 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Tensor Product-Based Neural Network for Solving Partial Differential Equations
May 28, 2026This paper presents the Tensor Product Network (TPNet), a novel neural architecture for efficient and accurate function approximation and PDE solving. The core of the proposal involves constructing the solution explicitly as a linear combination of basis functions integrated into the network, with coefficients determined by a direct least-squares solve, thereby bypassing traditional gradient-based training. The key methodological contribution include: (1) an efficient tensor-product scheme that generates multi-dimensional basis functions from combinations of two sets of subnetwork outputs, significantly reducing model complexity and parameter count while maintaining expressivity; (2) a block time-marching strategy to improve computational efficiency in long-time simulations; and (3) a linear reformulation strategy for handling nonlinear PDEs by treating known nonlinear terms as sources. TPNet achieves superior accuracy and shorter training times than conventional neural network solvers. This performance gain stems from its structured design and deterministic least-squares fitting, which contrast with the iterative, often computationally intensive optimization required by mainstream methods like Physics-Informed Neural Networks (PINNs).
Frontier: Towards Comprehensive and Accurate LLM Inference Simulation
May 20, 2026Modern LLM serving is no longer homogeneous or monolithic. Production systems now combine disaggregated execution, complex parallelism, runtime optimizations, and stateful workloads such as reasoning, agents, and RL rollouts. Simulation is attractive for exploring this growing design space, yet existing simulators lack the architectural completeness and decision-grade fidelity it demands. Their monolithic-replica abstractions are ill-suited to disaggregated serving, while average-case analytical proxies can distort SLA predictions and even reverse optimization conclusions. We present Frontier, a discrete-event simulator for modern LLM inference serving. Frontier features a disaggregated abstraction. It captures the structure and dynamics of modern serving systems by modeling co-location, Prefill-Decode Disaggregation (PDD), and Attention-FFN Disaggregation (AFD) with role-specific cluster workers, incorporating key runtime optimizations (e.g., CUDA Graphs, speculative decoding) within the scheduler-batch-engine loop, and supporting stateful requests for emerging workloads. It further provides accurate and generalizable predictions of computation, communication, and memory costs across diverse serving scenarios with complex workload compositions. On 16-H800 GPU testbed, Frontier achieves an average throughput error below 4%. Compared with state-of-the-art simulators, it reduces end-to-end latency error from 44.9% to 6.4% under co-location and from 51.7% to 2.6% under disaggregation. It scales to over 1K GPUs on commodity CPUs and enables new use cases such as SLA-dependent Pareto frontier exploration, heterogeneous disaggregated allocation, agentic reasoning scheduling validation, and RL post-training reconfiguration.
Minder: Faulty Machine Detection for Large-scale Distributed Model Training
Nov 04, 2024



Large-scale distributed model training requires simultaneous training on up to thousands of machines. Faulty machine detection is critical when an unexpected fault occurs in a machine. From our experience, a training task can encounter two faults per day on average, possibly leading to a halt for hours. To address the drawbacks of the time-consuming and labor-intensive manual scrutiny, we propose Minder, an automatic faulty machine detector for distributed training tasks. The key idea of Minder is to automatically and efficiently detect faulty distinctive monitoring metric patterns, which could last for a period before the entire training task comes to a halt. Minder has been deployed in our production environment for over one year, monitoring daily distributed training tasks where each involves up to thousands of machines. In our real-world fault detection scenarios, Minder can accurately and efficiently react to faults within 3.6 seconds on average, with a precision of 0.904 and F1-score of 0.893.
MMPDE-Net and Moving Sampling Physics-informed Neural Networks Based On Moving Mesh Method
Nov 14, 2023



In this work, we propose an end-to-end adaptive sampling neural network (MMPDE-Net) based on the moving mesh PDE method, which can adaptively generate new coordinates of sampling points by solving the moving mesh PDE. This model focuses on improving the efficiency of individual sampling points. Moreover, we have developed an iterative algorithm based on MMPDE-Net, which makes the sampling points more precise and controllable. Since MMPDE-Net is a framework independent of the deep learning solver, we combine it with PINN to propose MS-PINN and demonstrate its effectiveness by performing error analysis under the assumptions given in this paper. Meanwhile, we demonstrate the performance improvement of MS-PINN compared to PINN through numerical experiments on four typical examples to verify the effectiveness of our method.
