 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarten: Visual Question Answering with Mask Generation for Multi-modal Document Understanding
Mar 18, 2025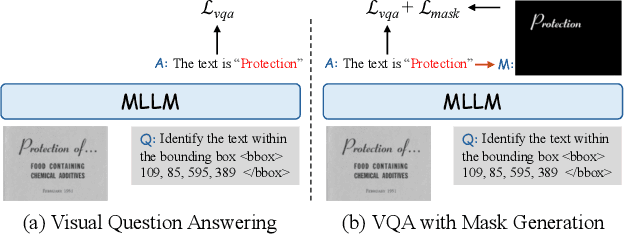
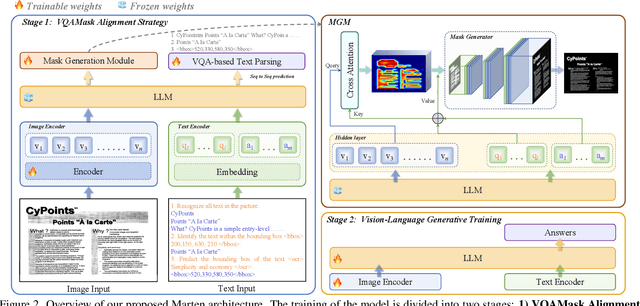

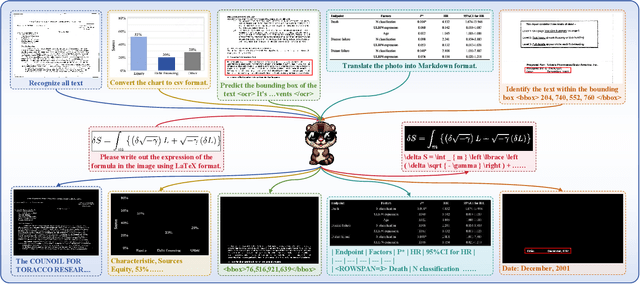
Multi-modal Large Language Models (MLLMs) have introduced a novel dimension to document understanding, i.e., they endow large language models with visual comprehension capabilities; however, how to design a suitable image-text pre-training task for bridging the visual and language modality in document-level MLLMs remains underexplored. In this study, we introduce a novel visual-language alignment method that casts the key issue as a Visual Question Answering with Mask generation (VQAMask) task, optimizing two tasks simultaneously: VQA-based text parsing and mask generation. The former allows the model to implicitly align images and text at the semantic level. The latter introduces an additional mask generator (discarded during inference) to explicitly ensure alignment between visual texts within images and their corresponding image regions at a spatially-aware level. Together, they can prevent model hallucinations when parsing visual text and effectively promote spatially-aware feature representation learning. To support the proposed VQAMask task, we construct a comprehensive image-mask generation pipeline and provide a large-scale dataset with 6M data (MTMask6M). Subsequently, we demonstrate that introducing the proposed mask generation task yields competitive document-level understanding performance. Leveraging the proposed VQAMask, we introduce Marten, a training-efficient MLLM tailored for document-level understanding. Extensive experiments show that our Marten consistently achieves significant improvements among 8B-MLLMs in document-centric tasks. Code and datasets are available at https://github.com/PriNing/Marten.
Disentangled World Models: Learning to Transfer Semantic Knowledge from Distracting Videos for Reinforcement Learning
Mar 11, 2025Training visual reinforcement learning (RL) in practical scenarios presents a significant challenge, $\textit{i.e.,}$ RL agents suffer from low sample efficiency in environments with variations. While various approaches have attempted to alleviate this issue by disentanglement representation learning, these methods usually start learning from scratch without prior knowledge of the world. This paper, in contrast, tries to learn and understand underlying semantic variations from distracting videos via offline-to-online latent distillation and flexible disentanglement constraints. To enable effective cross-domain semantic knowledge transfer, we introduce an interpretable model-based RL framework, dubbed Disentangled World Models (DisWM). Specifically, we pretrain the action-free video prediction model offline with disentanglement regularization to extract semantic knowledge from distracting videos. The disentanglement capability of the pretrained model is then transferred to the world model through latent distillation. For finetuning in the online environment, we exploit the knowledge from the pretrained model and introduce a disentanglement constraint to the world model. During the adaptation phase, the incorporation of actions and rewards from online environment interactions enriches the diversity of the data, which in turn strengthens the disentangled representation learning. Experimental results validate the superiority of our approach on various benchmarks.
One-Step Diffusion Model for Image Motion-Deblurring
Mar 09, 2025



