 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVP-Human Dataset for 3D Human Avatar Reconstruction from Unconstrained Frames
Apr 24, 2022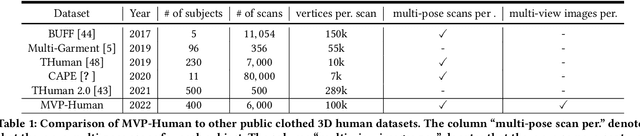
In this paper, we consider a novel problem of reconstructing a 3D human avatar from multiple unconstrained frames, independent of assumptions on camera calibration, capture space, and constrained actions. The problem should be addressed by a framework that takes multiple unconstrained images as inputs, and generates a shape-with-skinning avatar in the canonical space, finished in one feed-forward pass. To this end, we present 3D Avatar Reconstruction in the wild (ARwild), which first reconstructs the implicit skinning fields in a multi-level manner, by which the image features from multiple images are aligned and integrated to estimate a pixel-aligned implicit function that represents the clothed shape. To enable the training and testing of the new framework, we contribute a large-scale dataset, MVP-Human (Multi-View and multi-Pose 3D Human), which contains 400 subjects, each of which has 15 scans in different poses and 8-view images for each pose, providing 6,000 3D scans and 48,000 images in total. Overall, benefits from the specific network architecture and the diverse data, the trained model enables 3D avatar reconstruction from unconstrained frames and achieves state-of-the-art performance.
A Context-Integrated Transformer-Based Neural Network for Auction Design
Jan 29, 2022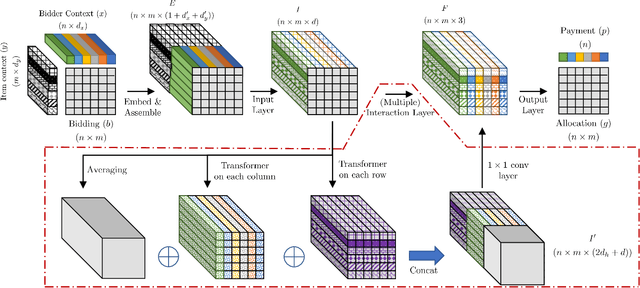
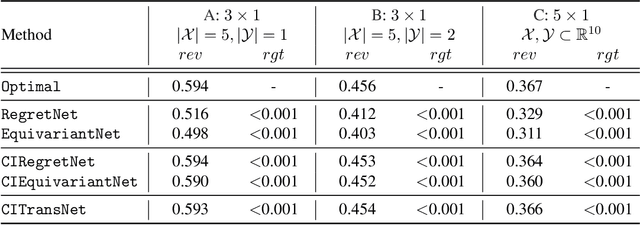
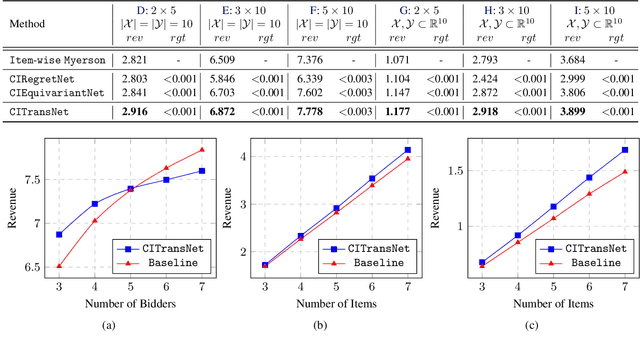
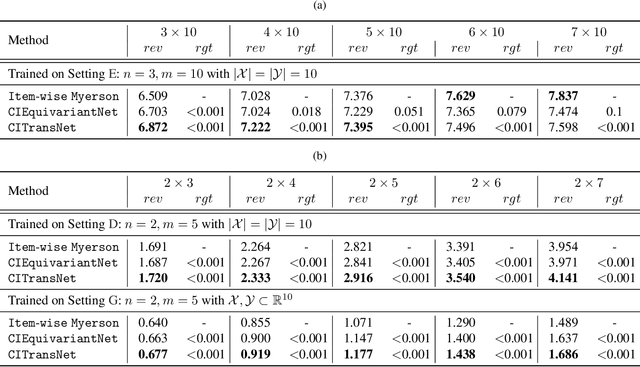
One of the central problems in auction design is developing an incentive-compatible mechanism that maximizes the auctioneer's expected revenue. While theoretical approaches have encountered bottlenecks in multi-item auctions, recently, there has been much progress on finding the optimal mechanism through deep learning. However, these works either focus on a fixed set of bidders and items, or restrict the auction to be symmetric. In this work, we overcome such limitations by factoring \emph{public} contextual information of bidders and items into the auction learning framework. We propose $\mathtt{CITransNet}$, a context-integrated transformer-based neural network for optimal auction design, which maintains permutation-equivariance over bids and contexts while being able to find asymmetric solutions. We show by extensive experiments that $\mathtt{CITransNet}$ can recover the known optimal solutions in single-item settings, outperform strong baselines in multi-item auctions, and generalize well to cases other than those in training.
