 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Equivalent Contrastive Learning for Radio Signal Recognition
Apr 13, 2026Robust radio signal recognition is fundamental to spectrum management, electromagnetic space security, and intelligent wireless applications, yet existing deep-learning methods rely heavily on large labeled datasets and struggle to capture the multi-domain characteristics inherent in real-world signals. To address these limitations, we propose an unsupervised equivalent contrastive learning method that leverages four information-lossless equivalent transformations, spanning the time, instantaneous, frequency, and time-frequency domains, to construct multi-view and semantically consistent representations of each signal. An equivalent contrastive learning strategy then aligns these complementary views to learn discriminative and transferable embeddings without requiring labeled data. Once pre-training is completed, the resulting model can be directly fine-tuned on downstream tasks using only raw signal samples, without reapplying any equivalent transformations, which reduces computational overhead and simplifies deployment. Extensive experiments on four public datasets demonstrate that the proposed method consistently outperforms state-of-the-art contrastive baselines under linear evaluation, few-shot semi-supervised learning, and cross-domain transfer settings. Notably, the learned representations yield substantial gains in few-shot regimes and challenging channel conditions, confirming the effectiveness of multi-domain equivalent modeling in enhancing robustness and generalization. This work establishes a principled pathway for exploiting massive unlabeled radio data and provides a foundation for future self-supervised learning frameworks in wireless systems.
T-ADD: Enhancing DOA Estimation Robustness Against Adversarial Attacks
Dec 11, 2025Deep learning has achieved remarkable success in direction-of-arrival (DOA) estimation. However, recent studies have shown that adversarial perturbations can severely compromise the performance of such models. To address this vulnerability, we propose Transformer-based Adversarial Defense for DOA estimation (T-ADD), a transformer-based defense method designed to counter adversarial attacks. To achieve a balance between robustness and estimation accuracy, we formulate the adversarial defense as a joint reconstruction task and introduce a tailored joint loss function. Experimental results demonstrate that, compared with three state-of-the-art adversarial defense methods, the proposed T-ADD significantly mitigates the adverse effects of widely used adversarial attacks, leading to notable improvements in the adversarial robustness of the DOA model.
DS-Pnet: FM-Based Positioning via Downsampling
Apr 10, 2025



In this paper we present DS-Pnet, a novel framework for FM signal-based positioning that addresses the challenges of high computational complexity and limited deployment in resource-constrained environments. Two downsampling methods-IQ signal downsampling and time-frequency representation downsampling-are proposed to reduce data dimensionality while preserving critical positioning features. By integrating with the lightweight MobileViT-XS neural network, the framework achieves high positioning accuracy with significantly reduced computational demands. Experiments on real-world FM signal datasets demonstrate that DS-Pnet achieves superior performance in both indoor and outdoor scenarios, with space and time complexity reductions of approximately 87% and 99.5%, respectively, compared to an existing method, FM-Pnet. Despite the high compression, DS-Pnet maintains robust positioning accuracy, offering an optimal balance between efficiency and precision.
