 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpDet: Exploring Implicit Fields for 3D Object Detection
Mar 31, 2022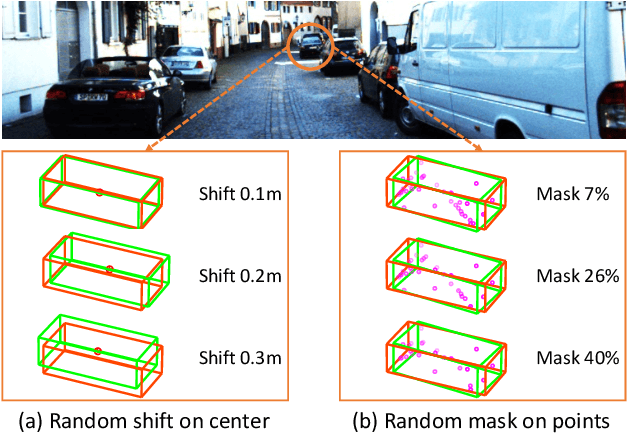
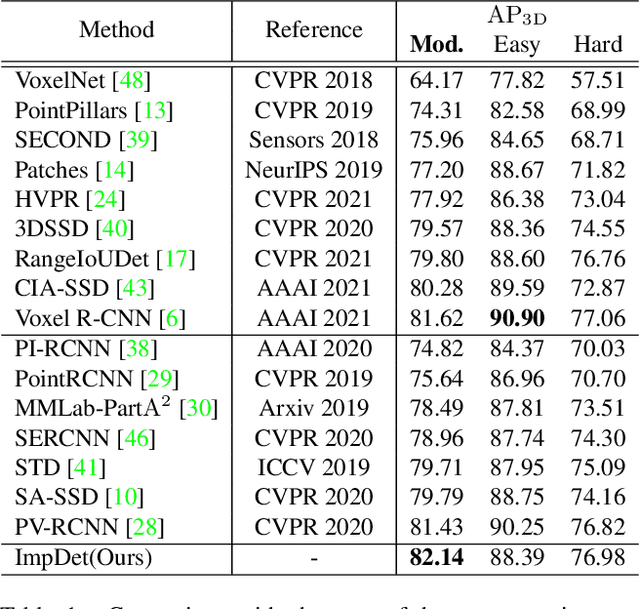
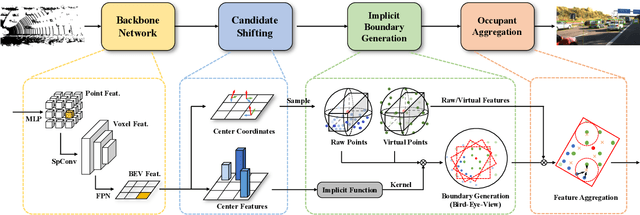
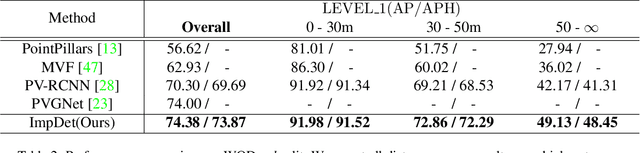
Conventional 3D object detection approaches concentrate on bounding boxes representation learning with several parameters, i.e., localization, dimension, and orientation. Despite its popularity and universality, such a straightforward paradigm is sensitive to slight numerical deviations, especially in localization. By exploiting the property that point clouds are naturally captured on the surface of objects along with accurate location and intensity information, we introduce a new perspective that views bounding box regression as an implicit function. This leads to our proposed framework, termed Implicit Detection or ImpDet, which leverages implicit field learning for 3D object detection. Our ImpDet assigns specific values to points in different local 3D spaces, thereby high-quality boundaries can be generated by classifying points inside or outside the boundary. To solve the problem of sparsity on the object surface, we further present a simple yet efficient virtual sampling strategy to not only fill the empty region, but also learn rich semantic features to help refine the boundaries. Extensive experimental results on KITTI and Waymo benchmarks demonstrate the effectiveness and robustness of unifying implicit fields into object detection.
BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
Mar 24, 2022
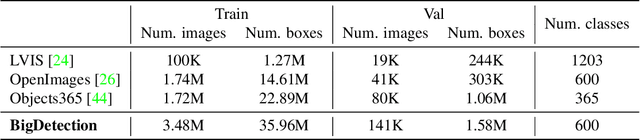
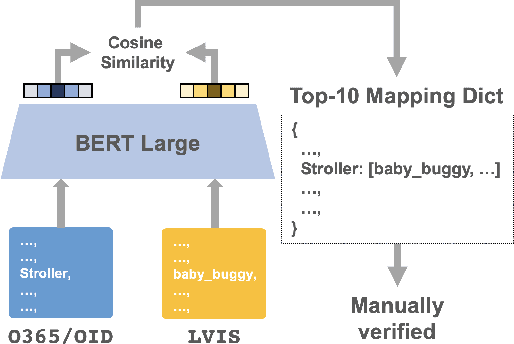
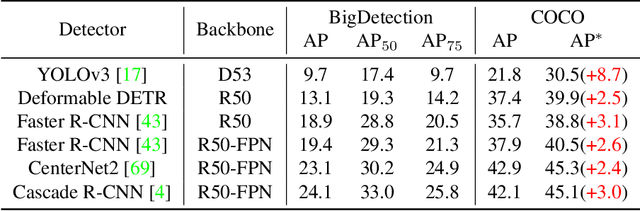
Multiple datasets and open challenges for object detection have been introduced in recent years. To build more general and powerful object detection systems, in this paper, we construct a new large-scale benchmark termed BigDetection. Our goal is to simply leverage the training data from existing datasets (LVIS, OpenImages and Object365) with carefully designed principles, and curate a larger dataset for improved detector pre-training. Specifically, we generate a new taxonomy which unifies the heterogeneous label spaces from different sources. Our BigDetection dataset has 600 object categories and contains over 3.4M training images with 36M bounding boxes. It is much larger in multiple dimensions than previous benchmarks, which offers both opportunities and challenges. Extensive experiments demonstrate its validity as a new benchmark for evaluating different object detection methods, and its effectiveness as a pre-training dataset.
QS-Craft: Learning to Quantize, Scrabble and Craft for Conditional Human Motion Animation
Mar 22, 2022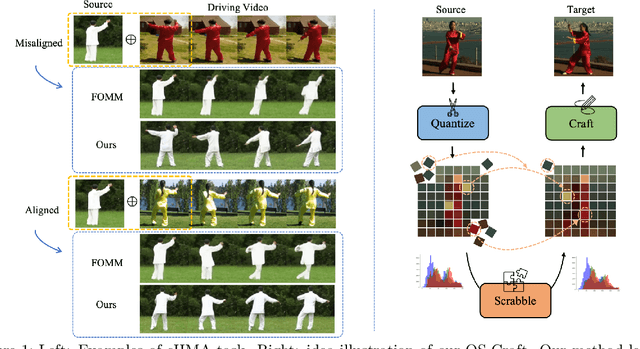
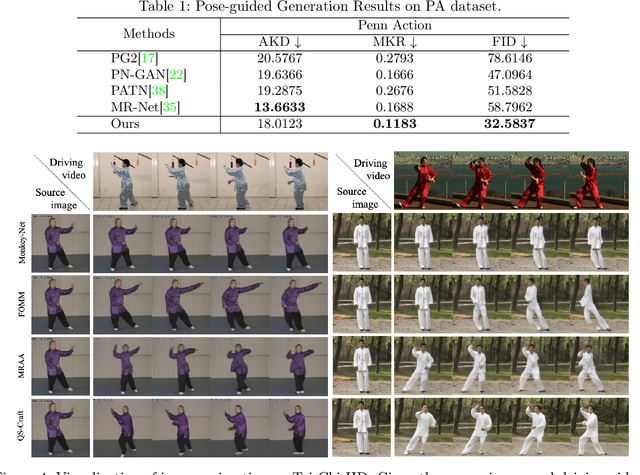
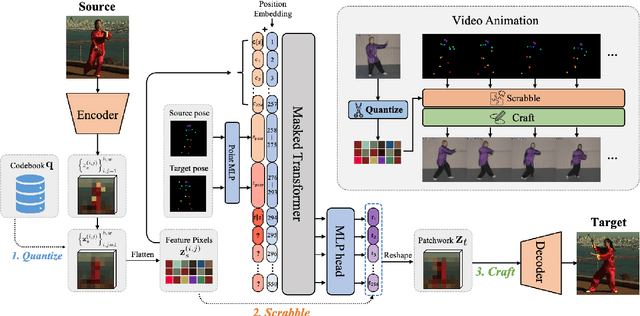
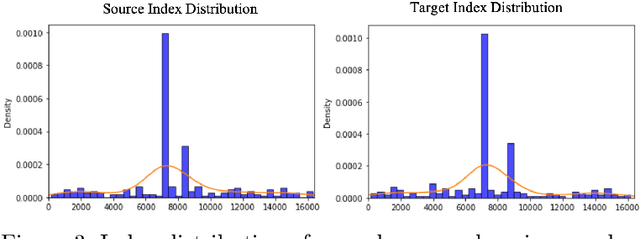
This paper studies the task of conditional Human Motion Animation (cHMA). Given a source image and a driving video, the model should animate the new frame sequence, in which the person in the source image should perform a similar motion as the pose sequence from the driving video. Despite the success of Generative Adversarial Network (GANs) methods in image and video synthesis, it