 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtract, Denoise, and Enforce: Evaluating and Predicting Lexical Constraints for Conditional Text Generation
Apr 18, 2021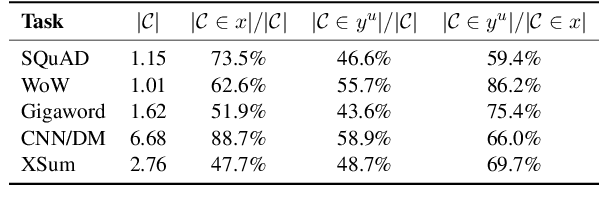
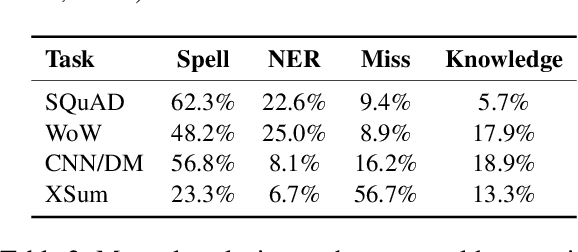
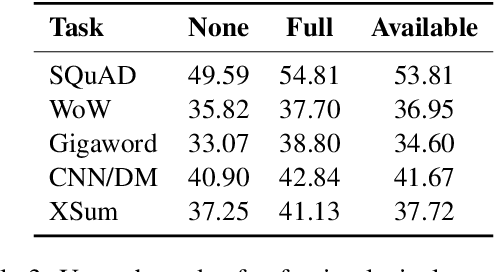
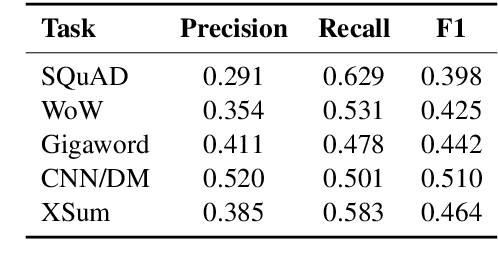
Recently, pre-trained language models (PLMs) have dominated conditional text generation tasks. Given the impressive performance and prevalence of the PLMs, it is seemingly natural to assume that they could figure out what to attend to in the input and what to include in the output via seq2seq learning without more guidance than the training input/output pairs. However, a rigorous study regarding the above assumption is still lacking. In this paper, we present a systematic analysis of conditional generation to study whether current PLMs are good enough for preserving important concepts in the input and to what extent explicitly guiding generation with lexical constraints is beneficial. We conduct extensive analytical experiments on a range of conditional generation tasks and try to answer in what scenarios guiding generation with lexical constraints works well and why. We then propose a framework for automatic constraint extraction, denoising, and enforcement that is shown to perform comparably or better than unconstrained generation. We hope that our findings could serve as a reference when determining whether it is appropriate and worthwhile to use explicit constraints for a specific task or dataset.\footnote{Our code is available at \url{https://github.com/morningmoni/LCGen-eval}.}
Lawyers are Dishonest? Quantifying Representational Harms in Commonsense Knowledge Resources
Mar 21, 2021

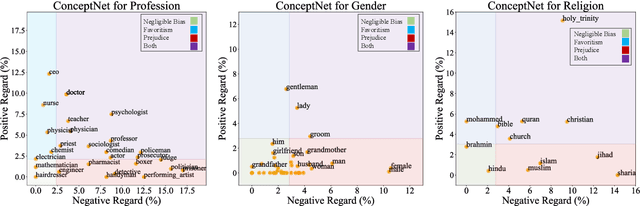

Warning: this paper contains content that may be offensive or upsetting. Numerous natural language processing models have tried injecting commonsense by using the ConceptNet knowledge base to improve performance on different tasks. ConceptNet, however, is mostly crowdsourced from humans and may reflect human biases such as "lawyers are dishonest." It is important that these biases are not conflated with the notion of commonsense. We study this missing yet important problem by first defining and quantifying biases in ConceptNet as two types of representational harms: overgeneralization of polarized perceptions and representation disparity. We find that ConceptNet contains severe biases and disparities across four demographic categories. In addition, we analyze two downstream models that use ConceptNet as a source for commonsense knowledge and find the existence of biases in those models as well. We further propose a filtered-based bias-mitigation approach and examine its effectiveness. We show that our mitigation approach can reduce the issues in both resource and models but leads to a performance drop, leaving room for future work to build fairer and stronger commonsense models.
