 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Vulnerabilities in Python Packages and Their Detection
Sep 04, 2025In the rapidly evolving software development landscape, Python stands out for its simplicity, versatility, and extensive ecosystem. Python packages, as units of organization, reusability, and distribution, have become a pressing concern, highlighted by the considerable number of vulnerability reports. As a scripting language, Python often cooperates with other languages for performance or interoperability. This adds complexity to the vulnerabilities inherent to Python packages, and the effectiveness of current vulnerability detection tools remains underexplored. This paper addresses these gaps by introducing PyVul, the first comprehensive benchmark suite of Python-package vulnerabilities. PyVul includes 1,157 publicly reported, developer-verified vulnerabilities, each linked to its affected packages. To accommodate diverse detection techniques, it provides annotations at both commit and function levels. An LLM-assisted data cleansing method is incorporated to improve label accuracy, achieving 100% commit-level and 94% function-level accuracy, establishing PyVul as the most precise large-scale Python vulnerability benchmark. We further carry out a distribution analysis of PyVul, which demonstrates that vulnerabilities in Python packages involve multiple programming languages and exhibit a wide variety of types. Moreover, our analysis reveals that multi-lingual Python packages are potentially more susceptible to vulnerabilities. Evaluation of state-of-the-art detectors using this benchmark reveals a significant discrepancy between the capabilities of existing tools and the demands of effectively identifying real-world security issues in Python packages. Additionally, we conduct an empirical review of the top-ranked CWEs observed in Python packages, to diagnose the fine-grained limitations of current detection tools and highlight the necessity for future advancements in the field.
Automated Trustworthiness Oracle Generation for Machine Learning Text Classifiers
Oct 30, 2024



Machine learning (ML) for text classification has been widely used in various domains, such as toxicity detection, chatbot consulting, and review analysis. These applications can significantly impact ethics, economics, and human behavior, raising serious concerns about trusting ML decisions. Several studies indicate that traditional metrics, such as model confidence and accuracy, are insufficient to build human trust in ML models. These models often learn spurious correlations during training and predict based on them during inference. In the real world, where such correlations are absent, their performance can deteriorate significantly. To avoid this, a common practice is to test whether predictions are reasonable. Along with this, a challenge known as the trustworthiness oracle problem has been introduced. Due to the lack of automated trustworthiness oracles, the assessment requires manual validation of the decision process disclosed by explanation methods, which is time-consuming and not scalable. We propose TOKI, the first automated trustworthiness oracle generation method for text classifiers, which automatically checks whether the prediction-contributing words are related to the predicted class using explanation methods and word embeddings. To demonstrate its practical usefulness, we introduce a novel adversarial attack method targeting trustworthiness issues identified by TOKI. We compare TOKI with a naive baseline based solely on model confidence using human-created ground truths of 6,000 predictions. We also compare TOKI-guided adversarial attack method with A2T, a SOTA adversarial attack method. Results show that relying on prediction uncertainty cannot distinguish between trustworthy and untrustworthy predictions, TOKI achieves 142% higher accuracy than the naive baseline, and TOKI-guided adversarial attack method is more effective with fewer perturbations than A2T.
LLM as Runtime Error Handler: A Promising Pathway to Adaptive Self-Healing of Software Systems
Aug 02, 2024



