 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Efficient Few-shot Adaptation for Vision Transformers
Jan 06, 2023The task of Few-shot Learning (FSL) aims to do the inference on novel categories containing only few labeled examples, with the help of knowledge learned from base categories containing abundant labeled training samples. While there are numerous works into FSL task, Vision Transformers (ViTs) have rarely been taken as the backbone to FSL with few trials focusing on naive finetuning of whole backbone or classification layer.} Essentially, despite ViTs have been shown to enjoy comparable or even better performance on other vision tasks, it is still very nontrivial to efficiently finetune the ViTs in real-world FSL scenarios. To this end, we propose a novel efficient Transformer Tuning (eTT) method that facilitates finetuning ViTs in the FSL tasks. The key novelties come from the newly presented Attentive Prefix Tuning (APT) and Domain Residual Adapter (DRA) for the task and backbone tuning, individually. Specifically, in APT, the prefix is projected to new key and value pairs that are attached to each self-attention layer to provide the model with task-specific information. Moreover, we design the DRA in the form of learnable offset vectors to handle the potential domain gaps between base and novel data. To ensure the APT would not deviate from the initial task-specific information much, we further propose a novel prototypical regularization, which maximizes the similarity between the projected distribution of prefix and initial prototypes, regularizing the update procedure. Our method receives outstanding performance on the challenging Meta-Dataset. We conduct extensive experiments to show the efficacy of our model.
Vocabulary-informed Zero-shot and Open-set Learning
Jan 04, 2023Despite significant progress in object categorization, in recent years, a number of important challenges remain; mainly, the ability to learn from limited labeled data and to recognize object classes within large, potentially open, set of labels. Zero-shot learning is one way of addressing these challenges, but it has only been shown to work with limited sized class vocabularies and typically requires separation between supervised and unsupervised classes, allowing former to inform the latter but not vice versa. We propose the notion of vocabulary-informed learning to alleviate the above mentioned challenges and address problems of supervised, zero-shot, generalized zero-shot and open set recognition using a unified framework. Specifically, we propose a weighted maximum margin framework for semantic manifold-based recognition that incorporates distance constraints from (both supervised and unsupervised) vocabulary atoms. Distance constraints ensure that labeled samples are projected closer to their correct prototypes, in the embedding space, than to others. We illustrate that resulting model shows improvements in supervised, zero-shot, generalized zero-shot, and large open set recognition, with up to 310K class vocabulary on Animal with Attributes and ImageNet datasets.
* 17 pages, 8 figures. TPAMI 2019 extended from CVPR 2016 (arXiv:1604.07093)
Compositional Scene Modeling with Global Object-Centric Representations
Nov 24, 2022



The appearance of the same object may vary in different scene images due to perspectives and occlusions between objects. Humans can easily identify the same object, even if occlusions exist, by completing the occluded parts based on its canonical image in the memory. Achieving this ability is still a challenge for machine learning, especially under the unsupervised learning setting. Inspired by such an ability of humans, this paper proposes a compositional scene modeling method to infer global representations of canonical images of objects without any supervision. The representation of each object is divided into an intrinsic part, which characterizes globally invariant information (i.e. canonical representation of an object), and an extrinsic part, which characterizes scene-dependent information (e.g., position and size). To infer the intrinsic representation of each object, we employ a patch-matching strategy to align the representation of a potentially occluded object with the canonical representations of objects, and sample the most probable canonical representation based on the category of object determined by amortized variational inference. Extensive experiments are conducted on four object-centric learning benchmarks, and experimental results demonstrate that the proposed method not only outperforms state-of-the-arts in terms of segmentation and reconstruction, but also achieves good global object identification performance.
Chinese Character Recognition with Radical-Structured Stroke Trees
Nov 24, 2022



The flourishing blossom of deep learning has witnessed the rapid development of Chinese character recognition. However, it remains a great challenge that the characters for testing may have different distributions from those of the training dataset. Existing methods based on a single-level representation (character-level, radical-level, or stroke-level) may be either too sensitive to distribution changes (e.g., induced by blurring, occlusion, and zero-shot problems) or too tolerant to one-to-many ambiguities. In this paper, we represent each Chinese character as a stroke tree, which is organized according to its radical structures, to fully exploit the merits of both radical and stroke levels in a decent way. We propose a two-stage decomposition framework, where a Feature-to-Radical Decoder perceives radical structures and radical regions, and a Radical-to-Stroke Decoder further predicts the stroke sequences according to the features of radical regions. The generated radical structures and stroke sequences are encoded as a Radical-Structured Stroke Tree (RSST), which is fed to a Tree-to-Character Translator based on the proposed Weighted Edit Distance to match the closest candidate character in the RSST lexicon. Our extensive experimental results demonstrate that the proposed method outperforms the state-of-the-art single-level methods by increasing margins as the distribution difference becomes more severe in the blurring, occlusion, and zero-shot scenarios, which indeed validates the robustness of the proposed method.
