 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidential Detection and Tracking Collaboration: New Problem, Benchmark and Algorithm for Robust Anti-UAV System
Jul 04, 2023



Unmanned Aerial Vehicles (UAVs) have been widely used in many areas, including transportation, surveillance, and military. However, their potential for safety and privacy violations is an increasing issue and highly limits their broader applications, underscoring the critical importance of UAV perception and defense (anti-UAV). Still, previous works have simplified such an anti-UAV task as a tracking problem, where the prior information of UAVs is always provided; such a scheme fails in real-world anti-UAV tasks (i.e. complex scenes, indeterminate-appear and -reappear UAVs, and real-time UAV surveillance). In this paper, we first formulate a new and practical anti-UAV problem featuring the UAVs perception in complex scenes without prior UAVs information. To benchmark such a challenging task, we propose the largest UAV dataset dubbed AntiUAV600 and a new evaluation metric. The AntiUAV600 comprises 600 video sequences of challenging scenes with random, fast, and small-scale UAVs, with over 723K thermal infrared frames densely annotated with bounding boxes. Finally, we develop a novel anti-UAV approach via an evidential collaboration of global UAVs detection and local UAVs tracking, which effectively tackles the proposed problem and can serve as a strong baseline for future research. Extensive experiments show our method outperforms SOTA approaches and validate the ability of AntiUAV600 to enhance UAV perception performance due to its large scale and complexity. Our dataset, pretrained models, and source codes will be released publically.
FusionBooster: A Unified Image Fusion Boosting Paradigm
May 10, 2023



Numerous ideas have emerged for designing fusion rules in the image fusion field. Essentially, all the existing formulations try to manage the diverse levels of information communicated by the source images to achieve the best fusion result. We argue that there is a scope for improving the performance of existing methods further with the help of FusionBooster, a fusion guidance method proposed in this paper. Our booster is based on the divide and conquer strategy controlled by an information probe. The booster is composed of three building blocks: the probe units, the booster layer, and the assembling module. Given the embedding produced by a backbone method, the probe units assess the source images and divide them according to their information content. This is instrumental in identifying missing information, as a step to its recovery. The recovery of the degraded components along with the fusion guidance are embedded in the booster layer. Lastly, the assembling module is responsible for piecing these advanced components together to deliver the output. We use concise reconstruction loss functions and lightweight models to formulate the network, with marginal computational increase. The experimental results obtained in various fusion tasks, as well as downstream detection tasks, consistently demonstrate that the proposed FusionBooster significantly improves the performance. Our codes will be publicly available on the project homepage.
LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images
Apr 16, 2023



Deep learning based fusion methods have been achieving promising performance in image fusion tasks. This is attributed to the network architecture that plays a very important role in the fusion process. However, in general, it is hard to specify a good fusion architecture, and consequently, the design of fusion networks is still a black art, rather than science. To address this problem, we formulate the fusion task mathematically, and establish a connection between its optimal solution and the network architecture that can implement it. This approach leads to a novel method proposed in the paper of constructing a lightweight fusion network. It avoids the time-consuming empirical network design by a trial-and-test strategy. In particular we adopt a learnable representation approach to the fusion task, in which the construction of the fusion network architecture is guided by the optimisation algorithm producing the learnable model. The low-rank representation (LRR) objective is the foundation of our learnable model. The matrix multiplications, which are at the heart of the solution are transformed into convolutional operations, and the iterative process of optimisation is replaced by a special feed-forward network. Based on this novel network architecture, an end-to-end lightweight fusion network is constructed to fuse infrared and visible light images. Its successful training is facilitated by a detail-to-semantic information loss function proposed to preserve the image details and to enhance the salient features of the source images. Our experiments show that the proposed fusion network exhibits better fusion performance than the state-of-the-art fusion methods on public datasets. Interestingly, our network requires a fewer training parameters than other existing methods. The codes are available at https://github.com/hli1221/imagefusion-LRRNet
Adaptive Riemannian Metrics on SPD Manifolds
Mar 26, 2023Symmetric Positive Definite (SPD) matrices have received wide attention in machine learning due to their intrinsic capacity of encoding underlying structural correlation in data. To reflect the non-Euclidean geometry of SPD manifolds, many successful Riemannian metrics have been proposed. However, existing fixed metric tensors might lead to sub-optimal performance for SPD matrices learning, especially for SPD neural networks. To remedy this limitation, we leverage the idea of pullback and propose adaptive Riemannian metrics for SPD manifolds. Moreover, we present comprehensive theories for our metrics. Experiments on three datasets demonstrate that equipped with the proposed metrics, SPD networks can exhibit superior performance.
