 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReshaping the Online Data Buffering and Organizing Mechanism for Continual Test-Time Adaptation
Jul 12, 2024



Continual Test-Time Adaptation (CTTA) involves adapting a pre-trained source model to continually changing unsupervised target domains. In this paper, we systematically analyze the challenges of this task: online environment, unsupervised nature, and the risks of error accumulation and catastrophic forgetting under continual domain shifts. To address these challenges, we reshape the online data buffering and organizing mechanism for CTTA. We propose an {uncertainty-aware buffering approach} to identify {and aggregate} significant samples with high certainty from the unsupervised, single-pass data stream. {Based on this}, we propose a graph-based class relation preservation constraint to overcome catastrophic forgetting. Furthermore, a pseudo-target replay objective is used to mitigate error accumulation. Extensive experiments demonstrate the superiority of our method in both segmentation and classification CTTA tasks. Code is available at \href{https://github.com/z1358/OBAO}{this https URL}.
Multi-modal Crowd Counting via a Broker Modality
Jul 10, 2024Multi-modal crowd counting involves estimating crowd density from both visual and thermal/depth images. This task is challenging due to the significant gap between these distinct modalities. In this paper, we propose a novel approach by introducing an auxiliary broker modality and on this basis frame the task as a triple-modal learning problem. We devise a fusion-based method to generate this broker modality, leveraging a non-diffusion, lightweight counterpart of modern denoising diffusion-based fusion models. Additionally, we identify and address the ghosting effect caused by direct cross-modal image fusion in multi-modal crowd counting. Through extensive experimental evaluations on popular multi-modal crowd-counting datasets, we demonstrate the effectiveness of our method, which introduces only 4 million additional parameters, yet achieves promising results. The code is available at https://github.com/HenryCilence/Broker-Modality-Crowd-Counting.
GLAD: Towards Better Reconstruction with Global and Local Adaptive Diffusion Models for Unsupervised Anomaly Detection
Jun 11, 2024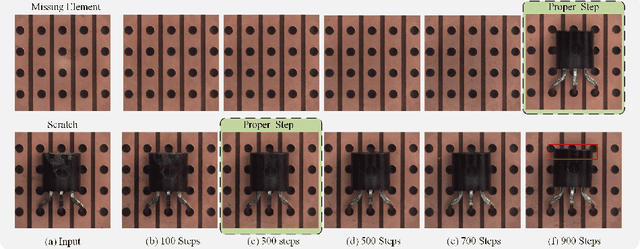
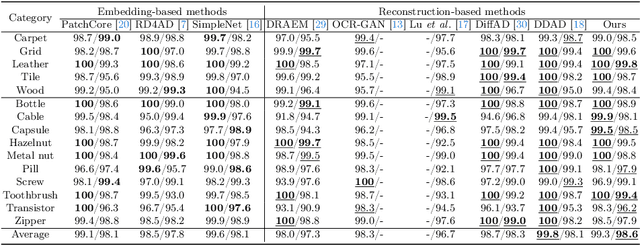

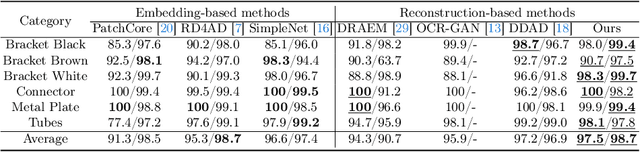
Diffusion models have shown superior performance on unsupervised anomaly detection tasks. Since trained with normal data only, diffusion models tend to reconstruct normal counterparts of test images with certain noises added. However, these methods treat all potential anomalies equally, which may cause two main problems. From the global perspective, the difficulty of reconstructing images with different anomalies is uneven. Therefore, instead of utilizing the same setting for all samples, we propose to predict a particular denoising step for each sample by evaluating the difference between image contents and the priors extracted from diffusion models. From the local perspective, reconstructing abnormal regions differs from normal areas even in the same image. Theoretically, the diffusion model predicts a noise for each step, typically following a standard Gaussian distribution. However, due to the difference between the anomaly and its potential normal counterpart, the predicted noise in abnormal regions will inevitably deviate from the standard Gaussian distribution. To this end, we propose introducing synthetic abnormal samples in training to encourage the diffusion models to break through the limitation of standard Gaussian distribution, and a spatial-adaptive feature fusion scheme is utilized during inference. With the above modifications, we propose a global and local adaptive diffusion model (abbreviated to GLAD) for unsupervised anomaly detection, which introduces appealing flexibility and achieves anomaly-free reconstruction while retaining as much normal information as possible. Extensive experiments are conducted on three commonly used anomaly detection datasets (MVTec-AD, MPDD, and VisA) and a printed circuit board dataset (PCB-Bank) we integrated, showing the effectiveness of the proposed method.
Image Captioning via Dynamic Path Customization
Jun 01, 2024