Cross-domain Federated Adaptive Prompt Tuning for CLIP
Nov 15, 2022



Federated learning (FL) allows multiple parties to collaboratively train a global model without disclosing their data. Existing research often requires all model parameters to participate in the training procedure. However, with the advent of powerful pre-trained models, it becomes possible to achieve higher performance with fewer learnable parameters in FL. In this paper, we propose a federated adaptive prompt tuning algorithm, FedAPT, for cross-domain federated image classification scenarios with the vision-language pre-trained model, CLIP, which gives play to the strong representation ability in FL. Compared with direct federated prompt tuning, our core idea is to adaptively unlock specific domain knowledge for each test sample in order to provide them with personalized prompts. To implement this idea, we design an adaptive prompt tuning module, which consists of a global prompt, an adaptive network, and some keys. The server randomly generates a set of keys and assigns a unique key to each client. Then all clients cooperatively train the global adaptive network and global prompt with the local datasets and the frozen keys. Ultimately, the global aggregation model can assign a personalized prompt to CLIP based on the domain features of each test sample. We perform extensive experiments on two multi-domain image classification datasets. The results show that FedAPT can achieve better performance with less than 10\% of the number of parameters of the fully trained model, and the global model can perform well in different client domains simultaneously.
Domain Discrepancy Aware Distillation for Model Aggregation in Federated Learning
Oct 04, 2022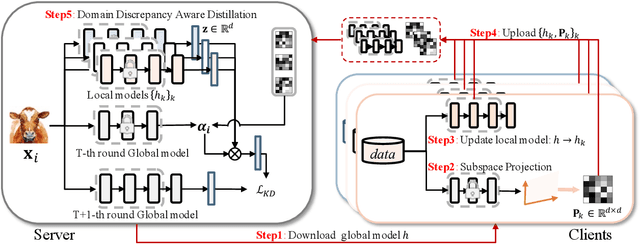
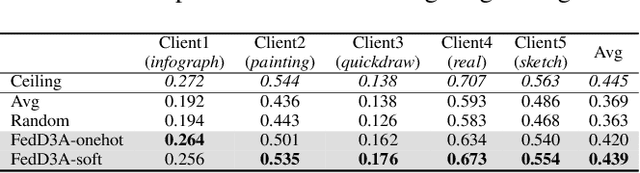

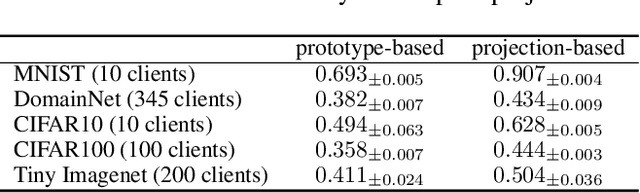
Knowledge distillation has recently become popular as a method of model aggregation on the server for federated learning. It is generally assumed that there are abundant public unlabeled data on the server. However, in reality, there exists a domain discrepancy between the datasets of the server domain and a client domain, which limits the performance of knowledge distillation. How to improve the aggregation under such a domain discrepancy setting is still an open problem. In this paper, we first analyze the generalization bound of the aggregation model produced from knowledge distillation for the client domains, and then describe two challenges, server-to-client discrepancy and client-to-client discrepancy, brought to the aggregation model by the domain discrepancies. Following our analysis, we propose an adaptive knowledge aggregation algorithm FedD3A based on domain discrepancy aware distillation to lower the bound. FedD3A performs adaptive weighting at the sample level in each round of FL. For each sample in the server domain, only the client models of its similar domains will be selected for playing the teacher role. To achieve this, we show that the discrepancy between the server-side sample and the client domain can be approximately measured using a subspace projection matrix calculated on each client without accessing its raw data. The server can thus leverage the projection matrices from multiple clients to assign weights to the corresponding teacher models for each server-side sample. We validate FedD3A on two popular cross-domain datasets and show that it outperforms the compared competitors in both cross-silo and cross-device FL settings.