SDA-$x$Net: Selective Depth Attention Networks for Adaptive Multi-scale Feature Representation
Sep 21, 2022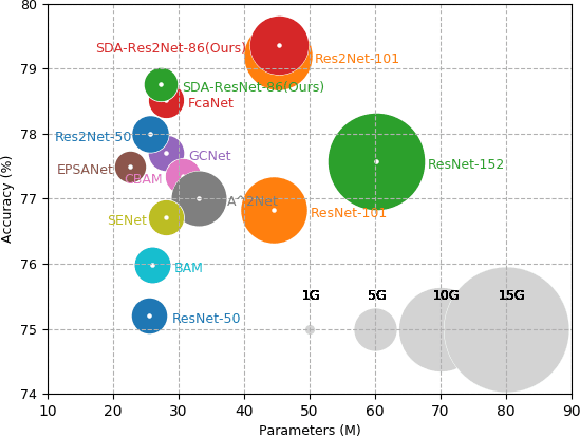
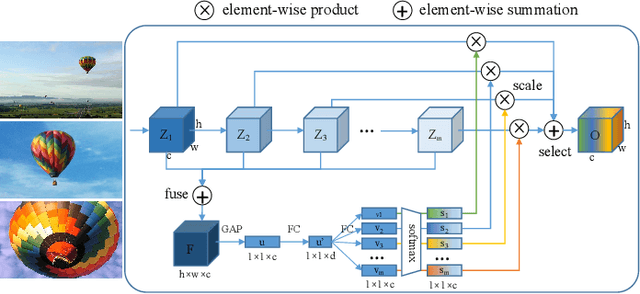
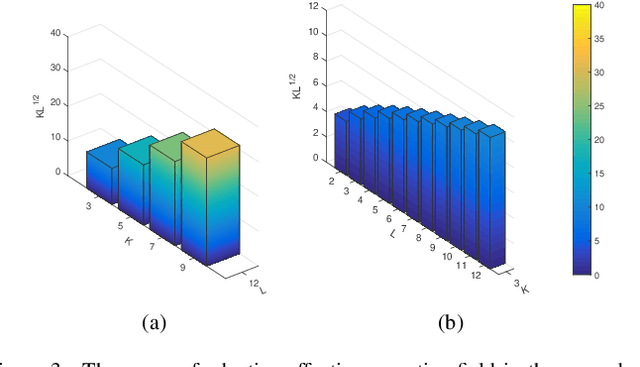
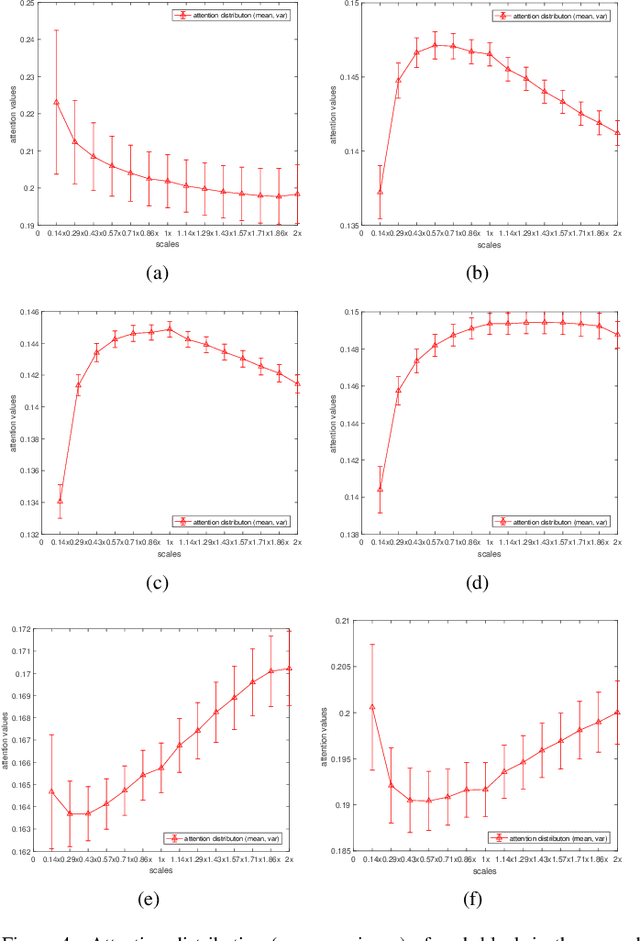
Existing multi-scale solutions lead to a risk of just increasing the receptive field sizes while neglecting small receptive fields. Thus, it is a challenging problem to effectively construct adaptive neural networks for recognizing various spatial-scale objects. To tackle this issue, we first introduce a new attention dimension, i.e., depth, in addition to existing attention dimensions such as channel, spatial, and branch, and present a novel selective depth attention network to symmetrically handle multi-scale objects in various vision tasks. Specifically, the blocks within each stage of a given neural network, i.e., ResNet, output hierarchical feature maps sharing the same resolution but with different receptive field sizes. Based on this structural property, we design a stage-wise building module, namely SDA, which includes a trunk branch and a SE-like attention branch. The block outputs of the trunk branch are fused to globally guide their depth attention allocation through the attention branch. According to the proposed attention mechanism, we can dynamically select different depth features, which contributes to adaptively adjusting the receptive field sizes for the variable-sized input objects. In this way, the cross-block information interaction leads to a long-range dependency along the depth direction. Compared with other multi-scale approaches, our SDA method combines multiple receptive fields from previous blocks into the stage output, thus offering