 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Speak: Using Self-talk to Generate Implicit Commonsense Knowledge for Response Generation
Oct 16, 2021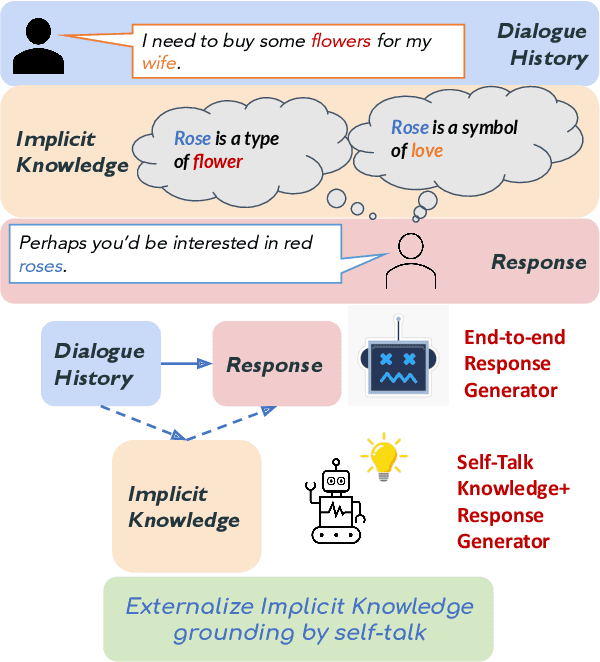
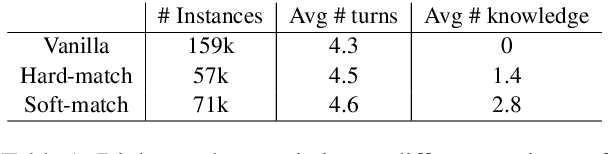
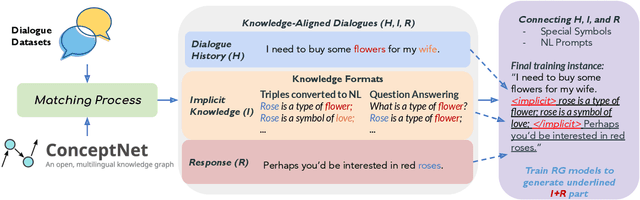

Implicit knowledge, such as common sense, is key to fluid human conversations. Current neural response generation (RG) models are trained end-to-end, omitting unstated implicit knowledge. In this paper, we present a self-talk approach that first generates the implicit commonsense knowledge and then generates response by referencing the externalized knowledge, all using one generative model. We analyze different choices to collect knowledge-aligned dialogues, represent implicit knowledge, and elicit knowledge and responses. We introduce three evaluation aspects: knowledge quality, knowledge-response connection, and response quality and perform extensive human evaluations. Our experimental results show that compared with end-to-end RG models, self-talk models that externalize the knowledge grounding process by explicitly generating implicit knowledge also produce responses that are more informative, specific, and follow common sense. We also find via human evaluation that self-talk models generate high-quality knowledge around 75% of the time. We hope that our findings encourage further work on different approaches to modeling implicit commonsense knowledge and training knowledgeable RG models.