Dynamic Graph Message Passing Networks for Visual Recognition
Sep 20, 2022

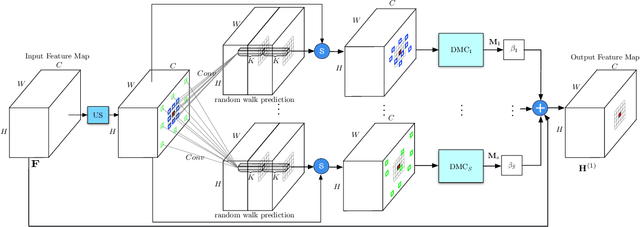
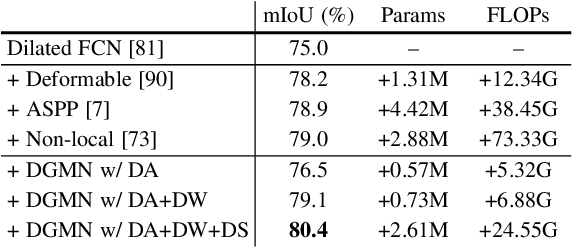
Modelling long-range dependencies is critical for scene understanding tasks in computer vision. Although convolution neural networks (CNNs) have excelled in many vision tasks, they are still limited in capturing long-range structured relationships as they typically consist of layers of local kernels. A fully-connected graph, such as the self-attention operation in Transformers, is beneficial for such modelling, however, its computational overhead is prohibitive. In this paper, we propose a dynamic graph message passing network, that significantly reduces the computational complexity compared to related works modelling a fully-connected graph. This is achieved by adaptively sampling nodes in the graph, conditioned on the input, for message passing. Based on the sampled nodes, we dynamically predict node-dependent filter weights and the affinity matrix for propagating information between them. This formulation allows us to design a self-attention module, and more importantly a new Transformer-based backbone network, that we use for both image classification pretraining, and for addressing various downstream tasks (object detection, instance and semantic segmentation). Using this model, we show significant improvements with respect to strong, state-of-the-art baselines on four different tasks. Our approach also outperforms fully-connected graphs while using substantially fewer floating-point operations and parameters. Code and models will be made publicly available at https://github.com/fudan-zvg/DGMN2