a wider and richer range of effective receptive fields. Moreover, our method can be served as a pluggable module to other multi-scale networks as well as attention networks, coined as SDA-$x$Net. Their combination further extends the range of the effective receptive fields towards small receptive fields, enabling interpretable neural networks. Our source code is available at \url{https://github.com/QingbeiGuo/SDA-xNet.git}.
RGBD1K: A Large-scale Dataset and Benchmark for RGB-D Object Tracking
Aug 21, 2022
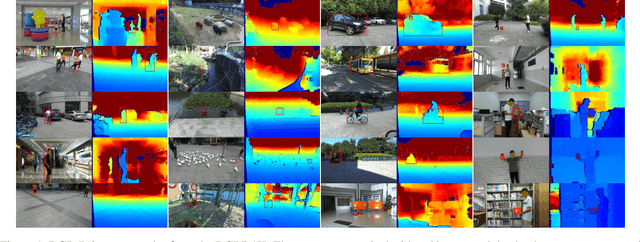
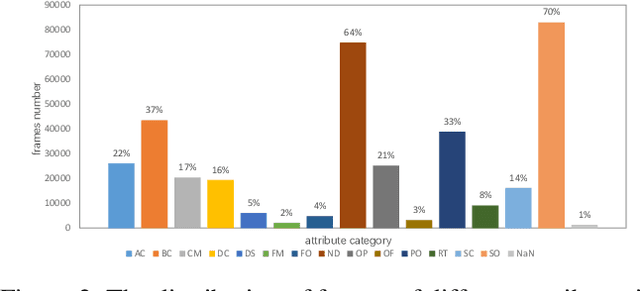

RGB-D object tracking has attracted considerable attention recently, achieving promising performance thanks to the symbiosis between visual and depth channels. However, given a limited amount of annotated RGB-D tracking data, most state-of-the-art RGB-D trackers are simple extensions of high-performance RGB-only trackers, without fully exploiting the underlying potential of the depth channel in the offline training stage. To address the dataset deficiency issue, a new RGB-D dataset named RGBD1K is released in this paper. The RGBD1K contains 1,050 sequences with about 2.5M frames in total. To demonstrate the benefits of training on a larger RGB-D data set in general, and RGBD1K in particular, we develop a transformer-based RGB-D tracker, named SPT, as a baseline for future visual object tracking studies using the new dataset. The results, of extensive experiments using the SPT tracker emonstrate the potential of the RGBD1K dataset to improve the performance of RGB-D tracking, inspiring future developments of effective tracker designs. The dataset and codes will be available on the project homepage: https://will.be.available.at.this.website.
