 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRT-DNAS: Real-time Constrained Differentiable Neural Architecture Search for 3D Cardiac Cine MRI Segmentation
Jun 13, 2022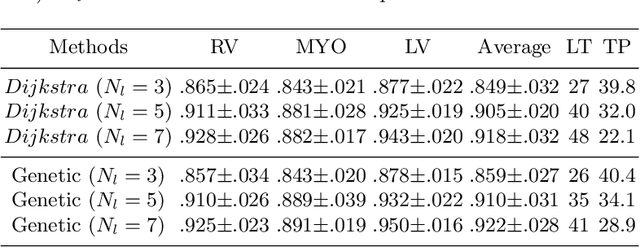

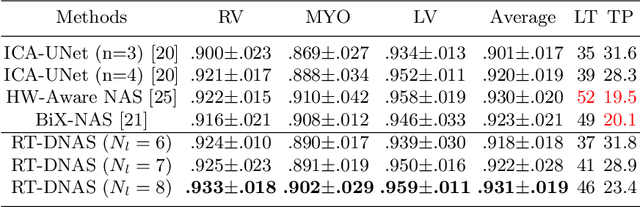
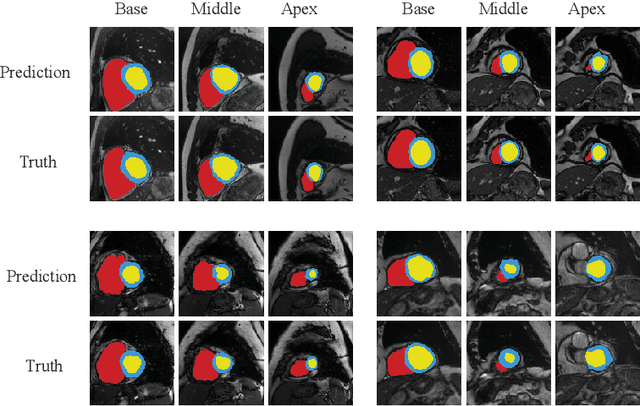
Accurately segmenting temporal frames of cine magnetic resonance imaging (MRI) is a crucial step in various real-time MRI guided cardiac interventions. To achieve fast and accurate visual assistance, there are strict requirements on the maximum latency and minimum throughput of the segmentation framework. State-of-the-art neural networks on this task are mostly hand-crafted to satisfy these constraints while achieving high accuracy. On the other hand, while existing literature have demonstrated the power of neural architecture search (NAS) in automatically identifying the best neural architectures for various medical applications, they are mostly guided by accuracy, sometimes with computation complexity, and the importance of real-time constraints are overlooked. A major challenge is that such constraints are non-differentiable and are thus not compatible with the widely used differentiable NAS frameworks. In this paper, we present a strategy that directly handles real-time constraints in a differentiable NAS framework named RT-DNAS. Experiments on extended 2017 MICCAI ACDC dataset show that compared with state-of-the-art manually and automatically designed architectures, RT-DNAS is able to identify ones with better accuracy while satisfying the real-time constraints.