Refining Neural Networks with Compositional Explanations
Mar 18, 2021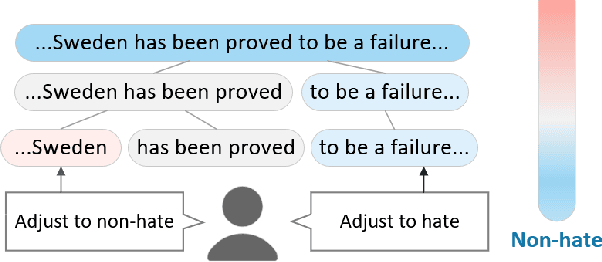
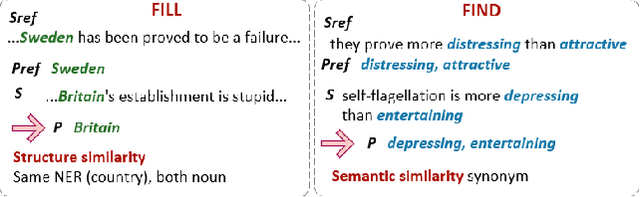


Neural networks are prone to learning spurious correlations from biased datasets, and are thus vulnerable when making inferences in a new target domain. Prior work reveals spurious patterns via post-hoc model explanations which compute the importance of input features, and further eliminates the unintended model behaviors by regularizing importance scores with human knowledge. However, such regularization technique lacks flexibility and coverage, since only importance scores towards a pre-defined list of features are adjusted, while more complex human knowledge such as feature interaction and pattern generalization can hardly be incorporated. In this work, we propose to refine a learned model by collecting human-provided compositional explanations on the models' failure cases. By describing generalizable rules about spurious patterns in the explanation, more training examples can be matched and regularized, tackling the challenge of regularization coverage. We additionally introduce a regularization term for feature interaction to support more complex human rationale in refining the model. We demonstrate the effectiveness of the proposed approach on two text classification tasks by showing improved performance in target domain after refinement.
Modality-specific Distillation
Jan 06, 2021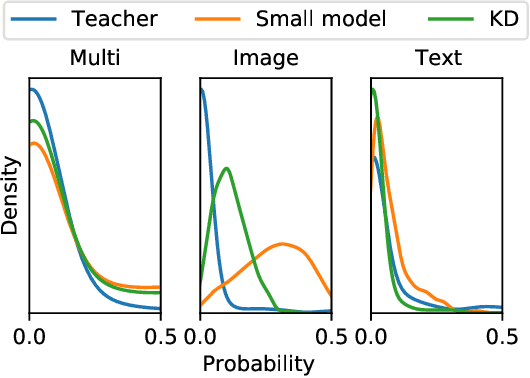
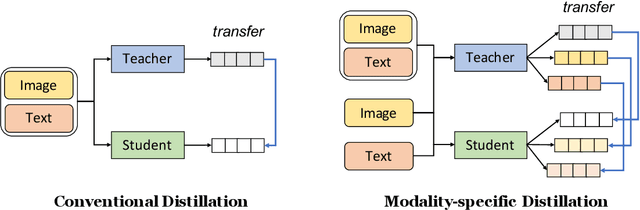
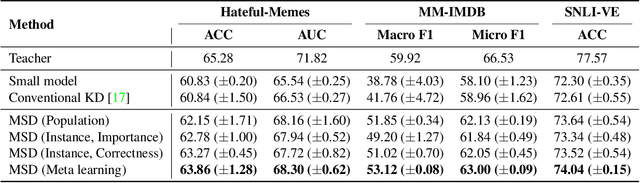
Large neural networks are impractical to deploy on mobile devices due to their heavy computational cost and slow inference. Knowledge distillation (KD) is a technique to reduce the model size while retaining performance by transferring knowledge from a large "teacher" model to a smaller "student" model. However, KD on multimodal datasets such as vision-language datasets is relatively unexplored and digesting such multimodal information is challenging since different modalities present different types of information. In this paper, we propose modality-specific distillation (MSD) to effectively transfer knowledge from a teacher on multimodal datasets. Existing KD approaches can be applied to multimodal setup, but a student doesn't have access to modality-specific predictions. Our idea aims at mimicking a teacher's modality-specific predictions by introducing an auxiliary loss term for each modality. Because each modality has different importance for predictions, we also propose weighting approaches for the auxiliary losses; a meta-learning approach to learn the optimal weights on these loss terms. In our experiments, we demonstrate the effectiveness of our MSD and the weighting scheme and show that it achieves better performance than KD.