This paper explores a novel dynamic network for vision and language tasks, where the inferring structure is customized on the fly for different inputs. Most previous state-of-the-art approaches are static and hand-crafted networks, which not only heavily rely on expert knowledge, but also ignore the semantic diversity of input samples, therefore resulting in suboptimal performance. To address these issues, we propose a novel Dynamic Transformer Network (DTNet) for image captioning, which dynamically assigns customized paths to different samples, leading to discriminative yet accurate captions. Specifically, to build a rich routing space and improve routing efficiency, we introduce five types of basic cells and group them into two separate routing spaces according to their operating domains, i.e., spatial and channel. Then, we design a Spatial-Channel Joint Router (SCJR), which endows the model with the capability of path customization based on both spatial and channel information of the input sample. To validate the effectiveness of our proposed DTNet, we conduct extensive experiments on the MS-COCO dataset and achieve new state-of-the-art performance on both the Karpathy split and the online test server.
Prompt Customization for Continual Learning
Apr 28, 2024



Contemporary continual learning approaches typically select prompts from a pool, which function as supplementary inputs to a pre-trained model. However, this strategy is hindered by the inherent noise of its selection approach when handling increasing tasks. In response to these challenges, we reformulate the prompting approach for continual learning and propose the prompt customization (PC) method. PC mainly comprises a prompt generation module (PGM) and a prompt modulation module (PMM). In contrast to conventional methods that employ hard prompt selection, PGM assigns different coefficients to prompts from a fixed-sized pool of prompts and generates tailored prompts. Moreover, PMM further modulates the prompts by adaptively assigning weights according to the correlations between input data and corresponding prompts. We evaluate our method on four benchmark datasets for three diverse settings, including the class, domain, and task-agnostic incremental learning tasks. Experimental results demonstrate consistent improvement (by up to 16.2\%), yielded by the proposed method, over the state-of-the-art (SOTA) techniques.
SpikeMba: Multi-Modal Spiking Saliency Mamba for Temporal Video Grounding
Apr 01, 2024Temporal video grounding (TVG) is a critical task in video content understanding. Despite significant advancements, existing methods often limit in capturing the fine-grained relationships between multimodal inputs and the high computational costs with processing long video sequences. To address these limitations, we introduce a novel SpikeMba: multi-modal spiking saliency mamba for temporal video grounding. In our work, we integrate the Spiking Neural Networks (SNNs) and state space models (SSMs) to capture the fine-grained relationships of multimodal features effectively. Specifically, we introduce the relevant slots to enhance the model's memory capabilities, enabling a deeper contextual understanding of video sequences. The contextual moment reasoner leverages these slots to maintain a balance between contextual information preservation and semantic relevance exploration. Simultaneously, the spiking saliency detector capitalizes on the unique properties of SNNs to accurately locate salient proposals. Our experiments demonstrate the effectiveness of SpikeMba, which consistently outperforms state-of-the-art methods across mainstream benchmarks.
Semi-supervised Counting via Pixel-by-pixel Density Distribution Modelling
Feb 23, 2024



This paper focuses on semi-supervised crowd counting, where only a small portion of the training data are labeled. We formulate the pixel-wise density value to regress as a probability distribution, instead of a single deterministic value. On this basis, we propose a semi-supervised crowd-counting model. Firstly, we design a pixel-wise distribution matching loss to measure the differences in the pixel-wise density distributions between the prediction and the ground truth; Secondly, we enhance the transformer decoder by using density tokens to specialize the forwards of decoders w.r.t. different density intervals; Thirdly, we design the interleaving consistency self-supervised learning mechanism to learn from unlabeled data efficiently. Extensive experiments on four datasets are performed to show that our method clearly outperforms the competitors by a large margin under various labeled ratio settings. Code will be released at https://github.com/LoraLinH/Semi-supervised-Counting-via-Pixel-by-pixel-Density-Distribution-Modelling.
Gramformer: Learning Crowd Counting via Graph-Modulated Transformer
Jan 08, 2024