FairPrune: Achieving Fairness Through Pruning for Dermatological Disease Diagnosis
Mar 04, 2022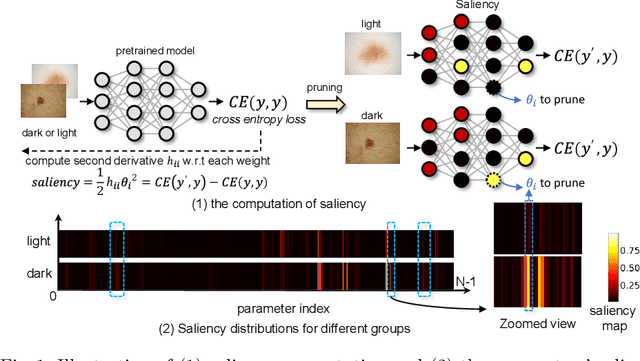
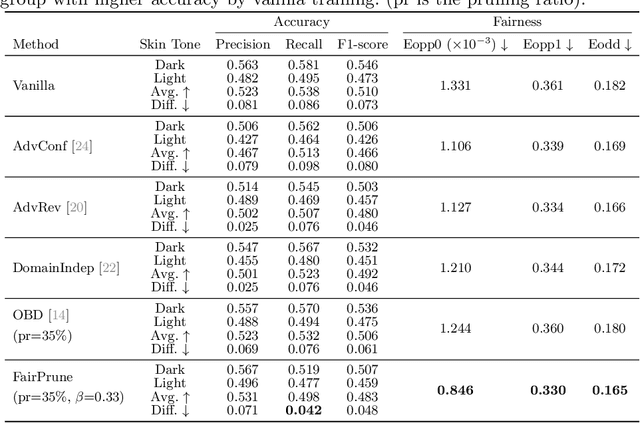
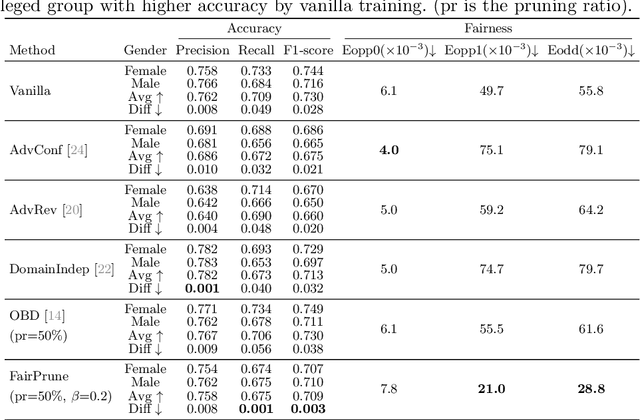
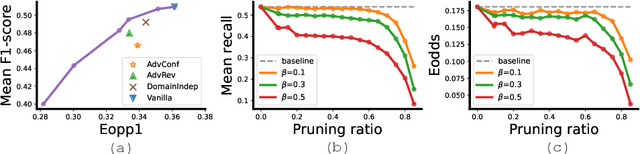
Many works have shown that deep learning-based medical image classification models can exhibit bias toward certain demographic attributes like race, gender, and age. Existing bias mitigation methods primarily focus on learning debiased models, which may not necessarily guarantee all sensitive information can be removed and usually comes with considerable accuracy degradation on both privileged and unprivileged groups. To tackle this issue, we propose a method, FairPrune, that achieves fairness by pruning. Conventionally, pruning is used to reduce the model size for efficient inference. However, we show that pruning can also be a powerful tool to achieve fairness. Our observation is that during pruning, each parameter in the model has different importance for different groups' accuracy. By pruning the parameters based on this importance difference, we can reduce the accuracy difference between the privileged group and the unprivileged group to improve fairness without a large accuracy drop. To this end, we use the second derivative of the parameters of a pre-trained model to quantify the importance of each parameter with respect to the model accuracy for each group. Experiments on two skin lesion diagnosis datasets over multiple sensitive attributes demonstrate that our method can greatly improve fairness while keeping the average accuracy of both groups as high as possible.
