 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVD: A Multi-Lingual Software Vulnerability Detection Framework
Dec 09, 2024Software vulnerabilities can result in catastrophic cyberattacks that increasingly threaten business operations. Consequently, ensuring the safety of software systems has become a paramount concern for both private and public sectors. Recent literature has witnessed increasing exploration of learning-based approaches for software vulnerability detection. However, a key limitation of these techniques is their primary focus on a single programming language, such as C/C++, which poses constraints considering the polyglot nature of modern software projects. Further, there appears to be an oversight in harnessing the synergies of vulnerability knowledge across varied languages, potentially underutilizing the full capabilities of these methods. To address the aforementioned issues, we introduce MVD - an innovative multi-lingual vulnerability detection framework. This framework acquires the ability to detect vulnerabilities across multiple languages by concurrently learning from vulnerability data of various languages, which are curated by our specialized pipeline. We also incorporate incremental learning to enable the detection capability of MVD to be extended to new languages, thus augmenting its practical utility. Extensive experiments on our curated dataset of more than 11K real-world multi-lingual vulnerabilities substantiate that our framework significantly surpasses state-of-the-art methods in multi-lingual vulnerability detection by 83.7% to 193.6% in PR-AUC. The results also demonstrate that MVD detects vulnerabilities well for new languages without compromising the detection performance of previously trained languages, even when training data for the older languages is unavailable. Overall, our findings motivate and pave the way for the prediction of multi-lingual vulnerabilities in modern software systems.
Automatic Data Labeling for Software Vulnerability Prediction Models: How Far Are We?
Jul 25, 2024Background: Software Vulnerability (SV) prediction needs large-sized and high-quality data to perform well. Current SV datasets mostly require expensive labeling efforts by experts (human-labeled) and thus are limited in size. Meanwhile, there are growing efforts in automatic SV labeling at scale. However, the fitness of auto-labeled data for SV prediction is still largely unknown. Aims: We quantitatively and qualitatively study the quality and use of the state-of-the-art auto-labeled SV data, D2A, for SV prediction. Method: Using multiple sources and manual validation, we curate clean SV data from human-labeled SV-fixing commits in two well-known projects for investigating the auto-labeled counterparts. Results: We discover that 50+% of the auto-labeled SVs are noisy (incorrectly labeled), and they hardly overlap with the publicly reported ones. Yet, SV prediction models utilizing the noisy auto-labeled SVs can perform up to 22% and 90% better in Matthews Correlation Coefficient and Recall, respectively, than the original models. We also reveal the promises and difficulties of applying noise-reduction methods for automatically addressing the noise in auto-labeled SV data to maximize the data utilization for SV prediction. Conclusions: Our study informs the benefits and challenges of using auto-labeled SVs, paving the way for large-scale SV prediction.
Mitigating Data Imbalance for Software Vulnerability Assessment: Does Data Augmentation Help?
Jul 15, 2024Background: Software Vulnerability (SV) assessment is increasingly adopted to address the ever-increasing volume and complexity of SVs. Data-driven approaches have been widely used to automate SV assessment tasks, particularly the prediction of the Common Vulnerability Scoring System (CVSS) metrics such as exploitability, impact, and severity. SV assessment suffers from the imbalanced distributions of the CVSS classes, but such data imbalance has been hardly understood and addressed in the literature. Aims: We conduct a large-scale study to quantify the impacts of data imbalance and mitigate the issue for SV assessment through the use of data augmentation. Method: We leverage nine data augmentation techniques to balance the class distributions of the CVSS metrics. We then compare the performance of SV assessment models with and without leveraging the augmented data. Results: Through extensive experiments on 180k+ real-world SVs, we show that mitigating data imbalance can significantly improve the predictive performance of models for all the CVSS tasks, by up to 31.8% in Matthews Correlation Coefficient. We also discover that simple text augmentation like combining random text insertion, deletion, and replacement can outperform the baseline across the board. Conclusions: Our study provides the motivation and the first promising step toward tackling data imbalance for effective SV assessment.
