 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Enhanced Reinforcement Learning for Long-Term User Satisfaction in Interactive Recommendation
Jan 27, 2026Interactive recommender systems can dynamically adapt to user feedback, but often suffer from content homogeneity and filter bubble effects due to overfitting short-term user preferences. While recent efforts aim to improve content diversity, they predominantly operate in static or one-shot settings, neglecting the long-term evolution of user interests. Reinforcement learning provides a principled framework for optimizing long-term user satisfaction by modeling sequential decision-making processes. However, its application in recommendation is hindered by sparse, long-tailed user-item interactions and limited semantic planning capabilities. In this work, we propose LLM-Enhanced Reinforcement Learning (LERL), a novel hierarchical recommendation framework that integrates the semantic planning power of LLM with the fine-grained adaptability of RL. LERL consists of a high-level LLM-based planner that selects semantically diverse content categories, and a low-level RL policy that recommends personalized items within the selected semantic space. This hierarchical design narrows the action space, enhances planning efficiency, and mitigates overexposure to redundant content. Extensive experiments on real-world datasets demonstrate that LERL significantly improves long-term user satisfaction when compared with state-of-the-art baselines. The implementation of LERL is available at https://anonymous.4open.science/r/code3-18D3/.
Listwise Preference Alignment Optimization for Tail Item Recommendation
Jul 03, 2025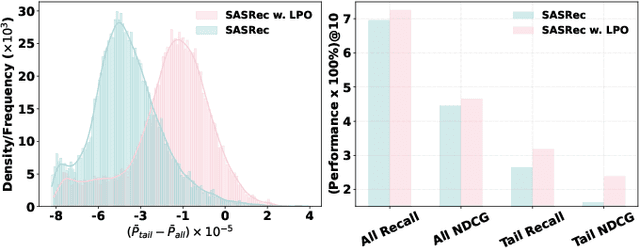
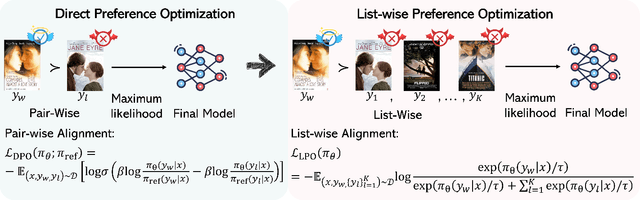
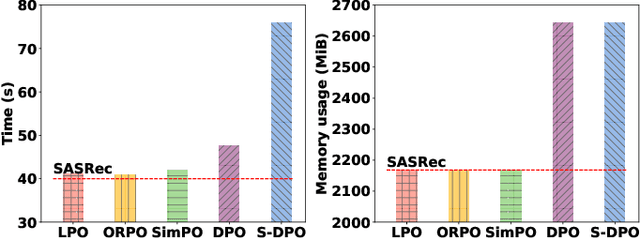
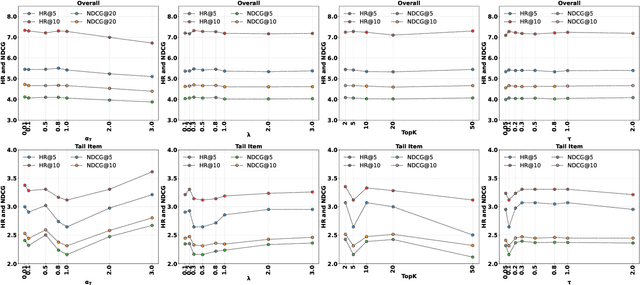
Preference alignment has achieved greater success on Large Language Models (LLMs) and drawn broad interest in recommendation research. Existing preference alignment methods for recommendation either require explicit reward modeling or only support pairwise preference comparison. The former directly increases substantial computational costs, while the latter hinders training efficiency on negative samples. Moreover, no existing effort has explored preference alignment solutions for tail-item recommendation. To bridge the above gaps, we propose LPO4Rec, which extends the Bradley-Terry model from pairwise comparison to listwise comparison, to improve the efficiency of model training. Specifically, we derive a closed form optimal policy to enable more efficient and effective training without explicit reward modeling. We also present an adaptive negative sampling and reweighting strategy to prioritize tail items during optimization and enhance performance in tail-item recommendations. Besides, we theoretically prove that optimizing the listwise preference optimization (LPO) loss is equivalent to maximizing the upper bound of the optimal reward. Our experiments on three public datasets show that our method outperforms 10 baselines by a large margin, achieving up to 50% performance improvement while reducing 17.9% GPU memory usage when compared with direct preference optimization (DPO) in tail-item recommendation. Our code is available at https://github.com/Yuhanleeee/LPO4Rec.