"One-Shot" Reduction of Additive Artifacts in Medical Images
Oct 23, 2021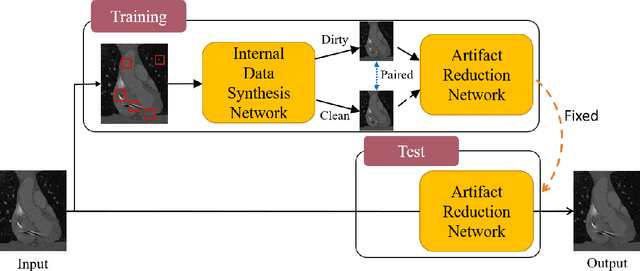
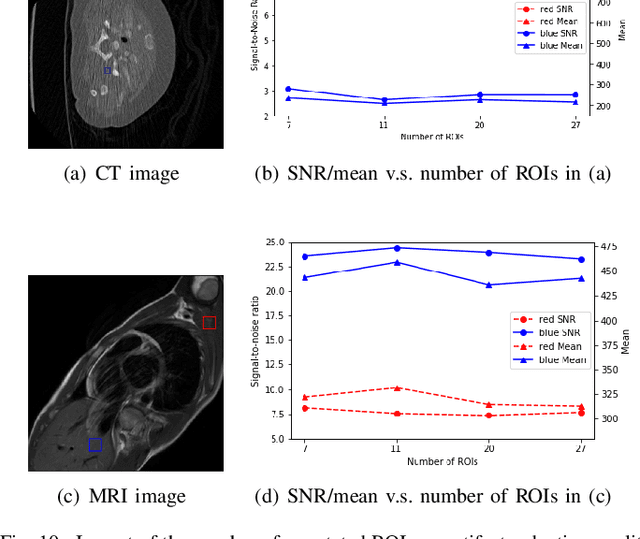

Medical images may contain various types of artifacts with different patterns and mixtures, which depend on many factors such as scan setting, machine condition, patients' characteristics, surrounding environment, etc. However, existing deep-learning-based artifact reduction methods are restricted by their training set with specific predetermined artifact types and patterns. As such, they have limited clinical adoption. In this paper, we introduce One-Shot medical image Artifact Reduction (OSAR), which exploits the power of deep learning but without using pre-trained general networks. Specifically, we train a light-weight image-specific artifact reduction network using data synthesized from the input image at test-time. Without requiring any prior large training data set, OSAR can work with almost any medical images that contain varying additive artifacts which are not in any existing data sets. In addition, Computed Tomography (CT) and Magnetic Resonance Imaging (MRI) are used as vehicles and show that the proposed method can reduce artifacts better than state-of-the-art both qualitatively and quantitatively using shorter test time.
Multi-Layer Pseudo-Supervision for Histopathology Tissue Semantic Segmentation using Patch-level Classification Labels
Oct 14, 2021

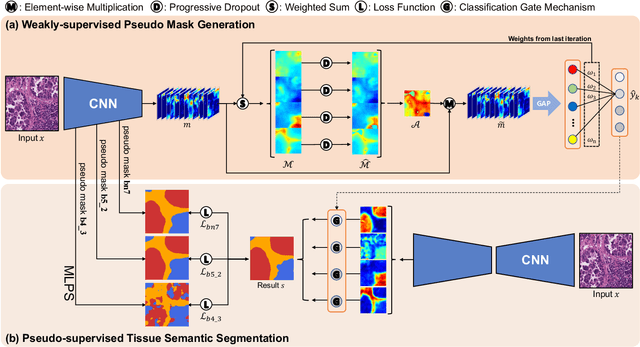
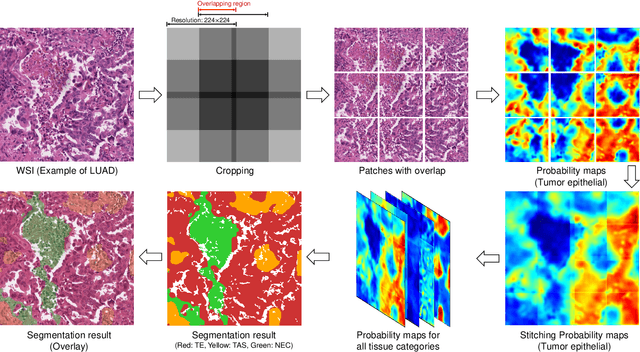
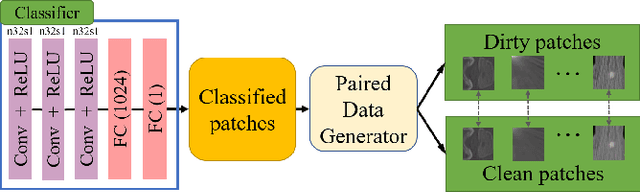
Tissue-level semantic segmentation is a vital step in computational pathology. Fully-supervised models have already achieved outstanding performance with dense pixel-level annotations. However, drawing such labels on the giga-pixel whole slide images is extremely expensive and time-consuming. In this paper, we use only patch-level classification labels to achieve tissue semantic segmentation on histopathology images, finally reducing the annotation efforts. We proposed a two-step model including a classification and a segmentation phases. In the classification phase, we proposed a CAM-based model to generate pseudo masks by patch-level labels. In the segmentation phase, we achieved tissue semantic segmentation by our proposed Multi-Layer Pseudo-Supervision. Several technical novelties have been proposed to reduce the information gap between pixel-level and patch-level annotations. As a part of this paper, we introduced a new weakly-supervised semantic segmentation (WSSS) dataset for lung adenocarcinoma (LUAD-HistoSeg). We conducted several experiments to evaluate our proposed model on two datasets. Our proposed model outperforms two state-of-the-art WSSS approaches. Note that we can achieve comparable quantitative and qualitative results with the fully-supervised model, with only around a 2\% gap for MIoU and FwIoU. By comparing with manual labeling, our model can greatly save the annotation time from hours to minutes. The source code is available at: \url{https://github.com/ChuHan89/WSSS-Tissue}.