WK-Pnet: FM-Based Positioning via Wavelet Packet Decomposition and Knowledge Distillation
Apr 10, 2025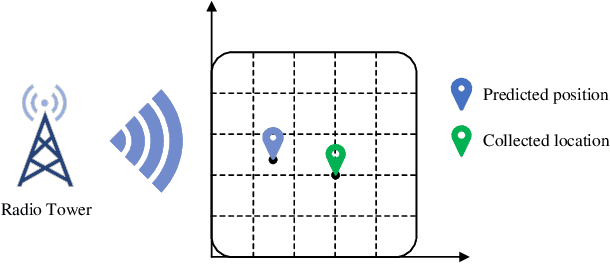
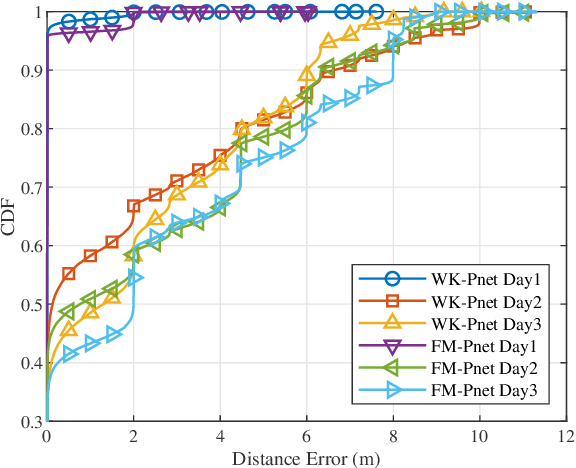
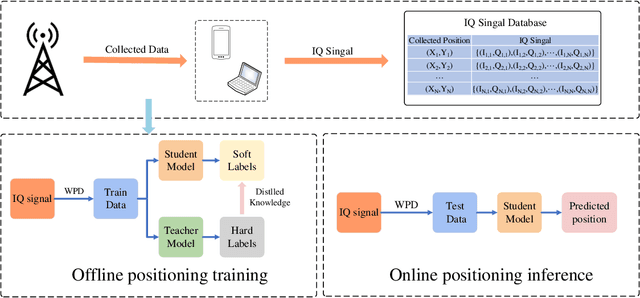
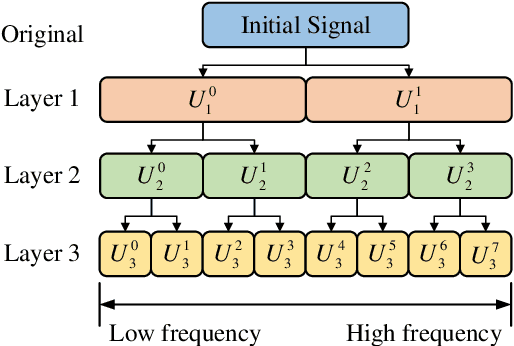
Accurate and efficient positioning in complex environments is critical for applications where traditional satellite-based systems face limitations, such as indoors or urban canyons. This paper introduces WK-Pnet, an FM-based indoor positioning framework that combines wavelet packet decomposition (WPD) and knowledge distillation. WK-Pnet leverages WPD to extract rich time-frequency features from FM signals, which are then processed by a deep learning model for precise position estimation. To address computational demands, we employ knowledge distillation, transferring insights from a high-capacity model to a streamlined student model, achieving substantial reductions in complexity without sacrificing accuracy. Experimental results across diverse environments validate WK-Pnet's superior positioning accuracy and lower computational requirements, making it a viable solution for positioning in real-time resource-constraint applications.
Deep Learning-Based Wideband Spectrum Sensing with Dual-Representation Inputs and Subband Shuffling Augmentation
Apr 10, 2025



The widespread adoption of mobile communication technology has led to a severe shortage of spectrum resources, driving the development of cognitive radio technologies aimed at improving spectrum utilization, with spectrum sensing being the key enabler. This paper presents a novel deep learning-based wideband spectrum sensing framework that leverages multi-taper power spectral inputs to achieve high-precision and sample-efficient sensing. To enhance sensing accuracy, we incorporate a feature fusion strategy that combines multiple power spectrum representations. To tackle the challenge of limited sample sizes, we propose two data augmentation techniques designed to expand the training set and improve the network's detection probability. Comprehensive simulation results demonstrate that our method outperforms existing approaches, particularly in low signal-to-noise ratio conditions, achieving higher detection probabilities and lower false alarm rates. The method also exhibits strong robustness across various scenarios, highlighting its significant potential for practical applications in wireless communication systems.
Augmenting Radio Signals with Wavelet Transform for Deep Learning-Based Modulation Recognition
Nov 07, 2023



The use of deep learning for radio modulation recognition has become prevalent in recent years. This approach automatically extracts high-dimensional features from large datasets, facilitating the accurate classification of modulation schemes. However, in real-world scenarios, it may not be feasible to gather sufficient training data in advance. Data augmentation is a method used to increase the diversity and quantity of training dataset and to reduce data sparsity and imbalance. In this paper, we propose data augmentation methods that involve replacing detail coefficients decomposed by discrete wavelet transform for reconstructing to generate new samples and expand the training set. Different generation methods are used to generate replacement sequences. Simulation results indicate that our proposed methods significantly outperform the other augmentation methods.