Software Vulnerability Prediction in Low-Resource Languages: An Empirical Study of CodeBERT and ChatGPT
Apr 26, 2024



Background: Software Vulnerability (SV) prediction in emerging languages is increasingly important to ensure software security in modern systems. However, these languages usually have limited SV data for developing high-performing prediction models. Aims: We conduct an empirical study to evaluate the impact of SV data scarcity in emerging languages on the state-of-the-art SV prediction model and investigate potential solutions to enhance the performance. Method: We train and test the state-of-the-art model based on CodeBERT with and without data sampling techniques for function-level and line-level SV prediction in three low-resource languages - Kotlin, Swift, and Rust. We also assess the effectiveness of ChatGPT for low-resource SV prediction given its recent success in other domains. Results: Compared to the original work in C/C++ with large data, CodeBERT's performance of function-level and line-level SV prediction significantly declines in low-resource languages, signifying the negative impact of data scarcity. Regarding remediation, data sampling techniques fail to improve CodeBERT; whereas, ChatGPT showcases promising results, substantially enhancing predictive performance by up to 34.4% for the function level and up to 53.5% for the line level. Conclusion: We have highlighted the challenge and made the first promising step for low-resource SV prediction, paving the way for future research in this direction.
Are Latent Vulnerabilities Hidden Gems for Software Vulnerability Prediction? An Empirical Study
Jan 20, 2024



Collecting relevant and high-quality data is integral to the development of effective Software Vulnerability (SV) prediction models. Most of the current SV datasets rely on SV-fixing commits to extract vulnerable functions and lines. However, none of these datasets have considered latent SVs existing between the introduction and fix of the collected SVs. There is also little known about the usefulness of these latent SVs for SV prediction. To bridge these gaps, we conduct a large-scale study on the latent vulnerable functions in two commonly used SV datasets and their utilization for function-level and line-level SV predictions. Leveraging the state-of-the-art SZZ algorithm, we identify more than 100k latent vulnerable functions in the studied datasets. We find that these latent functions can increase the number of SVs by 4x on average and correct up to 5k mislabeled functions, yet they have a noise level of around 6%. Despite the noise, we show that the state-of-the-art SV prediction model can significantly benefit from such latent SVs. The improvements are up to 24.5% in the performance (F1-Score) of function-level SV predictions and up to 67% in the effectiveness of localizing vulnerable lines. Overall, our study presents the first promising step toward the use of latent SVs to improve the quality of SV datasets and enhance the performance of SV prediction tasks.
Towards an Improved Understanding of Software Vulnerability Assessment Using Data-Driven Approaches
Jul 24, 2022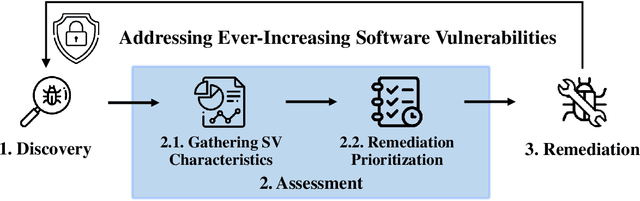
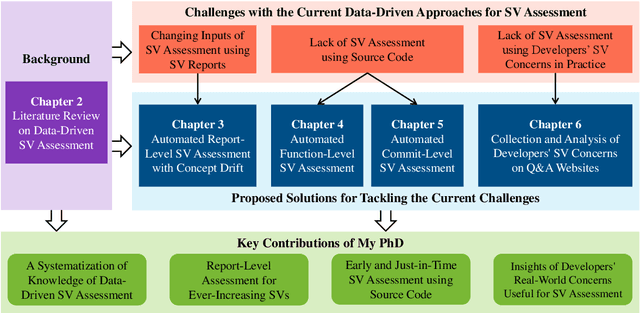


The thesis advances the field of software security by providing knowledge and automation support for software vulnerability assessment using data-driven approaches. Software vulnerability assessment provides important and multifaceted information to prevent and mitigate dangerous cyber-attacks in the wild. The key contributions include a systematisation of knowledge, along with a suite of novel data-driven techniques and practical recommendations for researchers and practitioners in the area. The thesis results help improve the understanding and inform the practice of assessing ever-increasing vulnerabilities in real-world software systems. This in turn enables more thorough and timely fixing prioritisation and planning of these critical security issues.