Semi-supervised Contrastive Learning for Label-efficient Medical Image Segmentation
Sep 28, 2021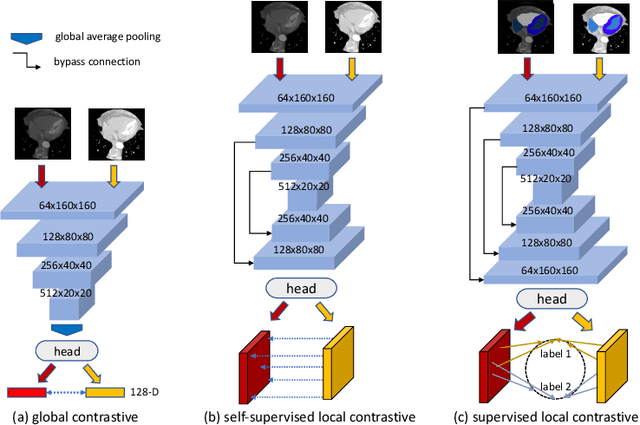
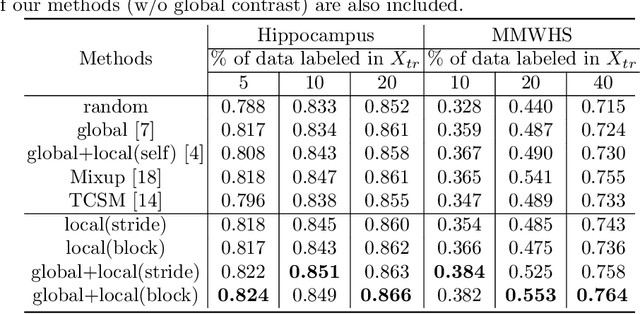
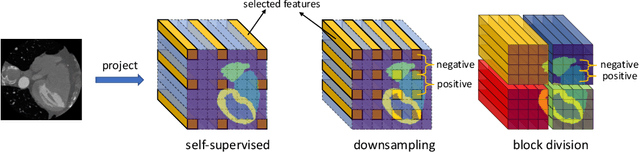
The success of deep learning methods in medical image segmentation tasks heavily depends on a large amount of labeled data to supervise the training. On the other hand, the annotation of biomedical images requires domain knowledge and can be laborious. Recently, contrastive learning has demonstrated great potential in learning latent representation of images even without any label. Existing works have explored its application to biomedical image segmentation where only a small portion of data is labeled, through a pre-training phase based on self-supervised contrastive learning without using any labels followed by a supervised fine-tuning phase on the labeled portion of data only. In this paper, we establish that by including the limited label in formation in the pre-training phase, it is possible to boost the performance of contrastive learning. We propose a supervised local contrastive loss that leverages limited pixel-wise annotation to force pixels with the same label to gather around in the embedding space. Such loss needs pixel-wise computation which can be expensive for large images, and we further propose two strategies, downsampling and block division, to address the issue. We evaluate our methods on two public biomedical image datasets of different modalities. With different amounts of labeled data, our methods consistently outperform the state-of-the-art contrast-based methods and other semi-supervised learning techniques.