Multi-initialization Optimization Network for Accurate 3D Human Pose and Shape Estimation
Dec 24, 2021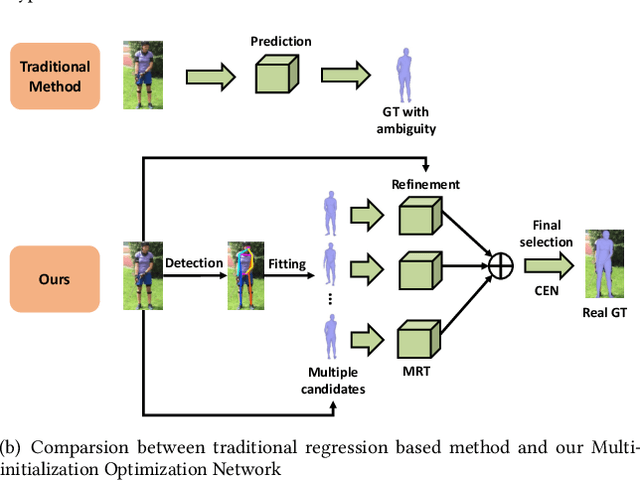
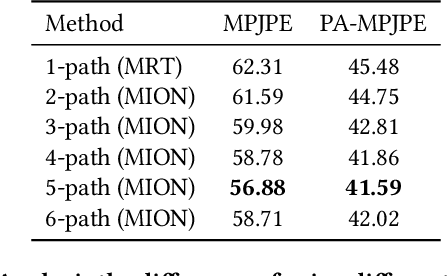

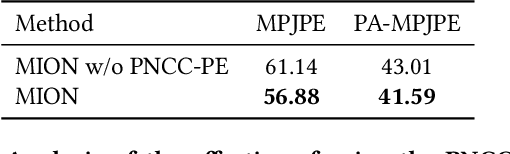
3D human pose and shape recovery from a monocular RGB image is a challenging task. Existing learning based methods highly depend on weak supervision signals, e.g. 2D and 3D joint location, due to the lack of in-the-wild paired 3D supervision. However, considering the 2D-to-3D ambiguities existed in these weak supervision labels, the network is easy to get stuck in local optima when trained with such labels. In this paper, we reduce the ambituity by optimizing multiple initializations. Specifically, we propose a three-stage framework named Multi-Initialization Optimization Network (MION). In the first stage, we strategically select different coarse 3D reconstruction candidates which are compatible with the 2D keypoints of input sample. Each coarse reconstruction can be regarded as an initialization leads to one optimization branch. In the second stage, we design a mesh refinement transformer (MRT) to respectively refine each coarse reconstruction result via a self-attention mechanism. Finally, a Consistency Estimation Network (CEN) is proposed to find the best result from mutiple candidates by evaluating if the visual evidence in RGB image matches a given 3D reconstruction. Experiments demonstrate that our Multi-Initialization Optimization Network outperforms existing 3D mesh based methods on multiple public benchmarks.