A Good Prompt Is Worth Millions of Parameters? Low-resource Prompt-based Learning for Vision-Language Models
Oct 16, 2021
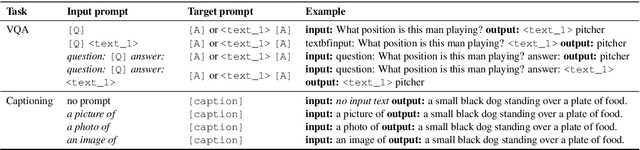
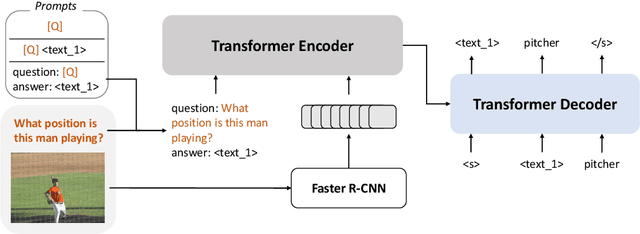
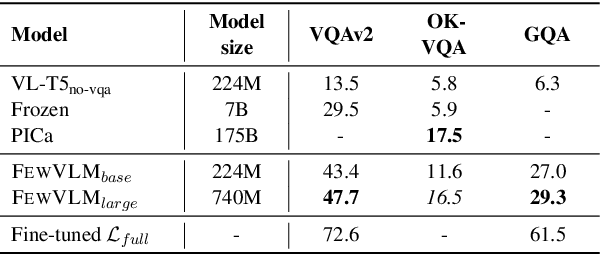
Large pretrained vision-language (VL) models can learn a new task with a handful of examples or generalize to a new task without fine-tuning. However, these gigantic VL models are hard to deploy for real-world applications due to their impractically huge model size and slow inference speed. In this work, we propose FewVLM, a few-shot prompt-based learner on vision-language tasks. We pretrain a sequence-to-sequence Transformer model with both prefix language modeling (PrefixLM) and masked language modeling (MaskedLM), and introduce simple prompts to improve zero-shot and few-shot performance on VQA and image captioning. Experimental results on five VQA and captioning datasets show that \method\xspace outperforms Frozen which is 31 times larger than ours by 18.2% point on zero-shot VQAv2 and achieves comparable results to a 246$\times$ larger model, PICa. We observe that (1) prompts significantly affect zero-shot performance but marginally affect few-shot performance, (2) MaskedLM helps few-shot VQA tasks while PrefixLM boosts captioning performance, and (3) performance significantly increases when training set size is small.
Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER
Oct 16, 2021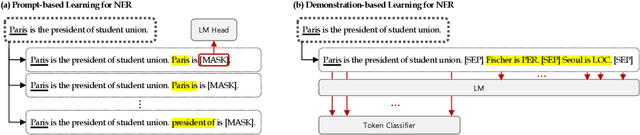
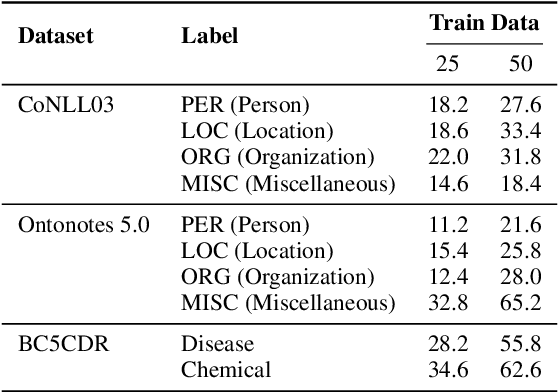

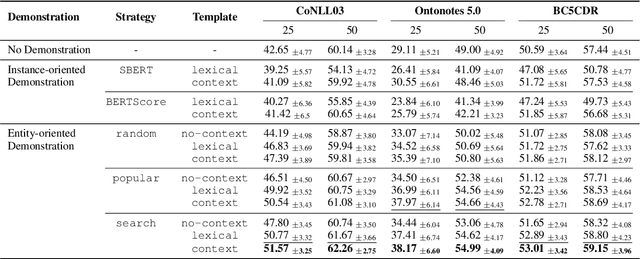
Recent advances in prompt-based learning have shown impressive results on few-shot text classification tasks by using cloze-style language prompts. There have been attempts on prompt-based learning for NER which use manually designed templates to predict entity types. However, these two-step methods may suffer from error propagation (from entity span detection), need to prompt for all possible text spans which is costly, and neglect the interdependency when predicting labels for different spans in a sentence. In this paper, we present a simple demonstration-based learning method for NER, which augments the prompt (learning context) with a few task demonstrations. Such demonstrations help the model learn the task better under low-resource settings and allow for span detection and classification over all tokens jointly. Here, we explore entity-oriented demonstration which selects an appropriate entity example per each entity type, and instance-oriented demonstration which retrieves a similar instance example. Through extensive experiments, we find empirically that showing entity example per each entity type, along with its example sentence, can improve the performance both in in-domain and cross-domain settings by 1-3 F1 score.