is still very challenging to conduct cHMA due to the difficulty in efficiently utilizing the conditional guided information such as images or poses, and generating images of good visual quality. To this end, this paper proposes a novel model of learning to Quantize, Scrabble, and Craft (QS-Craft) for conditional human motion animation. The key novelties come from the newly introduced three key steps: quantize, scrabble and craft. Particularly, our QS-Craft employs transformer in its structure to utilize the attention architectures. The guided information is represented as a pose coordinate sequence extracted from the driving videos. Extensive experiments on human motion datasets validate the efficacy of our model.
H4D: Human 4D Modeling by Learning Neural Compositional Representation
Mar 02, 2022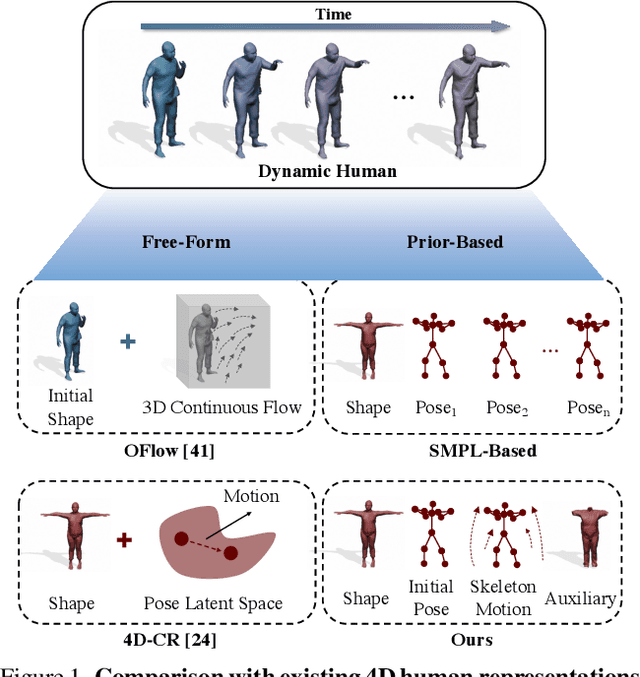
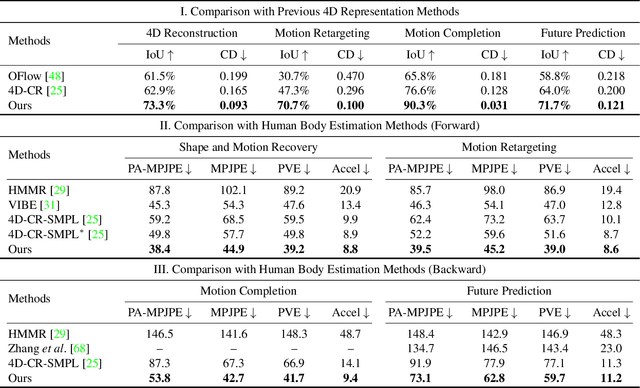
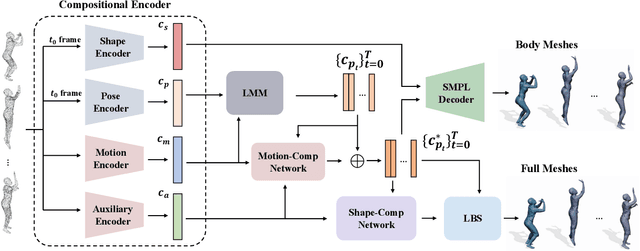
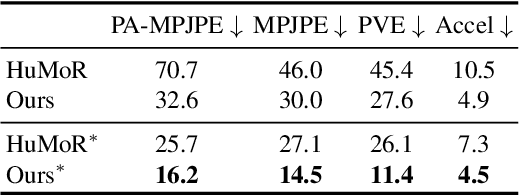
Despite the impressive results achieved by deep learning based 3D reconstruction, the techniques of directly learning to model the 4D human captures with detailed geometry have been less studied. This work presents a novel framework that can effectively learn a compact and compositional representation for dynamic human by exploiting the human body prior from the widely-used SMPL parametric model. Particularly, our representation, named H4D, represents dynamic 3D human over a temporal span into the latent spaces encoding shape, initial pose, motion and auxiliary information. A simple yet effective linear motion model is proposed to provide a rough and regularized motion estimation, followed by per-frame compensation for pose and geometry details with the residual encoded in the auxiliary