 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Forcing Planner: History-Annealed Planning with Time-Dependent Guidance for Autonomous Driving
Jun 09, 2026Learning-based motion planners, despite recent progress, often suffer from temporal inconsistency. Small perturbations across frames can accumulate into unstable trajectories, degrading comfort and safety in closed-loop driving. Several methods attempt to inject history as a static conditioning signal to stabilize outputs, only to induce the planner to copy historical patterns instead of adapting to environment contexts. To address this limitation, we propose Diffusion Forcing Planner (DFP), a diffusion-based planning framework driven by history-guided control. Specifically, DFP decomposes the full trajectory into history, current and future segments, and assign independent noise levels to each segment. The model jointly denoises the historical and the future segments, enforcing a heterogeneous joint diffusion process. At inference, classifier-free guidance (CFG) is applied to steer future sampling using annealed history in a controllable manner. Closed-loop evaluation and comprehensive ablations on nuPlan show that DFP achieves competitive performance while producing continuous, stable, and controllable motion plans in complex driving scenarios.
Rethinking Local Learning: A Cheaper and Faster Recipe for LLM Post-Training
May 06, 2026LLM post-training typically propagates task gradients through the full depth of the model. Although this end-to-end structure is simple and general, it couples task adaptation to full-depth activation storage, long-range backward dependencies and direct task-gradient access to pretrained representations. We argue that this full-depth backward coupling can be unnecessarily expensive and intrusive, particularly when post-training supervision is much narrower than pre-training. To this end, we propose \textbf{LoPT}: Local-Learning Post-Training, a simple post-training strategy that makes gradient reach an explicit design choice. LoPT places a single gradient boundary at the transformer midpoint: the second-half block learns from the task objective, while the first-half block is updated by a lightweight feature-reconstruction objective to preserve useful representations and maintain interface compatibility. LoPT shortens the task-induced backward path while limiting direct interference from narrow task gradients on early-layer representations. Extensive experiments demonstrate that LoPT achieves competitive performance with lower memory cost, higher training efficiency and better retention of pretrained capabilities. Our code is available at: https://github.com/HumyuShi/LoPT
Correct Is Not Enough: Training Reasoning Planners with Executor-Grounded Rewards
May 05, 2026Reinforcement learning with verifiable rewards has become a common way to improve explicit reasoning in large language models, but final-answer correctness alone does not reveal whether the reasoning trace is faithful, reliable, or useful to the model that consumes it. This outcome-only signal can reinforce traces that are right for the wrong reasons, overstate reasoning gains by rewarding shortcuts, and propagate flawed intermediate states in multi-step systems. To this end, we propose TraceLift, a planner-executor training framework that treats reasoning as a consumable intermediate artifact. During planner training, the planner emits tagged reasoning. A frozen executor turns this reasoning into the final artifact for verifier feedback, while an executor-grounded reward shapes the intermediate trace. This reward multiplies a rubric-based Reasoning Reward Model (RM) score by measured uplift on the same frozen executor, crediting traces that are both high-quality and useful. To make reasoning quality directly learnable, we introduce TRACELIFT-GROUPS, a rubric-annotated reason-only dataset built from math and code seed problems. Each example is a same-problem group containing a high-quality reference trace and multiple plausible flawed traces with localized perturbations that reduce reasoning quality or solution support while preserving task relevance. Extensive experiments on code and math benchmarks show that this executor-grounded reasoning reward improves the two-stage planner-executor system over execution-only training, suggesting that reasoning supervision should evaluate not only whether a trace looks good, but also whether it helps the model that consumes it.
CMSG Cross-Media Semantic-Graph Feature Matching Algorithm for Autonomous Vehicle Relocalization
May 15, 2023



Relocalization is the basis of map-based localization algorithms. Camera and LiDAR map-based methods are pervasive since their robustness under different scenarios. Generally, mapping and localization using the same sensor have better accuracy since matching features between the same type of data is easier. However, due to the camera's lack of 3D information and the high cost of LiDAR, cross-media methods are developing, which combined live image data and Lidar map. Although matching features between different media is challenging, we believe cross-media is the tendency for AV relocalization since its low cost and accuracy can be comparable to the same-sensor-based methods. In this paper, we propose CMSG, a novel cross-media algorithm for AV relocalization tasks. Semantic features are utilized for better interpretation the correlation between point clouds and image features. What's more, abstracted semantic graph nodes are introduced, and a graph network architecture is integrated to better extract the similarity of semantic features. Validation experiments are conducted on the KITTI odometry dataset. Our results show that CMSG can have comparable or even better accuracy compared to current single-sensor-based methods at a speed of 25 FPS on NVIDIA 1080 Ti GPU.