KG-FiD: Infusing Knowledge Graph in Fusion-in-Decoder for Open-Domain Question Answering
Oct 08, 2021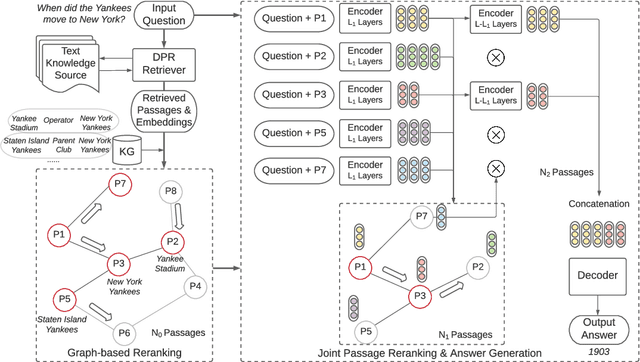
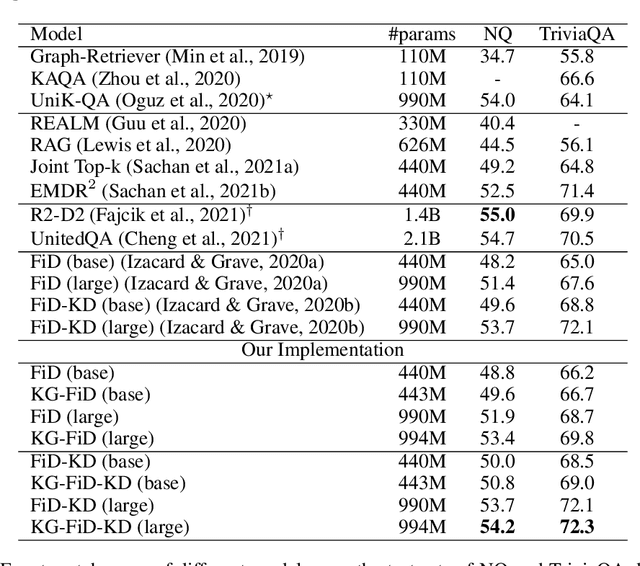
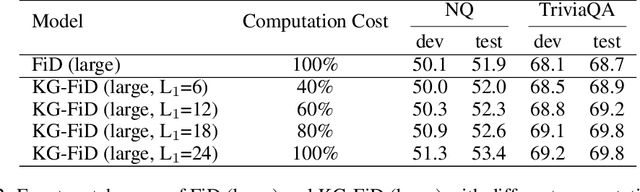
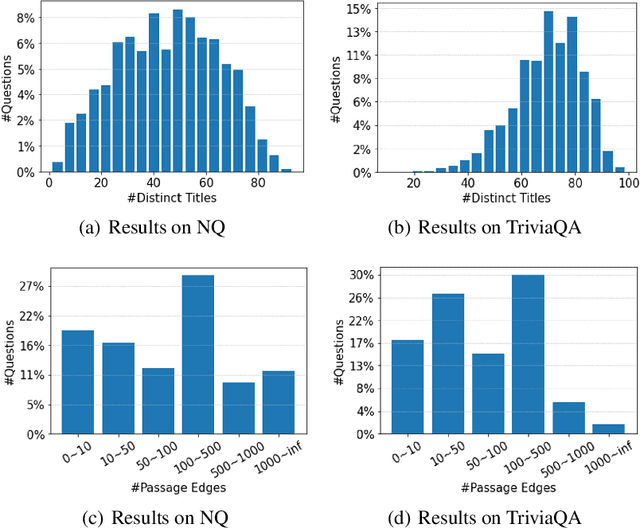
Current Open-Domain Question Answering (ODQA) model paradigm often contains a retrieving module and a reading module. Given an input question, the reading module predicts the answer from the relevant passages which are retrieved by the retriever. The recent proposed Fusion-in-Decoder (FiD), which is built on top of the pretrained generative model T5, achieves the state-of-the-art performance in the reading module. Although being effective, it remains constrained by inefficient attention on all retrieved passages which contain a lot of noise. In this work, we propose a novel method KG-FiD, which filters noisy passages by leveraging the structural relationship among the retrieved passages with a knowledge graph. We initiate the passage node embedding from the FiD encoder and then use graph neural network (GNN) to update the representation for reranking. To improve the efficiency, we build the GNN on top of the intermediate layer output of the FiD encoder and only pass a few top reranked passages into the higher layers of encoder and decoder for answer generation. We also apply the proposed GNN based reranking method to enhance the passage retrieval results in the retrieving module. Extensive experiments on common ODQA benchmark datasets (Natural Question and TriviaQA) demonstrate that KG-FiD can improve vanilla FiD by up to 1.5% on answer exact match score and achieve comparable performance with FiD with only 40% of computation cost.
