 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
Sep 30, 2023



Large Language Models (LLMs) have achieved remarkable success, demonstrating powerful instruction-following capabilities across diverse tasks. Instruction fine-tuning is critical in enabling LLMs to align with user intentions and effectively follow instructions. In this work, we investigate how instruction fine-tuning modifies pre-trained models, focusing on two perspectives: instruction recognition and knowledge evolution. To study the behavior shift of LLMs, we employ a suite of local and global explanation methods, including a gradient-based approach for input-output attribution and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. Our findings reveal three significant impacts of instruction fine-tuning: 1) It empowers LLMs to better recognize the instruction parts from user prompts, thereby facilitating high-quality response generation and addressing the ``lost-in-the-middle'' issue observed in pre-trained models; 2) It aligns the knowledge stored in feed-forward layers with user-oriented tasks, exhibiting minimal shifts across linguistic levels. 3) It facilitates the learning of word-word relations with instruction verbs through the self-attention mechanism, particularly in the lower and middle layers, indicating enhanced recognition of instruction words. These insights contribute to a deeper understanding of the behavior shifts in LLMs after instruction fine-tuning and lay the groundwork for future research aimed at interpreting and optimizing LLMs for various applications. We will release our code and data soon.
LASER: LLM Agent with State-Space Exploration for Web Navigation
Sep 15, 2023



Large language models (LLMs) have been successfully adapted for interactive decision-making tasks like web navigation. While achieving decent performance, previous methods implicitly assume a forward-only execution mode for the model, where they only provide oracle trajectories as in-context examples to teach the model how to reason in the interactive environment. Consequently, the model could not handle more challenging scenarios not covered in the in-context examples, e.g., mistakes, leading to sub-optimal performance. To address this issue, we propose to model the interactive task as state space exploration, where the LLM agent transitions among a pre-defined set of states by performing actions to complete the task. This formulation enables flexible back-tracking, allowing the model to easily recover from errors. We evaluate our proposed LLM Agent with State-Space ExploRation (LASER) on the WebShop task. Experimental results show that our LASER agent significantly outperforms previous methods and closes the gap with human performance on the web navigation task.
Skills-in-Context Prompting: Unlocking Compositionality in Large Language Models
Aug 14, 2023We consider the problem of eliciting compositional generalization capabilities in large language models (LLMs) with a novel type of prompting strategy. Compositional generalization empowers the LLMs to solve problems that are harder than the ones they have seen (i.e., easy-to-hard generalization), which is a critical reasoning capability of human-like intelligence. However, even the current state-of-the-art LLMs still struggle with this form of reasoning. To bridge this gap, we propose skills-in-context (SKiC) prompting, which instructs LLMs how to compose basic skills to resolve more complex problems. We find that it is crucial to demonstrate both the skills and the compositional examples within the same prompting context. With as few as two examplars, our SKiC prompting initiates strong synergies between skills and their composition capabilities. Notably, it empowers LLMs to solve unseen problems that require innovative skill compositions, achieving near-perfect generalization on a broad range of challenging compositionality tasks. Intriguingly, SKiC prompting unlocks the latent potential of LLMs, enabling them to leverage pre-existing internal skills acquired during earlier pre-training stages, even when these skills are not explicitly presented in the prompting context. This results in the capability of LLMs to solve unseen complex problems by activating and composing internal competencies. With such prominent features, SKiC prompting is able to achieve state-of-the-art performance on challenging mathematical reasoning benchmarks (e.g., MATH).
Thrust: Adaptively Propels Large Language Models with External Knowledge
Jul 19, 2023Although large-scale pre-trained language models (PTLMs) are shown to encode rich knowledge in their model parameters, the inherent knowledge in PTLMs can be opaque or static, making external knowledge necessary. However, the existing information retrieval techniques could be costly and may even introduce noisy and sometimes misleading knowledge. To address these challenges, we propose the instance-level adaptive propulsion of external knowledge (IAPEK), where we only conduct the retrieval when necessary. To achieve this goal, we propose measuring whether a PTLM contains enough knowledge to solve an instance with a novel metric, Thrust, which leverages the representation distribution of a small number of seen instances. Extensive experiments demonstrate that thrust is a good measurement of PTLM models' instance-level knowledgeability. Moreover, we can achieve significantly higher cost-efficiency with the Thrust score as the retrieval indicator than the naive usage of external knowledge on 88% of the evaluated tasks with 26% average performance improvement. Such findings shed light on the real-world practice of knowledge-enhanced LMs with a limited knowledge-seeking budget due to computation latency or costs.
