 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure Guided Lane Detection
May 12, 2021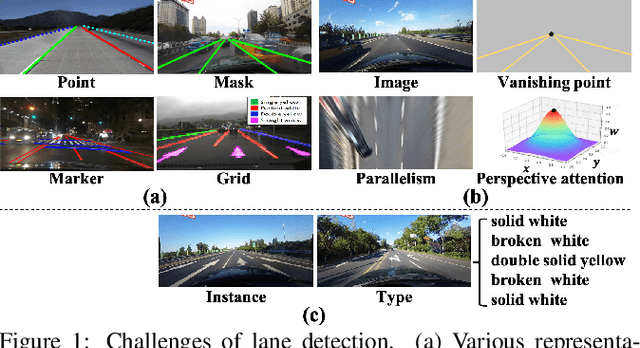
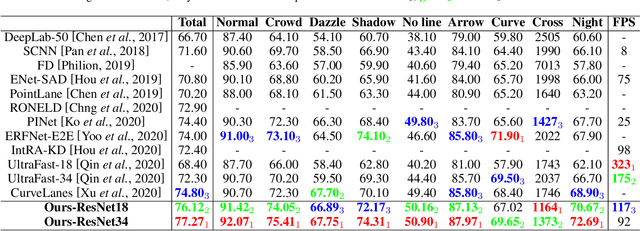
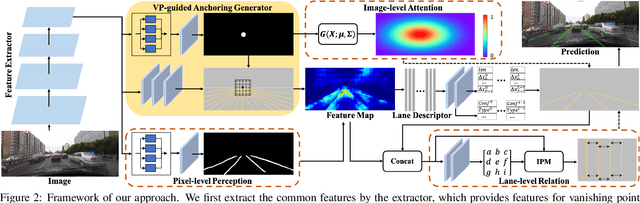
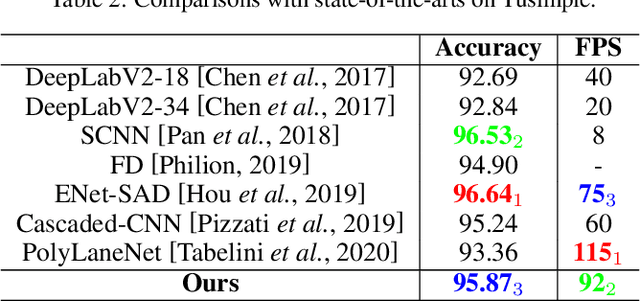
Recently, lane detection has made great progress with the rapid development of deep neural networks and autonomous driving. However, there exist three mainly problems including characterizing lanes, modeling the structural relationship between scenes and lanes, and supporting more attributes (e.g., instance and type) of lanes. In this paper, we propose a novel structure guided framework to solve these problems simultaneously. In the framework, we first introduce a new lane representation to characterize each instance. Then a topdown vanishing point guided anchoring mechanism is proposed to produce intensive anchors, which efficiently capture various lanes. Next, multi-level structural constraints are used to improve the perception of lanes. In the process, pixel-level perception with binary segmentation is introduced to promote features around anchors and restore lane details from bottom up, a lane-level relation is put forward to model structures (i.e., parallel) around lanes, and an image-level attention is used to adaptively attend different regions of the image from the perspective of scenes. With the help of structural guidance, anchors are effectively classified and regressed to obtain precise locations and shapes. Extensive experiments on public benchmark datasets show that the proposed approach outperforms state-of-the-art methods with 117 FPS on a single GPU.