RCP-RF: A Comprehensive Road-car-pedestrian Risk Management Framework based on Driving Risk Potential Field
May 04, 2023



Recent years have witnessed the proliferation of traffic accidents, which led wide researches on Automated Vehicle (AV) technologies to reduce vehicle accidents, especially on risk assessment framework of AV technologies. However, existing time-based frameworks can not handle complex traffic scenarios and ignore the motion tendency influence of each moving objects on the risk distribution, leading to performance degradation. To address this problem, we novelly propose a comprehensive driving risk management framework named RCP-RF based on potential field theory under Connected and Automated Vehicles (CAV) environment, where the pedestrian risk metric are combined into a unified road-vehicle driving risk management framework. Different from existing algorithms, the motion tendency between ego and obstacle cars and the pedestrian factor are legitimately considered in the proposed framework, which can improve the performance of the driving risk model. Moreover, it requires only O(N 2) of time complexity in the proposed method. Empirical studies validate the superiority of our proposed framework against state-of-the-art methods on real-world dataset NGSIM and real AV platform.
A New Adaptive Noise Covariance Matrices Estimation and Filtering Method: Application to Multi-Object Tracking
Dec 20, 2021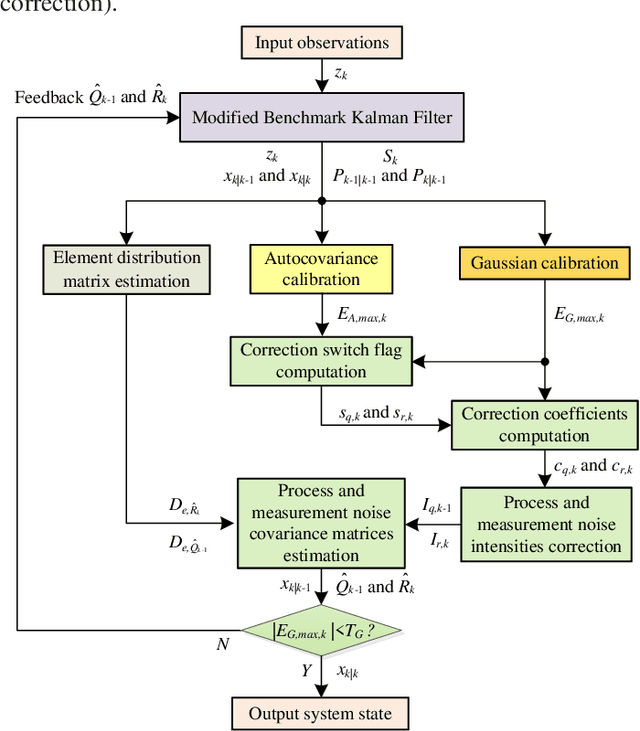
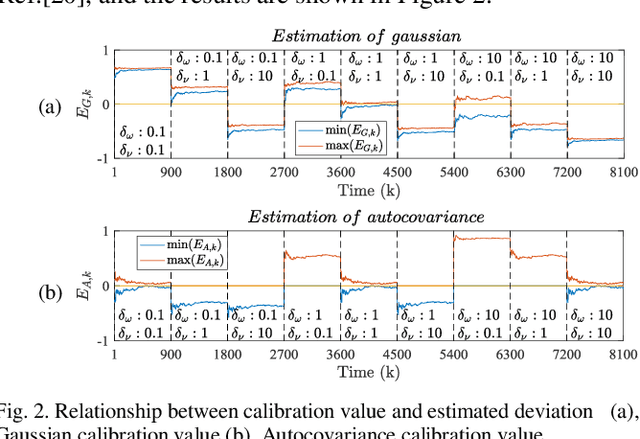
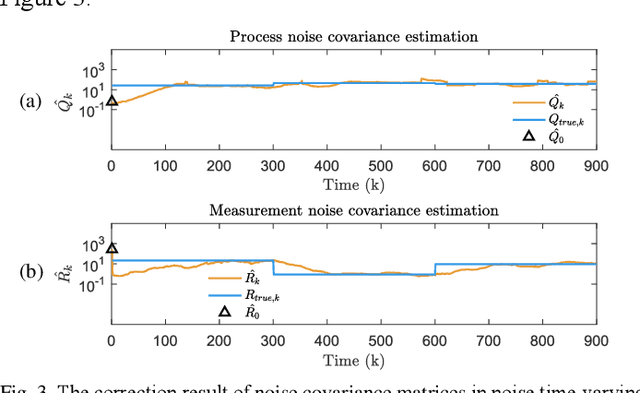
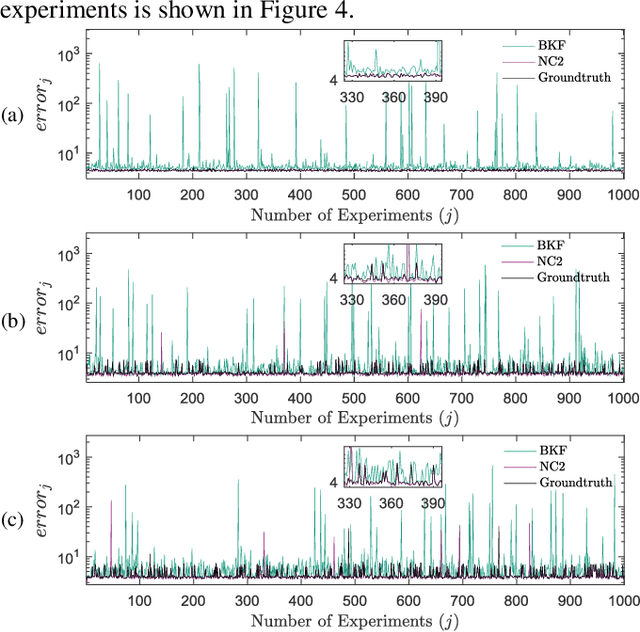
