 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Asymmetric Loss for Learning with Noisy Labels
Jul 23, 2025Learning with noisy labels is a crucial task for training accurate deep neural networks. To mitigate label noise, prior studies have proposed various robust loss functions, particularly symmetric losses. Nevertheless, symmetric losses usually suffer from the underfitting issue due to the overly strict constraint. To address this problem, the Active Passive Loss (APL) jointly optimizes an active and a passive loss to mutually enhance the overall fitting ability. Within APL, symmetric losses have been successfully extended, yielding advanced robust loss functions. Despite these advancements, emerging theoretical analyses indicate that asymmetric losses, a new class of robust loss functions, possess superior properties compared to symmetric losses. However, existing asymmetric losses are not compatible with advanced optimization frameworks such as APL, limiting their potential and applicability. Motivated by this theoretical gap and the prospect of asymmetric losses, we extend the asymmetric loss to the more complex passive loss scenario and propose the Asymetric Mean Square Error (AMSE), a novel asymmetric loss. We rigorously establish the necessary and sufficient condition under which AMSE satisfies the asymmetric condition. By substituting the traditional symmetric passive loss in APL with our proposed AMSE, we introduce a novel robust loss framework termed Joint Asymmetric Loss (JAL). Extensive experiments demonstrate the effectiveness of our method in mitigating label noise. Code available at: https://github.com/cswjl/joint-asymmetric-loss
Boosting All-in-One Image Restoration via Self-Improved Privilege Learning
May 30, 2025Unified image restoration models for diverse and mixed degradations often suffer from unstable optimization dynamics and inter-task conflicts. This paper introduces Self-Improved Privilege Learning (SIPL), a novel paradigm that overcomes these limitations by innovatively extending the utility of privileged information (PI) beyond training into the inference stage. Unlike conventional Privilege Learning, where ground-truth-derived guidance is typically discarded after training, SIPL empowers the model to leverage its own preliminary outputs as pseudo-privileged signals for iterative self-refinement at test time. Central to SIPL is Proxy Fusion, a lightweight module incorporating a learnable Privileged Dictionary. During training, this dictionary distills essential high-frequency and structural priors from privileged feature representations. Critically, at inference, the same learned dictionary then interacts with features derived from the model's initial restoration, facilitating a self-correction loop. SIPL can be seamlessly integrated into various backbone architectures, offering substantial performance improvements with minimal computational overhead. Extensive experiments demonstrate that SIPL significantly advances the state-of-the-art on diverse all-in-one image restoration benchmarks. For instance, when integrated with the PromptIR model, SIPL achieves remarkable PSNR improvements of +4.58 dB on composite degradation tasks and +1.28 dB on diverse five-task benchmarks, underscoring its effectiveness and broad applicability. Codes are available at our project page https://github.com/Aitical/SIPL.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
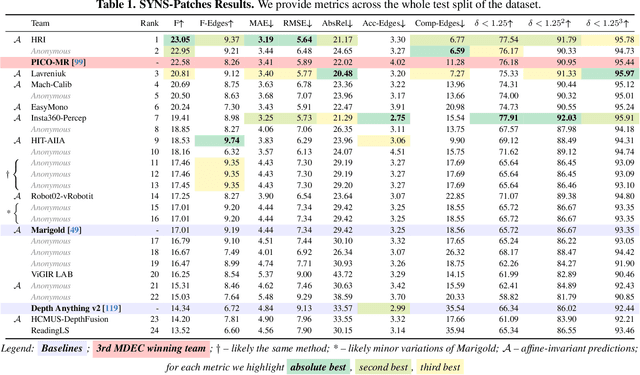
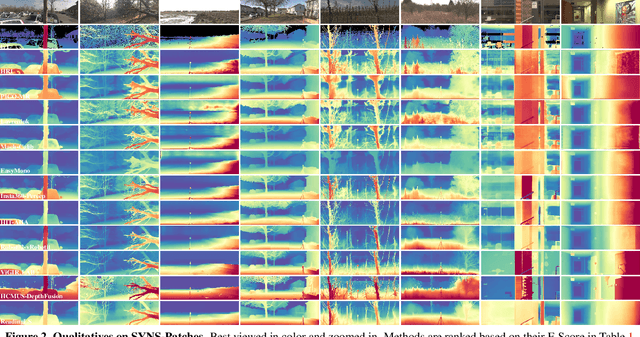
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Beyond Degradation Redundancy: Contrastive Prompt Learning for All-in-One Image Restoration
Apr 14, 2025


