 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-wise Distribution Alignment Guided Style Prompt Tuning for Source-free Cross-domain Few-shot Learning
Nov 15, 2024



Existing cross-domain few-shot learning (CDFSL) methods, which develop source-domain training strategies to enhance model transferability, face challenges with large-scale pre-trained models (LMs) due to inaccessible source data and training strategies. Moreover, fine-tuning LMs for CDFSL demands substantial computational resources, limiting practicality. This paper addresses the source-free CDFSL (SF-CDFSL) problem, tackling few-shot learning (FSL) in the target domain using only pre-trained models and a few target samples without source data or strategies. To overcome the challenge of inaccessible source data, this paper introduces Step-wise Distribution Alignment Guided Style Prompt Tuning (StepSPT), which implicitly narrows domain gaps through prediction distribution optimization. StepSPT proposes a style prompt to align target samples with the desired distribution and adopts a dual-phase optimization process. In the external process, a step-wise distribution alignment strategy factorizes prediction distribution optimization into a multi-step alignment problem to tune the style prompt. In the internal process, the classifier is updated using standard cross-entropy loss. Evaluations on five datasets demonstrate that StepSPT outperforms existing prompt tuning-based methods and SOTAs. Ablation studies further verify its effectiveness. Code will be made publicly available at \url{https://github.com/xuhuali-mxj/StepSPT}.
Enhancing Information Maximization with Distance-Aware Contrastive Learning for Source-Free Cross-Domain Few-Shot Learning
Mar 04, 2024



Existing Cross-Domain Few-Shot Learning (CDFSL) methods require access to source domain data to train a model in the pre-training phase. However, due to increasing concerns about data privacy and the desire to reduce data transmission and training costs, it is necessary to develop a CDFSL solution without accessing source data. For this reason, this paper explores a Source-Free CDFSL (SF-CDFSL) problem, in which CDFSL is addressed through the use of existing pretrained models instead of training a model with source data, avoiding accessing source data. This paper proposes an Enhanced Information Maximization with Distance-Aware Contrastive Learning (IM-DCL) method to address these challenges. Firstly, we introduce the transductive mechanism for learning the query set. Secondly, information maximization (IM) is explored to map target samples into both individual certainty and global diversity predictions, helping the source model better fit the target data distribution. However, IM fails to learn the decision boundary of the target task. This motivates us to introduce a novel approach called Distance-Aware Contrastive Learning (DCL), in which we consider the entire feature set as both positive and negative sets, akin to Schrodinger's concept of a dual state. Instead of a rigid separation between positive and negative sets, we employ a weighted distance calculation among features to establish a soft classification of the positive and negative sets for the entire feature set. Furthermore, we address issues related to IM by incorporating contrastive constraints between object features and their corresponding positive and negative sets. Evaluations of the 4 datasets in the BSCD-FSL benchmark indicate that the proposed IM-DCL, without accessing the source domain, demonstrates superiority over existing methods, especially in the distant domain task.
Deep Learning for Cross-Domain Few-Shot Visual Recognition: A Survey
Mar 15, 2023



Deep learning has been highly successful in computer vision with large amounts of labeled data, but struggles with limited labeled training data. To address this, Few-shot learning (FSL) is proposed, but it assumes that all samples (including source and target task data, where target tasks are performed with prior knowledge from source ones) are from the same domain, which is a stringent assumption in the real world. To alleviate this limitation, Cross-domain few-shot learning (CDFSL) has gained attention as it allows source and target data from different domains and label spaces. This paper provides a comprehensive review of CDFSL at the first time, which has received far less attention than FSL due to its unique setup and difficulties. We expect this paper to serve as both a position paper and a tutorial for those doing research in CDFSL. This review first introduces the definition of CDFSL and the issues involved, followed by the core scientific question and challenge. A comprehensive review of validated CDFSL approaches from the existing literature is then presented, along with their detailed descriptions based on a rigorous taxonomy. Furthermore, this paper outlines and discusses several promising directions of CDFSL that deserve further scientific investigation, covering aspects of problem setups, applications and theories.