Kalman filters are widely used for object tracking, where process and measurement noise are usually considered accurately known and constant. However, the exact known and constant assumptions do not always hold in practice. For example, when lidar is used to track noncooperative targets, the measurement noise is different under different distances and weather conditions. In addition, the process noise changes with the object's motion state, especially when the tracking object is a pedestrian, and the process noise changes more frequently. This paper proposes a new estimation-calibration-correction closed-loop estimation method to estimate the Kalman filter process and measurement noise covariance matrices online. First, we decompose the noise covariance matrix into an element distribution matrix and noise intensity and improve the Sage filter to estimate the element distribution matrix. Second, we propose a calibration method to accurately diagnose the noise intensity deviation. We then propose a correct method to adaptively correct the noise intensity online. Third, under the assumption that the system is detectable, the unbiased and convergence of the proposed method is mathematically proven. Simulation results prove the effectiveness and reliability of the proposed method. Finally, we apply the proposed method to multiobject tracking of lidar and evaluate it on the official KITTI server. The proposed method on the KITTI pedestrian multiobject tracking leaderboard (http://www.cvlibs.net/datasets /kitti/eval_tracking.php) surpasses all existing methods using lidar, proving the feasibility of the method in practical applications. This work provides a new way to improve the performance of the Kalman filter and multiobject tracking.
Large Scale Visual Food Recognition
Mar 31, 2021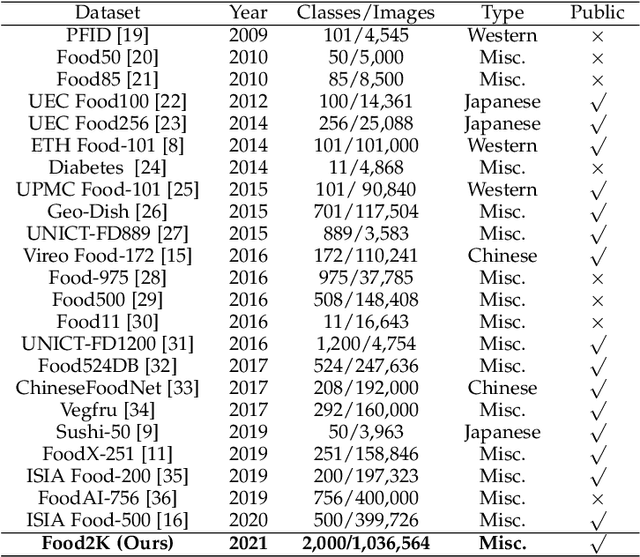
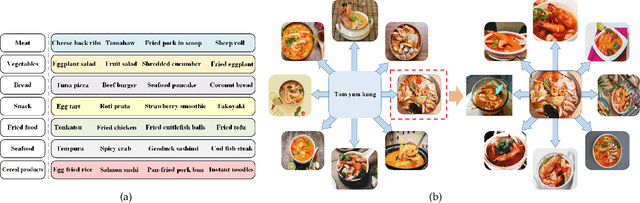

