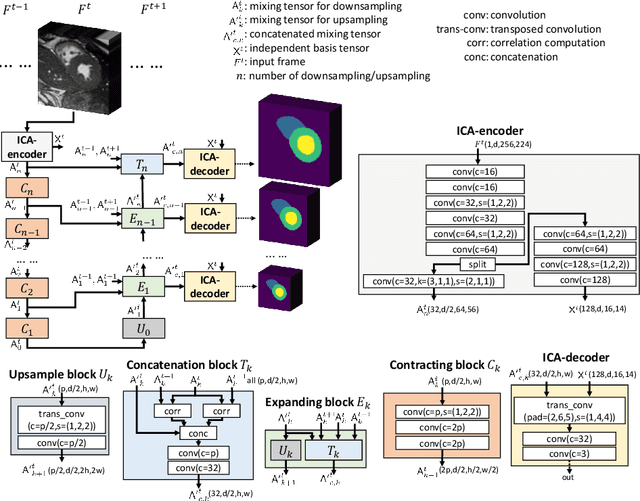
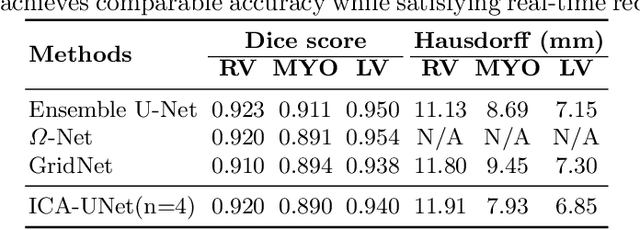
Real-time cine magnetic resonance imaging (MRI) plays an increasingly important role in various cardiac interventions. In order to enable fast and accurate visual assistance, the temporal frames need to be segmented on-the-fly. However, state-of-the-art MRI segmentation methods are used either offline because of their high computation complexity, or in real-time but with significant accuracy loss and latency increase (causing visually noticeable lag). As such, they can hardly be adopted to assist visual guidance. In this work, inspired by a new interpretation of Independent Component Analysis (ICA) for learning, we propose a novel ICA-UNet for real-time 3D cardiac cine MRI segmentation. Experiments using the MICCAI ACDC 2017 dataset show that, compared with the state-of-the-arts, ICA-UNet not only achieves higher Dice scores, but also meets the real-time requirements for both throughput and latency (up to 12.6X reduction), enabling real-time guidance for cardiac interventions without visual lag.