A Game-Theoretic Analysis of the Empirical Revenue Maximization Algorithm with Endogenous Sampling
Oct 12, 2020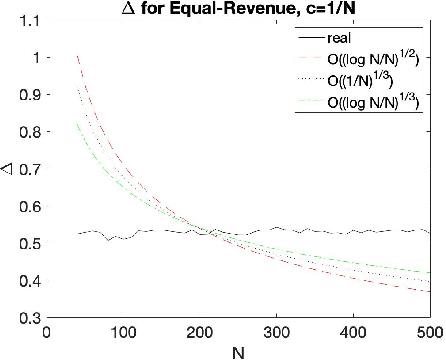
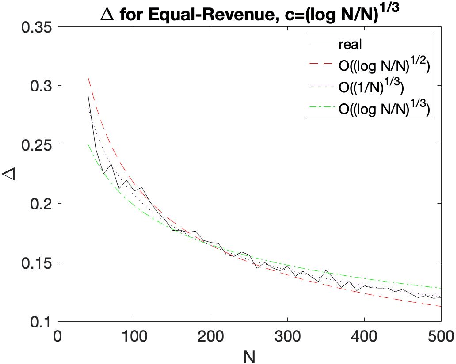
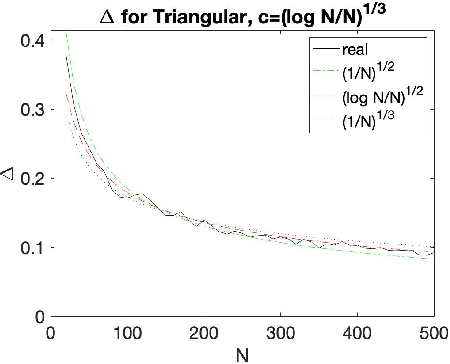
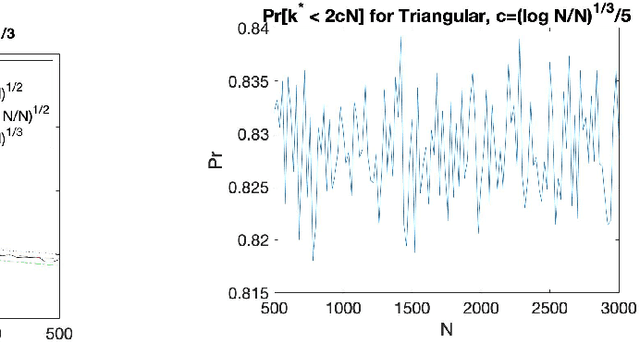
The Empirical Revenue Maximization (ERM) is one of the most important price learning algorithms in auction design: as the literature shows it can learn approximately optimal reserve prices for revenue-maximizing auctioneers in both repeated auctions and uniform-price auctions. However, in these applications the agents who provide inputs to ERM have incentives to manipulate the inputs to lower the outputted price. We generalize the definition of an incentive-awareness measure proposed by Lavi et al (2019), to quantify the reduction of ERM's outputted price due to a change of $m\ge 1$ out of $N$ input samples, and provide specific convergence rates of this measure to zero as $N$ goes to infinity for different types of input distributions. By adopting this measure, we construct an efficient, approximately incentive-compatible, and revenue-optimal learning algorithm using ERM in repeated auctions against non-myopic bidders, and show approximate group incentive-compatibility in uniform-price auctions.
Distilling Black-Box Travel Mode Choice Model for Behavioral Interpretation
Oct 30, 2019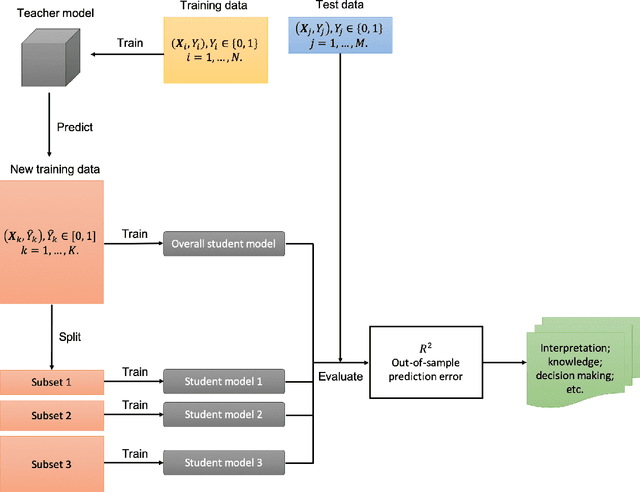

Machine learning has proved to be very successful for making predictions in travel behavior modeling. However, most machine-learning models have complex model structures and offer little or no explanation as to how they arrive at these predictions. Interpretations about travel behavior models are essential for decision makers to understand travelers' preferences and plan policy interventions accordingly. Therefore, this paper proposes to apply and extend the model distillation approach, a model-agnostic machine-learning interpretation method, to explain how a black-box travel mode choice model makes predictions for the entire population and subpopulations of interest. Model distillation aims at compressing knowledge from a complex model (teacher) into an understandable and interpretable model (student). In particular, the paper integrates model distillation with market segmentation to generate more insights by accounting for heterogeneity. Furthermore, the paper provides a comprehensive comparison of student models with the benchmark model (decision tree) and the teacher model (gradient boosting trees) to quantify the fidelity and accuracy of the students' interpretations.
