 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
Jun 09, 2025Recently, leveraging pre-trained vision-language models (VLMs) for building vision-language-action (VLA) models has emerged as a promising approach to effective robot manipulation learning. However, only few methods incorporate 3D signals into VLMs for action prediction, and they do not fully leverage the spatial structure inherent in 3D data, leading to low sample efficiency. In this paper, we introduce BridgeVLA, a novel 3D VLA model that (1) projects 3D inputs to multiple 2D images, ensuring input alignment with the VLM backbone, and (2) utilizes 2D heatmaps for action prediction, unifying the input and output spaces within a consistent 2D image space. In addition, we propose a scalable pre-training method that equips the VLM backbone with the capability to predict 2D heatmaps before downstream policy learning. Extensive experiments show the proposed method is able to learn 3D manipulation efficiently and effectively. BridgeVLA outperforms state-of-the-art baseline methods across three simulation benchmarks. In RLBench, it improves the average success rate from 81.4% to 88.2%. In COLOSSEUM, it demonstrates significantly better performance in challenging generalization settings, boosting the average success rate from 56.7% to 64.0%. In GemBench, it surpasses all the comparing baseline methods in terms of average success rate. In real-robot experiments, BridgeVLA outperforms a state-of-the-art baseline method by 32% on average. It generalizes robustly in multiple out-of-distribution settings, including visual disturbances and unseen instructions. Remarkably, it is able to achieve a success rate of 96.8% on 10+ tasks with only 3 trajectories per task, highlighting its extraordinary sample efficiency. Project Website:https://bridgevla.github.io/
Robotic Policy Learning via Human-assisted Action Preference Optimization
Jun 08, 2025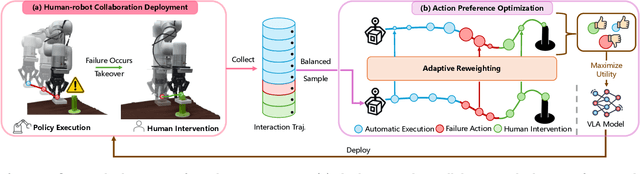



Establishing a reliable and iteratively refined robotic system is essential for deploying real-world applications. While Vision-Language-Action (VLA) models are widely recognized as the foundation model for such robotic deployment, their dependence on expert demonstrations hinders the crucial capabilities of correction and learning from failures. To mitigate this limitation, we introduce a Human-assisted Action Preference Optimization method named HAPO, designed to correct deployment failures and foster effective adaptation through preference alignment for VLA models. This method begins with a human-robot collaboration framework for reliable failure correction and interaction trajectory collection through human intervention. These human-intervention trajectories are further employed within the action preference optimization process, facilitating VLA models to mitigate failure action occurrences while enhancing corrective action adaptation. Specifically, we propose an adaptive reweighting algorithm to address the issues of irreversible interactions and token probability mismatch when introducing preference optimization into VLA models, facilitating model learning from binary desirability signals derived from interactions. Through combining these modules, our human-assisted action preference optimization method ensures reliable deployment and effective learning from failure for VLA models. The experiments conducted in simulation and real-world scenarios prove superior generalization and robustness of our framework across a variety of manipulation tasks.
On-demand Test-time Adaptation for Edge Devices
May 02, 2025Continual Test-time adaptation (CTTA) continuously adapts the deployed model on every incoming batch of data. While achieving optimal accuracy, existing CTTA approaches present poor real-world applicability on resource-constrained edge devices, due to the substantial memory overhead and energy consumption. In this work, we first introduce a novel paradigm -- on-demand TTA -- which triggers adaptation only when a significant domain shift is detected. Then, we present OD-TTA, an on-demand TTA framework for accurate and efficient adaptation on edge devices. OD-TTA comprises three innovative techniques: 1) a lightweight domain shift detection mechanism to activate TTA only when it is needed, drastically reducing the overall computation overhead, 2) a source domain selection module that chooses an appropriate source model for adaptation, ensuring high and robust accuracy, 3) a decoupled Batch Normalization (BN) update scheme to enable memory-efficient adaptation with small batch sizes. Extensive experiments show that OD-TTA achieves comparable and even better performance while reducing the energy and computation overhead remarkably, making TTA a practical reality.
Rebalanced Multimodal Learning with Data-aware Unimodal Sampling
Mar 05, 2025To address the modality learning degeneration caused by modality imbalance, existing multimodal learning~(MML) approaches primarily attempt to balance the optimization process of each modality from the perspective of model learning. However, almost all existing methods ignore the modality imbalance caused by unimodal data sampling, i.e., equal unimodal data sampling often results in discrepancies in informational content, leading to modality imbalance. Therefore, in this paper, we propose a novel MML approach called \underline{D}ata-aware \underline{U}nimodal \underline{S}ampling~(\method), which aims to dynamically alleviate the modality imbalance caused by sampling. Specifically, we first propose a novel cumulative modality discrepancy to monitor the multimodal learning process. Based on the learning status, we propose a heuristic and a reinforcement learning~(RL)-based data-aware unimodal sampling approaches to adaptively determine the quantity of sampled data at each iteration, thus alleviating the modality imbalance from the perspective of sampling. Meanwhile, our method can be seamlessly incorporated into almost all existing multimodal learning approaches as a plugin. Experiments demonstrate that \method~can achieve the best performance by comparing with diverse state-of-the-art~(SOTA) baselines.
Confined Orthogonal Matching Pursuit for Sparse Random Combinatorial Matrices
Jan 02, 2025