Unanticipated runtime errors, lacking predefined handlers, can abruptly terminate execution and lead to severe consequences, such as data loss or system crashes. Despite extensive efforts to identify potential errors during the development phase, such unanticipated errors remain a challenge to to be entirely eliminated, making the runtime mitigation measurements still indispensable to minimize their impact. Automated self-healing techniques, such as reusing existing handlers, have been investigated to reduce the loss coming through with the execution termination. However, the usability of existing methods is retained by their predefined heuristic rules and they fail to handle diverse runtime errors adaptively. Recently, the advent of Large Language Models (LLMs) has opened new avenues for addressing this problem. Inspired by their remarkable capabilities in understanding and generating code, we propose to deal with the runtime errors in a real-time manner using LLMs. Specifically, we propose Healer, the first LLM-assisted self-healing framework for handling runtime errors. When an unhandled runtime error occurs, Healer will be activated to generate a piece of error-handling code with the help of its internal LLM and the code will be executed inside the runtime environment owned by the framework to obtain a rectified program state from which the program should continue its execution. Our exploratory study evaluates the performance of Healer using four different code benchmarks and three state-of-the-art LLMs, GPT-3.5, GPT-4, and CodeQwen-7B. Results show that, without the need for any fine-tuning, GPT-4 can successfully help programs recover from 72.8% of runtime errors, highlighting the potential of LLMs in handling runtime errors.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
AI Coders Are Among Us: Rethinking Programming Language Grammar Towards Efficient Code Generation
Apr 25, 2024Besides humans and machines, Artificial Intelligence (AI) models have emerged to be another important audience of programming languages, as we come to the era of large language models (LLMs). LLMs can now excel at coding competitions and even program like developers to address various tasks, such as math calculation. Yet, the grammar and layout of existing programs are designed for humans. Particularly, abundant grammar tokens and formatting tokens are included to make the code more readable to humans. While beneficial, such a human-centric design imposes an unnecessary computational burden on LLMs where each token, either consumed or generated, consumes computational resources. To improve inference efficiency and reduce computational costs, we propose the concept of AI-oriented grammar, which aims to represent the code in a way that better suits the working mechanism of AI models. Code written with AI-oriented grammar discards formats and uses a minimum number of tokens to convey code semantics effectively. To demonstrate the feasibility of this concept, we explore and implement the first AI-oriented grammar for Python, named Simple Python (SimPy). SimPy is crafted by revising the original Python grammar through a series of heuristic rules. Programs written in SimPy maintain identical Abstract Syntax Tree (AST) structures to those in standard Python, allowing execution via a modified AST parser. In addition, we explore methods to enable existing LLMs to proficiently understand and use SimPy, and ensure the changes remain imperceptible for human developers. Compared with the original Python, SimPy not only reduces token usage by 13.5% and 10.4% for CodeLlama and GPT-4, but can also achieve equivalent, even improved, performance over the models trained on Python code.
A Proactive and Dual Prevention Mechanism against Illegal Song Covers empowered by Singing Voice Conversion
Jan 30, 2024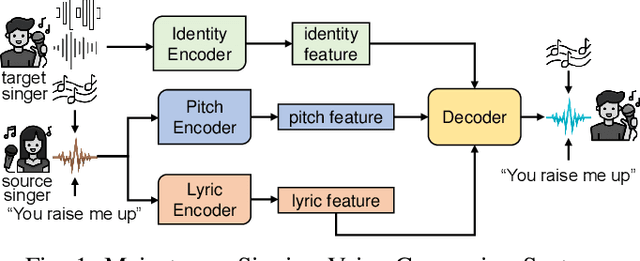
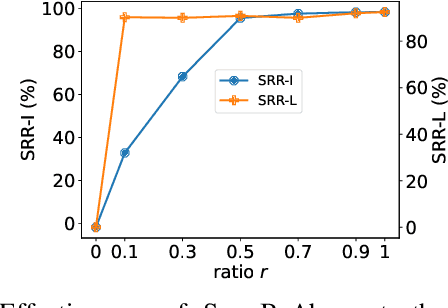
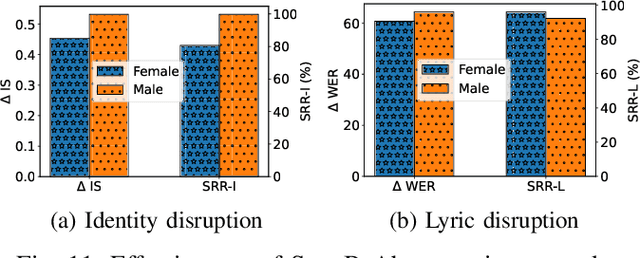
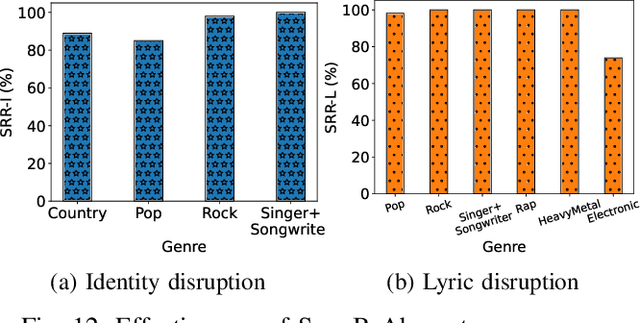
Singing voice conversion (SVC) automates song covers by converting one singer's singing voice into another target singer's singing voice with the original lyrics and melody. However, it raises serious concerns about copyright and civil right infringements to multiple entities. This work proposes SongBsAb, the first proactive approach to mitigate unauthorized SVC-based illegal song covers. SongBsAb introduces human-imperceptible perturbations to singing voices before releasing them, so that when they are used, the generation process of SVC will be interfered, resulting in unexpected singing voices. SongBsAb features a dual prevention effect by causing both (singer) identity disruption and lyric disruption, namely, the SVC-covered singing voice neither imitates the target singer nor preserves the original lyrics. To improve the imperceptibility of perturbations, we refine a psychoacoustic model-based loss with the backing track as an additional masker, a unique accompanying element for singing voices compared to ordinary speech voices. To enhance the transferability, we propose to utilize a frame-level interaction reduction-based loss. We demonstrate the prevention effectiveness, utility, and robustness of SongBsAb on three SVC models and two datasets using both objective and human study-based subjective metrics. Our work fosters an emerging research direction for mitigating illegal automated song covers.
Are Latent Vulnerabilities Hidden Gems for Software Vulnerability Prediction? An Empirical Study
Jan 20, 2024