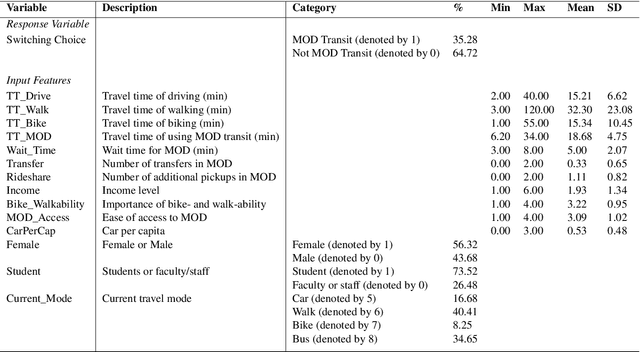
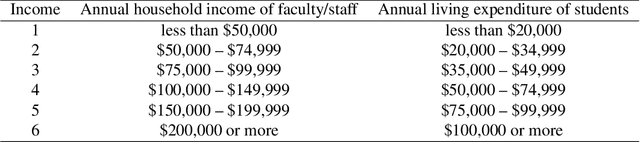
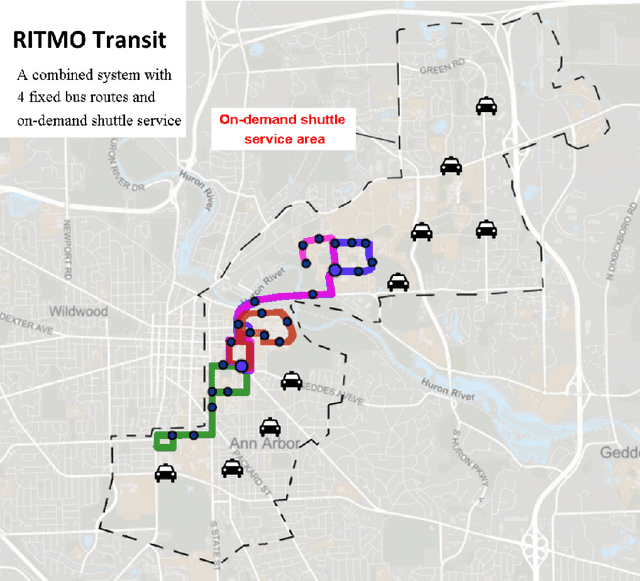
Modeling Heterogeneity in Mode-Switching Behavior Under a Mobility-on-Demand Transit System: An Interpretable Machine Learning Approach
Feb 08, 2019
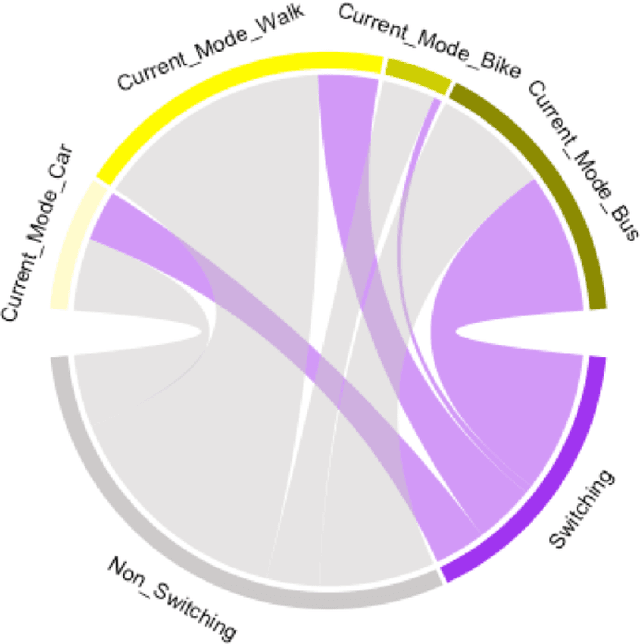
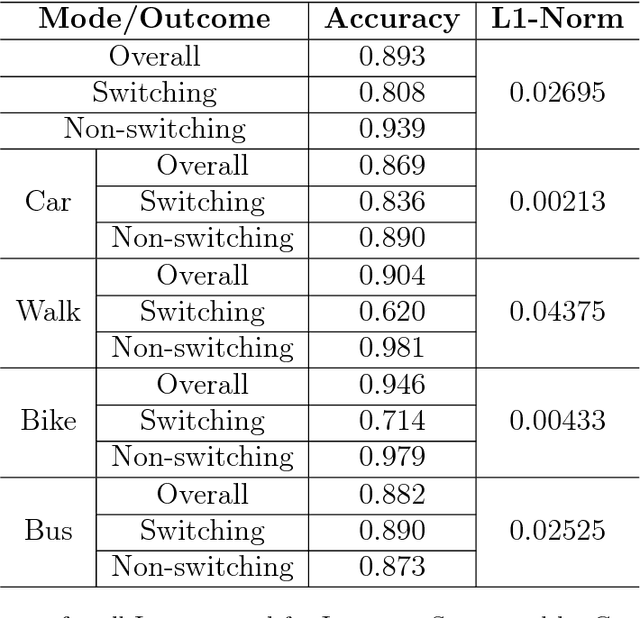
Recent years have witnessed an increased focus on interpretability and the use of machine learning to inform policy analysis and decision making. This paper applies machine learning to examine travel behavior and, in particular, on modeling changes in travel modes when individuals are presented with a novel (on-demand) mobility option. It addresses the following question: Can machine learning be applied to model individual taste heterogeneity (preference heterogeneity for travel modes and response heterogeneity to travel attributes) in travel mode choice? This paper first develops a high-accuracy classifier to predict mode-switching behavior under a hypothetical Mobility-on-Demand Transit system (i.e., stated-preference data), which represents the case study underlying this research. We show that this classifier naturally captures individual heterogeneity available in the data. Moreover, the paper derives insights on heterogeneous switching behaviors through the generation of marginal effects and elasticities by current travel mode, partial dependence plots, and individual conditional expectation plots. The paper also proposes two new model-agnostic interpretation tools for machine learning, i.e., conditional partial dependence