Cross-Domain Few-Shot Classification via Inter-Source Stylization
Aug 17, 2022
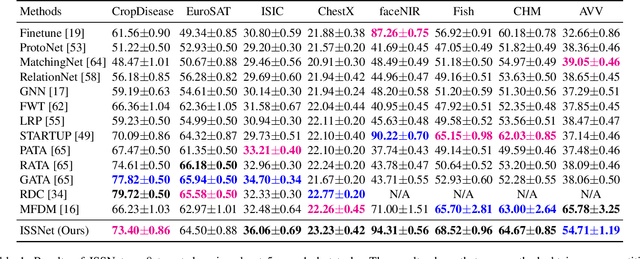
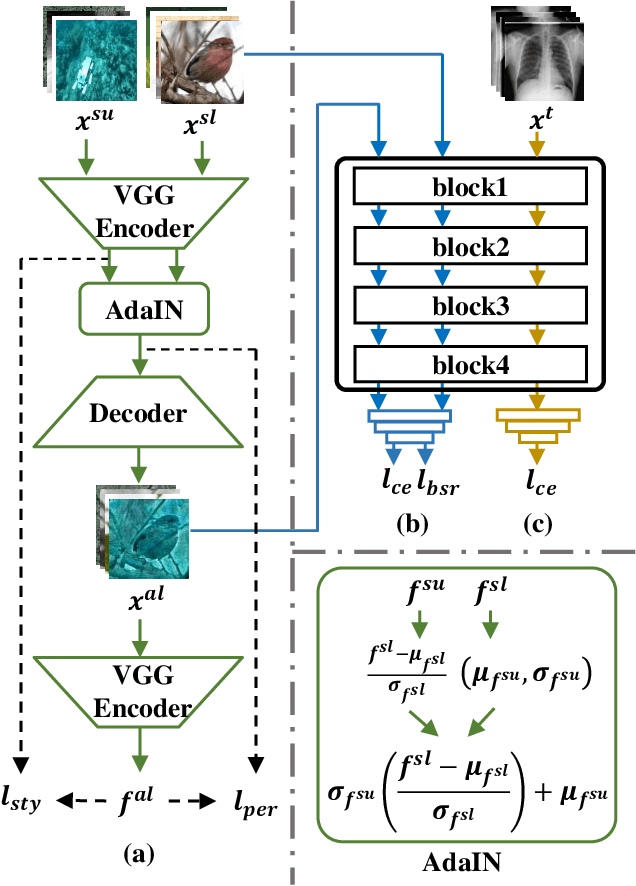
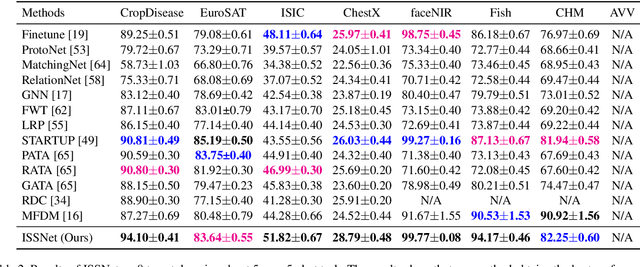
Cross-Domain Few Shot Classification (CDFSC) leverages prior knowledge learned from a supervised auxiliary dataset to solve a target task with limited supervised information available, where the auxiliary and target datasets come from the different domains. It is challenging due to the domain shift between these datasets. Inspired by Multisource Domain Adaptation (MDA), the recent works introduce the multiple domains to improve the performance. However, they, on the one hand, evaluate only on the benchmark with natural images, and on the other hand, they need many annotations even in the source domains can be costly. To address the above mentioned issues, this paper explore a new Multisource CDFSC setting (MCDFSC) where only one source domain is fully labeled while the rest source domains remain unlabeled. These sources are from different fileds, means they are not only natural images. Considering the inductive bias of CNNs, this paper proposed Inter-Source stylization network (ISSNet) for this new MCDFSC setting. It transfers the styles of unlabeled sources to labeled source, which expands the distribution of labeled source and further improves the model generalization ability. Experiments on 8 target datasets demonstrate ISSNet effectively suppresses the performance degradation caused by different domains.
An Edge Information and Mask Shrinking Based Image Inpainting Approach
Jun 11, 2020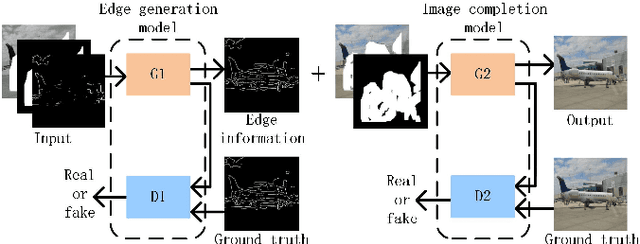
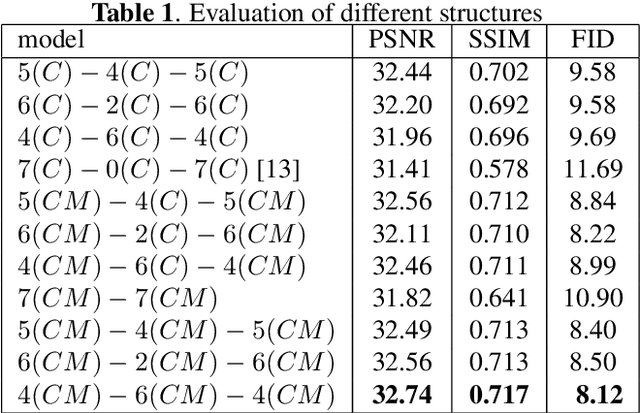
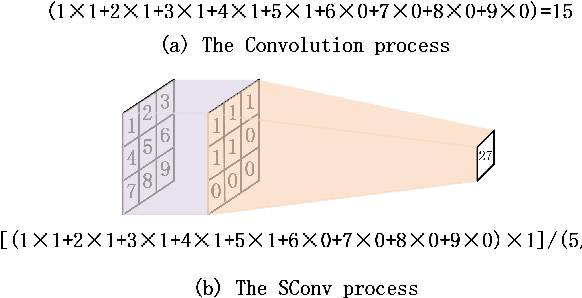
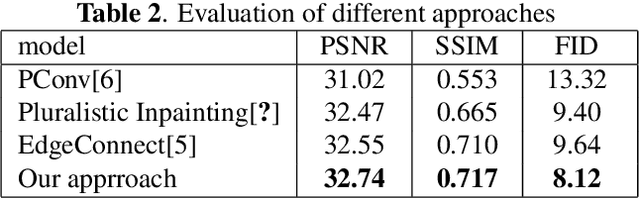
In the image inpainting task, the ability to repair both high-frequency and low-frequency information in the missing regions has a substantial influence on the quality of the restored image. However, existing inpainting methods usually fail to consider both high-frequency and low-frequency information simultaneously. To solve this problem, this paper proposes edge information and mask shrinking based image inpainting approach, which consists of two models. The first model is an edge generation model used to generate complete edge information from the damaged image, and the second model is an image completion model used to fix the missing regions with the generated edge information and the valid contents of the damaged image. The mask shrinking strategy is employed in the image completion model to track the areas to be repaired. The proposed approach is evaluated qualitatively and quantitatively on the dataset Places2. The result shows our approach outperforms state-of-the-art methods.