Commonsense-Focused Dialogues for Response Generation: An Empirical Study
Sep 21, 2021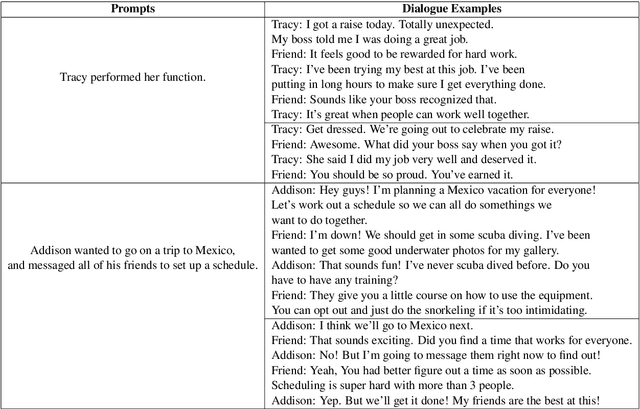
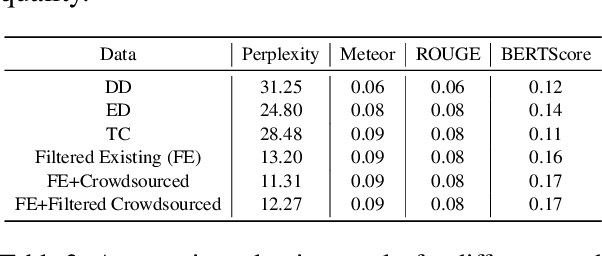
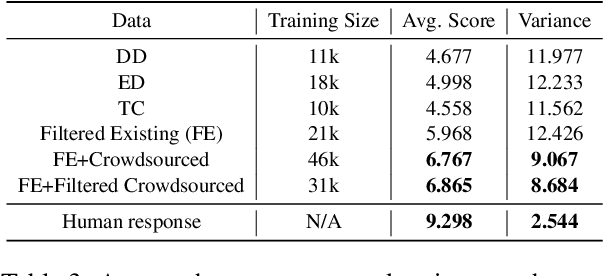
Smooth and effective communication requires the ability to perform latent or explicit commonsense inference. Prior commonsense reasoning benchmarks (such as SocialIQA and CommonsenseQA) mainly focus on the discriminative task of choosing the right answer from a set of candidates, and do not involve interactive language generation as in dialogue. Moreover, existing dialogue datasets do not explicitly focus on exhibiting commonsense as a facet. In this paper, we present an empirical study of commonsense in dialogue response generation. We first auto-extract commonsensical dialogues from existing dialogue datasets by leveraging ConceptNet, a commonsense knowledge graph. Furthermore, building on social contexts/situations in SocialIQA, we collect a new dialogue dataset with 25K dialogues aimed at exhibiting social commonsense in an interactive setting. We evaluate response generation models trained using these datasets and find that models trained on both extracted and our collected data produce responses that consistently exhibit more commonsense than baselines. Finally we propose an approach for automatic evaluation of commonsense that relies on features derived from ConceptNet and pre-trained language and dialog models, and show reasonable correlation with human evaluation of responses' commonsense quality. We are releasing a subset of our collected data, Commonsense-Dialogues, containing about 11K dialogs.