Currently, methods for single-image deblurring based on CNNs and transformers have demonstrated promising performance. However, these methods often suffer from perceptual limitations, poor generalization ability, and struggle with heavy or complex blur. While diffusion-based methods can partially address these shortcomings, their multi-step denoising process limits their practical usage. In this paper, we conduct an in-depth exploration of diffusion models in deblurring and propose a one-step diffusion model for deblurring (OSDD), a novel framework that reduces the denoising process to a single step, significantly improving inference efficiency while maintaining high fidelity. To tackle fidelity loss in diffusion models, we introduce an enhanced variational autoencoder (eVAE), which improves structural restoration. Additionally, we construct a high-quality synthetic deblurring dataset to mitigate perceptual collapse and design a dynamic dual-adapter (DDA) to enhance perceptual quality while preserving fidelity. Extensive experiments demonstrate that our method achieves strong performance on both full and no-reference metrics. Our code and pre-trained model will be publicly available at https://github.com/xyLiu339/OSDD.
QuantCache: Adaptive Importance-Guided Quantization with Hierarchical Latent and Layer Caching for Video Generation
Mar 09, 2025Recently, Diffusion Transformers (DiTs) have emerged as a dominant architecture in video generation, surpassing U-Net-based models in terms of performance. However, the enhanced capabilities of DiTs come with significant drawbacks, including increased computational and memory costs, which hinder their deployment on resource-constrained devices. Current acceleration techniques, such as quantization and cache mechanism, offer limited speedup and are often applied in isolation, failing to fully address the complexities of DiT architectures. In this paper, we propose QuantCache, a novel training-free inference acceleration framework that jointly optimizes hierarchical latent caching, adaptive importance-guided quantization, and structural redundancy-aware pruning. QuantCache achieves an end-to-end latency speedup of 6.72$\times$ on Open-Sora with minimal loss in generation quality. Extensive experiments across multiple video generation benchmarks demonstrate the effectiveness of our method, setting a new standard for efficient DiT inference. The code and models will be available at https://github.com/JunyiWuCode/QuantCache.
QArtSR: Quantization via Reverse-Module and Timestep-Retraining in One-Step Diffusion based Image Super-Resolution
Mar 07, 2025



One-step diffusion-based image super-resolution (OSDSR) models are showing increasingly superior performance nowadays. However, although their denoising steps are reduced to one and they can be quantized to 8-bit to reduce the costs further, there is still significant potential for OSDSR to quantize to lower bits. To explore more possibilities of quantized OSDSR, we propose an efficient method, Quantization via reverse-module and timestep-retraining for OSDSR, named QArtSR. Firstly, we investigate the influence of timestep value on the performance of quantized models. Then, we propose Timestep Retraining Quantization (TRQ) and Reversed Per-module Quantization (RPQ) strategies to calibrate the quantized model. Meanwhile, we adopt the module and image losses to update all quantized modules. We only update the parameters in quantization finetuning components, excluding the original weights. To ensure that all modules are fully finetuned, we add extended end-to-end training after per-module stage. Our 4-bit and 2-bit quantization experimental results indicate that QArtSR obtains superior effects against the recent leading comparison methods. The performance of 4-bit QArtSR is close to the full-precision one. Our code will be released at https://github.com/libozhu03/QArtSR.
A Token-level Text Image Foundation Model for Document Understanding
Mar 04, 2025



In recent years, general visual foundation models (VFMs) have witnessed increasing adoption, particularly as image encoders for popular multi-modal large language models (MLLMs). However, without semantically fine-grained supervision, these models still encounter fundamental prediction errors in the context of downstream text-image-related tasks, i.e., perception, understanding and reasoning with images containing small and dense texts. To bridge this gap, we develop TokenOCR, the first token-level visual foundation model specifically tailored for text-image-related tasks, designed to support a variety of traditional downstream applications. To facilitate the pretraining of TokenOCR, we also devise a high-quality data production pipeline that constructs the first token-level image text dataset, TokenIT, comprising 20 million images and 1.8 billion token-mask pairs. Furthermore, leveraging this foundation with exceptional image-as-text capability, we seamlessly replace previous VFMs with TokenOCR to construct a document-level MLLM, TokenVL, for VQA-based document understanding tasks. Finally, extensive experiments demonstrate the effectiveness of TokenOCR and TokenVL. Code, datasets, and weights will be available at https://token-family.github.io/TokenOCR_project.
MARS: Mesh AutoRegressive Model for 3D Shape Detailization
Feb 17, 2025