A Medical Image Fusion Method based on MDLatLRRv2
Jul 02, 2022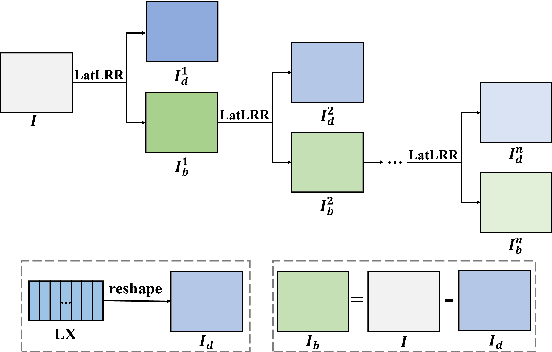
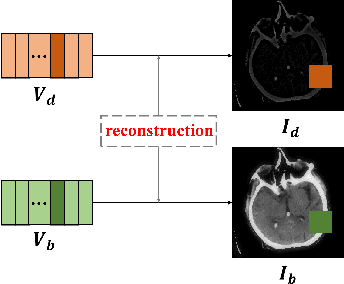
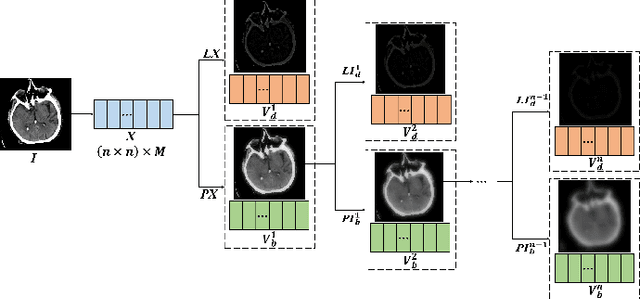
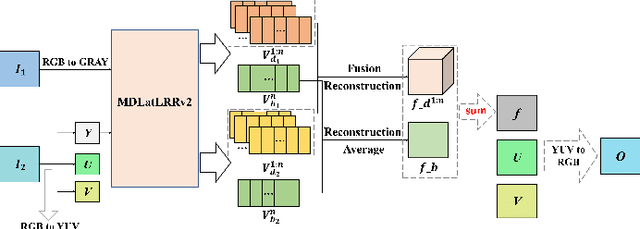
Since MDLatLRR only considers detailed parts (salient features) of input images extracted by latent low-rank representation (LatLRR), it doesn't use base parts (principal features) extracted by LatLRR effectively. Therefore, we proposed an improved multi-level decomposition method called MDLatLRRv2 which effectively analyzes and utilizes all the image features obtained by LatLRR. Then we apply MDLatLRRv2 to medical image fusion. The base parts are fused by average strategy and the detail parts are fused by nuclear-norm operation. The comparison with the existing methods demonstrates that the proposed method can achieve state-of-the-art fusion performance in objective and subjective assessment.
