 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Review Agent Benchmark
Mar 24, 2026Software engineering agents have shown significant promise in writing code. As AI agents permeate code writing, and generate huge volumes of code automatically -- the matter of code quality comes front and centre. As the automatically generated code gets integrated into huge code-bases -- the issue of code review and broadly quality assurance becomes important. In this paper, we take a fresh look at the problem and curate a code review dataset for AI agents to work with. Our dataset called c-CRAB (pronounced see-crab) can evaluate agents for code review tasks. Specifically given a pull-request (which could be coming from code generation agents or humans), if a code review agent produces a review, our evaluation framework can asses the reviewing capability of the code review agents. Our evaluation framework is used to evaluate the state of the art today -- the open-source PR-agent, as well as commercial code review agents from Devin, Claude Code, and Codex. Our c-CRAB dataset is systematically constructed from human reviews -- given a human review of a pull request instance we generate corresponding tests to evaluate the code review agent generated reviews. Such a benchmark construction gives us several insights. Firstly, the existing review agents taken together can solve only around 40% of the c-CRAB tasks, indicating the potential to close this gap by future research. Secondly, we observe that the agent reviews often consider different aspects from the human reviews -- indicating the potential for human-agent collaboration for code review that could be deployed in future software teams. Last but not the least, the agent generated tests from our data-set act as a held out test-suite and hence quality gate for agent generated reviews. What this will mean for future collaboration of code generation agents, test generation agents and code review agents -- remains to be investigated.
Transducer Tuning: Efficient Model Adaptation for Software Tasks Using Code Property Graphs
Dec 18, 2024



Large language models have demonstrated promising performance across various software engineering tasks. While fine-tuning is a common practice to adapt these models for downstream tasks, it becomes challenging in resource-constrained environments due to increased memory requirements from growing trainable parameters in increasingly large language models. We introduce \approach, a technique to adapt large models for downstream code tasks using Code Property Graphs (CPGs). Our approach introduces a modular component called \transducer that enriches code embeddings with structural and dependency information from CPGs. The Transducer comprises two key components: Graph Vectorization Engine (GVE) and Attention-Based Fusion Layer (ABFL). GVE extracts CPGs from input source code and transforms them into graph feature vectors. ABFL then fuses those graphs feature vectors with initial code embeddings from a large language model. By optimizing these transducers for different downstream tasks, our approach enhances the models without the need to fine-tune them for specific tasks. We have evaluated \approach on three downstream tasks: code summarization, assert generation, and code translation. Our results demonstrate competitive performance compared to full parameter fine-tuning while reducing up to 99\% trainable parameters to save memory. \approach also remains competitive against other fine-tuning approaches (e.g., LoRA, Prompt-Tuning, Prefix-Tuning) while using only 1.5\%-80\% of their trainable parameters. Our findings show that integrating structural and dependency information through Transducer Tuning enables more efficient model adaptation, making it easier for users to adapt large models in resource-constrained settings.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
Your Instructions Are Not Always Helpful: Assessing the Efficacy of Instruction Fine-tuning for Software Vulnerability Detection
Jan 15, 2024Software, while beneficial, poses potential cybersecurity risks due to inherent vulnerabilities. Detecting these vulnerabilities is crucial, and deep learning has shown promise as an effective tool for this task due to its ability to perform well without extensive feature engineering. However, a challenge in deploying deep learning for vulnerability detection is the limited availability of training data. Recent research highlights the deep learning efficacy in diverse tasks. This success is attributed to instruction fine-tuning, a technique that remains under-explored in the context of vulnerability detection. This paper investigates the capability of models, specifically a recent language model, to generalize beyond the programming languages used in their training data. It also examines the role of natural language instructions in enhancing this generalization. Our study evaluates the model performance on a real-world dataset to predict vulnerable code. We present key insights and lessons learned, contributing to understanding the deep learning application in software vulnerability detection.
On the Effectiveness of Pretrained Models for API Learning
Apr 05, 2022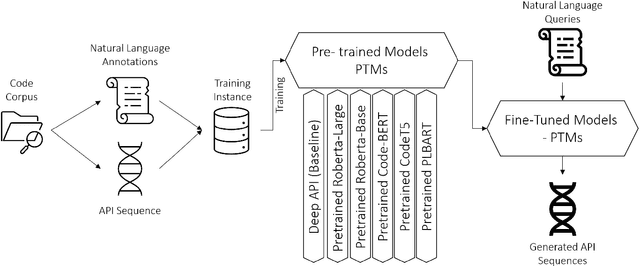
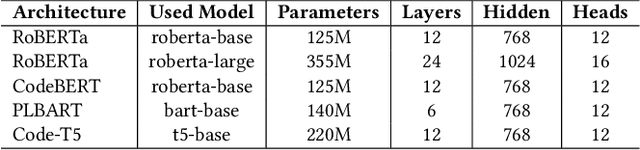

Developers frequently use APIs to implement certain functionalities, such as parsing Excel Files, reading and writing text files line by line, etc. Developers can greatly benefit from automatic API usage sequence generation based on natural language queries for building applications in a faster and cleaner manner. Existing approaches utilize information retrieval models to search for matching API sequences given a query or use RNN-based encoder-decoder to generate API sequences. As it stands, the first approach treats queries and API names as bags of words. It lacks deep comprehension of the semantics of the queries. The latter approach adapts a neural language model to encode a user query into a fixed-length context vector and generate API sequences from the context vector. We want to understand the effectiveness of recent Pre-trained Transformer based Models (PTMs) for the API learning task. These PTMs are trained on large natural language corpora in an unsupervised manner to retain contextual knowledge about the language and have found success in solving similar Natural Language Processing (NLP) problems. However, the applicability of PTMs has not yet been explored for the API sequence generation task. We use a dataset that contains 7 million annotations collected from GitHub to evaluate the PTMs empirically. This dataset was also used to assess previous approaches. Based on our results, PTMs generate more accurate API sequences and outperform other related methods by around 11%. We have also identified two different tokenization approaches that can contribute to a significant boost in PTMs' performance for the API sequence generation task.
* 12 pages, 4 figures, ICPC 2022