On the Use of Fine-grained Vulnerable Code Statements for Software Vulnerability Assessment Models
Mar 16, 2022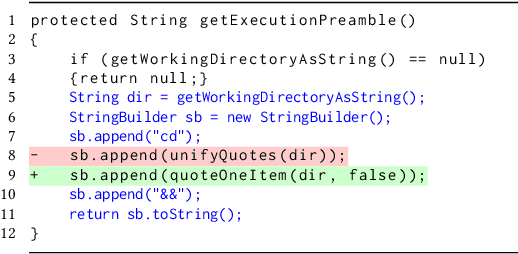

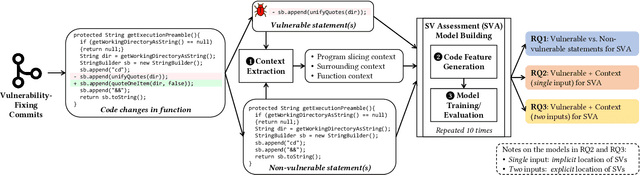
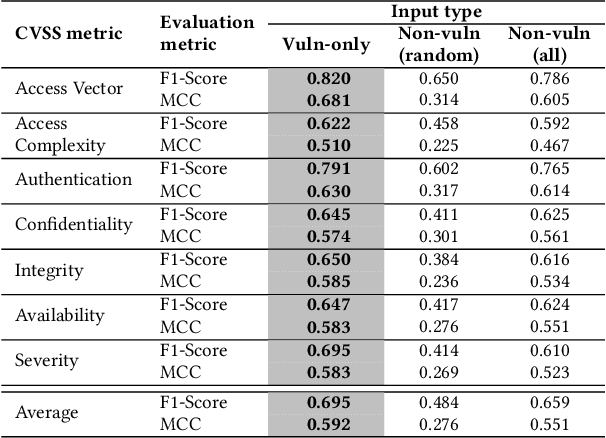
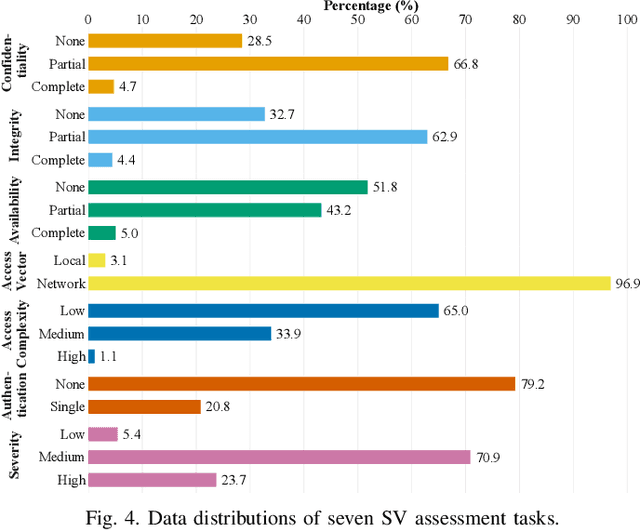
Many studies have developed Machine Learning (ML) approaches to detect Software Vulnerabilities (SVs) in functions and fine-grained code statements that cause such SVs. However, there is little work on leveraging such detection outputs for data-driven SV assessment to give information about exploitability, impact, and severity of SVs. The information is important to understand SVs and prioritize their fixing. Using large-scale data from 1,782 functions of 429 SVs in 200 real-world projects, we investigate ML models for automating function-level SV assessment tasks, i.e., predicting seven Common Vulnerability Scoring System (CVSS) metrics. We particularly study the value and use of vulnerable statements as inputs for developing the assessment models because SVs in functions are originated in these statements. We show that vulnerable statements are 5.8 times smaller in size, yet exhibit 7.5-114.5% stronger assessment performance (Matthews Correlation Coefficient (MCC)) than non-vulnerable statements. Incorporating context of vulnerable statements further increases the performance by up to 8.9% (0.64 MCC and 0.75 F1-Score). Overall, we provide the initial yet promising ML-based baselines for function-level SV assessment, paving the way for further research in this direction.