Hardware-aware Real-time Myocardial Segmentation Quality Control in Contrast Echocardiography
Sep 14, 2021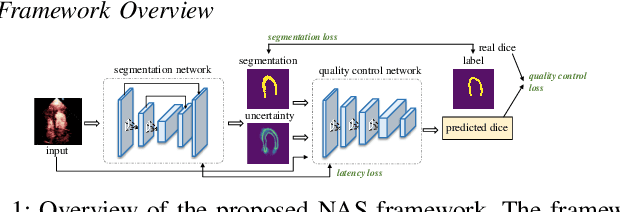
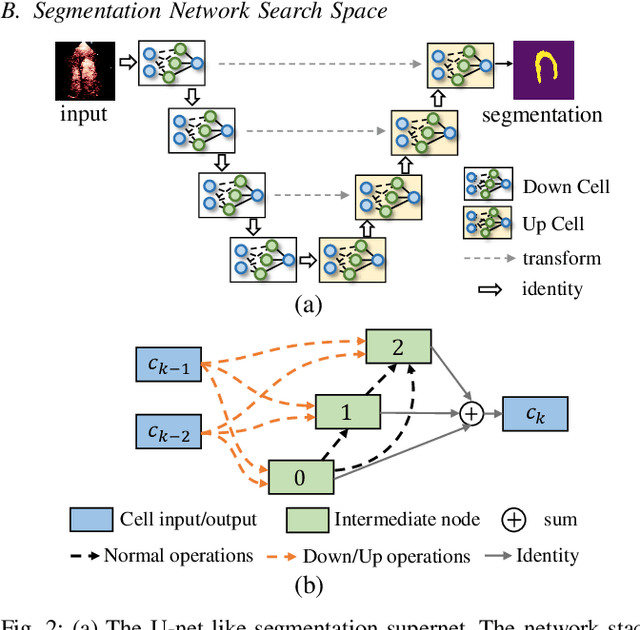
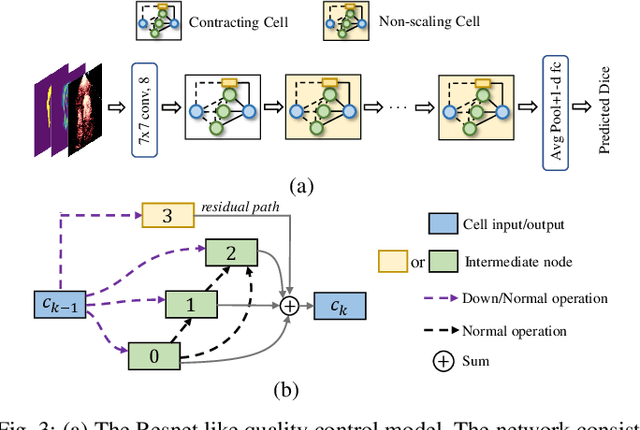
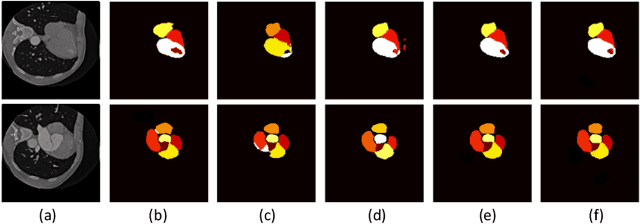
Automatic myocardial segmentation of contrast echocardiography has shown great potential in the quantification of myocardial perfusion parameters. Segmentation quality control is an important step to ensure the accuracy of segmentation results for quality research as well as its clinical application. Usually, the segmentation quality control happens after the data acquisition. At the data acquisition time, the operator could not know the quality of the segmentation results. On-the-fly segmentation quality control could help the operator to adjust the ultrasound probe or retake data if the quality is unsatisfied, which can greatly reduce the effort of time-consuming manual correction. However, it is infeasible to deploy state-of-the-art DNN-based models because the segmentation module and quality control module must fit in the limited hardware resource on the ultrasound machine while satisfying strict latency constraints. In this paper, we propose a hardware-aware neural architecture search framework for automatic myocardial segmentation and quality control of contrast echocardiography. We explicitly incorporate the hardware latency as a regularization term into the loss function during training. The proposed method searches the best neural network architecture for the segmentation module and quality prediction module with strict latency.