RockNER: A Simple Method to Create Adversarial Examples for Evaluating the Robustness of Named Entity Recognition Models
Sep 12, 2021
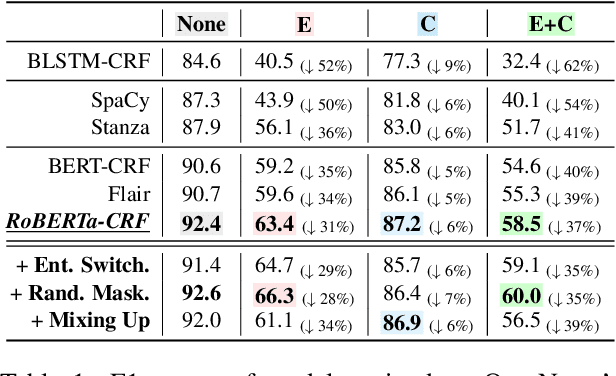
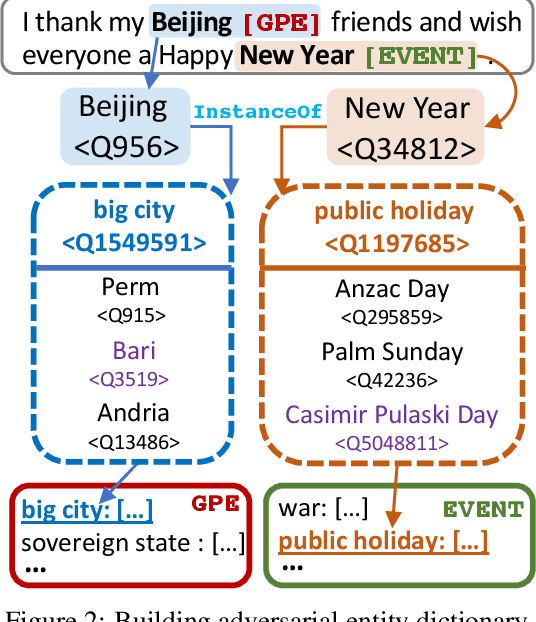
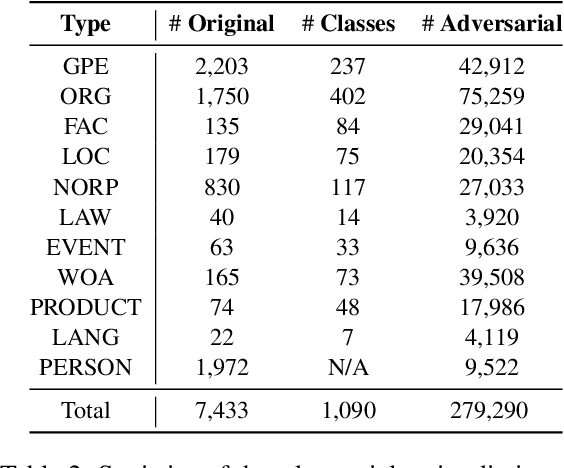
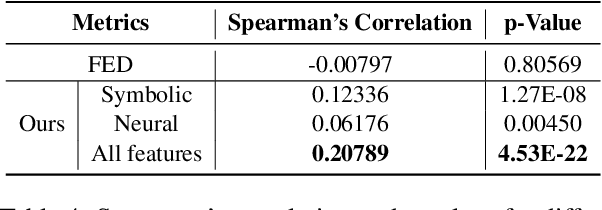
To audit the robustness of named entity recognition (NER) models, we propose RockNER, a simple yet effective method to create natural adversarial examples. Specifically, at the entity level, we replace target entities with other entities of the same semantic class in Wikidata; at the context level, we use pre-trained language models (e.g., BERT) to generate word substitutions. Together, the two levels of attack produce natural adversarial examples that result in a shifted distribution from the training data on which our target models have been trained. We apply the proposed method to the OntoNotes dataset and create a new benchmark named OntoRock for evaluating the robustness of existing NER models via a systematic evaluation protocol. Our experiments and analysis reveal that even the best model has a significant performance drop, and these models seem to memorize in-domain entity patterns instead of reasoning from the context. Our work also studies the effects of a few simple data augmentation methods to improve the robustness of NER models.