code. Technically, we introduce novel GRU-based architectures to facilitate learning and improve the representation capability. Extensive experiments demonstrate our method is not only efficacy in recovering dynamic human with accurate motion and detailed geometry, but also amenable to various 4D human related tasks, including motion retargeting, motion completion and future prediction.
Compositional Scene Representation Learning via Reconstruction: A Survey
Feb 15, 2022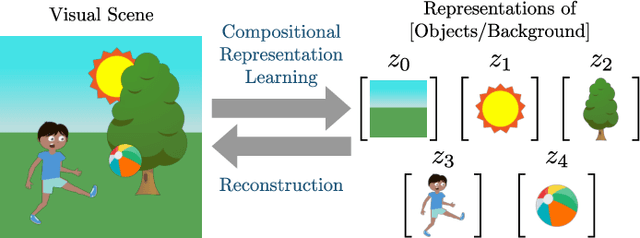

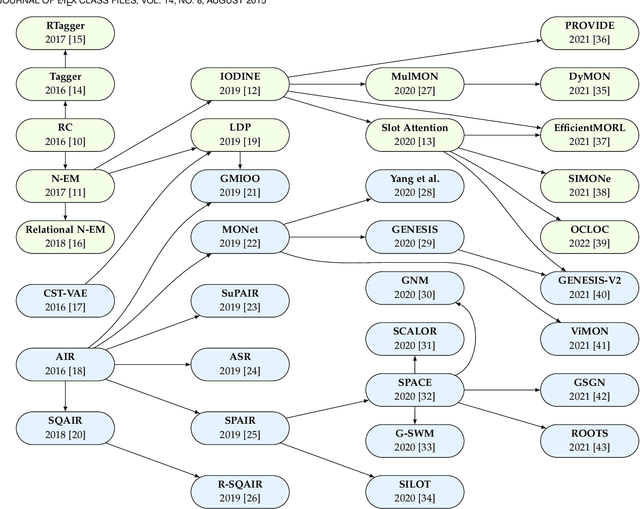
Visual scene representation learning is an important research problem in the field of computer vision. The performance on vision tasks could be improved if more suitable representations are learned for visual scenes. Complex visual scenes are the composition of relatively simple visual concepts, and have the property of combinatorial explosion. Compared with directly representing the entire visual scene, extracting compositional scene representations can better cope with the diverse combination of background and objects. Because compositional scene representations abstract the concept of objects, performing visual scene analysis and understanding based on these representations could be easier and more interpretable. Moreover, learning compositional scene representations via reconstruction can greatly reduce the need for training data annotations. Therefore, compositional scene representation learning via reconstruction has important research significance. In this survey, we first discuss representative methods that either learn from a single viewpoint or multiple viewpoints without object-level supervision, then the applications of compositional scene representations, and finally the future directions on this topic.