Mixing Signals: Data Augmentation Approach for Deep Learning Based Modulation Recognition
Apr 05, 2022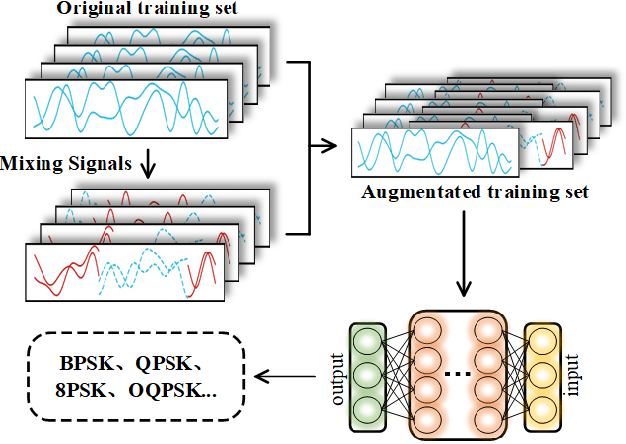
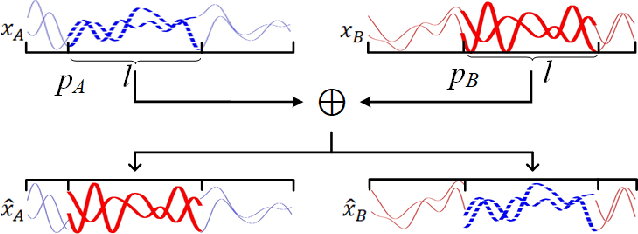
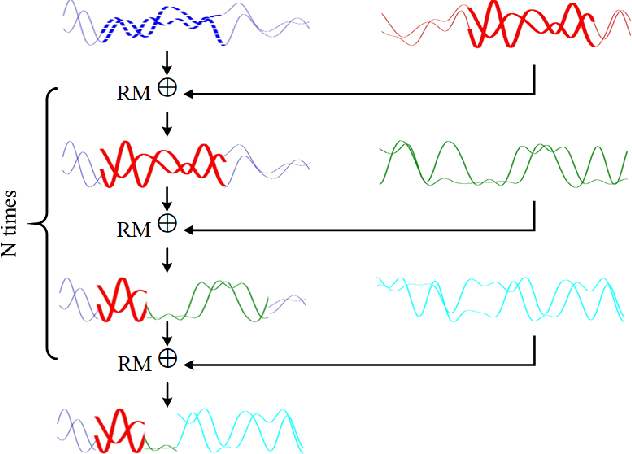

With the rapid development of deep learning, automatic modulation recognition (AMR), as an important task in cognitive radio, has gradually transformed from traditional feature extraction and classification to automatic classification by deep learning technology. However, deep learning models are data-driven methods, which often require a large amount of data as the training support. Data augmentation, as the strategy of expanding dataset, can improve the generalization of the deep learning models and thus improve the accuracy of the models to a certain extent. In this paper, for AMR of radio signals, we propose a data augmentation strategy based on mixing signals and consider four specific methods (Random Mixing, Maximum-Similarity-Mixing, $\theta-$Similarity Mixing and n-times Random Mixing) to achieve data augmentation. Experiments show that our proposed method can improve the classification accuracy of deep learning based AMR models in the full public dataset RML2016.10a. In particular, for the case of a single signal-to-noise ratio signal set, the classification accuracy can be significantly improved, which verifies the effectiveness of the methods.
Deep Transfer Clustering of Radio Signals
Jul 26, 2021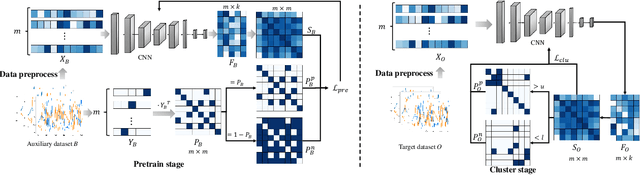

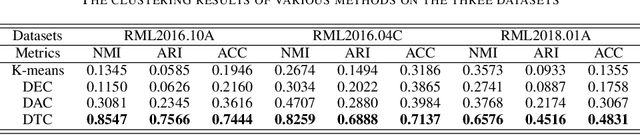
Modulation recognition is an important task in radio signal processing. Most of the current researches focus on supervised learning. However, in many real scenarios, it is difficult and cost to obtain the labels of signals. In this letter, we turn to the more challenging problem: can we cluster the modulation types just based on a large number of unlabeled radio signals? If this problem can be solved, we then can also recognize modulation types by manually labeling a very small number of samples. To answer this problem, we propose a deep transfer clustering (DTC) model. DTC naturally integrates feature learning and deep clustering, and further adopts a transfer learning mechanism to improve the feature extraction ability of an embedded convolutional neural network (CNN) model. The experiments validate that our DTC significantly outperforms a number of baselines, achieving the state-of-the-art performance in clustering radio signals for modulation recognition.