Orthogonal matching pursuit (OMP) is a commonly used greedy algorithm for recovering sparse signals from compressed measurements. In this paper, we introduce a variant of the OMP algorithm to reduce the complexity of reconstructing a class of $K$-sparse signals $\boldsymbol{x} \in \mathbb{R}^{n}$ from measurements $\boldsymbol{y} = \boldsymbol{A}\boldsymbol{x}$, where $\boldsymbol{A} \in \{0,1\}^{m \times n}$ is a sparse random combinatorial matrix with $d~(d \leq m/2)$ ones per column. The proposed algorithm, referred to as the confined OMP algorithm, utilizes the properties of $\boldsymbol{x}$ and $\boldsymbol{A}$ to remove much of the redundancy in the dictionary (also referred to as $\boldsymbol{A}$) and thus fewer column indices of $\boldsymbol{A}$ need to be identified. To this end, we first define a confined set $\Gamma$ with $|\Gamma| \leq n$ and then prove that the support of $\boldsymbol{x}$ is a subset of $\Gamma$ with probability 1 if the distributions of non-zero components of $\boldsymbol{x}$ satisfy a certain condition. During the process of the confined OMP algorithm, the possibly chosen column indices are strictly confined into the confined set $\Gamma$. We further develop lower bounds on the probability of exact recovery of $\boldsymbol{x}$ using OMP algorithm and confined OMP algorithm with $K$ iterations, respectively. The obtained theoretical results of confined OMP algorithm can be used to optimize the column degree $d$ of $\boldsymbol{A}$. Finally, experimental results show that the confined OMP algorithm is more efficient in reconstructing a class of sparse signals compared to the OMP algorithm.
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
Dec 18, 2024
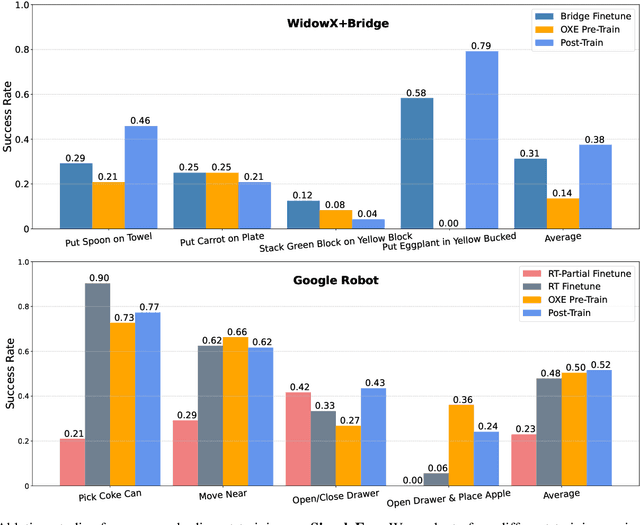