Dual Contrastive Transformer for Hierarchical Preference Modeling in Sequential Recommendation
Oct 30, 2024



Sequential recommender systems (SRSs) aim to predict the subsequent items which may interest users via comprehensively modeling users' complex preference embedded in the sequence of user-item interactions. However, most of existing SRSs often model users' single low-level preference based on item ID information while ignoring the high-level preference revealed by item attribute information, such as item category. Furthermore, they often utilize limited sequence context information to predict the next item while overlooking richer inter-item semantic relations. To this end, in this paper, we proposed a novel hierarchical preference modeling framework to substantially model the complex low- and high-level preference dynamics for accurate sequential recommendation. Specifically, in the framework, a novel dual-transformer module and a novel dual contrastive learning scheme have been designed to discriminatively learn users' low- and high-level preference and to effectively enhance both low- and high-level preference learning respectively. In addition, a novel semantics-enhanced context embedding module has been devised to generate more informative context embedding for further improving the recommendation performance. Extensive experiments on six real-world datasets have demonstrated both the superiority of our proposed method over the state-of-the-art ones and the rationality of our design.
Modeling Temporal Positive and Negative Excitation for Sequential Recommendation
Oct 29, 2024



Sequential recommendation aims to predict the next item which interests users via modeling their interest in items over time. Most of the existing works on sequential recommendation model users' dynamic interest in specific items while overlooking users' static interest revealed by some static attribute information of items, e.g., category, or brand. Moreover, existing works often only consider the positive excitation of a user's historical interactions on his/her next choice on candidate items while ignoring the commonly existing negative excitation, resulting in insufficient modeling dynamic interest. The overlook of static interest and negative excitation will lead to incomplete interest modeling and thus impede the recommendation performance. To this end, in this paper, we propose modeling both static interest and negative excitation for dynamic interest to further improve the recommendation performance. Accordingly, we design a novel Static-Dynamic Interest Learning (SDIL) framework featured with a novel Temporal Positive and Negative Excitation Modeling (TPNE) module for accurate sequential recommendation. TPNE is specially designed for comprehensively modeling dynamic interest based on temporal positive and negative excitation learning. Extensive experiments on three real-world datasets show that SDIL can effectively capture both static and dynamic interest and outperforms state-of-the-art baselines.
Graph and Sequential Neural Networks in Session-based Recommendation: A Survey
Aug 27, 2024Recent years have witnessed the remarkable success of recommendation systems (RSs) in alleviating the information overload problem. As a new paradigm of RSs, session-based recommendation (SR) specializes in users' short-term preference capture and aims to provide a more dynamic and timely recommendation based on the ongoing interacted actions. In this survey, we will give a comprehensive overview of the recent works on SR. First, we clarify the definitions of various SR tasks and introduce the characteristics of session-based recommendation against other recommendation tasks. Then, we summarize the existing methods in two categories: sequential neural network based methods and graph neural network (GNN) based methods. The standard frameworks and technical are also introduced. Finally, we discuss the challenges of SR and new research directions in this area.
Temporal Disentangled Contrastive Diffusion Model for Spatiotemporal Imputation
Feb 18, 2024



Spatiotemporal data analysis is pivotal across various domains, including transportation, meteorology, and healthcare. However, the data collected in real-world scenarios often suffers incompleteness due to sensor malfunctions and network transmission errors. Spatiotemporal imputation endeavours to predict missing values by exploiting the inherent spatial and temporal dependencies present in the observed data. Traditional approaches, which rely on classical statistical and machine learning techniques, are often inadequate, particularly when the data fails to meet strict distributional assumptions. In contrast, recent deep learning-based methods, leveraging graph and recurrent neural networks, have demonstrated enhanced efficacy. Nonetheless, these approaches are prone to error accumulation. Generative models have been increasingly adopted to circumvent the reliance on potentially inaccurate historical imputed values for future predictions. These models grapple with the challenge of producing unstable results, a particular issue in diffusion-based models. We aim to address these challenges by designing conditional features to guide the generative process and expedite training. Specifically, we introduce C$^2$TSD, a novel approach incorporating trend and seasonal information as conditional features and employing contrastive learning to improve model generalizability. The extensive experiments on three real-world datasets demonstrate the superior performance of C$^2$TSD over various state-of-the-art baselines.