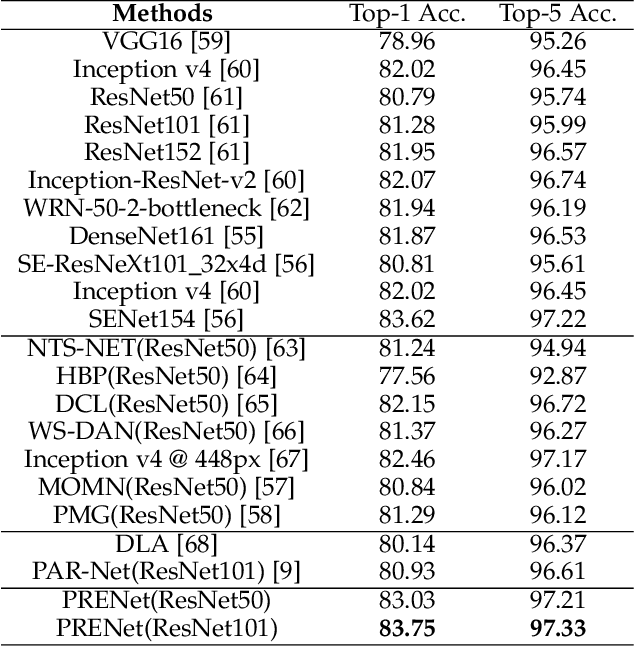
Food recognition plays an important role in food choice and intake, which is essential to the health and well-being of humans. It is thus of importance to the computer vision community, and can further support many food-oriented vision and multimodal tasks. Unfortunately, we have witnessed remarkable advancements in generic visual recognition for released large-scale datasets, yet largely lags in the food domain. In this paper, we introduce Food2K, which is the largest food recognition dataset with 2,000 categories and over 1 million images.Compared with existing food recognition datasets, Food2K bypasses them in both categories and images by one order of magnitude, and thus establishes a new challenging benchmark to develop advanced models for food visual representation learning. Furthermore, we propose a deep progressive region enhancement network for food recognition, which mainly consists of two components, namely progressive local feature learning and region feature enhancement. The former adopts improved progressive training to learn diverse and complementary local features, while the latter utilizes self-attention to incorporate richer context with multiple scales into local features for further local feature enhancement. Extensive experiments on Food2K demonstrate the effectiveness of our proposed method. More importantly, we have verified better generalization ability of Food2K in various tasks, including food recognition, food image retrieval, cross-modal recipe retrieval, food detection and segmentation. Food2K can be further explored to benefit more food-relevant tasks including emerging and more complex ones (e.g., nutritional understanding of food), and the trained models on Food2K can be expected as backbones to improve the performance of more food-relevant tasks. We also hope Food2K can serve as a large scale fine-grained visual recognition benchmark.