plots and conditional individual partial dependence plots, specifically designed to examine response heterogeneity. The results on the case study show that the machine-learning classifier, together with model-agnostic interpretation tools, provides valuable insights on travel mode switching behavior for different individuals and population segments. For example, the existing drivers are more sensitive to additional pickups than people using other travel modes, and current transit users are generally willing to share rides but reluctant to take any additional transfers.
Cost-Effective Incentive Allocation via Structured Counterfactual Inference
Feb 07, 2019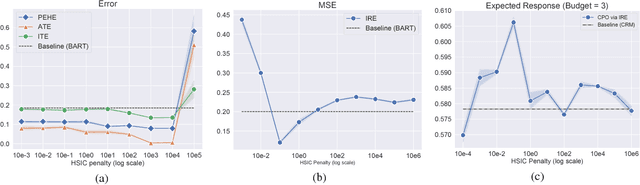
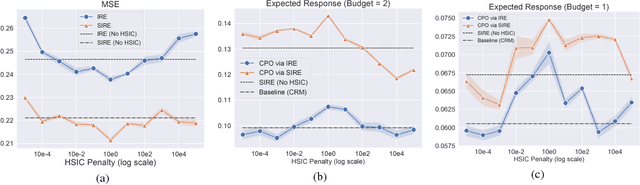
We address a practical problem ubiquitous in modern industry, in which a mediator tries to learn a policy for allocating strategic financial incentives for customers in a marketing campaign and observes only bandit feedback. In contrast to traditional policy optimization frameworks, we rely on a specific assumption for the reward structure and we incorporate budget constraints. We develop a new two-step method for solving this constrained counterfactual policy optimization problem. First, we cast the reward estimation problem as a domain adaptation problem with supplementary structure. Subsequently, the estimators are used for optimizing the policy with constraints. We establish theoretical error bounds for our estimation procedure and we empirically show that the approach leads to significant improvement on both synthetic and real datasets.