DreamNet: A Deep Riemannian Network based on SPD Manifold Learning for Visual Classification
Jun 16, 2022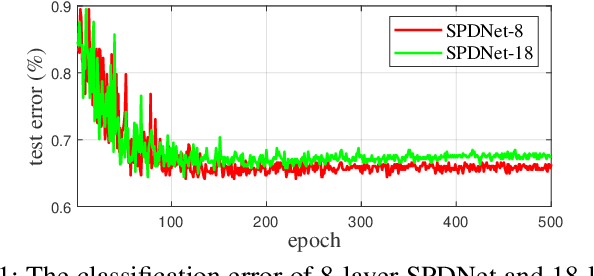
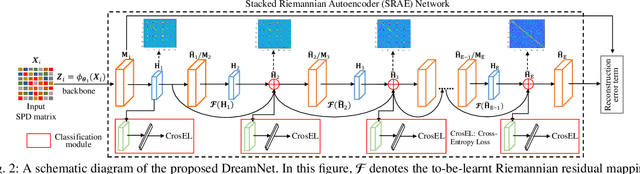
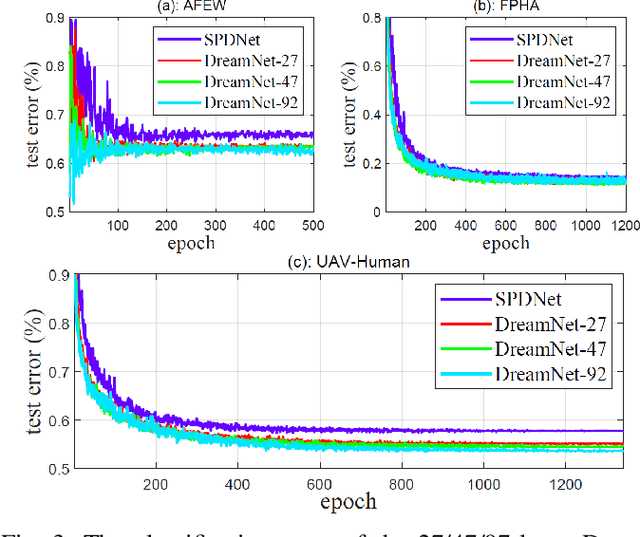
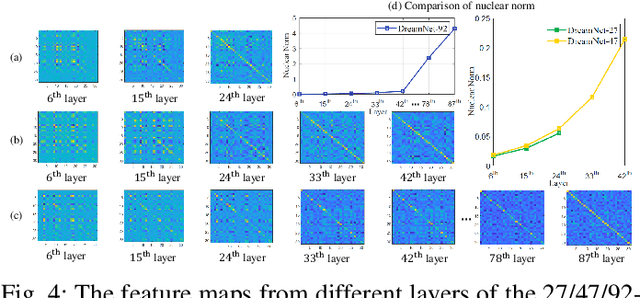
Image set-based visual classification methods have achieved remarkable performance, via characterising the image set in terms of a non-singular covariance matrix on a symmetric positive definite (SPD) manifold. To adapt to complicated visual scenarios better, several Riemannian networks (RiemNets) for SPD matrix nonlinear processing have recently been studied. However, it is pertinent to ask, whether greater accuracy gains can be achieved by simply increasing the depth of RiemNets. The answer appears to be negative, as deeper RiemNets tend to lose generalization ability. To explore a possible solution to this issue, we propose a new architecture for SPD matrix learning. Specifically, to enrich the deep representations, we adopt SPDNet [1] as the backbone, with a stacked Riemannian autoencoder (SRAE) built on the tail. The associated reconstruction error term can make the embedding functions of both SRAE and of each RAE an approximate identity mapping, which helps to prevent the degradation of statistical information. We then insert several residual-like blocks with shortcut connections to augment the representational capacity of SRAE, and to simplify the training of a deeper network. The experimental evidence demonstrates that our DreamNet can achieve improved accuracy with increased depth of the network.
