 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgrammable Motion Generation for Open-Set Motion Control Tasks
May 29, 2024Character animation in real-world scenarios necessitates a variety of constraints, such as trajectories, key-frames, interactions, etc. Existing methodologies typically treat single or a finite set of these constraint(s) as separate control tasks. They are often specialized, and the tasks they address are rarely extendable or customizable. We categorize these as solutions to the close-set motion control problem. In response to the complexity of practical motion control, we propose and attempt to solve the open-set motion control problem. This problem is characterized by an open and fully customizable set of motion control tasks. To address this, we introduce a new paradigm, programmable motion generation. In this paradigm, any given motion control task is broken down into a combination of atomic constraints. These constraints are then programmed into an error function that quantifies the degree to which a motion sequence adheres to them. We utilize a pre-trained motion generation model and optimize its latent code to minimize the error function of the generated motion. Consequently, the generated motion not only inherits the prior of the generative model but also satisfies the required constraints. Experiments show that we can generate high-quality motions when addressing a wide range of unseen tasks. These tasks encompass motion control by motion dynamics, geometric constraints, physical laws, interactions with scenes, objects or the character own body parts, etc. All of these are achieved in a unified approach, without the need for ad-hoc paired training data collection or specialized network designs. During the programming of novel tasks, we observed the emergence of new skills beyond those of the prior model. With the assistance of large language models, we also achieved automatic programming. We hope that this work will pave the way for the motion control of general AI agents.
HeadEvolver: Text to Head Avatars via Locally Learnable Mesh Deformation
Mar 14, 2024We present HeadEvolver, a novel framework to generate stylized head avatars from text guidance. HeadEvolver uses locally learnable mesh deformation from a template head mesh, producing high-quality digital assets for detail-preserving editing and animation. To tackle the challenges of lacking fine-grained and semantic-aware local shape control in global deformation through Jacobians, we introduce a trainable parameter as a weighting factor for the Jacobian at each triangle to adaptively change local shapes while maintaining global correspondences and facial features. Moreover, to ensure the coherence of the resulting shape and appearance from different viewpoints, we use pretrained image diffusion models for differentiable rendering with regularization terms to refine the deformation under text guidance. Extensive experiments demonstrate that our method can generate diverse head avatars with an articulated mesh that can be edited seamlessly in 3D graphics software, facilitating downstream applications such as more efficient animation with inherited blend shapes and semantic consistency.
HumanGaussian: Text-Driven 3D Human Generation with Gaussian Splatting
Nov 28, 2023



Realistic 3D human generation from text prompts is a desirable yet challenging task. Existing methods optimize 3D representations like mesh or neural fields via score distillation sampling (SDS), which suffers from inadequate fine details or excessive training time. In this paper, we propose an efficient yet effective framework, HumanGaussian, that generates high-quality 3D humans with fine-grained geometry and realistic appearance. Our key insight is that 3D Gaussian Splatting is an efficient renderer with periodic Gaussian shrinkage or growing, where such adaptive density control can be naturally guided by intrinsic human structures. Specifically, 1) we first propose a Structure-Aware SDS that simultaneously optimizes human appearance and geometry. The multi-modal score function from both RGB and depth space is leveraged to distill the Gaussian densification and pruning process. 2) Moreover, we devise an Annealed Negative Prompt Guidance by decomposing SDS into a noisier generative score and a cleaner classifier score, which well addresses the over-saturation issue. The floating artifacts are further eliminated based on Gaussian size in a prune-only phase to enhance generation smoothness. Extensive experiments demonstrate the superior efficiency and competitive quality of our framework, rendering vivid 3D humans under diverse scenarios. Project Page: https://alvinliu0.github.io/projects/HumanGaussian
SemanticBoost: Elevating Motion Generation with Augmented Textual Cues
Oct 31, 2023