Benchmarking Chinese Text Recognition: Datasets, Baselines, and an Empirical Study
Dec 30, 2021


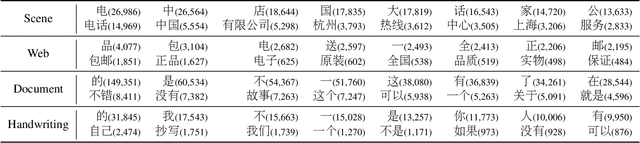
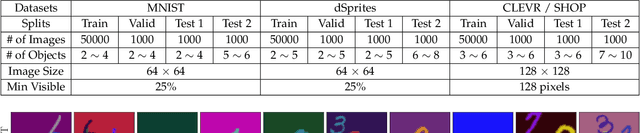
The flourishing blossom of deep learning has witnessed the rapid development of text recognition in recent years. However, the existing text recognition methods are mainly for English texts, whereas ignoring the pivotal role of Chinese texts. As another widely-spoken language, Chinese text recognition in all ways has extensive application markets. Based on our observations, we attribute the scarce attention on Chinese text recognition to the lack of reasonable dataset construction standards, unified evaluation methods, and results of the existing baselines. To fill this gap, we manually collect Chinese text datasets from publicly available competitions, projects, and papers, then divide them into four categories including scene, web, document, and handwriting datasets. Furthermore, we evaluate a series of representative text recognition methods on these datasets with unified evaluation methods to provide experimental results. By analyzing the experimental results, we surprisingly observe that state-of-the-art baselines for recognizing English texts cannot perform well on Chinese scenarios. We consider that there still remain numerous challenges under exploration due to the characteristics of Chinese texts, which are quite different from English texts. The code and datasets are made publicly available at https://github.com/FudanVI/benchmarking-chinese-text-recognition.
The Devil is in the Task: Exploiting Reciprocal Appearance-Localization Features for Monocular 3D Object Detection
Dec 28, 2021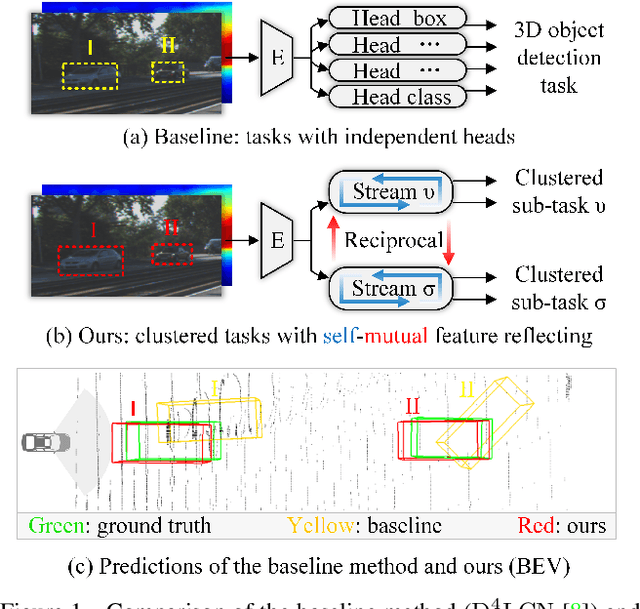
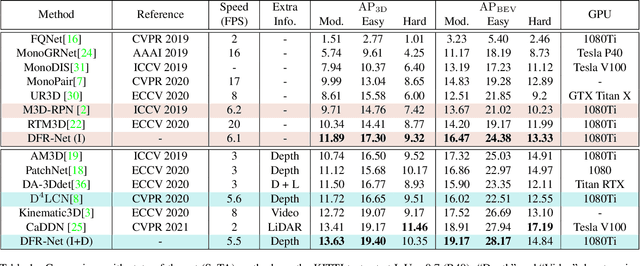
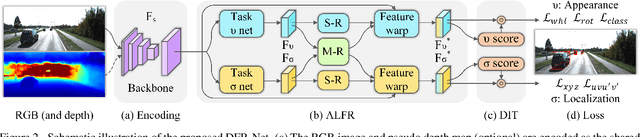
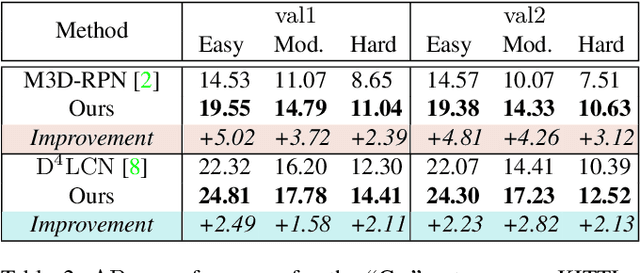
Low-cost monocular 3D object detection plays a fundamental role in autonomous driving, whereas its accuracy is still far from satisfactory. In this paper, we dig into the 3D object detection task and reformulate it as the sub-tasks of object localization and appearance perception, which benefits to a deep excavation of reciprocal information underlying the entire task. We introduce a Dynamic Feature Reflecting Network, named DFR-Net, which contains two novel standalone modules: (i) the Appearance-Localization Feature Reflecting module (ALFR) that first separates taskspecific features and then self-mutually reflects the reciprocal features; (ii) the Dynamic Intra-Trading module (DIT) that adaptively realigns the training processes of various sub-tasks via a self-learning manner. Extensive experiments on the challenging KITTI dataset demonstrate the effectiveness and generalization of DFR-Net. We rank 1st among all the monocular 3D object detectors in the KITTI test set (till March 16th, 2021). The proposed method is also easy to be plug-and-play in many cutting-edge 3D detection frameworks at negligible cost to boost performance. The code will be made publicly available.