MinT: Boosting Generalization in Mathematical Reasoning via Multi-View Fine-Tuning
Jul 16, 2023



Reasoning in mathematical domains remains a significant challenge for relatively small language models (LMs). Many current methods focus on specializing LMs in mathematical reasoning and rely heavily on knowledge distillation from powerful but inefficient large LMs (LLMs). In this work, we explore a new direction that avoids over-reliance on LLM teachers, introducing a multi-view fine-tuning method that efficiently exploits existing mathematical problem datasets with diverse annotation styles. Our approach uniquely considers the various annotation formats as different "views" and leverages them in training the model. By postpending distinct instructions to input questions, models can learn to generate solutions in diverse formats in a flexible manner. Experimental results show that our strategy enables a LLaMA-7B model to outperform prior approaches that utilize knowledge distillation, as well as carefully established baselines. Additionally, the proposed method grants the models promising generalization ability across various views and datasets, and the capability to learn from inaccurate or incomplete noisy data. We hope our multi-view training paradigm could inspire future studies in other machine reasoning domains.
PIVOINE: Instruction Tuning for Open-world Information Extraction
May 24, 2023We consider the problem of Open-world Information Extraction (Open-world IE), which extracts comprehensive entity profiles from unstructured texts. Different from the conventional closed-world setting of Information Extraction (IE), Open-world IE considers a more general situation where entities and relations could be beyond a predefined ontology. More importantly, we seek to develop a large language model (LLM) that is able to perform Open-world IE to extract desirable entity profiles characterized by (possibly fine-grained) natural language instructions. We achieve this by finetuning LLMs using instruction tuning. In particular, we construct INSTRUCTOPENWIKI, a substantial instruction tuning dataset for Open-world IE enriched with a comprehensive corpus, extensive annotations, and diverse instructions. We finetune the pretrained BLOOM models on INSTRUCTOPENWIKI and obtain PIVOINE, an LLM for Open-world IE with strong instruction-following capabilities. Our experiments demonstrate that PIVOINE significantly outperforms traditional closed-world methods and other LLM baselines, displaying impressive generalization capabilities on both unseen instructions and out-of-ontology cases. Consequently, PIVOINE emerges as a promising solution to tackle the open-world challenge in IE effectively.
OASum: Large-Scale Open Domain Aspect-based Summarization
Dec 19, 2022Aspect or query-based summarization has recently caught more attention, as it can generate differentiated summaries based on users' interests. However, the current dataset for aspect or query-based summarization either focuses on specific domains, contains relatively small-scale instances, or includes only a few aspect types. Such limitations hinder further explorations in this direction. In this work, we take advantage of crowd-sourcing knowledge on Wikipedia.org and automatically create a high-quality, large-scale open-domain aspect-based summarization dataset named OASum, which contains more than 3.7 million instances with around 1 million different aspects on 2 million Wikipedia pages. We provide benchmark results on OAsum and demonstrate its ability for diverse aspect-based summarization generation. To overcome the data scarcity problem on specific domains, we also perform zero-shot, few-shot, and fine-tuning on seven downstream datasets. Specifically, zero/few-shot and fine-tuning results show that the model pre-trained on our corpus demonstrates a strong aspect or query-focused generation ability compared with the backbone model. Our dataset and pre-trained checkpoints are publicly available.
ZeroKBC: A Comprehensive Benchmark for Zero-Shot Knowledge Base Completion
Dec 06, 2022Knowledge base completion (KBC) aims to predict the missing links in knowledge graphs. Previous KBC tasks and approaches mainly focus on the setting where all test entities and relations have appeared in the training set. However, there has been limited research on the zero-shot KBC settings, where we need to deal with unseen entities and relations that emerge in a constantly growing knowledge base. In this work, we systematically examine different possible scenarios of zero-shot KBC and develop a comprehensive benchmark, ZeroKBC, that covers these scenarios with diverse types of knowledge sources. Our systematic analysis reveals several missing yet important zero-shot KBC settings. Experimental results show that canonical and state-of-the-art KBC systems cannot achieve satisfactory performance on this challenging benchmark. By analyzing the strength and weaknesses of these systems on solving ZeroKBC, we further present several important observations and promising future directions.