AutoTriggER: Named Entity Recognition with Auxiliary Trigger Extraction
Sep 10, 2021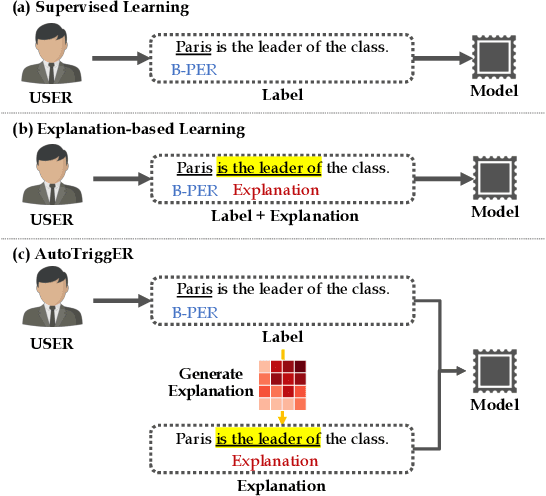
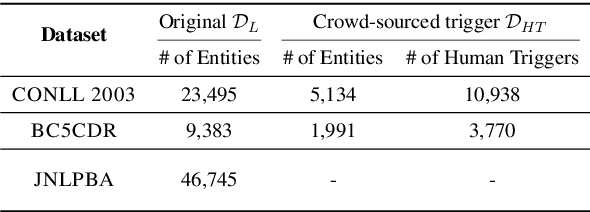

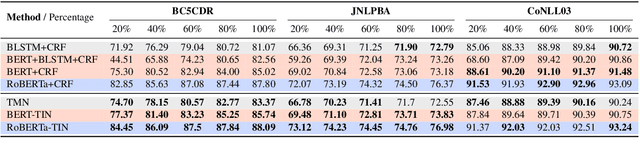
Deep neural models for low-resource named entity recognition (NER) have shown impressive results by leveraging distant super-vision or other meta-level information (e.g. explanation). However, the costs of acquiring such additional information are generally prohibitive, especially in domains where existing resources (e.g. databases to be used for distant supervision) may not exist. In this paper, we present a novel two-stage framework (AutoTriggER) to improve NER performance by automatically generating and leveraging "entity triggers" which are essentially human-readable clues in the text that can help guide the model to make better decisions. Thus, the framework is able to both create and leverage auxiliary supervision by itself. Through experiments on three well-studied NER datasets, we show that our automatically extracted triggers are well-matched to human triggers, and AutoTriggER improves performance over a RoBERTa-CRFarchitecture by nearly 0.5 F1 points on average and much more in a low resource setting.
Discretized Integrated Gradients for Explaining Language Models
Aug 31, 2021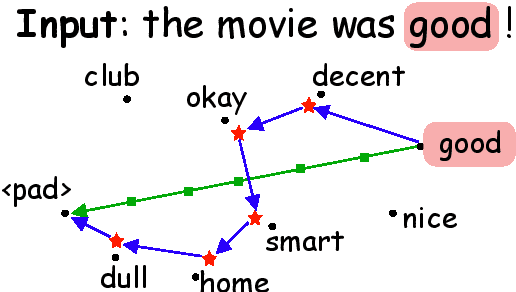
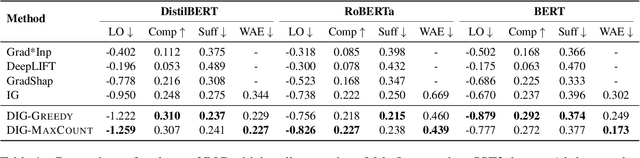
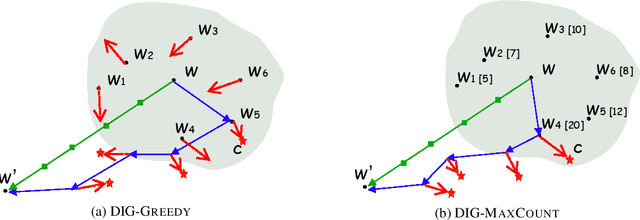
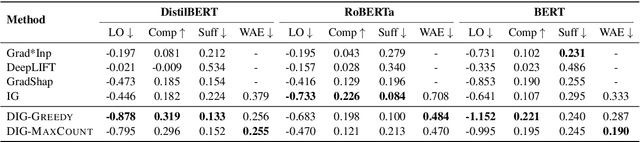
As a prominent attribution-based explanation algorithm, Integrated Gradients (IG) is widely adopted due to its desirable explanation axioms and the ease of gradient computation. It measures feature importance by averaging the model's output gradient interpolated along a straight-line path in the input data space. However, such straight-line interpolated points are not representative of text data due to the inherent discreteness of the word embedding space. This questions the faithfulness of the gradients computed at the interpolated points and consequently, the quality of the generated explanations. Here we propose Discretized Integrated Gradients (DIG), which allows effective attribution along non-linear interpolation paths. We develop two interpolation strategies for the discrete word embedding space that generates interpolation points that lie close to actual words in the embedding space, yielding more faithful gradient computation. We demonstrate the effectiveness of DIG over IG through experimental and human evaluations on multiple sentiment classification datasets. We provide the source code of DIG to encourage reproducible research.