Compositional Law Parsing with Latent Random Functions
Sep 15, 2022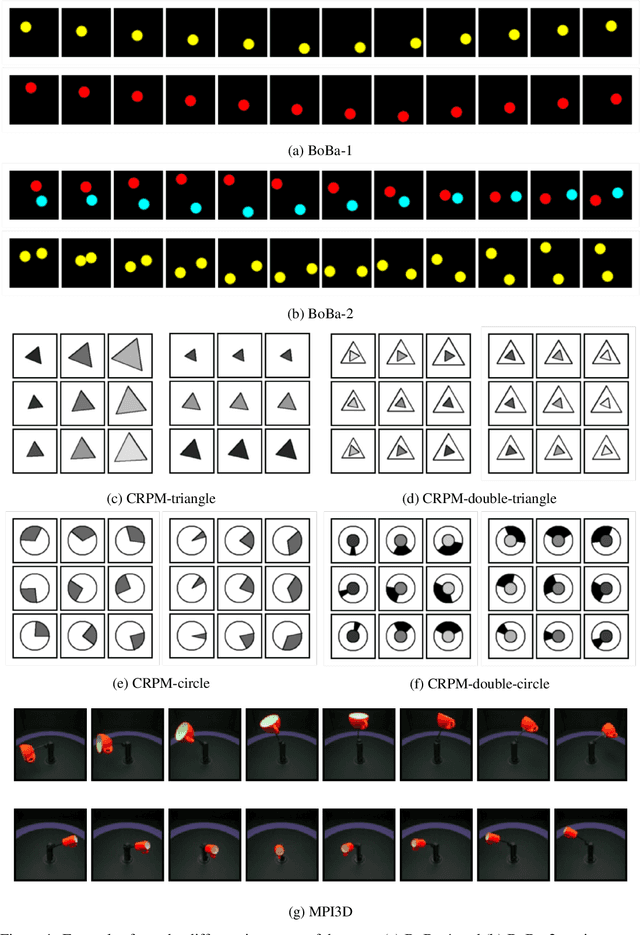
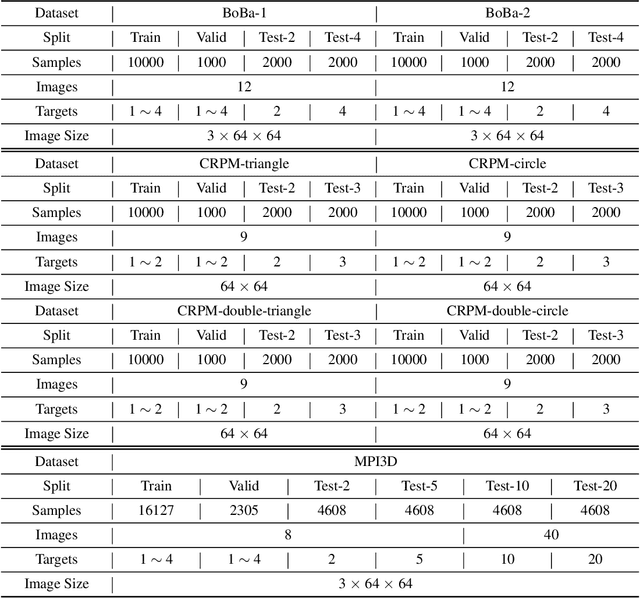
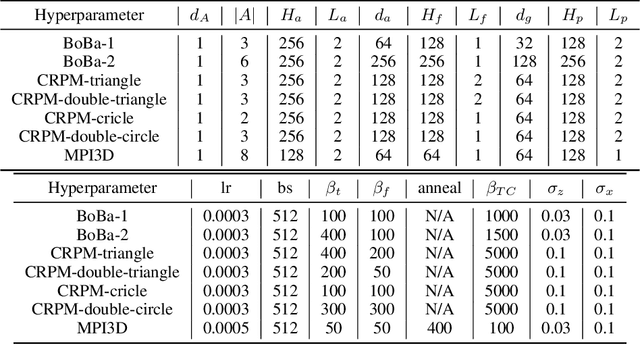
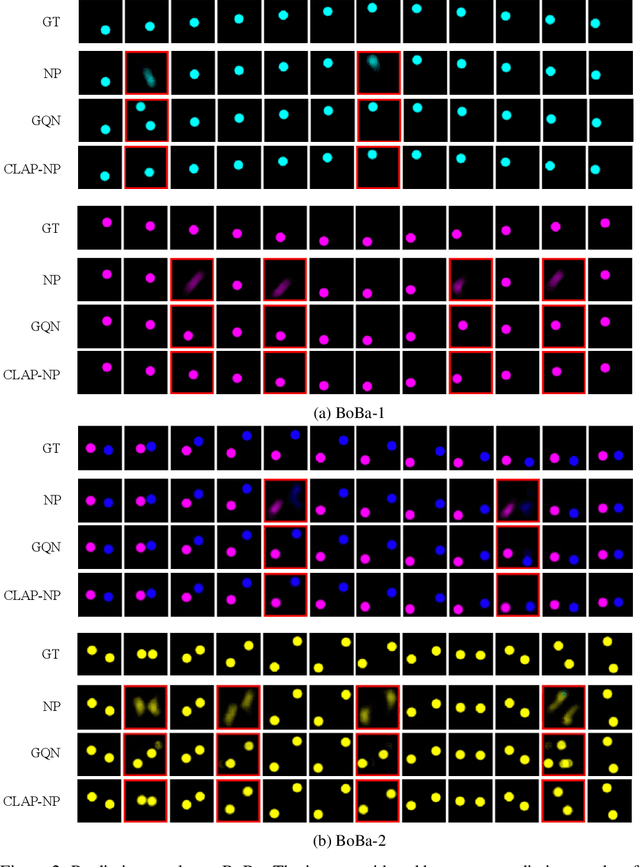
Human cognition has compositionality. We understand a scene by decomposing the scene into different concepts (e.g. shape and position of an object) and learning the respective laws of these concepts which may be either natural (e.g. laws of motion) or man-made (e.g. laws of a game). The automatic parsing of these laws indicates the model's ability to understand the scene, which makes law parsing play a central role in many visual tasks. In this paper, we propose a deep latent variable model for Compositional LAw Parsing (CLAP). CLAP achieves the human-like compositionality ability through an encoding-decoding architecture to represent concepts in the scene as latent variables, and further employ concept-specific random functions, instantiated with Neural Processes, in the latent space to capture the law on each concept. Our experimental results demonstrate that CLAP outperforms the compared baseline methods in multiple visual tasks including intuitive physics, abstract visual reasoning, and scene representation. In addition, CLAP can learn concept-specific laws in a scene without supervision and one can edit laws through modifying the corresponding latent random functions, validating its interpretability and manipulability.