ImageTBAD: A 3D Computed Tomography Angiography Image Dataset for Automatic Segmentation of Type-B Aortic Dissection
Sep 01, 2021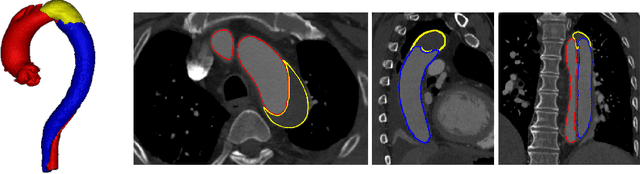
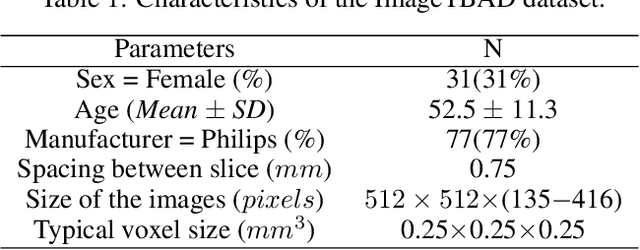

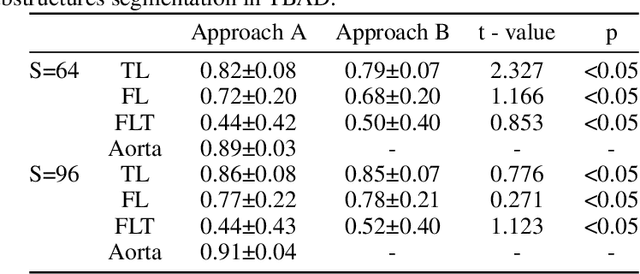
Type-B Aortic Dissection (TBAD) is one of the most serious cardiovascular events characterized by a growing yearly incidence,and the severity of disease prognosis. Currently, computed tomography angiography (CTA) has been widely adopted for the diagnosis and prognosis of TBAD. Accurate segmentation of true lumen (TL), false lumen (FL), and false lumen thrombus (FLT) in CTA are crucial for the precise quantification of anatomical features. However, existing works only focus on only TL and FL without considering FLT. In this paper, we propose ImageTBAD, the first 3D computed tomography angiography (CTA) image dataset of TBAD with annotation of TL, FL, and FLT. The proposed dataset contains 100 TBAD CTA images, which is of decent size compared with existing medical imaging datasets. As FLT can appear almost anywhere along the aorta with irregular shapes, segmentation of FLT presents a wide class of segmentation problems where targets exist in a variety of positions with irregular shapes. We further propose a baseline method for automatic segmentation of TBAD. Results show that the baseline method can achieve comparable results with existing works on aorta and TL segmentation. However, the segmentation accuracy of FLT is only 52%, which leaves large room for improvement and also shows the challenge of our dataset. To facilitate further research on this challenging problem, our dataset and codes are released to the public.
Segmentation with Multiple Acceptable Annotations: A Case Study of Myocardial Segmentation in Contrast Echocardiography
Jun 29, 2021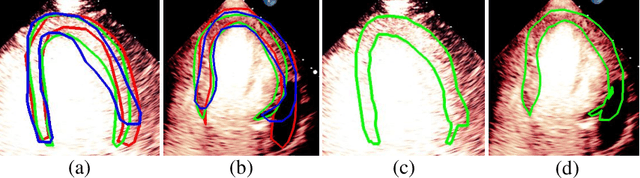
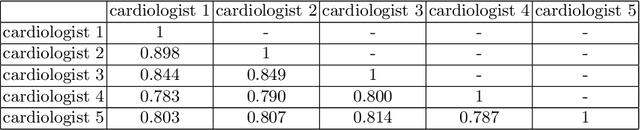
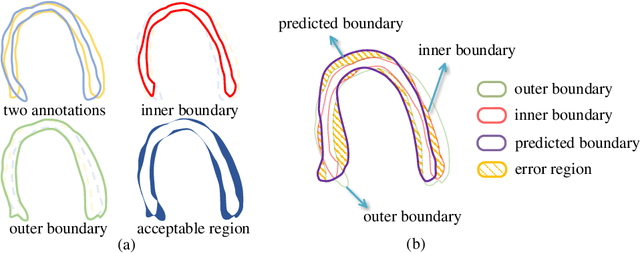
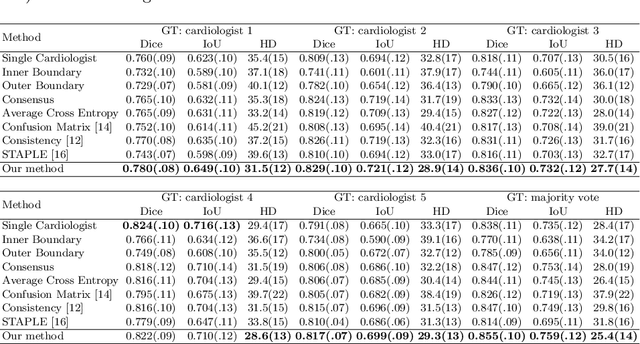
Most existing deep learning-based frameworks for image segmentation assume that a unique ground truth is known and can be used for performance evaluation. This is true for many applications, but not all. Myocardial segmentation of Myocardial Contrast Echocardiography (MCE), a critical task in automatic myocardial perfusion analysis, is an example. Due to the low resolution and serious artifacts in MCE data, annotations from different cardiologists can vary significantly, and it is hard to tell which one is the best. In this case, how can