A Policy Gradient Method with Variance Reduction for Uplift Modeling
Nov 26, 2018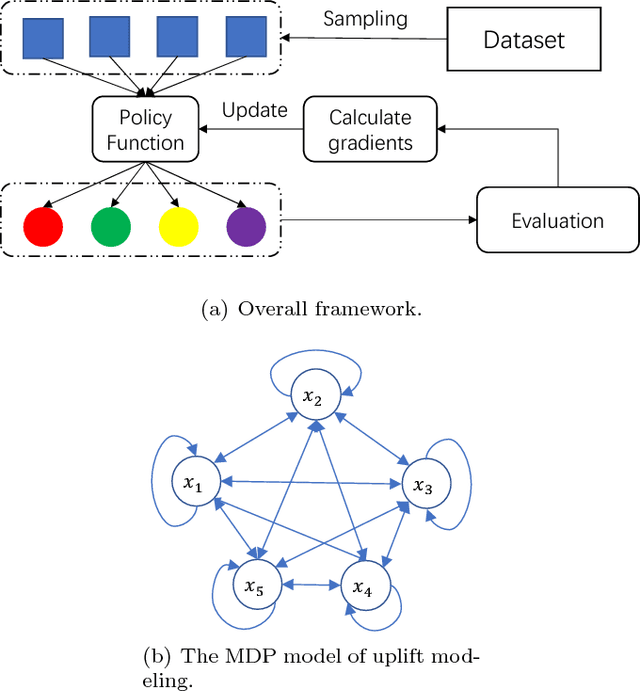

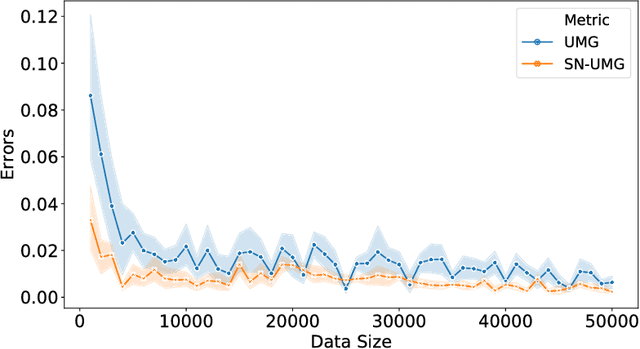
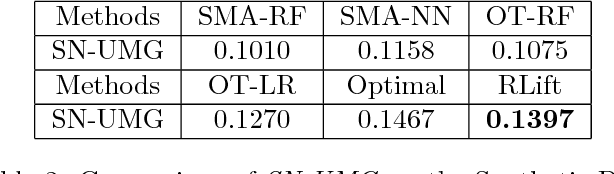
Uplift modeling aims to directly model the incremental impact of a treatment on an individual response. It has been widely and successfully used in healthcare analytics and business operations, where one tries to measure the net effect of a new medicine on patients or to understand the impact of a marketing campaign on company revenue. In this work, we address the problem from a new angle and reformulate it as a Markov Decision Process (MDP). This new formulation allows us to handle the lack of explicit labels, to deal with any number of actions (in comparison to the normal two action uplift modeling), and to apply it to applications with responses of general types, which is a challenging task for previous methods. Furthermore, we also design an unbiased metric for more accurate offline evaluation of uplift effects, set up a better reward function for the policy gradient method to solve the problem and adopt some action-based baselines to reduce variance. We conducted extensive experiments on both a synthetic dataset and real-world scenarios, and showed that our method can achieve significant improvement over previous methods.
Modeling Stated Preference for Mobility-on-Demand Transit: A Comparison of Machine Learning and Logit Models
Nov 04, 2018

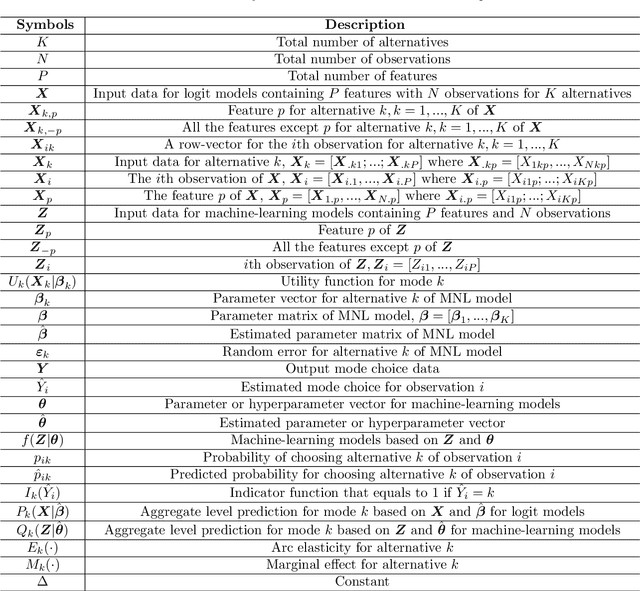
Logit models are usually applied when studying individual travel behavior, i.e., to predict travel mode choice and to gain behavioral insights on traveler preferences. Recently, some studies have applied machine learning to model travel mode choice and reported higher out-of-sample prediction accuracy than conventional logit models (e.g., multinomial logit). However, there has not been a comprehensive comparison between logit models and machine learning that covers both prediction and behavioral analysis. This paper aims at addressing this gap by examining the key differences in model development, evaluation, and behavioral interpretation between logit and machine-learning models for travel-mode choice modeling. To complement the theoretical discussions, we also empirically evaluated the two approaches on stated-preference survey data for a new type of transit system integrating high-frequency fixed routes and micro-transit. The results show that machine learning can produce significantly higher predictive accuracy than logit models and are better at capturing the nonlinear relationships between trip attributes and mode-choice outcomes. On