Automated Security Assessment for the Internet of Things
Sep 09, 2021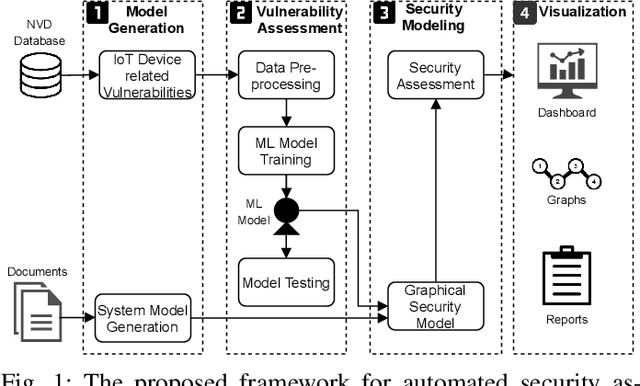
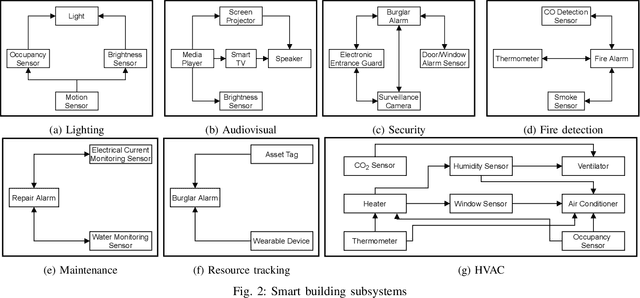
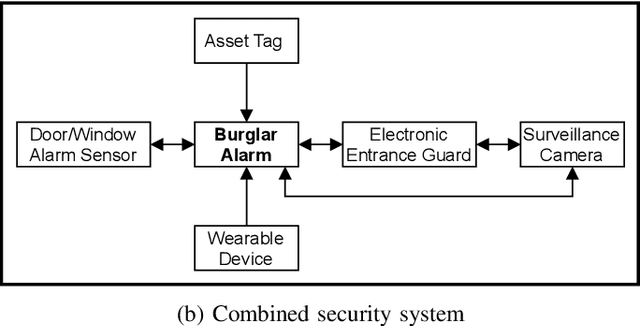
Internet of Things (IoT) based applications face an increasing number of potential security risks, which need to be systematically assessed and addressed. Expert-based manual assessment of IoT security is a predominant approach, which is usually inefficient. To address this problem, we propose an automated security assessment framework for IoT networks. Our framework first leverages machine learning and natural language processing to analyze vulnerability descriptions for predicting vulnerability metrics. The predicted metrics are then input into a two-layered graphical security model, which consists of an attack graph at the upper layer to present the network connectivity and an attack tree for each node in the network at the bottom layer to depict the vulnerability information. This security model automatically assesses the security of the IoT network by capturing potential attack paths. We evaluate the viability of our approach using a proof-of-concept smart building system model which contains a variety of real-world IoT devices and potential vulnerabilities. Our evaluation of the proposed framework demonstrates its effectiveness in terms of automatically predicting the vulnerability metrics of new vulnerabilities with more than 90% accuracy, on average, and identifying the most vulnerable attack paths within an IoT network. The produced assessment results can serve as a guideline for cybersecurity professionals to take further actions and mitigate risks in a timely manner.
DeepCVA: Automated Commit-level Vulnerability Assessment with Deep Multi-task Learning
Aug 18, 2021
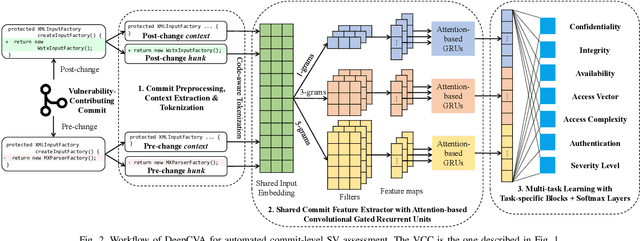

It is increasingly suggested to identify Software Vulnerabilities (SVs) in code commits to give early warnings about potential security risks. However, there is a lack of effort to assess vulnerability-contributing commits right after they are detected to provide timely information about the exploitability, impact and severity of SVs. Such information is important to plan and prioritize the mitigation for the identified SVs. We propose a novel Deep multi-task learning model, DeepCVA, to automate seven Commit-level Vulnerability Assessment tasks simultaneously based on Common Vulnerability Scoring System (CVSS) metrics. We conduct large-scale experiments on 1,229 vulnerability-contributing commits containing 542 different SVs in 246 real-world software projects to evaluate the effectiveness and efficiency of our model. We show that DeepCVA is the best-performing model with 38% to 59.8% higher Matthews Correlation Coefficient than many supervised and unsupervised baseline models. DeepCVA also requires 6.3 times less training and validation time than seven cumulative assessment models, leading to significantly less model maintenance cost as well. Overall, DeepCVA presents the first effective and efficient solution to automatically assess SVs early in software systems.