Twins: Revisiting the Design of Spatial Attention in Vision Transformers
May 11, 2021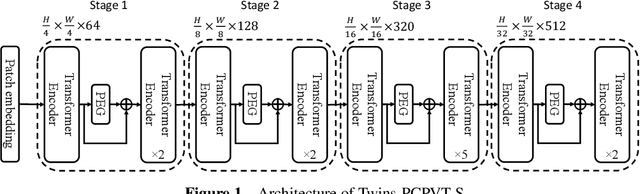
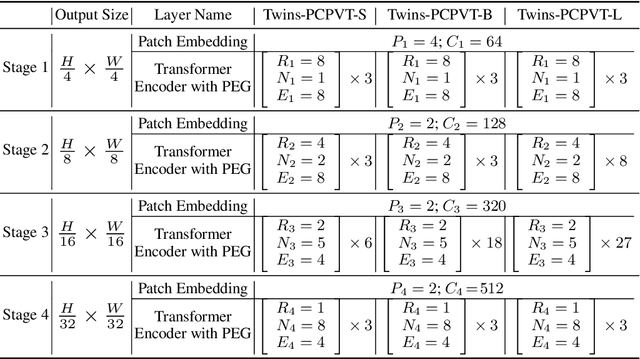
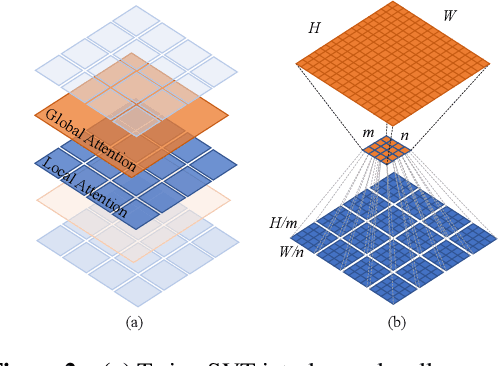
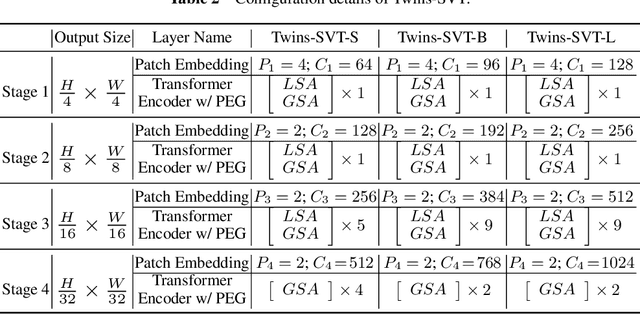
Very recently, a variety of vision transformer architectures for dense prediction tasks have been proposed and they show that the design of spatial attention is critical to their success in these tasks. In this work, we revisit the design of the spatial attention and demonstrate that a carefully-devised yet simple spatial attention mechanism performs favourably against the state-of-the-art schemes. As a result, we propose two vision transformer architectures, namely, Twins-PCPVT and Twins-SVT. Our proposed architectures are highly-efficient and easy to implement, only involving matrix multiplications that are highly optimized in modern deep learning frameworks. More importantly, the proposed architectures achieve excellent performance on a wide range of visual tasks including imagelevel classification as well as dense detection and segmentation. The simplicity and strong performance suggest that our proposed architectures may serve as stronger backbones for many vision tasks. Our code will be released soon at https://github.com/Meituan-AutoML/Twins .
Rethinking BiSeNet For Real-time Semantic Segmentation
Apr 27, 2021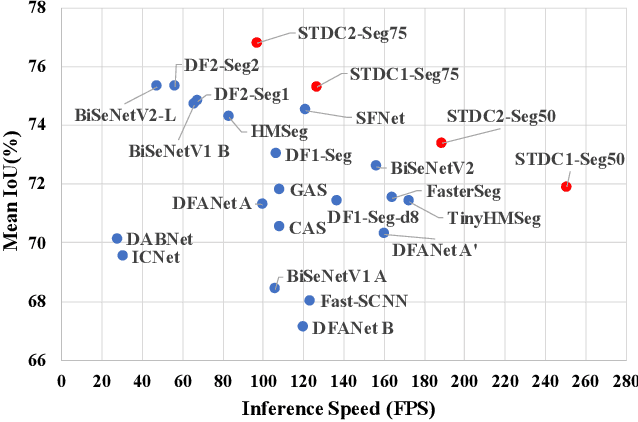
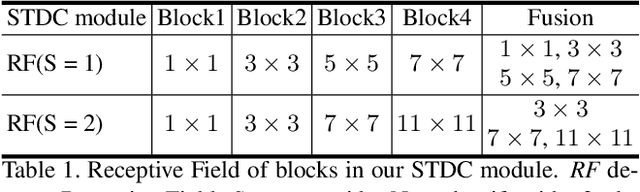
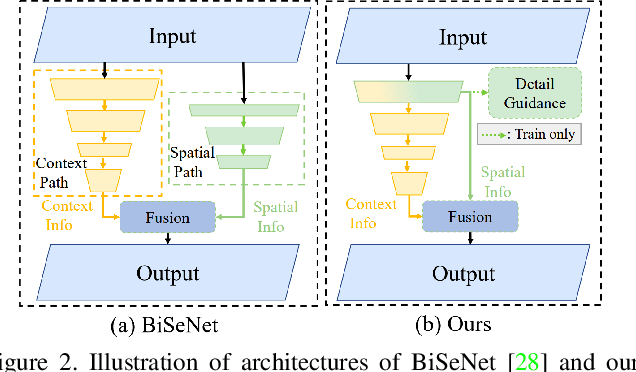
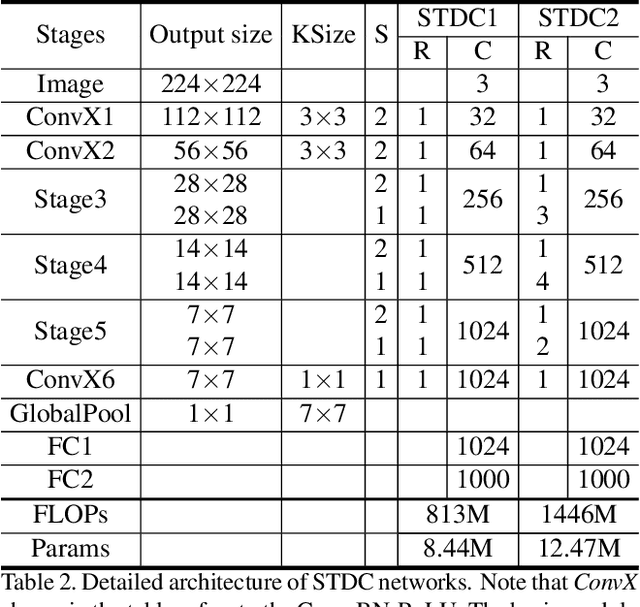
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
Large Scale Visual Food Recognition
Mar 31, 2021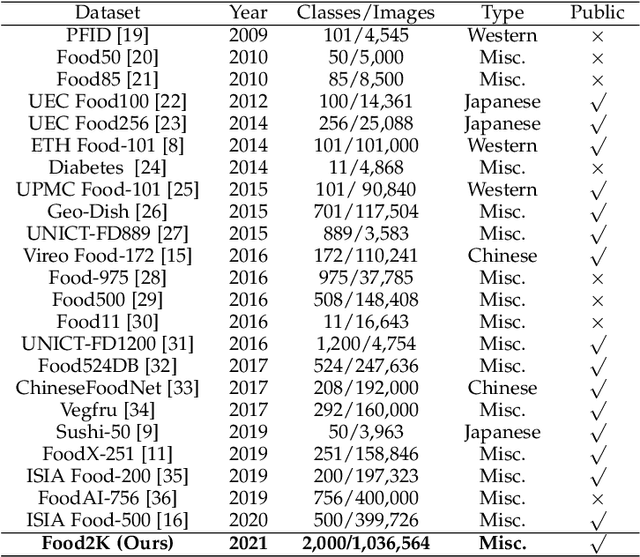