Text Gestalt: Stroke-Aware Scene Text Image Super-Resolution
Dec 13, 2021
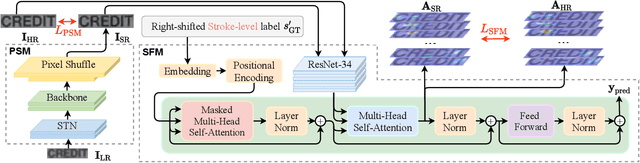
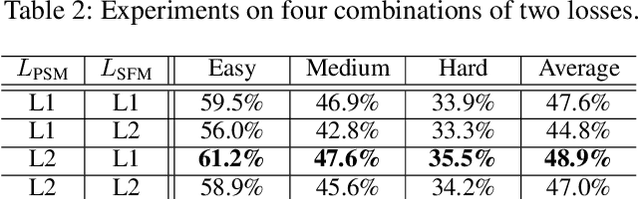
In the last decade, the blossom of deep learning has witnessed the rapid development of scene text recognition. However, the recognition of low-resolution scene text images remains a challenge. Even though some super-resolution methods have been proposed to tackle this problem, they usually treat text images as general images while ignoring the fact that the visual quality of strokes (the atomic unit of text) plays an essential role for text recognition. According to Gestalt Psychology, humans are capable of composing parts of details into the most similar objects guided by prior knowledge. Likewise, when humans observe a low-resolution text image, they will inherently use partial stroke-level details to recover the appearance of holistic characters. Inspired by Gestalt Psychology, we put forward a Stroke-Aware Scene Text Image Super-Resolution method containing a Stroke-Focused Module (SFM) to concentrate on stroke-level internal structures of characters in text images. Specifically, we attempt to design rules for decomposing English characters and digits at stroke-level, then pre-train a text recognizer to provide stroke-level attention maps as positional clues with the purpose of controlling the consistency between the generated super-resolution image and high-resolution ground truth. The extensive experimental results validate that the proposed method can indeed generate more distinguishable images on TextZoom and manually constructed Chinese character dataset Degraded-IC13. Furthermore, since the proposed SFM is only used to provide stroke-level guidance when training, it will not bring any time overhead during the test phase. Code is available at https://github.com/FudanVI/FudanOCR/tree/main/text-gestalt.