State-of-the-art methods for mesh detailization predominantly utilize Generative Adversarial Networks (GANs) to generate detailed meshes from coarse ones. These methods typically learn a specific style code for each category or similar categories without enforcing geometry supervision across different Levels of Detail (LODs). Consequently, such methods often fail to generalize across a broader range of categories and cannot ensure shape consistency throughout the detailization process. In this paper, we introduce MARS, a novel approach for 3D shape detailization. Our method capitalizes on a novel multi-LOD, multi-category mesh representation to learn shape-consistent mesh representations in latent space across different LODs. We further propose a mesh autoregressive model capable of generating such latent representations through next-LOD token prediction. This approach significantly enhances the realism of the generated shapes. Extensive experiments conducted on the challenging 3D Shape Detailization benchmark demonstrate that our proposed MARS model achieves state-of-the-art performance, surpassing existing methods in both qualitative and quantitative assessments. Notably, the model's capability to generate fine-grained details while preserving the overall shape integrity is particularly commendable.
SparseFormer: Detecting Objects in HRW Shots via Sparse Vision Transformer
Feb 11, 2025Recent years have seen an increase in the use of gigapixel-level image and video capture systems and benchmarks with high-resolution wide (HRW) shots. However, unlike close-up shots in the MS COCO dataset, the higher resolution and wider field of view raise unique challenges, such as extreme sparsity and huge scale changes, causing existing close-up detectors inaccuracy and inefficiency. In this paper, we present a novel model-agnostic sparse vision transformer, dubbed SparseFormer, to bridge the gap of object detection between close-up and HRW shots. The proposed SparseFormer selectively uses attentive tokens to scrutinize the sparsely distributed windows that may contain objects. In this way, it can jointly explore global and local attention by fusing coarse- and fine-grained features to handle huge scale changes. SparseFormer also benefits from a novel Cross-slice non-maximum suppression (C-NMS) algorithm to precisely localize objects from noisy windows and a simple yet effective multi-scale strategy to improve accuracy. Extensive experiments on two HRW benchmarks, PANDA and DOTA-v1.0, demonstrate that the proposed SparseFormer significantly improves detection accuracy (up to 5.8%) and speed (up to 3x) over the state-of-the-art approaches.
AdaSVD: Adaptive Singular Value Decomposition for Large Language Models
Feb 04, 2025



Large language models (LLMs) have achieved remarkable success in natural language processing (NLP) tasks, yet their substantial memory requirements present significant challenges for deployment on resource-constrained devices. Singular Value Decomposition (SVD) has emerged as a promising compression technique for LLMs, offering considerable reductions in memory overhead. However, existing SVD-based methods often struggle to effectively mitigate the errors introduced by SVD truncation, leading to a noticeable performance gap when compared to the original models. Furthermore, applying a uniform compression ratio across all transformer layers fails to account for the varying importance of different layers. To address these challenges, we propose AdaSVD, an adaptive SVD-based LLM compression approach. Specifically, AdaSVD introduces adaComp, which adaptively compensates for SVD truncation errors by alternately updating the singular matrices U and V^T. Additionally, AdaSVD introduces adaCR, which adaptively assigns layer-specific compression ratios based on the relative importance of each layer. Extensive experiments across multiple LLM families and evaluation metrics demonstrate that AdaSVD consistently outperforms state-of-the-art (SOTA) SVD-based methods, achieving superior performance with significantly reduced memory requirements. The code and models will be available at https://github.com/ZHITENGLI/AdaSVD.
Human Body Restoration with One-Step Diffusion Model and A New Benchmark
Feb 03, 2025



Human body restoration, as a specific application of image restoration, is widely applied in practice and plays a vital role across diverse fields. However, thorough research remains difficult, particularly due to the lack of benchmark datasets. In this study, we propose a high-quality dataset automated cropping and filtering (HQ-ACF) pipeline. This pipeline leverages existing object detection datasets and other unlabeled images to automatically crop and filter high-quality human images. Using this pipeline, we constructed a person-based restoration with sophisticated objects and natural activities (\emph{PERSONA}) dataset, which includes training, validation, and test sets. The dataset significantly surpasses other human-related datasets in both quality and content richness. Finally, we propose \emph{OSDHuman}, a novel one-step diffusion model for human body restoration. Specifically, we propose a high-fidelity image embedder (HFIE) as the prompt generator to better guide the model with low-quality human image information, effectively avoiding misleading prompts. Experimental results show that OSDHuman outperforms existing methods in both visual quality and quantitative metrics. The dataset and code will at https://github.com/gobunu/OSDHuman.