Collecting relevant and high-quality data is integral to the development of effective Software Vulnerability (SV) prediction models. Most of the current SV datasets rely on SV-fixing commits to extract vulnerable functions and lines. However, none of these datasets have considered latent SVs existing between the introduction and fix of the collected SVs. There is also little known about the usefulness of these latent SVs for SV prediction. To bridge these gaps, we conduct a large-scale study on the latent vulnerable functions in two commonly used SV datasets and their utilization for function-level and line-level SV predictions. Leveraging the state-of-the-art SZZ algorithm, we identify more than 100k latent vulnerable functions in the studied datasets. We find that these latent functions can increase the number of SVs by 4x on average and correct up to 5k mislabeled functions, yet they have a noise level of around 6%. Despite the noise, we show that the state-of-the-art SV prediction model can significantly benefit from such latent SVs. The improvements are up to 24.5% in the performance (F1-Score) of function-level SV predictions and up to 67% in the effectiveness of localizing vulnerable lines. Overall, our study presents the first promising step toward the use of latent SVs to improve the quality of SV datasets and enhance the performance of SV prediction tasks.
When Neural Code Completion Models Size up the Situation: Attaining Cheaper and Faster Completion through Dynamic Model Inference
Jan 18, 2024Leveraging recent advancements in large language models, modern neural code completion models have demonstrated the capability to generate highly accurate code suggestions. However, their massive size poses challenges in terms of computational costs and environmental impact, hindering their widespread adoption in practical scenarios. Dynamic inference emerges as a promising solution, as it allocates minimal computation during inference while maintaining the model's performance. In this research, we explore dynamic inference within the context of code completion. Initially, we conducted an empirical investigation on GPT-2, focusing on the inference capabilities of intermediate layers for code completion. We found that 54.4% of tokens can be accurately generated using just the first layer, signifying significant computational savings potential. Moreover, despite using all layers, the model still fails to predict 14.5% of tokens correctly, and the subsequent completions continued from them are rarely considered helpful, with only a 4.2% Acceptance Rate. These findings motivate our exploration of dynamic inference in code completion and inspire us to enhance it with a decision-making mechanism that stops the generation of incorrect code. We thus propose a novel dynamic inference method specifically tailored for code completion models. This method aims not only to produce correct predictions with largely reduced computation but also to prevent incorrect predictions proactively. Our extensive evaluation shows that it can averagely skip 1.7 layers out of 16 layers in the models, leading to an 11.2% speedup with only a marginal 1.1% reduction in ROUGE-L.
Pop Quiz! Do Pre-trained Code Models Possess Knowledge of Correct API Names?
Sep 14, 2023



Recent breakthroughs in pre-trained code models, such as CodeBERT and Codex, have shown their superior performance in various downstream tasks. The correctness and unambiguity of API usage among these code models are crucial for achieving desirable program functionalities, requiring them to learn various API fully qualified names structurally and semantically. Recent studies reveal that even state-of-the-art pre-trained code models struggle with suggesting the correct APIs during code generation. However, the reasons for such poor API usage performance are barely investigated. To address this challenge, we propose using knowledge probing as a means of interpreting code models, which uses cloze-style tests to measure the knowledge stored in models. Our comprehensive study examines a code model's capability of understanding API fully qualified names from two different perspectives: API call and API import. Specifically, we reveal that current code models struggle with understanding API names, with pre-training strategies significantly affecting the quality of API name learning. We demonstrate that natural language context can assist code models in locating Python API names and generalize Python API name knowledge to unseen data. Our findings provide insights into the limitations and capabilities of current pre-trained code models, and suggest that incorporating API structure into the pre-training process can improve automated API usage and code representations. This work provides significance for advancing code intelligence practices and direction for future studies. All experiment results, data and source code used in this work are available at \url{https://doi.org/10.5281/zenodo.7902072}.
CodeMark: Imperceptible Watermarking for Code Datasets against Neural Code Completion Models
Aug 28, 2023



Code datasets are of immense value for training neural-network-based code completion models, where companies or organizations have made substantial investments to establish and process these datasets. Unluckily, these datasets, either built for proprietary or public usage, face the high risk of unauthorized exploits, resulting from data leakages, license violations, etc. Even worse, the ``black-box'' nature of neural models sets a high barrier for externals to audit their training datasets, which further connives these unauthorized usages. Currently, watermarking methods have been proposed to prohibit inappropriate usage of image and natural language datasets. However, due to domain specificity, they are not directly applicable to code datasets, leaving the copyright protection of this emerging and important field of code data still exposed to threats. To fill this gap, we propose a method, named CodeMark, to embed user-defined imperceptible watermarks into code datasets to trace their usage in training neural code completion models. CodeMark is based on adaptive semantic-preserving transformations, which preserve the exact functionality of the code data and keep the changes covert against rule-breakers. We implement CodeMark in a toolkit and conduct an extensive evaluation of code completion models. CodeMark is validated to fulfill all desired properties of practical watermarks, including harmlessness to model accuracy, verifiability, robustness, and imperceptibility.