Current techniques face difficulties in generating motions from intricate semantic descriptions, primarily due to insufficient semantic annotations in datasets and weak contextual understanding. To address these issues, we present SemanticBoost, a novel framework that tackles both challenges simultaneously. Our framework comprises a Semantic Enhancement module and a Context-Attuned Motion Denoiser (CAMD). The Semantic Enhancement module extracts supplementary semantics from motion data, enriching the dataset's textual description and ensuring precise alignment between text and motion data without depending on large language models. On the other hand, the CAMD approach provides an all-encompassing solution for generating high-quality, semantically consistent motion sequences by effectively capturing context information and aligning the generated motion with the given textual descriptions. Distinct from existing methods, our approach can synthesize accurate orientational movements, combined motions based on specific body part descriptions, and motions generated from complex, extended sentences. Our experimental results demonstrate that SemanticBoost, as a diffusion-based method, outperforms auto-regressive-based techniques, achieving cutting-edge performance on the Humanml3D dataset while maintaining realistic and smooth motion generation quality.
TapMo: Shape-aware Motion Generation of Skeleton-free Characters
Oct 19, 2023Previous motion generation methods are limited to the pre-rigged 3D human model, hindering their applications in the animation of various non-rigged characters. In this work, we present TapMo, a Text-driven Animation Pipeline for synthesizing Motion in a broad spectrum of skeleton-free 3D characters. The pivotal innovation in TapMo is its use of shape deformation-aware features as a condition to guide the diffusion model, thereby enabling the generation of mesh-specific motions for various characters. Specifically, TapMo comprises two main components - Mesh Handle Predictor and Shape-aware Diffusion Module. Mesh Handle Predictor predicts the skinning weights and clusters mesh vertices into adaptive handles for deformation control, which eliminates the need for traditional skeletal rigging. Shape-aware Motion Diffusion synthesizes motion with mesh-specific adaptations. This module employs text-guided motions and mesh features extracted during the first stage, preserving the geometric integrity of the animations by accounting for the character's shape and deformation. Trained in a weakly-supervised manner, TapMo can accommodate a multitude of non-human meshes, both with and without associated text motions. We demonstrate the effectiveness and generalizability of TapMo through rigorous qualitative and quantitative experiments. Our results reveal that TapMo consistently outperforms existing auto-animation methods, delivering superior-quality animations for both seen or unseen heterogeneous 3D characters.
RaBit: Parametric Modeling of 3D Biped Cartoon Characters with a Topological-consistent Dataset
Mar 24, 2023



Assisting people in efficiently producing visually plausible 3D characters has always been a fundamental research topic in computer vision and computer graphics. Recent learning-based approaches have achieved unprecedented accuracy and efficiency in the area of 3D real human digitization. However, none of the prior works focus on modeling 3D biped cartoon characters, which are also in great demand in gaming and filming. In this paper, we introduce 3DBiCar, the first large-scale dataset of 3D biped cartoon characters, and RaBit, the corresponding parametric model. Our dataset contains 1,500 topologically consistent high-quality 3D textured models which are manually crafted by professional artists. Built upon the data, RaBit is thus designed with a SMPL-like linear blend shape model and a StyleGAN-based neural UV-texture generator, simultaneously expressing the shape, pose, and texture. To demonstrate the practicality of 3DBiCar and RaBit, various applications are conducted, including single-view reconstruction, sketch-based modeling, and 3D cartoon animation. For the single-view reconstruction setting, we find a straightforward global mapping from input images to the output UV-based texture maps tends to lose detailed appearances of some local parts (e.g., nose, ears). Thus, a part-sensitive texture reasoner is adopted to make all important local areas perceived. Experiments further demonstrate the effectiveness of our method both qualitatively and quantitatively. 3DBiCar and RaBit are available at gaplab.cuhk.edu.cn/projects/RaBit.
Open Long-Tailed Recognition in a Dynamic World
Aug 17, 2022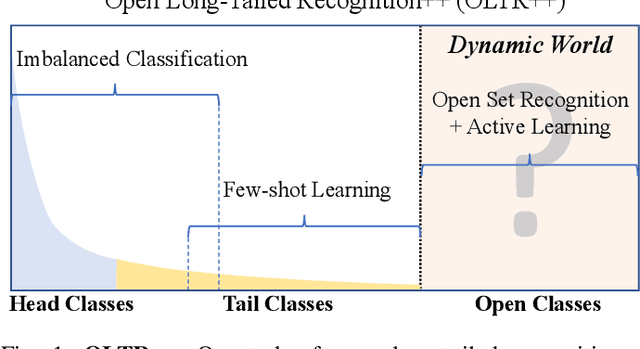
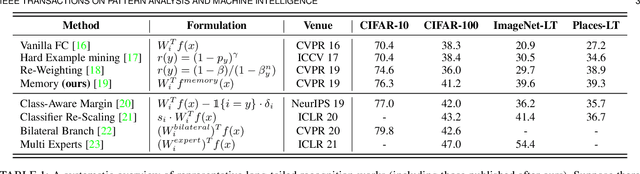
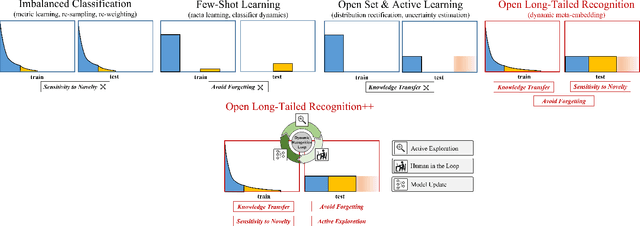