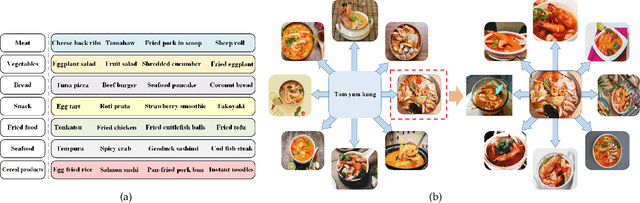

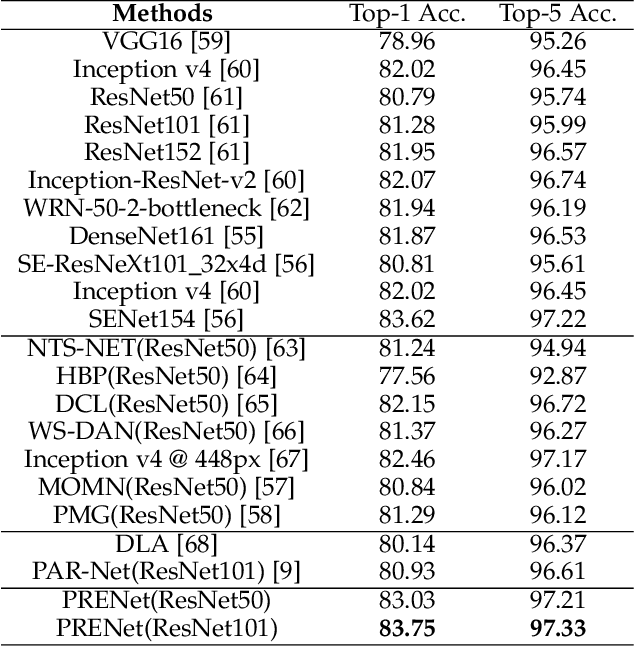
Food recognition plays an important role in food choice and intake, which is essential to the health and well-being of humans. It is thus of importance to the computer vision community, and can further support many food-oriented vision and multimodal tasks. Unfortunately, we have witnessed remarkable advancements in generic visual recognition for released large-scale datasets, yet largely lags in the food domain. In this paper, we introduce Food2K, which is the largest food recognition dataset with 2,000 categories and over 1 million images.Compared with existing food recognition datasets, Food2K bypasses them in both categories and images by one order of magnitude, and thus establishes a new challenging benchmark to develop advanced models for food visual representation learning. Furthermore, we propose a deep progressive region enhancement network for food recognition, which mainly consists of two components, namely progressive local feature learning and region feature enhancement. The former adopts improved progressive training to learn diverse and complementary local features, while the latter utilizes self-attention to incorporate richer context with multiple scales into local features for further local feature enhancement. Extensive experiments on Food2K demonstrate the effectiveness of our proposed method. More importantly, we have verified better generalization ability of Food2K in various tasks, including food recognition, food image retrieval, cross-modal recipe retrieval, food detection and segmentation. Food2K can be further explored to benefit more food-relevant