SNR-based teachers-student technique for speech enhancement
May 29, 2020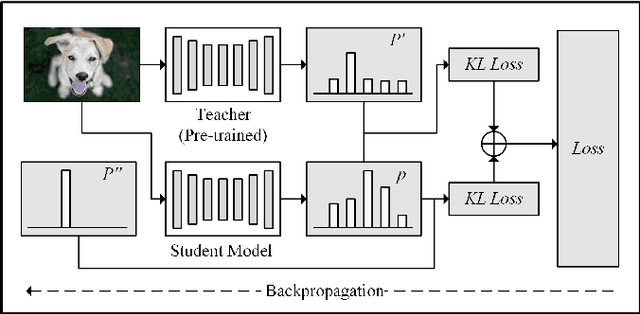
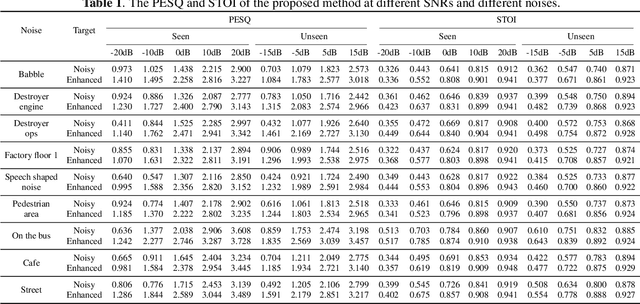
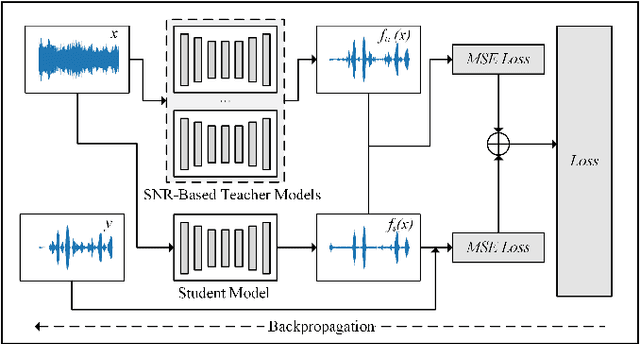
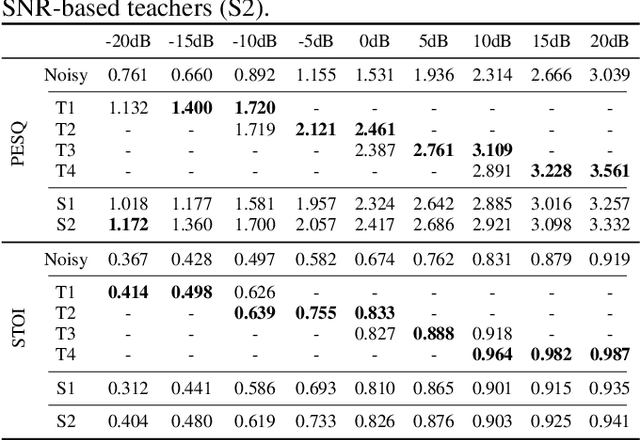
It is very challenging for speech enhancement methods to achieves robust performance under both high signal-to-noise ratio (SNR) and low SNR simultaneously. In this paper, we propose a method that integrates an SNR-based teachers-student technique and time-domain U-Net to deal with this problem. Specifically, this method consists of multiple teacher models and a student model. We first train the teacher models under multiple small-range SNRs that do not coincide with each other so that they can perform speech enhancement well within the specific SNR range. Then, we choose different teacher models to supervise the training of the student model according to the SNR of the training data. Eventually, the student model can perform speech enhancement under both high SNR and low SNR. To evaluate the proposed method, we constructed a dataset with an SNR ranging from -20dB to 20dB based on the public dataset. We experimentally analyzed the effectiveness of the SNR-based teachers-student technique and compared the proposed method with several state-of-the-art methods.