AGO-Net: Association-Guided 3D Point Cloud Object Detection Network
Aug 24, 2022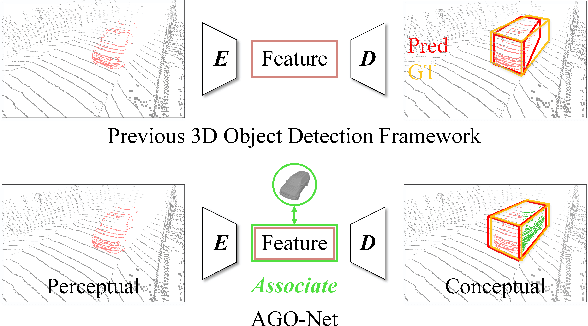
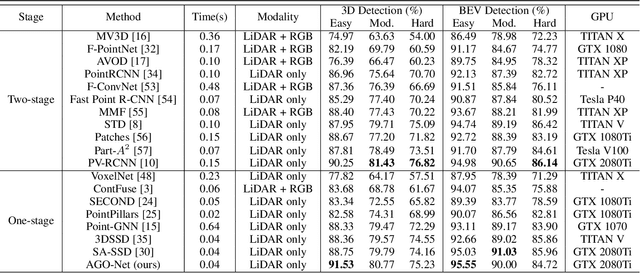
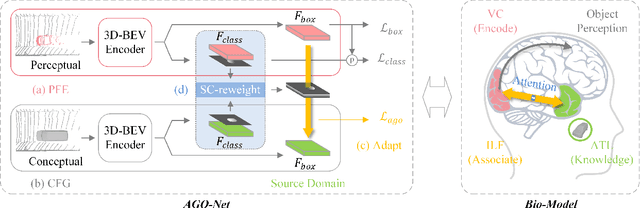
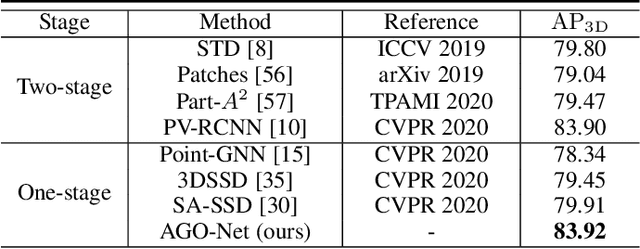
The human brain can effortlessly recognize and localize objects, whereas current 3D object detection methods based on LiDAR point clouds still report inferior performance for detecting occluded and distant objects: the point cloud appearance varies greatly due to occlusion, and has inherent variance in point densities along the distance to sensors. Therefore, designing feature representations robust to such point clouds is critical. Inspired by human associative recognition, we propose a novel 3D detection framework that associates intact features for objects via domain adaptation. We bridge the gap between the perceptual domain, where features are derived from real scenes with sub-optimal representations, and the conceptual domain, where features are extracted from augmented scenes that consist of non-occlusion objects with rich detailed information. A feasible method is investigated to construct conceptual scenes without external datasets. We further introduce an attention-based re-weighting module that adaptively strengthens the feature adaptation of more informative regions. The network's feature enhancement ability is exploited without introducing extra cost during inference, which is plug-and-play in various 3D detection frameworks. We achieve new state-of-the-art performance on the KITTI 3D detection benchmark in both accuracy and speed. Experiments on nuScenes and Waymo datasets also validate the versatility of our method.
LoRD: Local 4D Implicit Representation for High-Fidelity Dynamic Human Modeling
Aug 18, 2022


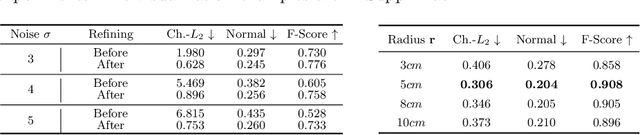
Recent progress in 4D implicit representation focuses on globally controlling the shape and motion with low dimensional latent vectors, which is prone to missing surface details and accumulating tracking error. While many deep local representations have shown promising results for 3D shape modeling, their 4D counterpart does not exist yet. In this paper, we fill this blank by proposing a novel Local 4D implicit Representation for Dynamic clothed human, named LoRD, which has the merits of both 4D human modeling and local representation, and enables high-fidelity reconstruction with detailed surface deformations, such as clothing wrinkles. Particularly, our key insight is to encourage the network to learn the latent codes of local part-level representation, capable of explaining the local geometry and temporal deformations. To make the inference at test-time, we first estimate the inner body skeleton motion to track local parts at each time step, and then optimize the latent codes for each part via auto-decoding based on different types of observed data. Extensive experiments demonstrate that the proposed method has strong capability for representing 4D human, and outperforms state-of-the-art methods on practical applications, including 4D reconstruction from sparse points, non-rigid depth fusion, both qualitatively and quantitatively.