tasks including emerging and more complex ones (e.g., nutritional understanding of food), and the trained models on Food2K can be expected as backbones to improve the performance of more food-relevant tasks. We also hope Food2K can serve as a large scale fine-grained visual recognition benchmark.
Conditional Positional Encodings for Vision Transformers
Mar 18, 2021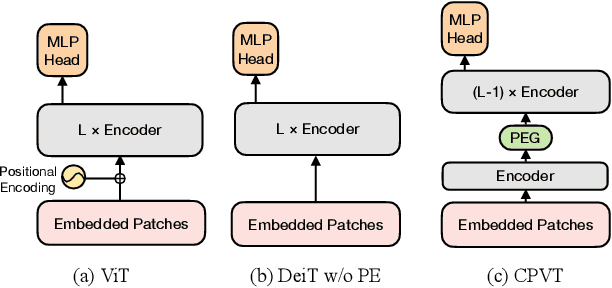
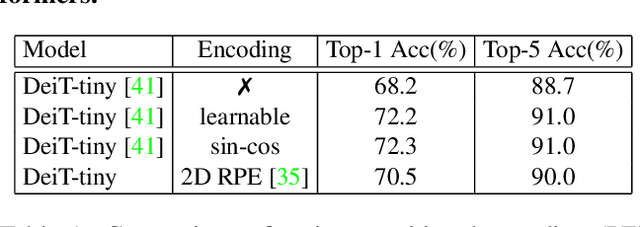
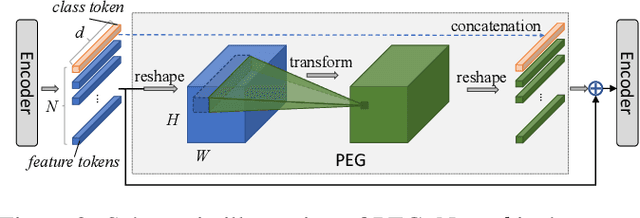
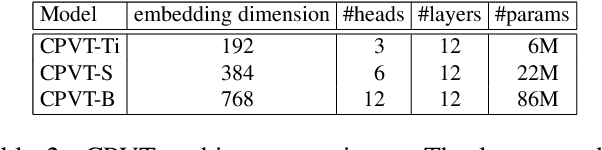
We propose a conditional positional encoding (CPE) scheme for vision Transformers. Unlike previous fixed or learnable positional encodings, which are pre-defined and independent of input tokens, CPE is dynamically generated and conditioned on the local neighborhood of the input tokens. As a result, CPE can easily generalize to the input sequences that are longer than what the model has ever seen during training. Besides, CPE can keep the desired translation-invariance in the image classification task, resulting in improved classification accuracy. CPE can be effortlessly implemented with a simple Position Encoding Generator (PEG), and it can be seamlessly incorporated into the current Transformer framework. Built on PEG, we present Conditional Position encoding Vision Transformer (CPVT). We demonstrate that CPVT has visually similar attention maps compared to those with learned positional encodings. Benefit from the conditional positional encoding scheme, we obtain state-of-the-art results on the ImageNet classification task compared with vision Transformers to date. Our code will be made available at https://github.com/Meituan-AutoML/CPVT .