All-in-one image restoration, addressing diverse degradation types with a unified model, presents significant challenges in designing task-specific prompts that effectively guide restoration across multiple degradation scenarios. While adaptive prompt learning enables end-to-end optimization, it often yields overlapping or redundant task representations. Conversely, explicit prompts derived from pretrained classifiers enhance discriminability but may discard critical visual information for reconstruction. To address these limitations, we introduce Contrastive Prompt Learning (CPL), a novel framework that fundamentally enhances prompt-task alignment through two complementary innovations: a \emph{Sparse Prompt Module (SPM)} that efficiently captures degradation-specific features while minimizing redundancy, and a \emph{Contrastive Prompt Regularization (CPR)} that explicitly strengthens task boundaries by incorporating negative prompt samples across different degradation types. Unlike previous approaches that focus primarily on degradation classification, CPL optimizes the critical interaction between prompts and the restoration model itself. Extensive experiments across five comprehensive benchmarks demonstrate that CPL consistently enhances state-of-the-art all-in-one restoration models, achieving significant improvements in both standard multi-task scenarios and challenging composite degradation settings. Our framework establishes new state-of-the-art performance while maintaining parameter efficiency, offering a principled solution for unified image restoration.
Content-Aware Transformer for All-in-one Image Restoration
Apr 07, 2025



Image restoration has witnessed significant advancements with the development of deep learning models. Although Transformer architectures have progressed considerably in recent years, challenges remain, particularly the limited receptive field in window-based self-attention. In this work, we propose DSwinIR, a Deformable Sliding window Transformer for Image Restoration. DSwinIR introduces a novel deformable sliding window self-attention that adaptively adjusts receptive fields based on image content, enabling the attention mechanism to focus on important regions and enhance feature extraction aligned with salient features. Additionally, we introduce a central ensemble pattern to reduce the inclusion of irrelevant content within attention windows. In this way, the proposed DSwinIR model integrates the deformable sliding window Transformer and central ensemble pattern to amplify the strengths of both CNNs and Transformers while mitigating their limitations. Extensive experiments on various image restoration tasks demonstrate that DSwinIR achieves state-of-the-art performance. For example, in image deraining, compared to DRSformer on the SPA dataset, DSwinIR achieves a 0.66 dB PSNR improvement. In all-in-one image restoration, compared to PromptIR, DSwinIR achieves over a 0.66 dB and 1.04 dB improvement on three-task and five-task settings, respectively. Pretrained models and code are available at our project https://github.com/Aitical/DSwinIR.
Balancing Task-invariant Interaction and Task-specific Adaptation for Unified Image Fusion
Apr 07, 2025



Unified image fusion aims to integrate complementary information from multi-source images, enhancing image quality through a unified framework applicable to diverse fusion tasks. While treating all fusion tasks as a unified problem facilitates task-invariant knowledge sharing, it often overlooks task-specific characteristics, thereby limiting the overall performance. Existing general image fusion methods incorporate explicit task identification to enable adaptation to different fusion tasks. However, this dependence during inference restricts the model's generalization to unseen fusion tasks. To address these issues, we propose a novel unified image fusion framework named "TITA", which dynamically balances both Task-invariant Interaction and Task-specific Adaptation. For task-invariant interaction, we introduce the Interaction-enhanced Pixel Attention (IPA) module to enhance pixel-wise interactions for better multi-source complementary information extraction. For task-specific adaptation, the Operation-based Adaptive Fusion (OAF) module dynamically adjusts operation weights based on task properties. Additionally, we incorporate the Fast Adaptive Multitask Optimization (FAMO) strategy to mitigate the impact of gradient conflicts across tasks during joint training. Extensive experiments demonstrate that TITA not only achieves competitive performance compared to specialized methods across three image fusion scenarios but also exhibits strong generalization to unseen fusion tasks.