NFLAT: Non-Flat-Lattice Transformer for Chinese Named Entity Recognition
May 19, 2022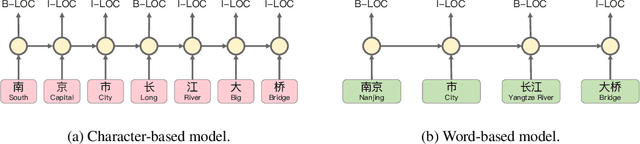
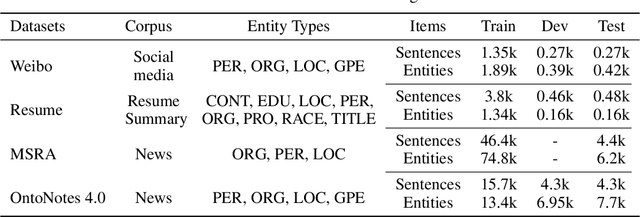
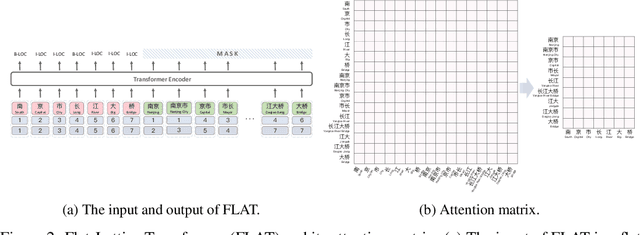
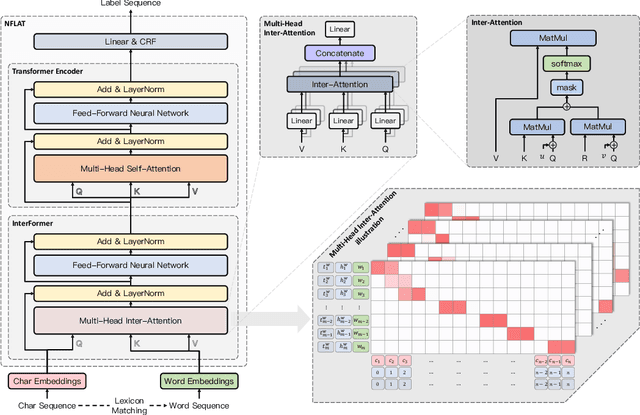
Recently, Flat-LAttice Transformer (FLAT) has achieved great success in Chinese Named Entity Recognition (NER). FLAT performs lexical enhancement by constructing flat lattices, which mitigates the difficulties posed by blurred word boundaries and the lack of word semantics. In FLAT, the positions of starting and ending characters are used to connect a matching word. However, this method is likely to match more words when dealing with long texts, resulting in long input sequences. Therefore, it significantly increases the memory and computational costs of the self-attention module. To deal with this issue, we advocate a novel lexical enhancement method, InterFormer, that effectively reduces the amount of computational and memory costs by constructing non-flat lattices. Furthermore, with InterFormer as the backbone, we implement NFLAT for Chinese NER. NFLAT decouples lexicon fusion and context feature encoding. Compared with FLAT, it reduces unnecessary attention calculations in "word-character" and "word-word". This reduces the memory usage by about 50% and can use more extensive lexicons or higher batches for network training. The experimental results obtained on several well-known benchmarks demonstrate the superiority of the proposed method over the state-of-the-art hybrid (character-word) models.
Low-rank features based double transformation matrices learning for image classification
Feb 17, 2022Linear regression is a supervised method that has been widely used in classification tasks. In order to apply linear regression to classification tasks, a technique for relaxing regression targets was proposed. However, methods based on this technique ignore the pressure on a single transformation matrix due to the complex information contained in the data. A single transformation matrix in this case is too strict to provide a flexible projection, thus it is necessary to adopt relaxation on transformation matrix. This paper proposes a double transformation matrices learning method based on latent low-rank feature extraction. The core idea is to use double transformation matrices for relaxation, and jointly projecting the learned principal and salient features from two directions into the label space, which can share the pressure of a single transformation matrix. Firstly, the low-rank features are learned by the latent low rank representation (LatLRR) method which processes the original data from two directions. In this process, sparse noise is also separated, which alleviates its interference on projection learning to some extent. Then, two transformation matrices are introduced to process the two features separately, and the information useful for the classification is extracted. Finally, the two transformation matrices can be easily obtained by alternate optimization methods. Through such processing, even when a large amount of redundant information is contained in samples, our method can also obtain projection results that are easy to classify. Experiments on multiple data sets demonstrate the effectiveness of our approach for classification, especially for complex scenarios.