Scene Text Detection with Scribble Lines
Dec 10, 2020
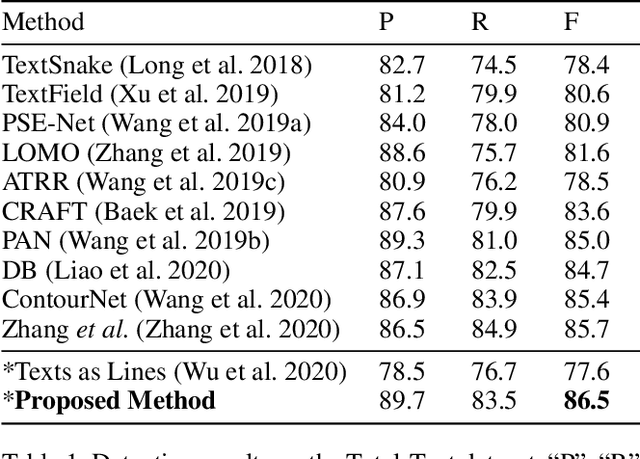
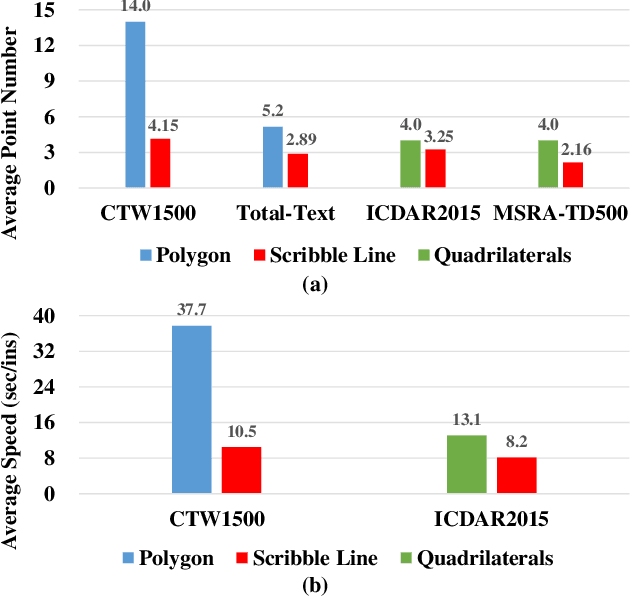
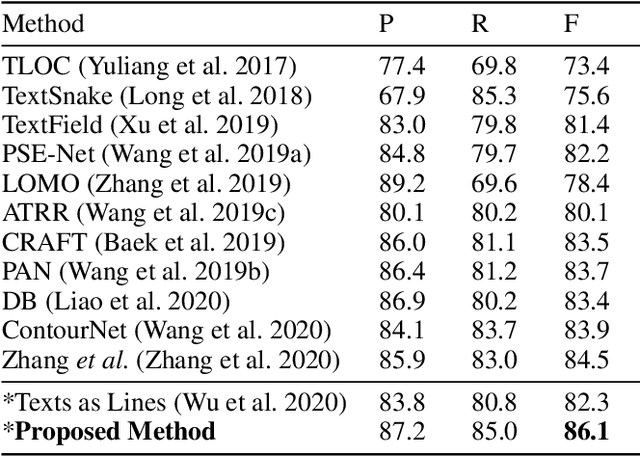
Scene text detection, which is one of the most popular topics in both academia and industry, can achieve remarkable performance with sufficient training data. However, the annotation costs of scene text detection are huge with traditional labeling methods due to the various shapes of texts. Thus, it is practical and insightful to study simpler labeling methods without harming the detection performance. In this paper, we propose to annotate the texts by scribble lines instead of polygons for text detection. It is a general labeling method for texts with various shapes and requires low labeling costs. Furthermore, a weakly-supervised scene text detection framework is proposed to use the scribble lines for text detection. The experiments on several benchmarks show that the proposed method bridges the performance gap between the weakly labeling method and the original polygon-based labeling methods, with even better performance. We will release the weak annotations of the benchmarks in our experiments and hope it will benefit the field of scene text detection to achieve better performance with simpler annotations.