Adaptive Visibility Graph Neural Network and its Application in Modulation Classification
Jun 16, 2021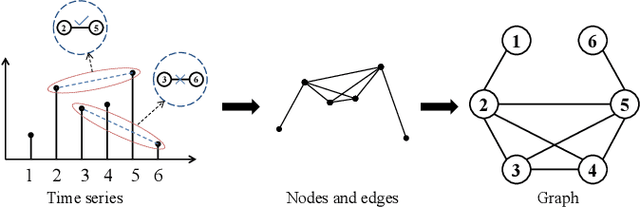
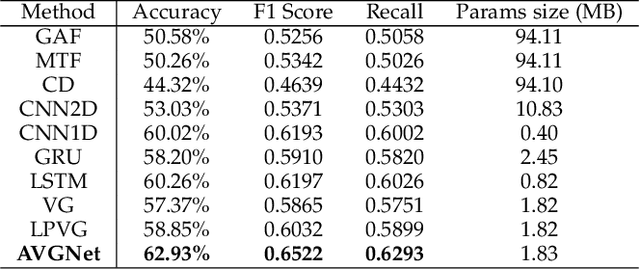
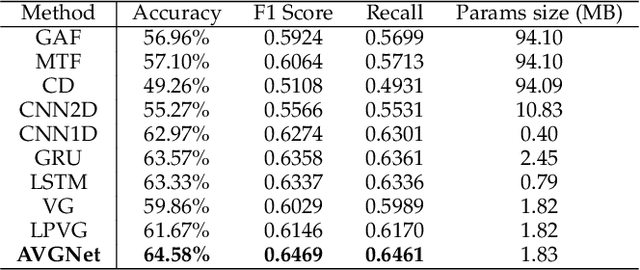
Our digital world is full of time series and graphs which capture the various aspects of many complex systems. Traditionally, there are respective methods in processing these two different types of data, e.g., Recurrent Neural Network (RNN) and Graph Neural Network (GNN), while in recent years, time series could be mapped to graphs by using the techniques such as Visibility Graph (VG), so that researchers can use graph algorithms to mine the knowledge in time series. Such mapping methods establish a bridge between time series and graphs, and have high potential to facilitate the analysis of various real-world time series. However, the VG method and its variants are just based on fixed rules and thus lack of flexibility, largely limiting their application in reality. In this paper, we propose an Adaptive Visibility Graph (AVG) algorithm that can adaptively map time series into graphs, based on which we further establish an end-to-end classification framework AVGNet, by utilizing GNN model DiffPool as the classifier. We then adopt AVGNet for radio signal modulation classification which is an important task in the field of wireless communication. The simulations validate that AVGNet outperforms a series of advanced deep learning methods, achieving the state-of-the-art performance in this task.
SigNet: An Advanced Deep Learning Framework for Radio Signal Classification
Oct 28, 2020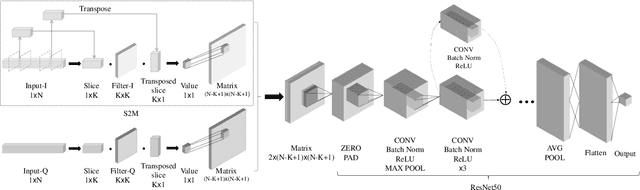
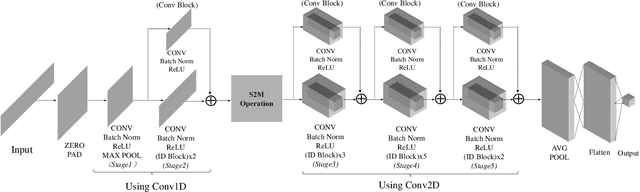
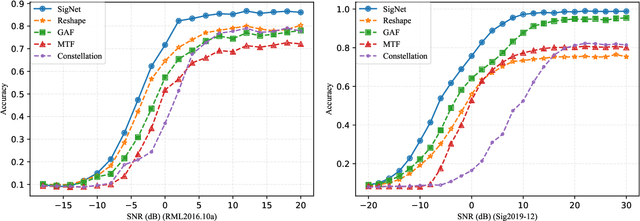
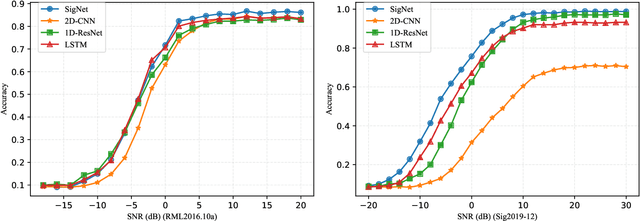
Deep learning methods achieve great success in many areas due to their powerful feature extraction capabilities and end-to-end training mechanism, and recently they are also introduced for radio signal modulation classification. In this paper, we propose a novel deep learning framework called SigNet, where a signal-to-matrix (S2M) operator is adopted to convert the original signal into a square matrix first and is co-trained with a follow-up CNN architecture for classification. This model is further accelerated by integrating 1D convolution operators, leading to the upgraded model SigNet2.0. The experiments on two signal datasets show that both SigNet and SigNet2.0 outperform a number of well-known baselines, achieving the state-of-the-art performance. Notably, they obtain significantly higher accuracy than 1D-ResNet and 2D-CNN (at most increasing 70.5\%), while much faster than LSTM (at most saving 88.0\% training time). More interestingly, our proposed models behave extremely well in few-shot learning when a small training data set is provided. They can achieve a relatively high accuracy even when 1\% training data are kept, while other baseline models may lose their effectiveness much more quickly as the datasets get smaller. Such result suggests that SigNet/SigNet2.0 could be extremely useful in the situations where labeled signal data are difficult to obtain.