we find a good way to evaluate segmentation performance and how do we train the neural network? In this paper, we address the first problem by proposing a new extended Dice to effectively evaluate the segmentation performance when multiple accepted ground truth is available. Then based on our proposed metric, we solve the second problem by further incorporating the new metric into a loss function that enables neural networks to flexibly learn general features of myocardium. Experiment results on our clinical MCE data set demonstrate that the neural network trained with the proposed loss function outperforms those existing ones that try to obtain a unique ground truth from multiple annotations, both quantitatively and qualitatively. Finally, our grading study shows that using extended Dice as an evaluation metric can better identify segmentation results that need manual correction compared with using Dice.
Positional Contrastive Learning for Volumetric Medical Image Segmentation
Jun 18, 2021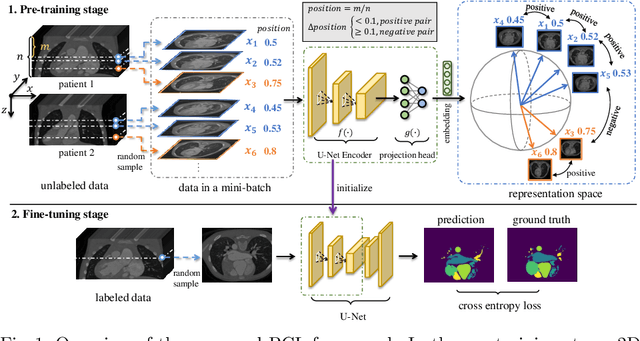
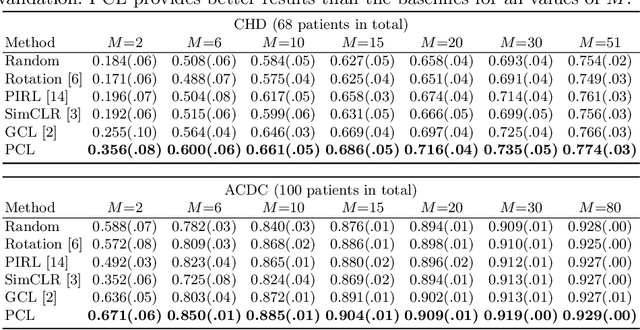
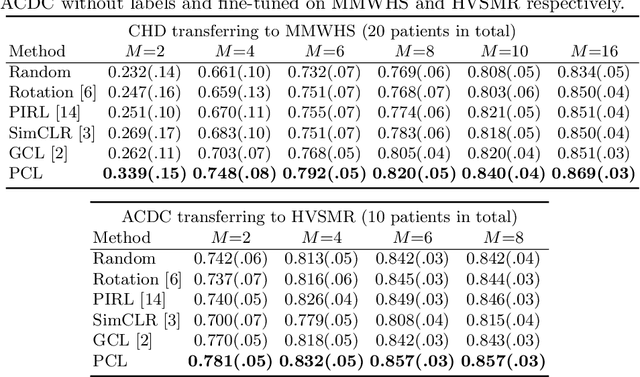
The success of deep learning heavily depends on the availability of large labeled training sets. However, it is hard to get large labeled datasets in medical image domain because of the strict privacy concern and costly labeling efforts. Contrastive learning, an unsupervised learning technique, has been proved powerful in learning image-level representations from unlabeled data. The learned encoder can then be transferred or fine-tuned to improve the performance of downstream tasks with limited labels. A critical step in contrastive learning is the generation of contrastive data pairs, which is relatively simple for natural image classification but quite challenging for medical image segmentation due to the existence of the same tissue or organ across the dataset. As a result, when applied to medical image segmentation, most state-of-the-art contrastive learning frameworks inevitably introduce a lot of false-negative pairs and result in degraded segmentation quality. To address this issue, we propose a novel positional contrastive learning (PCL) framework to generate contrastive data pairs by leveraging the position information in volumetric medical images. Experimental results on CT and MRI datasets demonstrate that the proposed PCL method can substantially improve the segmentation performance compared to existing methods in both semi-supervised setting and transfer learning setting.