Beyond Single Instance Multi-view Unsupervised Representation Learning
Nov 26, 2020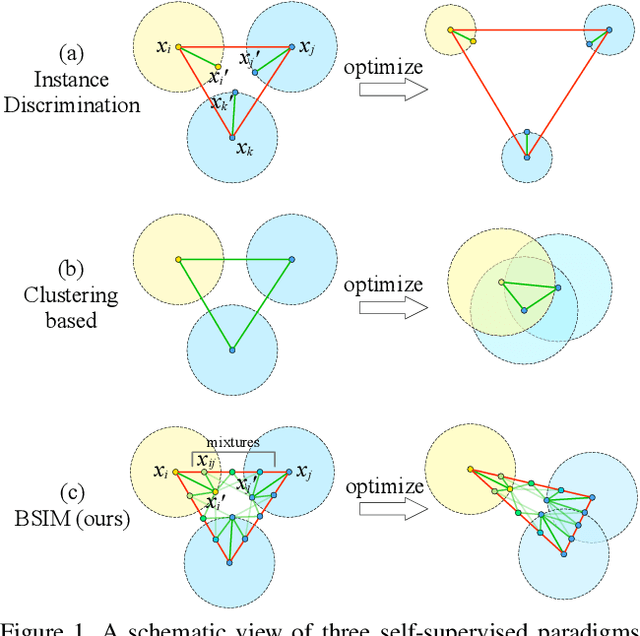
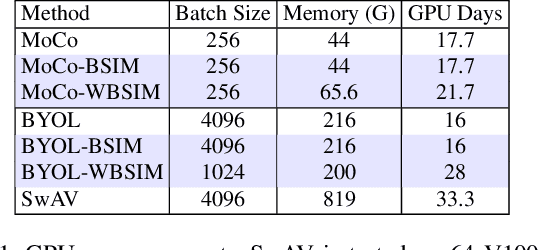
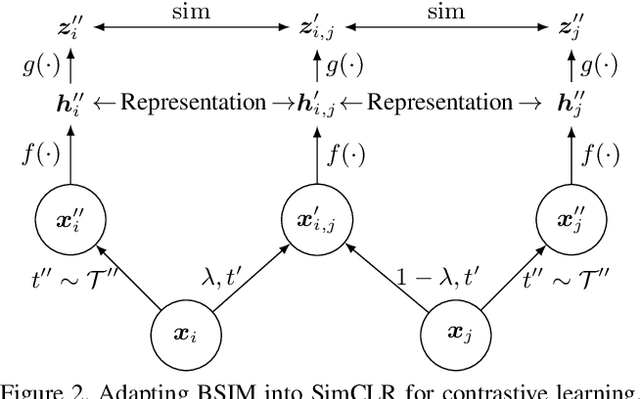
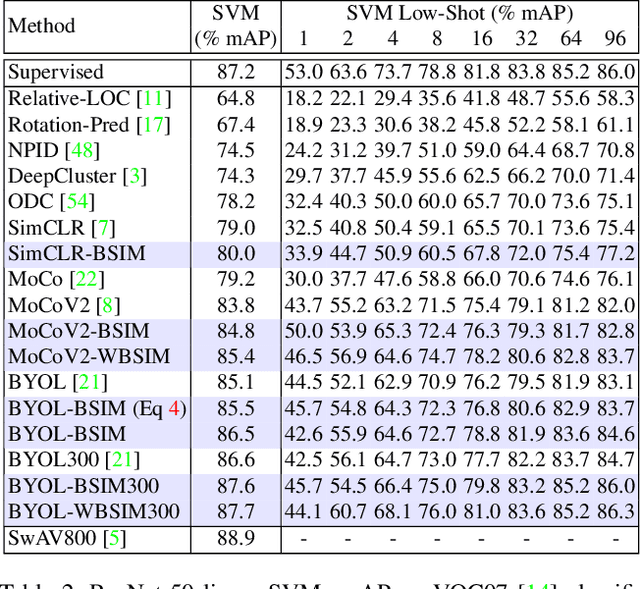
Recent unsupervised contrastive representation learning follows a Single Instance Multi-view (SIM) paradigm where positive pairs are usually constructed with intra-image data augmentation. In this paper, we propose an effective approach called Beyond Single Instance Multi-view (BSIM). Specifically, we impose more accurate instance discrimination capability by measuring the joint similarity between two randomly sampled instances and their mixture, namely spurious-positive pairs. We believe that learning joint similarity helps to improve the performance when encoded features are distributed more evenly in the latent space. We apply it as an orthogonal improvement for unsupervised contrastive representation learning, including current outstanding methods SimCLR, MoCo, and BYOL. We evaluate our learned representations on many downstream benchmarks like linear classification on ImageNet-1k and PASCAL VOC 2007, object detection on MS COCO 2017 and VOC, etc. We obtain substantial gains with a large margin almost on all these tasks compared with prior arts.