A Fast Point Cloud Ground Segmentation Approach Based on Coarse-To-Fine Markov Random Field
Nov 26, 2020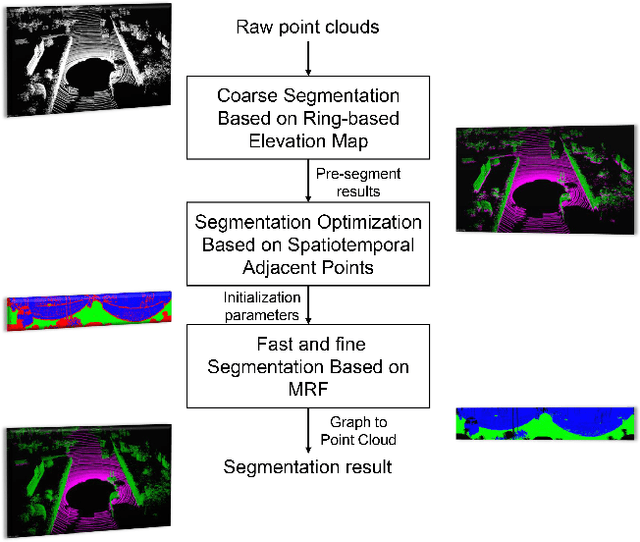
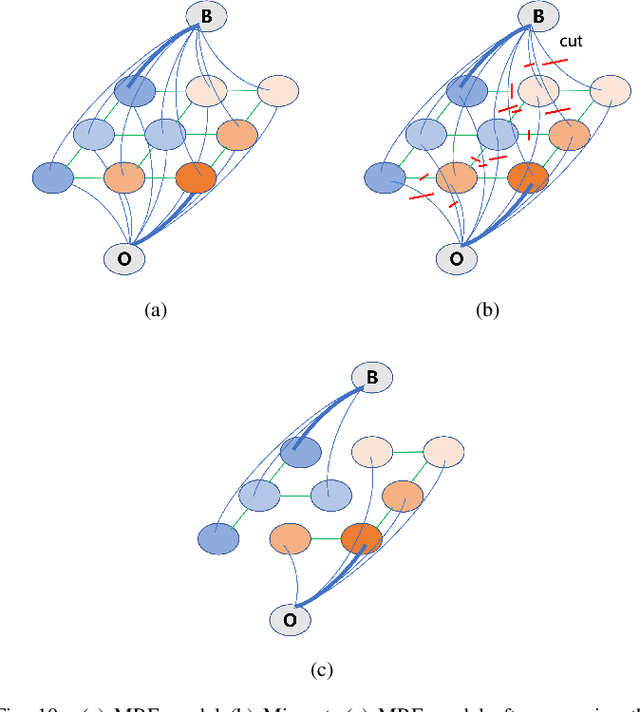
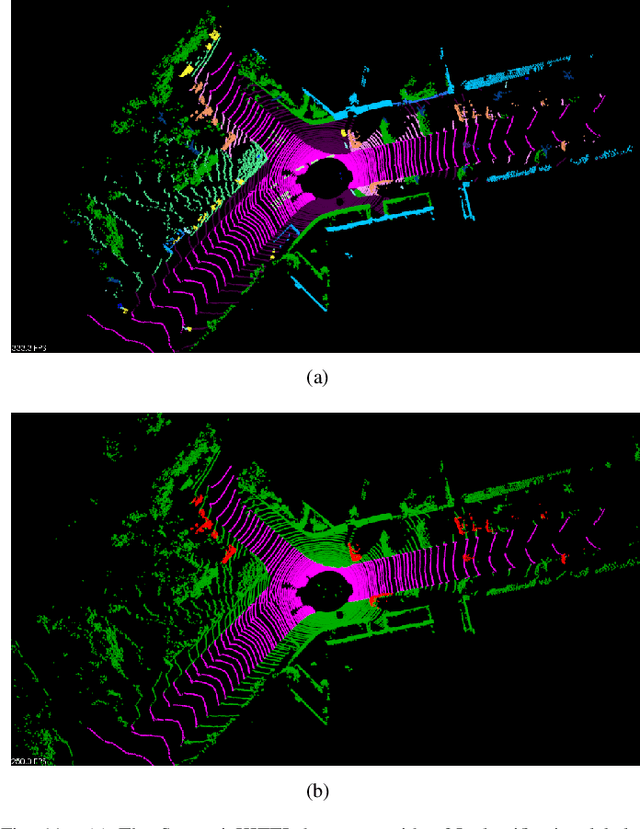
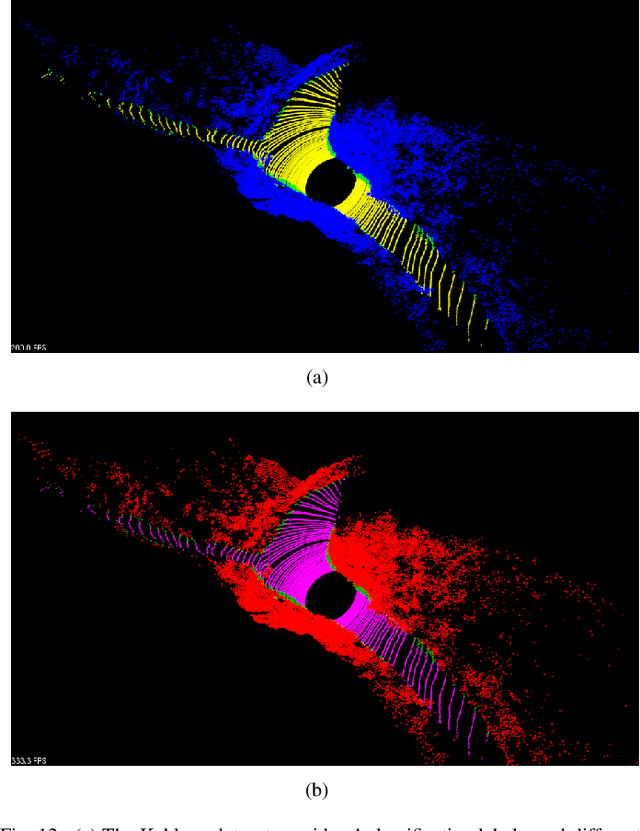
Ground segmentation is an important preprocessing task for autonomous vehicles (AVs) with 3D LiDARs. To solve the problem of existing ground segmentation methods being very difficult to balance accuracy and computational complexity, a fast point cloud ground segmentation approach based on a coarse-to-fine Markov random field (MRF) method is proposed. The method uses an improved elevation map for ground coarse segmentation, and then uses spatiotemporal adjacent points to optimize the segmentation results. The processed point cloud is classified into high-confidence obstacle points, ground points, and unknown classification points to initialize an MRF model. The graph cut method is then used to solve the model to achieve fine segmentation. Experiments on datasets showed that our method improves on other algorithms in terms of ground segmentation accuracy and is faster than other graph-based algorithms, which require only a single core of an I7-3770 CPU to process a frame of Velodyne HDL-64E data (in 39.77 ms, on average). Field tests were also conducted to demonstrate the effectiveness of the proposed method.
ISIA Food-500: A Dataset for Large-Scale Food Recognition via Stacked Global-Local Attention Network
Aug 13, 2020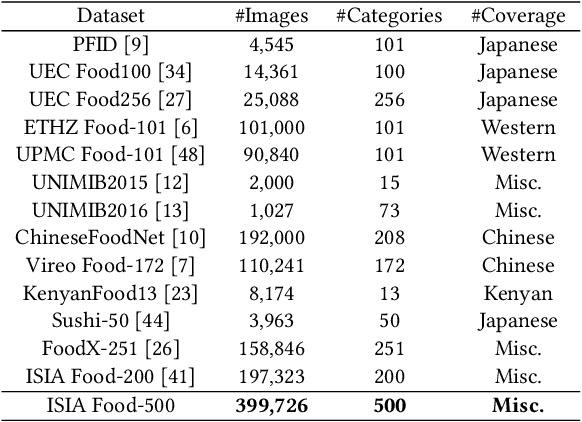