A Survey on Data-driven Software Vulnerability Assessment and Prioritization
Jul 25, 2021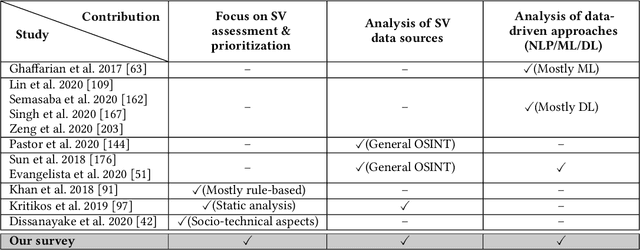
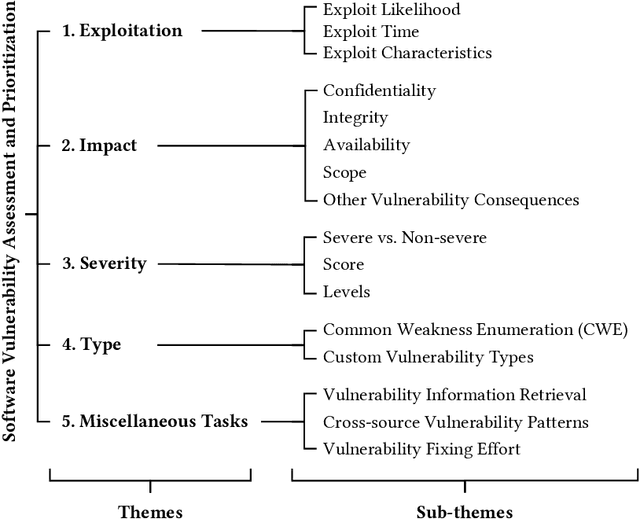
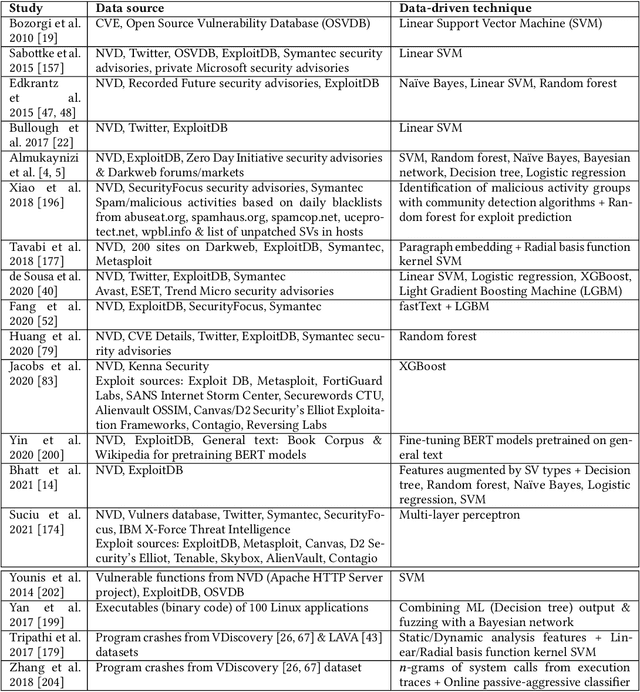
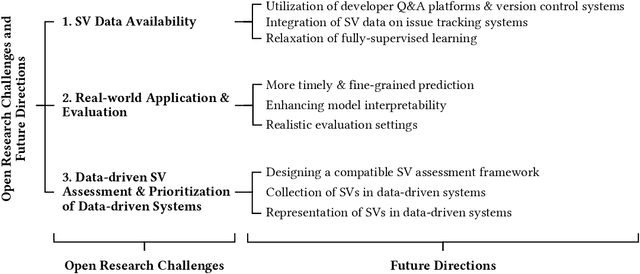
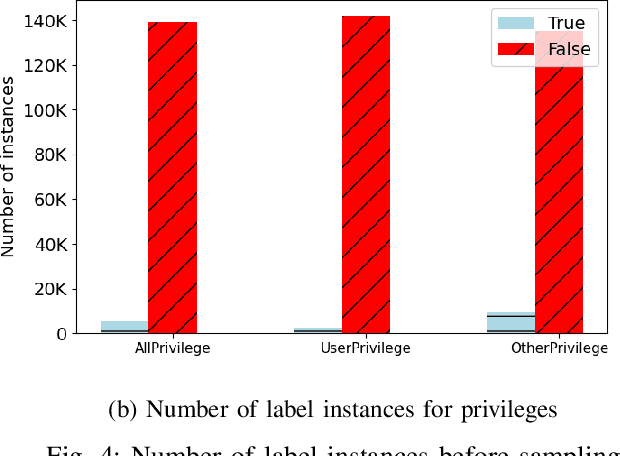
Software Vulnerabilities (SVs) are increasing in complexity and scale, posing great security risks to many software systems. Given the limited resources in practice, SV assessment and prioritization help practitioners devise optimal SV mitigation plans based on various SV characteristics. The surge in SV data sources and data-driven techniques such as Machine Learning and Deep Learning have taken SV assessment and prioritization to the next level. Our survey provides a taxonomy of the past research efforts and highlights the best practices for data-driven SV assessment and prioritization. We also discuss the current limitations and propose potential solutions to address such issues.