ROME: Robustifying Memory-Efficient NAS via Topology Disentanglement and Gradients Accumulation
Nov 23, 2020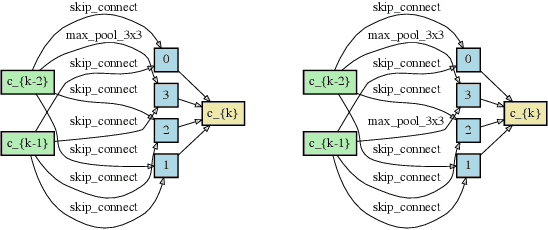

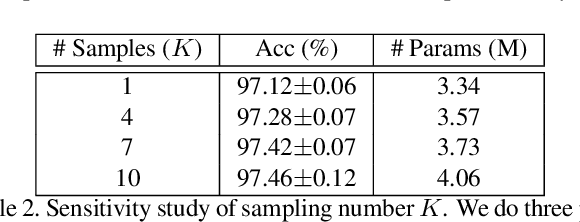
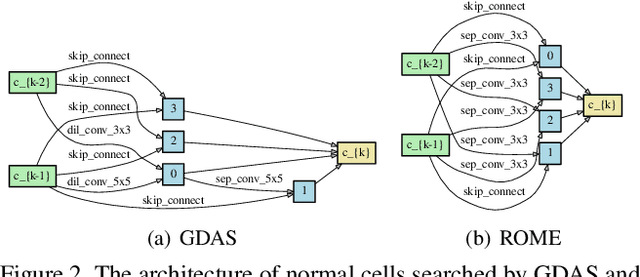
Single-path based differentiable neural architecture search has great strengths for its low computational cost and memory-friendly nature. However, we surprisingly discover that it suffers from severe searching instability which has been primarily ignored, posing a potential weakness for a wider application. In this paper, we delve into its performance collapse issue and propose a new algorithm called RObustifying Memory-Efficient NAS (ROME). Specifically, 1) for consistent topology in the search and evaluation stage, we involve separate parameters to disentangle the topology from the operations of the architecture. In such a way, we can independently sample connections and operations without interference; 2) to discount sampling unfairness and variance, we enforce fair sampling for weight update and apply a gradient accumulation mechanism for architecture parameters. Extensive experiments demonstrate that our proposed method has strong performance and robustness, where it mostly achieves state-of-the-art results on a large number of standard benchmarks.