Real world data often exhibits a long-tailed and open-ended (with unseen classes) distribution. A practical recognition system must balance between majority (head) and minority (tail) classes, generalize across the distribution, and acknowledge novelty upon the instances of unseen classes (open classes). We define Open Long-Tailed Recognition++ (OLTR++) as learning from such naturally distributed data and optimizing for the classification accuracy over a balanced test set which includes both known and open classes. OLTR++ handles imbalanced classification, few-shot learning, open-set recognition, and active learning in one integrated algorithm, whereas existing classification approaches often focus only on one or two aspects and deliver poorly over the entire spectrum. The key challenges are: 1) how to share visual knowledge between head and tail classes, 2) how to reduce confusion between tail and open classes, and 3) how to actively explore open classes with learned knowledge. Our algorithm, OLTR++, maps images to a feature space such that visual concepts can relate to each other through a memory association mechanism and a learned metric (dynamic meta-embedding) that both respects the closed world classification of seen classes and acknowledges the novelty of open classes. Additionally, we propose an active learning scheme based on visual memory, which learns to recognize open classes in a data-efficient manner for future expansions. On three large-scale open long-tailed datasets we curated from ImageNet (object-centric), Places (scene-centric), and MS1M (face-centric) data, as well as three standard benchmarks (CIFAR-10-LT, CIFAR-100-LT, and iNaturalist-18), our approach, as a unified framework, consistently demonstrates competitive performance. Notably, our approach also shows strong potential for the active exploration of open classes and the fairness analysis of minority groups.
Masked Frequency Modeling for Self-Supervised Visual Pre-Training
Jun 15, 2022



We present Masked Frequency Modeling (MFM), a unified frequency-domain-based approach for self-supervised pre-training of visual models. Instead of randomly inserting mask tokens to the input embeddings in the spatial domain, in this paper, we shift the perspective to the frequency domain. Specifically, MFM first masks out a portion of frequency components of the input image and then predicts the missing frequencies on the frequency spectrum. Our key insight is that predicting masked components in the frequency domain is more ideal to reveal underlying image patterns rather than predicting masked patches in the spatial domain, due to the heavy spatial redundancy. Our findings suggest that with the right configuration of mask-and-predict strategy, both the structural information within high-frequency components and the low-level statistics among low-frequency counterparts are useful in learning good representations. For the first time, MFM demonstrates that, for both ViT and CNN, a simple non-Siamese framework can learn meaningful representations even using none of the following: (i) extra data, (ii) extra model, (iii) mask token. Experimental results on ImageNet and several robustness benchmarks show the competitive performance and advanced robustness of MFM compared with recent masked image modeling approaches. Furthermore, we also comprehensively investigate the effectiveness of classical image restoration tasks for representation learning from a unified frequency perspective and reveal their intriguing relations with our MFM approach. Project page: https://www.mmlab-ntu.com/project/mfm/index.html.
Style-ERD: Responsive and Coherent Online Motion Style Transfer
Mar 29, 2022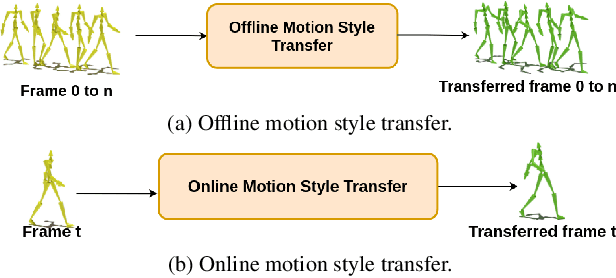

