 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLADFA: A Framework of Using Large Language Models and Retrieval-Augmented Generation for Personal Data Flow Analysis in Privacy Policies
Jan 15, 2026Privacy policies help inform people about organisations' personal data processing practices, covering different aspects such as data collection, data storage, and sharing of personal data with third parties. Privacy policies are often difficult for people to fully comprehend due to the lengthy and complex legal language used and inconsistent practices across different sectors and organisations. To help conduct automated and large-scale analyses of privacy policies, many researchers have studied applications of machine learning and natural language processing techniques, including large language models (LLMs). While a limited number of prior studies utilised LLMs for extracting personal data flows from privacy policies, our approach builds on this line of work by combining LLMs with retrieval-augmented generation (RAG) and a customised knowledge base derived from existing studies. This paper presents the development of LADFA, an end-to-end computational framework, which can process unstructured text in a given privacy policy, extract personal data flows and construct a personal data flow graph, and conduct analysis of the data flow graph to facilitate insight discovery. The framework consists of a pre-processor, an LLM-based processor, and a data flow post-processor. We demonstrated and validated the effectiveness and accuracy of the proposed approach by conducting a case study that involved examining ten selected privacy policies from the automotive industry. Moreover, it is worth noting that LADFA is designed to be flexible and customisable, making it suitable for a range of text-based analysis tasks beyond privacy policy analysis.
aedFaCT: Scientific Fact-Checking Made Easier via Semi-Automatic Discovery of Relevant Expert Opinions
May 12, 2023



In this highly digitised world, fake news is a challenging problem that can cause serious harm to society. Considering how fast fake news can spread, automated methods, tools and services for assisting users to do fact-checking (i.e., fake news detection) become necessary and helpful, for both professionals, such as journalists and researchers, and the general public such as news readers. Experts, especially researchers, play an essential role in informing people about truth and facts, which makes them a good proxy for non-experts to detect fake news by checking relevant expert opinions and comments. Therefore, in this paper, we present aedFaCT, a web browser extension that can help professionals and news readers perform fact-checking via the automatic discovery of expert opinions relevant to the news of concern via shared keywords. Our initial evaluation with three independent testers (who did not participate in the development of the extension) indicated that aedFaCT can provide a faster experience to its users compared with traditional fact-checking practices based on manual online searches, without degrading the quality of retrieved evidence for fact-checking. The source code of aedFaCT is publicly available at https://github.com/altuncu/aedFaCT.
Visualising Personal Data Flows: Insights from a Case Study of Booking.com
Apr 20, 2023Commercial organisations are holding and processing an ever-increasing amount of personal data. Policies and laws are continually changing to require these companies to be more transparent regarding collection, storage, processing and sharing of this data. This paper reports our work of taking 'Booking.com' as a case study to visualise personal data flows extracted from their privacy policy. By showcasing how the company shares its consumers' personal data, we raise questions and extend discussions on the challenges and limitations of using privacy policy to inform customers the true scale and landscape of personal data flows. More importantly, this case study can inform us about future research on more data flow-oriented privacy policy analysis and on the construction of a more comprehensive ontology on personal data flows in complicated business ecosystems.
Graphical Models of False Information and Fact Checking Ecosystems
Aug 24, 2022
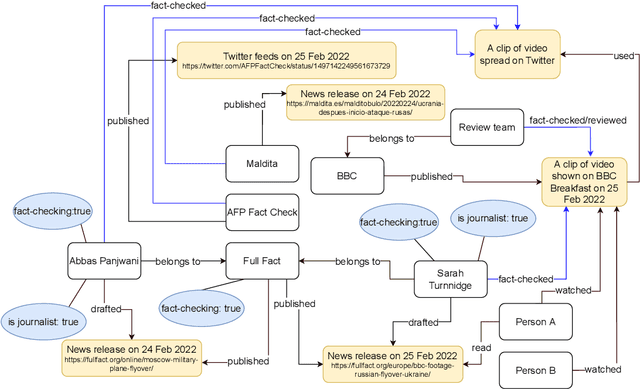
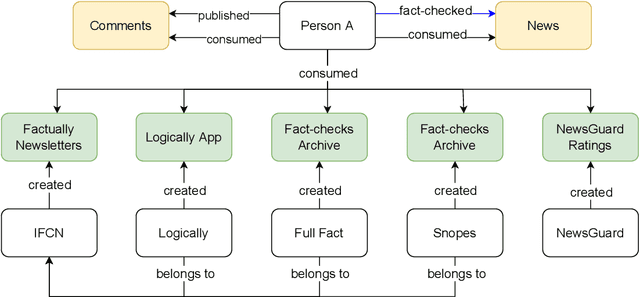
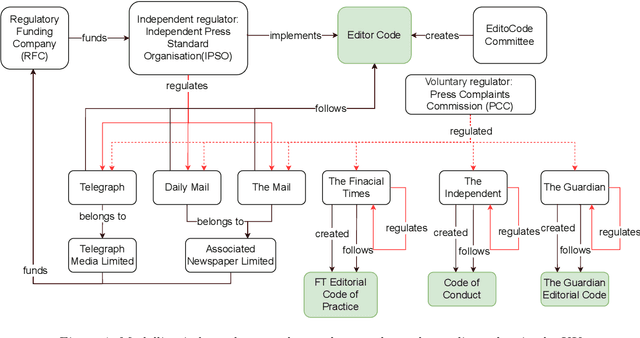
The wide spread of false information online including misinformation and disinformation has become a major problem for our highly digitised and globalised society. A lot of research has been done to better understand different aspects of false information online such as behaviours of different actors and patterns of spreading, and also on better detection and prevention of such information using technical and socio-technical means. One major approach to detect and debunk false information online is to use human fact-checkers, who can be helped by automated tools. Despite a lot of research done, we noticed a significant gap on the lack of conceptual models describing the complicated ecosystems of false information and fact checking. In this paper, we report the first graphical models of such ecosystems, focusing on false information online in multiple contexts, including traditional media outlets and user-generated content. The proposed models cover a wide range of entity types and relationships, and can be a new useful tool for researchers and practitioners to study false information online and the effects of fact checking.