Unsupervised Learning of Compositional Scene Representations from Multiple Unspecified Viewpoints
Dec 12, 2021
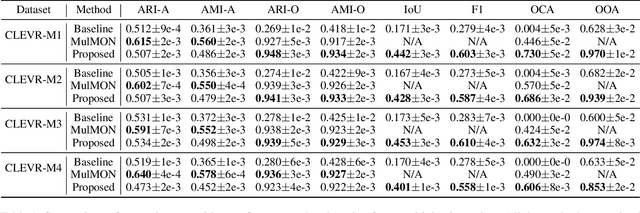
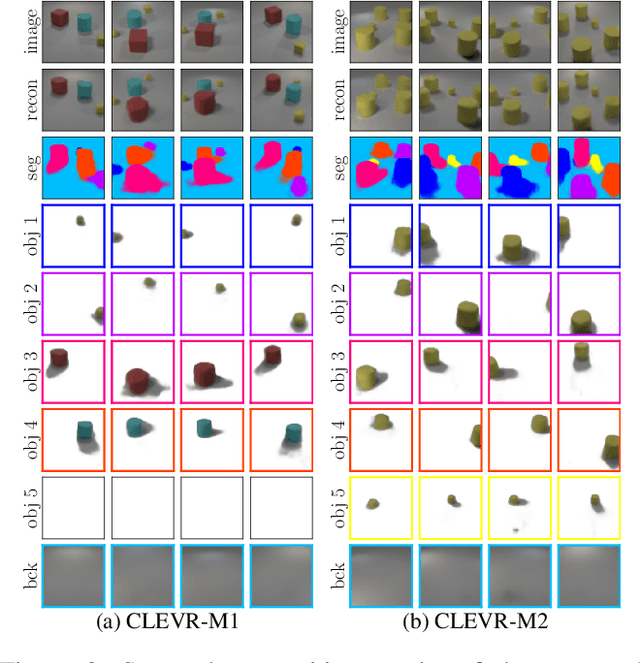
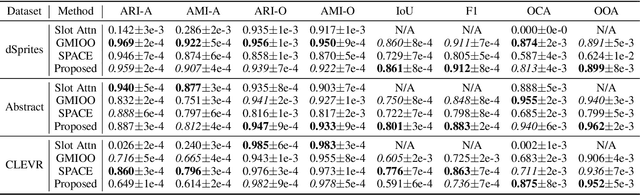
Visual scenes are extremely rich in diversity, not only because there are infinite combinations of objects and background, but also because the observations of the same scene may vary greatly with the change of viewpoints. When observing a visual scene that contains multiple objects from multiple viewpoints, humans are able to perceive the scene in a compositional way from each viewpoint, while achieving the so-called "object constancy" across different viewpoints, even though the exact viewpoints are untold. This ability is essential for humans to identify the same object while moving and to learn from vision efficiently. It is intriguing to design models that have the similar ability. In this paper, we consider a novel problem of learning compositional scene representations from multiple unspecified viewpoints without using any supervision, and propose a deep generative model which separates latent representations into a viewpoint-independent part and a viewpoint-dependent part to solve this problem. To infer latent representations, the information contained in different viewpoints is iteratively integrated by neural networks. Experiments on several specifically designed synthetic datasets have shown that the proposed method is able to effectively learn from multiple unspecified viewpoints.
SGM3D: Stereo Guided Monocular 3D Object Detection
Dec 03, 2021
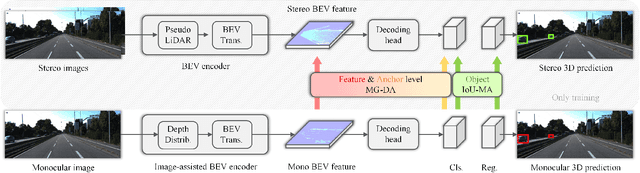
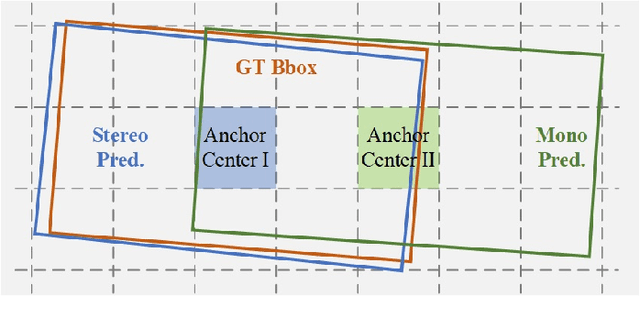

Monocular 3D object detection is a critical yet challenging task for autonomous driving, due to the lack of accurate depth information captured by LiDAR sensors. In this paper, we propose a stereo-guided monocular 3D object detection network, termed SGM3D, which leverages robust 3D features extracted from stereo images to enhance the features learned from the monocular image. We innovatively investigate a multi-granularity domain adaptation module (MG-DA) to exploit the network's ability so as to generate stereo-mimic features only based on the monocular cues. The coarse BEV feature-level, as well as the fine anchor-level domain adaptation, are leveraged to guide the monocular branch. We present an IoU matching-based alignment module (IoU-MA) for object-level domain adaptation between the stereo and monocular predictions to alleviate the mismatches in previous stages. We conduct extensive experiments on the most challenging KITTI and Lyft datasets and achieve new state-of-the-art performance. Furthermore, our method can be integrated into many other monocular approaches to boost performance without introducing any extra computational cost.