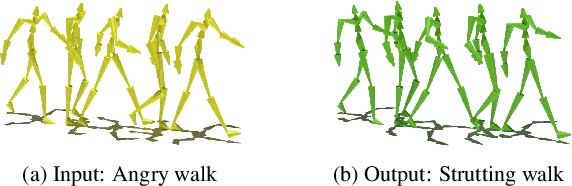
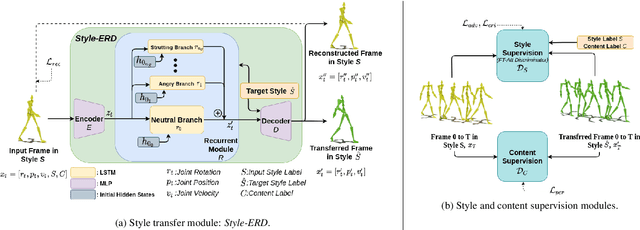
Motion style transfer is a common method for enriching character animation. Motion style transfer algorithms are often designed for offline settings where motions are processed in segments. However, for online animation applications, such as realtime avatar animation from motion capture, motions need to be processed as a stream with minimal latency. In this work, we realize a flexible, high-quality motion style transfer method for this setting. We propose a novel style transfer model, Style-ERD, to stylize motions in an online manner with an Encoder-Recurrent-Decoder structure, along with a novel discriminator that combines feature attention and temporal attention. Our method stylizes motions into multiple target styles with a unified model. Although our method targets online settings, it outperforms previous offline methods in motion realism and style expressiveness and provides significant gains in runtime efficiency
Unsupervised Object-Level Representation Learning from Scene Images
Jun 22, 2021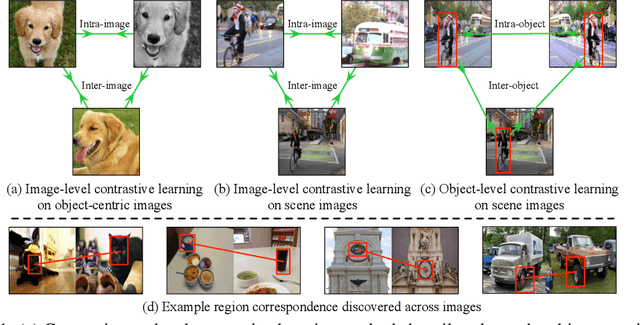
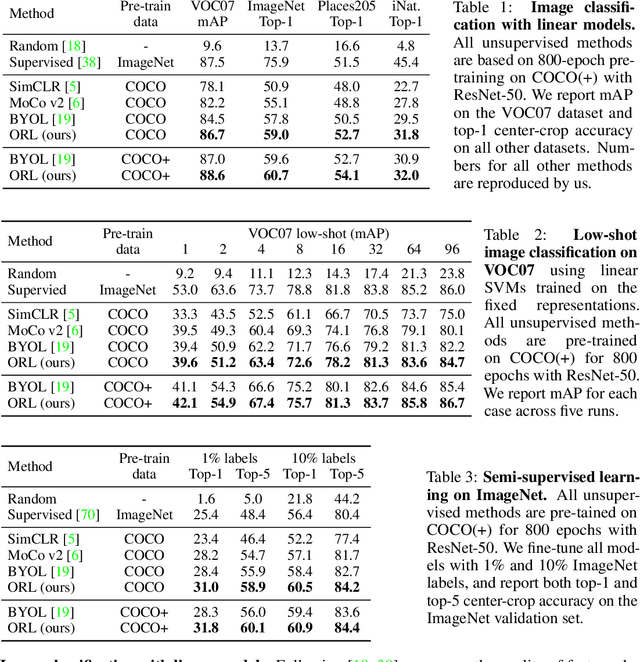


Contrastive self-supervised learning has largely narrowed the gap to supervised pre-training on ImageNet. However, its success highly relies on the object-centric priors of ImageNet, i.e., different augmented views of the same image correspond to the same object. Such a heavily curated constraint becomes immediately infeasible when pre-trained on more complex scene images with many objects. To overcome this limitation, we introduce Object-level Representation Learning (ORL), a new self-supervised learning framework towards scene images. Our key insight is to leverage image-level self-supervised pre-training as the prior to discover object-level semantic correspondence, thus realizing object-level representation learning from scene images. Extensive experiments on COCO show that ORL significantly improves the performance of self-supervised learning on scene images, even surpassing supervised ImageNet pre-training on several downstream tasks. Furthermore, ORL improves the downstream performance when more unlabeled scene images are available, demonstrating its great potential of harnessing unlabeled data in the wild. We hope our approach can motivate future research on more general-purpose unsupervised representation learning from scene data. Project page: https://www.mmlab-ntu.com/project/orl/.