Attention-aware Social Graph Transformer Networks for Stochastic Trajectory Prediction
Dec 26, 2023



Trajectory prediction is fundamental to various intelligent technologies, such as autonomous driving and robotics. The motion prediction of pedestrians and vehicles helps emergency braking, reduces collisions, and improves traffic safety. Current trajectory prediction research faces problems of complex social interactions, high dynamics and multi-modality. Especially, it still has limitations in long-time prediction. We propose Attention-aware Social Graph Transformer Networks for multi-modal trajectory prediction. We combine Graph Convolutional Networks and Transformer Networks by generating stable resolution pseudo-images from Spatio-temporal graphs through a designed stacking and interception method. Furthermore, we design the attention-aware module to handle social interaction information in scenarios involving mixed pedestrian-vehicle traffic. Thus, we maintain the advantages of the Graph and Transformer, i.e., the ability to aggregate information over an arbitrary number of neighbors and the ability to perform complex time-dependent data processing. We conduct experiments on datasets involving pedestrian, vehicle, and mixed trajectories, respectively. Our results demonstrate that our model minimizes displacement errors across various metrics and significantly reduces the likelihood of collisions. It is worth noting that our model effectively reduces the final displacement error, illustrating the ability of our model to predict for a long time.
GATGPT: A Pre-trained Large Language Model with Graph Attention Network for Spatiotemporal Imputation
Nov 24, 2023The analysis of spatiotemporal data is increasingly utilized across diverse domains, including transportation, healthcare, and meteorology. In real-world settings, such data often contain missing elements due to issues like sensor malfunctions and data transmission errors. The objective of spatiotemporal imputation is to estimate these missing values by understanding the inherent spatial and temporal relationships in the observed multivariate time series. Traditionally, spatiotemporal imputation has relied on specific, intricate architectures designed for this purpose, which suffer from limited applicability and high computational complexity. In contrast, our approach integrates pre-trained large language models (LLMs) into spatiotemporal imputation, introducing a groundbreaking framework, GATGPT. This framework merges a graph attention mechanism with LLMs. We maintain most of the LLM parameters unchanged to leverage existing knowledge for learning temporal patterns, while fine-tuning the upper layers tailored to various applications. The graph attention component enhances the LLM's ability to understand spatial relationships. Through tests on three distinct real-world datasets, our innovative approach demonstrates comparable results to established deep learning benchmarks.
Adversarial Robustness of Deep Reinforcement Learning based Dynamic Recommender Systems
Dec 02, 2021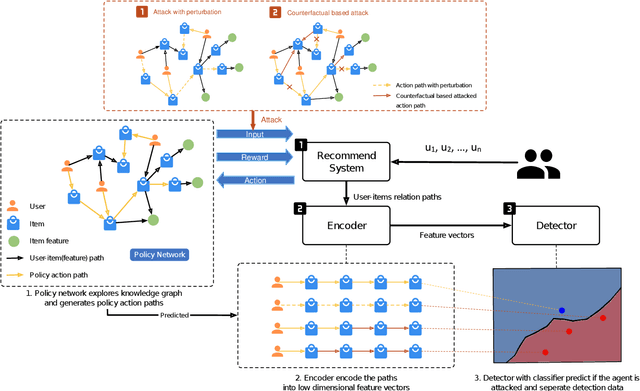
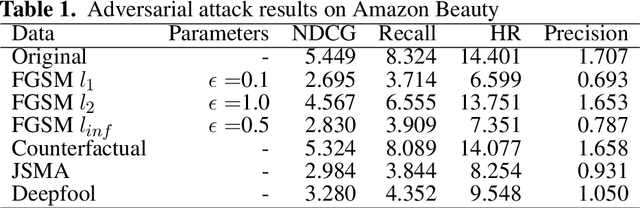
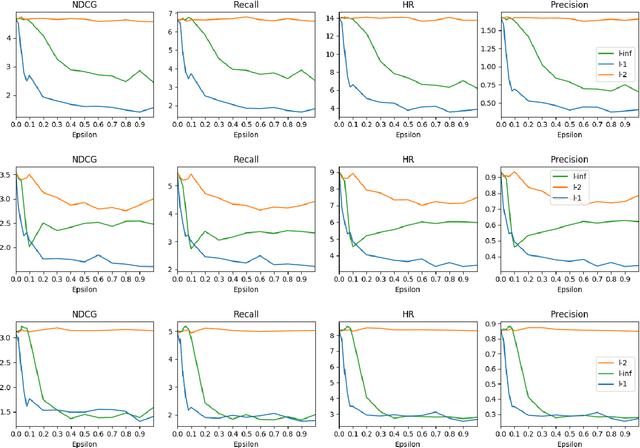
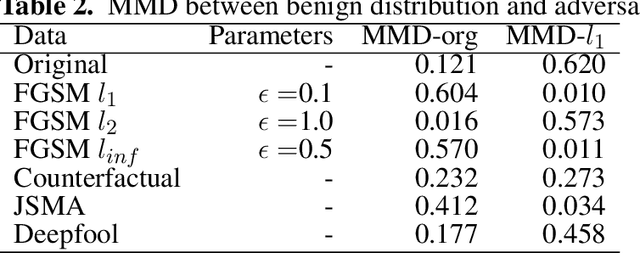
Adversarial attacks, e.g., adversarial perturbations of the input and adversarial samples, pose significant challenges to machine learning and deep learning techniques, including interactive recommendation systems. The latent embedding space of those techniques makes adversarial attacks difficult to detect at an early stage. Recent advance in causality shows that counterfactual can also be considered one of ways to generate the adversarial samples drawn from different distribution as the training samples. We propose to explore adversarial examples and attack agnostic detection on reinforcement learning-based interactive recommendation systems. We first craft different types of adversarial examples by adding perturbations to the input and intervening on the casual factors. Then, we augment recommendation systems by detecting potential attacks with a deep learning-based classifier based on the crafted data. Finally, we study the attack strength and frequency of adversarial examples and evaluate our model on standard datasets with multiple crafting methods. Our extensive experiments show that most adversarial attacks are effective, and both attack strength and attack frequency impact the attack performance. The strategically-timed attack achieves comparative attack performance with only 1/3 to 1/2 attack frequency. Besides, our black-box detector trained with one crafting method has the generalization ability over several other crafting methods.