the other hand, compared to the multinomial logit model, the best-performing machine-learning model, the random forest model, produces less reasonable behavioral outputs (i.e. marginal effects and elasticities) when they were computed from a standard approach. By introducing some behavioral constraints into the computation of behavioral outputs from a random forest model, however, we obtained better results that are somewhat comparable with the multinomial logit model. We believe that there is great potential in merging ideas from machine learning and conventional statistical methods to develop refined models for travel-behavior research and suggest some possible research directions.
Latent Dirichlet Allocation for Internet Price War
Aug 23, 2018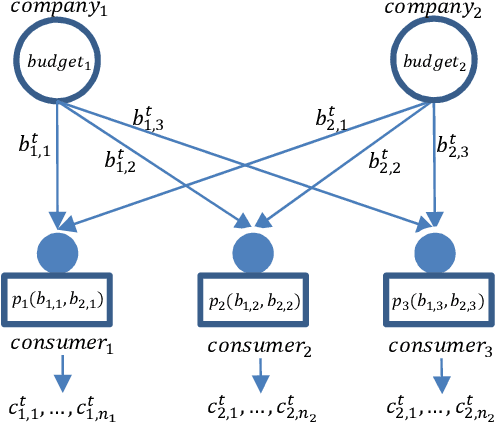
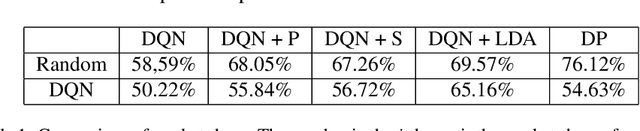
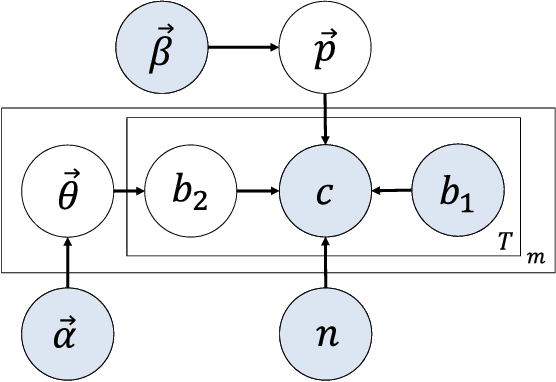

Internet market makers are always facing intense competitive environment, where personalized price reductions or discounted coupons are provided for attracting more customers. Participants in such a price war scenario have to invest a lot to catch up with other competitors. However, such a huge cost of money may not always lead to an improvement of market share. This is mainly due to a lack of information about others' strategies or customers' willingness when participants develop their strategies. In order to obtain this hidden information through observable data, we study the relationship between companies and customers in the Internet price war. Theoretically, we provide a formalization of the problem as a stochastic game with imperfect and incomplete information. Then we develop a variant of Latent Dirichlet Allocation (LDA) to infer latent variables under the current market environment, which represents the preferences of customers and strategies of competitors. To our best knowledge, it is the first time that LDA is applied to game scenario. We conduct simulated experiments where our LDA model exhibits a significant improvement on finding strategies in the Internet price war by including all available market information of the market maker's competitors. And the model is applied to an open dataset for real business. Through comparisons on the likelihood of prediction for users' behavior and distribution distance between inferred opponent's strategy and the real one, our model is shown to be able to provide a better understanding for the market environment. Our work marks a successful learning method to infer latent information in the environment of price war by the LDA modeling, and sets an example for related competitive applications to follow.