Improving Counterfactual Generation for Fair Hate Speech Detection
Aug 03, 2021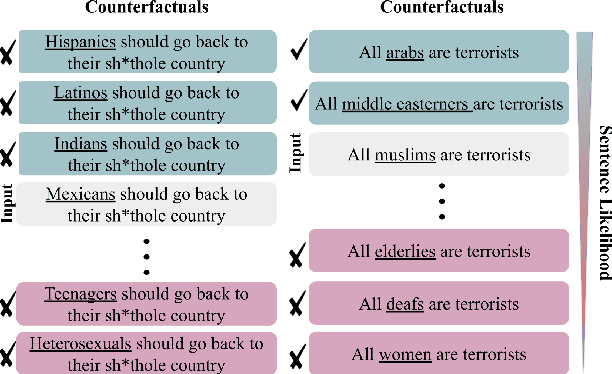


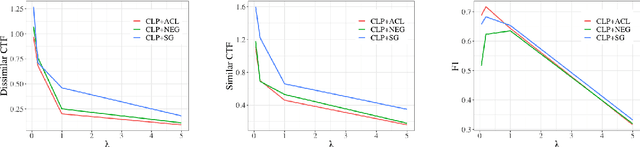
Bias mitigation approaches reduce models' dependence on sensitive features of data, such as social group tokens (SGTs), resulting in equal predictions across the sensitive features. In hate speech detection, however, equalizing model predictions may ignore important differences among targeted social groups, as hate speech can contain stereotypical language specific to each SGT. Here, to take the specific language about each SGT into account, we rely on counterfactual fairness and equalize predictions among counterfactuals, generated by changing the SGTs. Our method evaluates the similarity in sentence likelihoods (via pre-trained language models) among counterfactuals, to treat SGTs equally only within interchangeable contexts. By applying logit pairing to equalize outcomes on the restricted set of counterfactuals for each instance, we improve fairness metrics while preserving model performance on hate speech detection.
Do Language Models Perform Generalizable Commonsense Inference?
Jun 22, 2021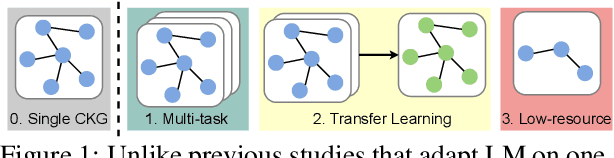
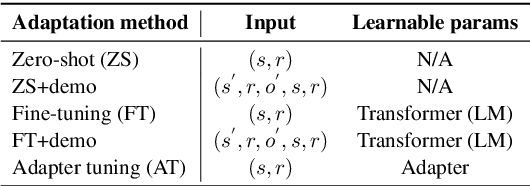
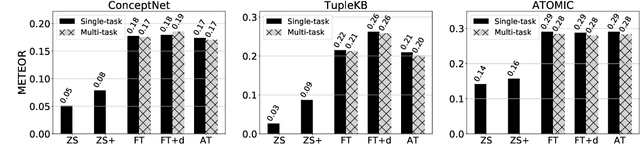
Inspired by evidence that pretrained language models (LMs) encode commonsense knowledge, recent work has applied LMs to automatically populate commonsense knowledge graphs (CKGs). However, there is a lack of understanding on their generalization to multiple CKGs, unseen relations, and novel entities. This paper analyzes the ability of LMs to perform generalizable commonsense inference, in terms of knowledge capacity, transferability, and induction. Our experiments with these three aspects show that: (1) LMs can adapt to different schemas defined by multiple CKGs but fail to reuse the knowledge to generalize to new relations. (2) Adapted LMs generalize well to unseen subjects, but less so on novel objects. Future work should investigate how to improve the transferability and induction of commonsense mining from LMs.