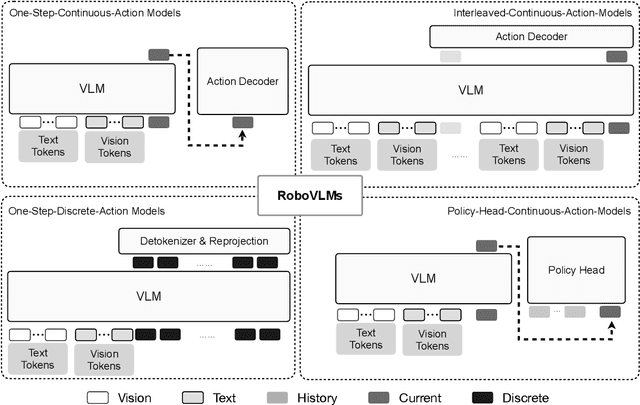
Foundation Vision Language Models (VLMs) exhibit strong capabilities in multi-modal representation learning, comprehension, and reasoning. By injecting action components into the VLMs, Vision-Language-Action Models (VLAs) can be naturally formed and also show promising performance. Existing work has demonstrated the effectiveness and generalization of VLAs in multiple scenarios and tasks. Nevertheless, the transfer from VLMs to VLAs is not trivial since existing VLAs differ in their backbones, action-prediction formulations, data distributions, and training recipes. This leads to a missing piece for a systematic understanding of the design choices of VLAs. In this work, we disclose the key factors that significantly influence the performance of VLA and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures, and when to add cross-embodiment data. The obtained results convince us firmly to explain why we need VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures, and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. We open-source all details, including codes, models, datasets, and toolkits, along with detailed training and evaluation recipes at: robovlms.github.io.
Effective Tuning Strategies for Generalist Robot Manipulation Policies
Oct 02, 2024Generalist robot manipulation policies (GMPs) have the potential to generalize across a wide range of tasks, devices, and environments. However, existing policies continue to struggle with out-of-distribution scenarios due to the inherent difficulty of collecting sufficient action data to cover extensively diverse domains. While fine-tuning offers a practical way to quickly adapt a GMPs to novel domains and tasks with limited samples, we observe that the performance of the resulting GMPs differs significantly with respect to the design choices of fine-tuning strategies. In this work, we first conduct an in-depth empirical study to investigate the effect of key factors in GMPs fine-tuning strategies, covering the action space, policy head, supervision signal and the choice of tunable parameters, where 2,500 rollouts are evaluated for a single configuration. We systematically discuss and summarize our findings and identify the key design choices, which we believe give a practical guideline for GMPs fine-tuning. We observe that in a low-data regime, with carefully chosen fine-tuning strategies, a GMPs significantly outperforms the state-of-the-art imitation learning algorithms. The results presented in this work establish a new baseline for future studies on fine-tuned GMPs, and provide a significant addition to the GMPs toolbox for the community.
MECD: Unlocking Multi-Event Causal Discovery in Video Reasoning
Sep 26, 2024



Video causal reasoning aims to achieve a high-level understanding of video content from a causal perspective. However, current video reasoning tasks are limited in scope, primarily executed in a question-answering paradigm and focusing on short videos containing only a single event and simple causal relationships, lacking comprehensive and structured causality analysis for videos with multiple events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relationships between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD requires identifying the causal associations between these events to derive a comprehensive, structured event-level video causal diagram explaining why and how the final result event occurred. To address MECD, we devise a novel framework inspired by the Granger Causality method, using an efficient mask-based event prediction model to perform an Event Granger Test, which estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to address challenges in MECD like causality confounding and illusory causality. Experiments validate the effectiveness of our framework in providing causal relationships in multi-event videos, outperforming GPT-4o and VideoLLaVA by 5.7% and 4.1%, respectively.
Automated Review Generation Method Based on Large Language Models
Jul 30, 2024



Literature research, vital for scientific advancement, is overwhelmed by the vast ocean of available information. Addressing this, we propose an automated review generation method based on Large Language Models (LLMs) to streamline literature processing and reduce cognitive load. In case study on propane dehydrogenation (PDH) catalysts, our method swiftly generated comprehensive reviews from 343 articles, averaging seconds per article per LLM account. Extended analysis of 1041 articles provided deep insights into catalysts' composition, structure, and performance. Recognizing LLMs' hallucinations, we employed a multi-layered quality control strategy, ensuring our method's reliability and effective hallucination mitigation. Expert verification confirms the accuracy and citation integrity of generated reviews, demonstrating LLM hallucination risks reduced to below 0.5% with over 95% confidence. Released Windows application enables one-click review generation, aiding researchers in tracking advancements and recommending literature. This approach showcases LLMs' role in enhancing scientific research productivity and sets the stage for further exploration.
Mixture of Experts based Multi-task Supervise Learning from Crowds
Jul 18, 2024



Existing truth inference methods in crowdsourcing aim to map redundant labels and items to the ground truth. They treat the ground truth as hidden variables and use statistical or deep learning-based worker behavior models to infer the ground truth. However, worker behavior models that rely on ground truth hidden variables overlook workers' behavior at the item feature level, leading to imprecise characterizations and negatively impacting the quality of truth inference. This paper proposes a new paradigm of multi-task supervised learning from crowds, which eliminates the need for modeling of items's ground truth in worker behavior models. Within this paradigm, we propose a worker behavior model at the item feature level called Mixture of Experts based Multi-task Supervised Learning from Crowds (MMLC). Two truth inference strategies are proposed within MMLC. The first strategy, named MMLC-owf, utilizes clustering methods in the worker spectral space to identify the projection vector of the oracle worker. Subsequently, the labels generated based on this vector are considered as the inferred truth. The second strategy, called MMLC-df, employs the MMLC model to fill the crowdsourced data, which can enhance the effectiveness of existing truth inference methods. Experimental results demonstrate that MMLC-owf outperforms state-of-the-art methods and MMLC-df enhances the quality of existing truth inference methods.