Transformer has been popular in recent crowd counting work since it breaks the limited receptive field of traditional CNNs. However, since crowd images always contain a large number of similar patches, the self-attention mechanism in Transformer tends to find a homogenized solution where the attention maps of almost all patches are identical. In this paper, we address this problem by proposing Gramformer: a graph-modulated transformer to enhance the network by adjusting the attention and input node features respectively on the basis of two different types of graphs. Firstly, an attention graph is proposed to diverse attention maps to attend to complementary information. The graph is building upon the dissimilarities between patches, modulating the attention in an anti-similarity fashion. Secondly, a feature-based centrality encoding is proposed to discover the centrality positions or importance of nodes. We encode them with a proposed centrality indices scheme to modulate the node features and similarity relationships. Extensive experiments on four challenging crowd counting datasets have validated the competitiveness of the proposed method. Code is available at {https://github.com/LoraLinH/Gramformer}.
Linguistic Profiling of Deepfakes: An Open Database for Next-Generation Deepfake Detection
Jan 04, 2024The emergence of text-to-image generative models has revolutionized the field of deepfakes, enabling the creation of realistic and convincing visual content directly from textual descriptions. However, this advancement presents considerably greater challenges in detecting the authenticity of such content. Existing deepfake detection datasets and methods often fall short in effectively capturing the extensive range of emerging deepfakes and offering satisfactory explanatory information for detection. To address the significant issue, this paper introduces a deepfake database (DFLIP-3K) for the development of convincing and explainable deepfake detection. It encompasses about 300K diverse deepfake samples from approximately 3K generative models, which boasts the largest number of deepfake models in the literature. Moreover, it collects around 190K linguistic footprints of these deepfakes. The two distinguished features enable DFLIP-3K to develop a benchmark that promotes progress in linguistic profiling of deepfakes, which includes three sub-tasks namely deepfake detection, model identification, and prompt prediction. The deepfake model and prompt are two essential components of each deepfake, and thus dissecting them linguistically allows for an invaluable exploration of trustworthy and interpretable evidence in deepfake detection, which we believe is the key for the next-generation deepfake detection. Furthermore, DFLIP-3K is envisioned as an open database that fosters transparency and encourages collaborative efforts to further enhance its growth. Our extensive experiments on the developed benchmark verify that our DFLIP-3K database is capable of serving as a standardized resource for evaluating and comparing linguistic-based deepfake detection, identification, and prompt prediction techniques.
Semi-Supervised Crowd Counting with Contextual Modeling: Facilitating Holistic Understanding of Crowd Scenes
Oct 23, 2023To alleviate the heavy annotation burden for training a reliable crowd counting model and thus make the model more practicable and accurate by being able to benefit from more data, this paper presents a new semi-supervised method based on the mean teacher framework. When there is a scarcity of labeled data available, the model is prone to overfit local patches. Within such contexts, the conventional approach of solely improving the accuracy of local patch predictions through unlabeled data proves inadequate. Consequently, we propose a more nuanced approach: fostering the model's intrinsic 'subitizing' capability. This ability allows the model to accurately estimate the count in regions by leveraging its understanding of the crowd scenes, mirroring the human cognitive process. To achieve this goal, we apply masking on unlabeled data, guiding the model to make predictions for these masked patches based on the holistic cues. Furthermore, to help with feature learning, herein we incorporate a fine-grained density classification task. Our method is general and applicable to most existing crowd counting methods as it doesn't have strict structural or loss constraints. In addition, we observe that the model trained with our framework exhibits a 'subitizing'-like behavior. It accurately predicts low-density regions with only a 'glance', while incorporating local details to predict high-density regions. Our method achieves the state-of-the-art performance, surpassing previous approaches by a large margin on challenging benchmarks such as ShanghaiTech A and UCF-QNRF. The code is available at: https://github.com/cha15yq/MRC-Crowd.