COB-GS: Clear Object Boundaries in 3DGS Segmentation Based on Boundary-Adaptive Gaussian Splitting
Mar 26, 2025Accurate object segmentation is crucial for high-quality scene understanding in the 3D vision domain. However, 3D segmentation based on 3D Gaussian Splatting (3DGS) struggles with accurately delineating object boundaries, as Gaussian primitives often span across object edges due to their inherent volume and the lack of semantic guidance during training. In order to tackle these challenges, we introduce Clear Object Boundaries for 3DGS Segmentation (COB-GS), which aims to improve segmentation accuracy by clearly delineating blurry boundaries of interwoven Gaussian primitives within the scene. Unlike existing approaches that remove ambiguous Gaussians and sacrifice visual quality, COB-GS, as a 3DGS refinement method, jointly optimizes semantic and visual information, allowing the two different levels to cooperate with each other effectively. Specifically, for the semantic guidance, we introduce a boundary-adaptive Gaussian splitting technique that leverages semantic gradient statistics to identify and split ambiguous Gaussians, aligning them closely with object boundaries. For the visual optimization, we rectify the degraded suboptimal texture of the 3DGS scene, particularly along the refined boundary structures. Experimental results show that COB-GS substantially improves segmentation accuracy and robustness against inaccurate masks from pre-trained model, yielding clear boundaries while preserving high visual quality. Code is available at https://github.com/ZestfulJX/COB-GS.
FUSE: Label-Free Image-Event Joint Monocular Depth Estimation via Frequency-Decoupled Alignment and Degradation-Robust Fusion
Mar 26, 2025Image-event joint depth estimation methods leverage complementary modalities for robust perception, yet face challenges in generalizability stemming from two factors: 1) limited annotated image-event-depth datasets causing insufficient cross-modal supervision, and 2) inherent frequency mismatches between static images and dynamic event streams with distinct spatiotemporal patterns, leading to ineffective feature fusion. To address this dual challenge, we propose Frequency-decoupled Unified Self-supervised Encoder (FUSE) with two synergistic components: The Parameter-efficient Self-supervised Transfer (PST) establishes cross-modal knowledge transfer through latent space alignment with image foundation models, effectively mitigating data scarcity by enabling joint encoding without depth ground truth. Complementing this, we propose the Frequency-Decoupled Fusion module (FreDFuse) to explicitly decouple high-frequency edge features from low-frequency structural components, resolving modality-specific frequency mismatches through physics-aware fusion. This combined approach enables FUSE to construct a universal image-event encoder that only requires lightweight decoder adaptation for target datasets. Extensive experiments demonstrate state-of-the-art performance with 14% and 24.9% improvements in Abs.Rel on MVSEC and DENSE datasets. The framework exhibits remarkable zero-shot adaptability to challenging scenarios including extreme lighting and motion blur, significantly advancing real-world deployment capabilities. The source code for our method is publicly available at: https://github.com/sunpihai-up/FUSE
CALLIC: Content Adaptive Learning for Lossless Image Compression
Dec 23, 2024



Learned lossless image compression has achieved significant advancements in recent years. However, existing methods often rely on training amortized generative models on massive datasets, resulting in sub-optimal probability distribution estimation for specific testing images during encoding process. To address this challenge, we explore the connection between the Minimum Description Length (MDL) principle and Parameter-Efficient Transfer Learning (PETL), leading to the development of a novel content-adaptive approach for learned lossless image compression, dubbed CALLIC. Specifically, we first propose a content-aware autoregressive self-attention mechanism by leveraging convolutional gating operations, termed Masked Gated ConvFormer (MGCF), and pretrain MGCF on training dataset. Cache then Crop Inference (CCI) is proposed to accelerate the coding process. During encoding, we decompose pre-trained layers, including depth-wise convolutions, using low-rank matrices and then adapt the incremental weights on testing image by Rate-guided Progressive Fine-Tuning (RPFT). RPFT fine-tunes with gradually increasing patches that are sorted in descending order by estimated entropy, optimizing learning process and reducing adaptation time. Extensive experiments across diverse datasets demonstrate that CALLIC sets a new state-of-the-art (SOTA) for learned lossless image compression.