EchoCP: An Echocardiography Dataset in Contrast Transthoracic Echocardiography for Patent Foramen Ovale Diagnosis
May 18, 2021
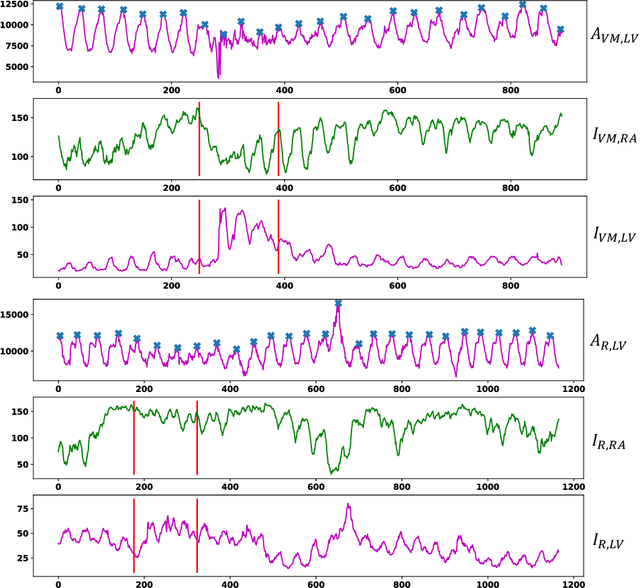
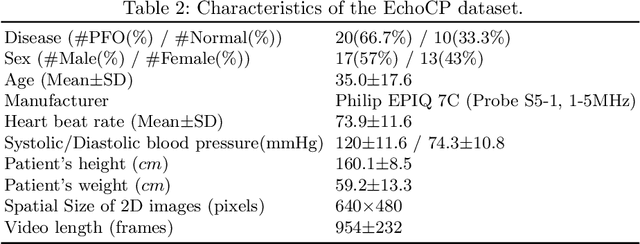
Patent foramen ovale (PFO) is a potential separation between the septum, primum and septum secundum located in the anterosuperior portion of the atrial septum. PFO is one of the main factors causing cryptogenic stroke which is the fifth leading cause of death in the United States. For PFO diagnosis, contrast transthoracic echocardiography (cTTE) is preferred as being a more robust method compared with others. However, the current PFO diagnosis through cTTE is extremely slow as it is proceeded manually by sonographers on echocardiography videos. Currently there is no publicly available dataset for this important topic in the community. In this paper, we present EchoCP, as the first echocardiography dataset in cTTE targeting PFO diagnosis. EchoCP consists of 30 patients with both rest and Valsalva maneuver videos which covers various PFO grades. We further establish an automated baseline method for PFO diagnosis based on the state-of-the-art cardiac chamber segmentation technique, which achieves 0.89 average mean Dice score, but only 0.70/0.67 mean accuracies for PFO diagnosis, leaving large room for improvement. We hope that the challenging EchoCP dataset can stimulate further research and lead to innovative and generic solutions that would have an impact in multiple domains. Our dataset is released.