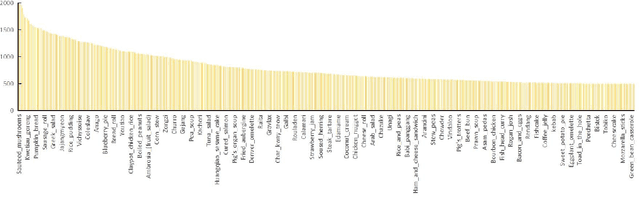
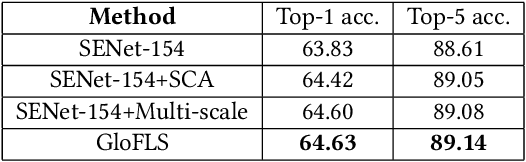
Food recognition has received more and more attention in the multimedia community for its various real-world applications, such as diet management and self-service restaurants. A large-scale ontology of food images is urgently needed for developing advanced large-scale food recognition algorithms, as well as for providing the benchmark dataset for such algorithms. To encourage further progress in food recognition, we introduce the dataset ISIA Food- 500 with 500 categories from the list in the Wikipedia and 399,726 images, a more comprehensive food dataset that surpasses existing popular benchmark datasets by category coverage and data volume. Furthermore, we propose a stacked global-local attention network, which consists of two sub-networks for food recognition. One subnetwork first utilizes hybrid spatial-channel attention to extract more discriminative features, and then aggregates these multi-scale discriminative features from multiple layers into global-level representation (e.g., texture and shape information about food). The other one generates attentional regions (e.g., ingredient relevant regions) from different regions via cascaded spatial transformers, and further aggregates these multi-scale regional features from different layers into local-level representation. These two types of features are finally fused as comprehensive representation for food recognition. Extensive experiments on ISIA Food-500 and other two popular benchmark datasets demonstrate the effectiveness of our proposed method, and thus can be considered as one strong baseline. The dataset, code and models can be found at http://123.57.42.89/FoodComputing-Dataset/ISIA-Food500.html.