On the uncertainty analysis of the data-enabled physics-informed neural network for solving neutron diffusion eigenvalue problem
Mar 17, 2023In practical engineering experiments, the data obtained through detectors are inevitably noisy. For the already proposed data-enabled physics-informed neural network (DEPINN) \citep{DEPINN}, we investigate the performance of DEPINN in calculating the neutron diffusion eigenvalue problem from several perspectives when the prior data contain different scales of noise. Further, in order to reduce the effect of noise and improve the utilization of the noisy prior data, we propose innovative interval loss functions and give some rigorous mathematical proofs. The robustness of DEPINN is examined on two typical benchmark problems through a large number of numerical results, and the effectiveness of the proposed interval loss function is demonstrated by comparison. This paper confirms the feasibility of the improved DEPINN for practical engineering applications in nuclear reactor physics.
Neural Networks Base on Power Method and Inverse Power Method for Solving Linear Eigenvalue Problems
Sep 28, 2022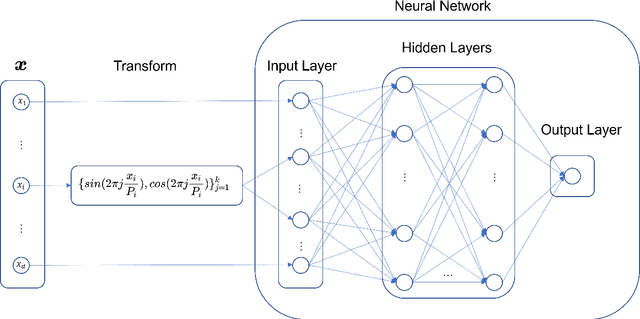
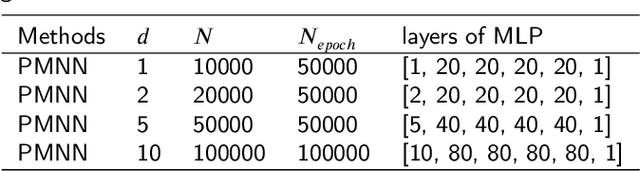
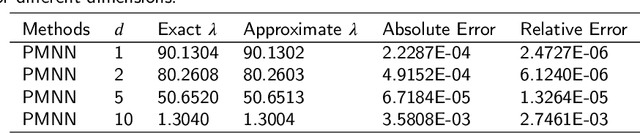
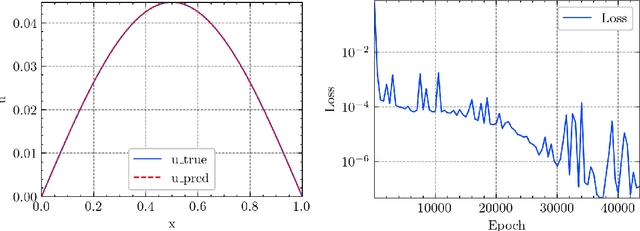
In this article, we propose three methods Power Method Neural Network (PMNN), Inverse Power Method Neural Networ (IPMNN) and Shifted Inverse Power Method Neural Network (SIPMNN) combined with power method, inverse power method and shifted inverse power method to solve eigenvalue problems with the dominant eigenvalue, the smallest eigenvalue and the smallest zero eigenvalue, respectively. The methods share similar spirits with traditional methods, but the differences are the differential operator realized by Automatic Differentiation (AD), the eigenfunction learned by the neural network and the iterations implemented by optimizing the specially defined loss function. We examine the applicability and accuracy of our methods in several numerical examples in high dimensions. Numerical results obtained by our methods for multidimensional problems show that our methods can provide accurate eigenvalue and eigenfunction approximations.