An Entropy-guided Reinforced Partial Convolutional Network for Zero-Shot Learning
Nov 03, 2021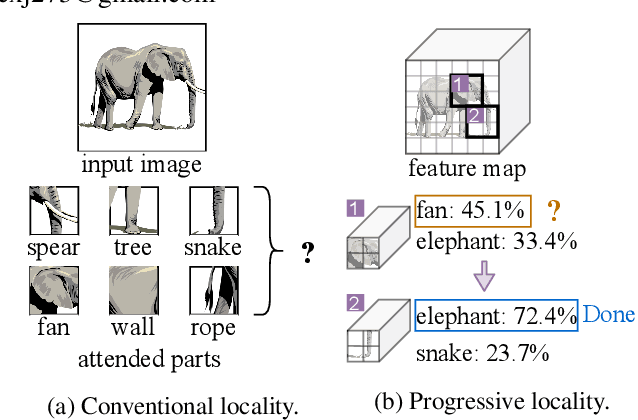
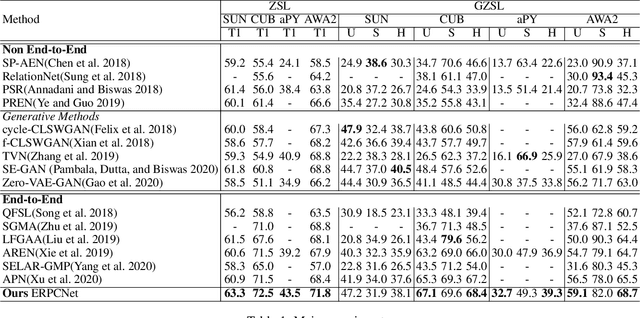
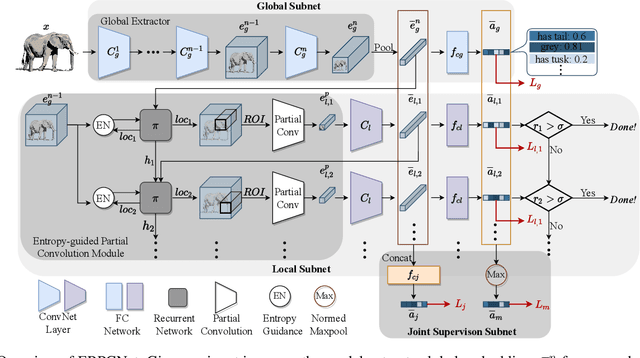
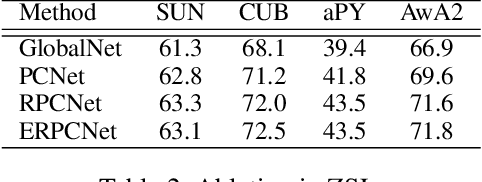
Zero-Shot Learning (ZSL) aims to transfer learned knowledge from observed classes to unseen classes via semantic correlations. A promising strategy is to learn a global-local representation that incorporates global information with extra localities (i.e., small parts/regions of inputs). However, existing methods discover localities based on explicit features without digging into the inherent properties and relationships among regions. In this work, we propose a novel Entropy-guided Reinforced Partial Convolutional Network (ERPCNet), which extracts and aggregates localities progressively based on semantic relevance and visual correlations without human-annotated regions. ERPCNet uses reinforced partial convolution and entropy guidance; it not only discovers global-cooperative localities dynamically but also converges faster for policy gradient optimization. We conduct extensive experiments to demonstrate ERPCNet's performance through comparisons with state-of-the-art methods under ZSL and Generalized Zero-Shot Learning (GZSL) settings on four benchmark datasets. We also show ERPCNet is time efficient and explainable through visualization analysis.