Knowledge-in-Context: Towards Knowledgeable Semi-Parametric Language Models
Oct 28, 2022Fully-parametric language models generally require a huge number of model parameters to store the necessary knowledge for solving multiple natural language tasks in zero/few-shot settings. In addition, it is hard to adapt to the evolving world knowledge without the costly model re-training. In this paper, we develop a novel semi-parametric language model architecture, Knowledge-in-Context (KiC), which empowers a parametric text-to-text language model with a knowledge-rich external memory. Specifically, the external memory contains six different types of knowledge: entity, dictionary, commonsense, event, script, and causality knowledge. For each input instance, the KiC model adaptively selects a knowledge type and retrieves the most helpful pieces of knowledge. The input instance along with its knowledge augmentation is fed into a text-to-text model (e.g., T5) to generate the output answer, where both the input and the output are in natural language forms after prompting. Interestingly, we find that KiC can be identified as a special mixture-of-experts (MoE) model, where the knowledge selector plays the role of a router that is used to determine the sequence-to-expert assignment in MoE. This key observation inspires us to develop a novel algorithm for training KiC with an instance-adaptive knowledge selector. As a knowledge-rich semi-parametric language model, KiC only needs a much smaller parametric part to achieve superior zero-shot performance on unseen tasks. By evaluating on 40+ different tasks, we show that KiC_Large with 770M parameters easily outperforms large language models (LMs) that are 4-39x larger by a large margin. We also demonstrate that KiC exhibits emergent abilities at a much smaller model scale compared to the fully-parametric models.
Zemi: Learning Zero-Shot Semi-Parametric Language Models from Multiple Tasks
Oct 01, 2022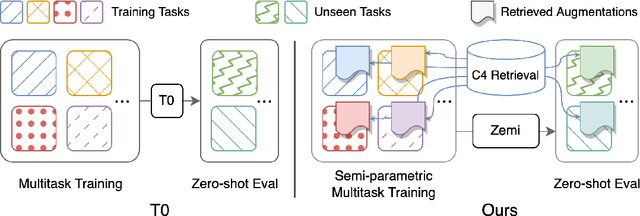
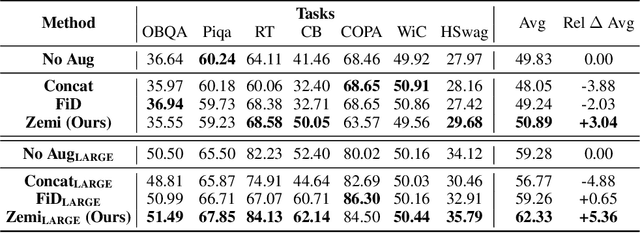
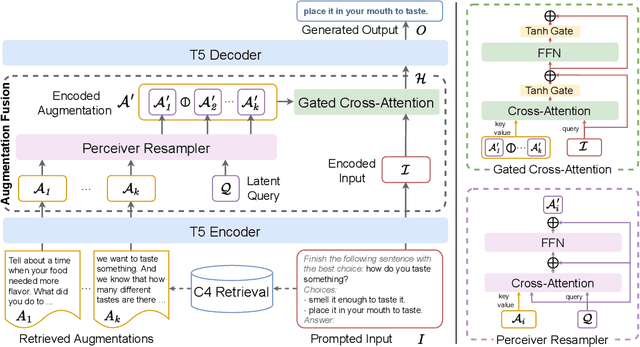
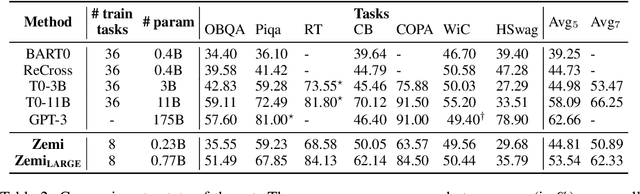
Although large language models have achieved impressive zero-shot ability, the huge model size generally incurs high cost. Recently, semi-parametric language models, which augment a smaller language model with an external retriever, have demonstrated promising language modeling capabilities. However, it remains unclear whether such semi-parametric language models can perform competitively well as their fully-parametric counterparts on zero-shot generalization to downstream tasks. In this work, we introduce $\text{Zemi}$, a zero-shot semi-parametric language model. To our best knowledge, this is the first semi-parametric language model that can demonstrate strong zero-shot performance on a wide range of held-out unseen tasks. We train $\text{Zemi}$ with a novel semi-parametric multitask prompted training paradigm, which shows significant improvement compared with the parametric multitask training as proposed by T0. Specifically, we augment the multitask training and zero-shot evaluation with retrieval from a large-scale task-agnostic unlabeled corpus. In order to incorporate multiple potentially noisy retrieved augmentations, we further propose a novel $\text{augmentation fusion}$ module leveraging perceiver resampler and gated cross-attention. Notably, our proposed $\text{Zemi}_\text{LARGE}$ outperforms T0-3B by 16% on all seven evaluation tasks while being 3.9x smaller in model size.