Free-Form Image Inpainting via Contrastive Attention Network
Oct 29, 2020
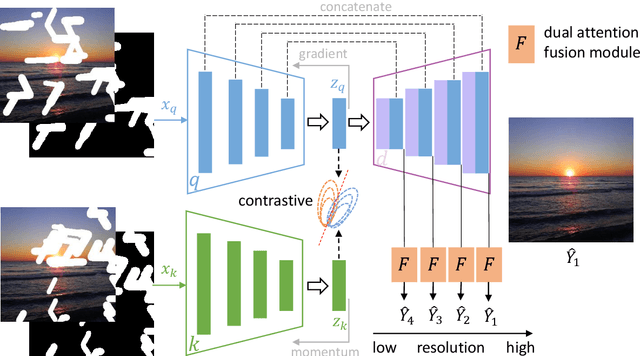
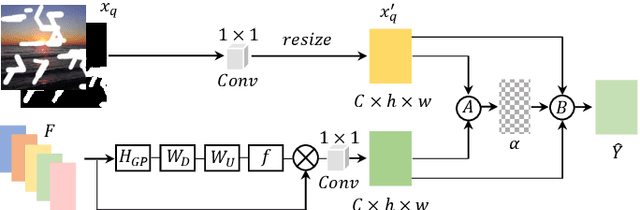

Most deep learning based image inpainting approaches adopt autoencoder or its variants to fill missing regions in images. Encoders are usually utilized to learn powerful representational spaces, which are important for dealing with sophisticated learning tasks. Specifically, in image inpainting tasks, masks with any shapes can appear anywhere in images (i.e., free-form masks) which form complex patterns. It is difficult for encoders to capture such powerful representations under this complex situation. To tackle this problem, we propose a self-supervised Siamese inference network to improve the robustness and generalization. It can encode contextual semantics from full resolution images and obtain more discriminative representations. we further propose a multi-scale decoder with a novel dual attention fusion module (DAF), which can combine both the restored and known regions in a smooth way. This multi-scale architecture is beneficial for decoding discriminative representations learned by encoders into images layer by layer. In this way, unknown regions will be filled naturally from outside to inside. Qualitative and quantitative experiments on multiple datasets, including facial and natural datasets (i.e., Celeb-HQ, Pairs Street View, Places2 and ImageNet), demonstrate that our proposed method outperforms state-of-the-art methods in generating high-quality inpainting results.
DARTS-: Robustly Stepping out of Performance Collapse Without Indicators
Sep 02, 2020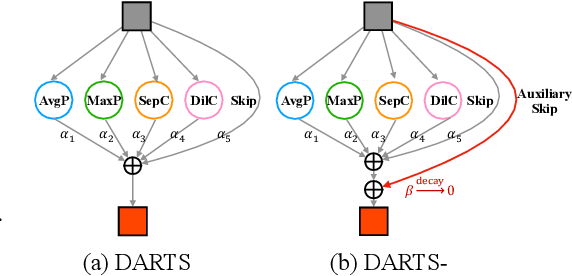
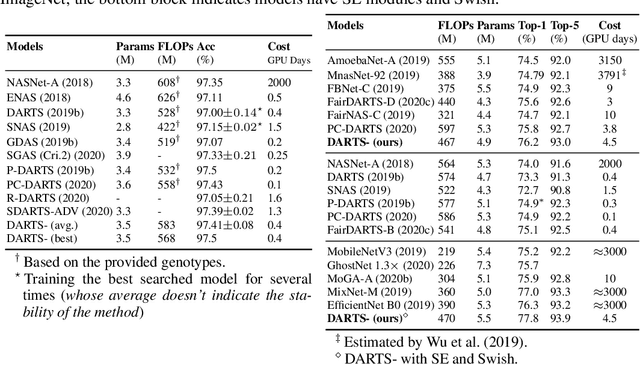

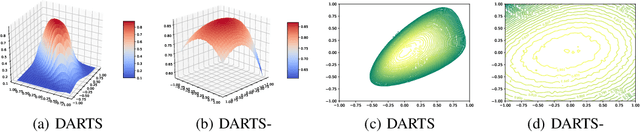
Despite the fast development of differentiable architecture search (DARTS), it suffers from a standing instability issue regarding searching performance, which extremely limits its application. Existing robustifying methods draw clues from the outcome instead of finding out the causing factor. Various indicators such as Hessian eigenvalues are proposed as a signal of performance collapse, and the searching should be stopped once an indicator reaches a preset threshold. However, these methods tend to easily reject good architectures if thresholds are inappropriately set, let alone the searching is intrinsically noisy. In this paper, we undertake a more subtle and direct approach to resolve the collapse. We first demonstrate that skip connections with a learnable architectural coefficient can easily recover from a disadvantageous state and become dominant. We conjecture that skip connections profit too much from this privilege, hence causing the collapse for the derived model. Therefore, we propose to factor out this benefit with an auxiliary skip connection, ensuring a fairer competition for all operations. Extensive experiments on various datasets verify that our approach can substantially improve the robustness of DARTS.