Zero-shot Learning by Generating Task-specific Adapters
Jan 02, 2021

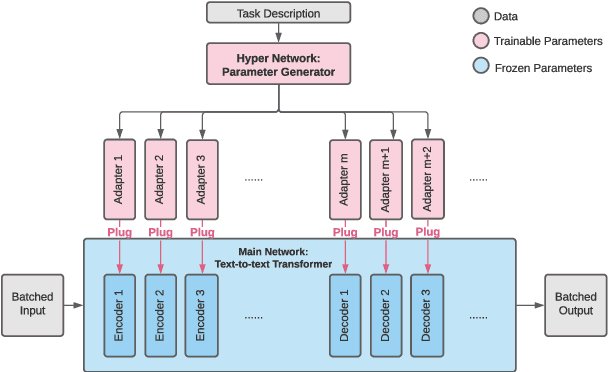
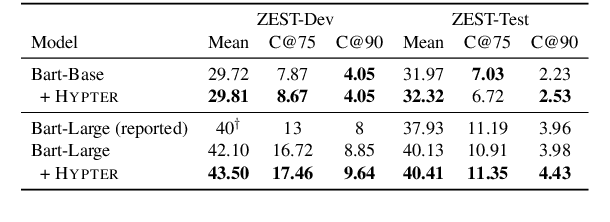
Pre-trained text-to-text transformers achieve impressive performance across a wide range of NLP tasks, and they naturally support zero-shot learning (ZSL) by using the task description as prompt in the input. However, this approach has potential limitations, as it learns from input-output pairs at instance level, instead of learning to solve tasks at task level. Alternatively, applying existing ZSL methods to text-to-text transformers is non-trivial due to their text generation objective and huge size. To address these issues, we introduce Hypter, a framework that improves zero-shot transferability by training a hypernetwork to generate task-specific adapters from task descriptions. This formulation enables learning at task level, and greatly reduces the number of parameters by using light-weight adapters. Experiments on two datasets demonstrate Hypter improves upon fine-tuning baselines.
RiddleSense: Answering Riddle Questions as Commonsense Reasoning
Jan 02, 2021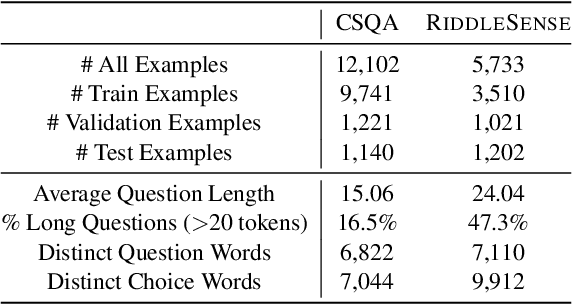
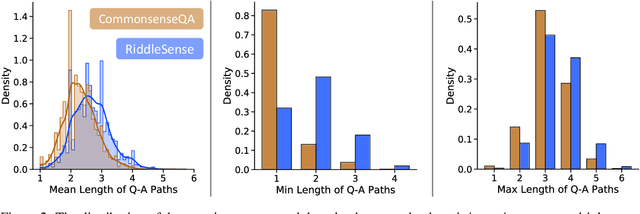
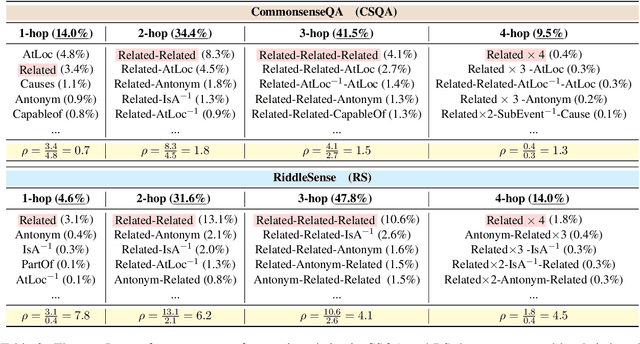
A riddle is a mystifying, puzzling question about everyday concepts. For example, the riddle "I have five fingers but I am not alive. What am I?" asks about the concept of a glove. Solving riddles is a challenging cognitive process for humans, in that it requires complex commonsense reasoning abilities and an understanding of figurative language. However, there are currently no commonsense reasoning datasets that test these abilities. We propose RiddleSense, a novel multiple-choice question answering challenge for benchmarking higher-order commonsense reasoning models, which is the first large dataset for riddle-style commonsense question answering, where the distractors are crowdsourced from human annotators. We systematically evaluate a wide range of reasoning models over it and point out that there is a large gap between the best-supervised model and human performance -- pointing to interesting future research for higher-order commonsense reasoning and computational creativity.
Studying Strategically: Learning to Mask for Closed-book QA
Jan 01, 2021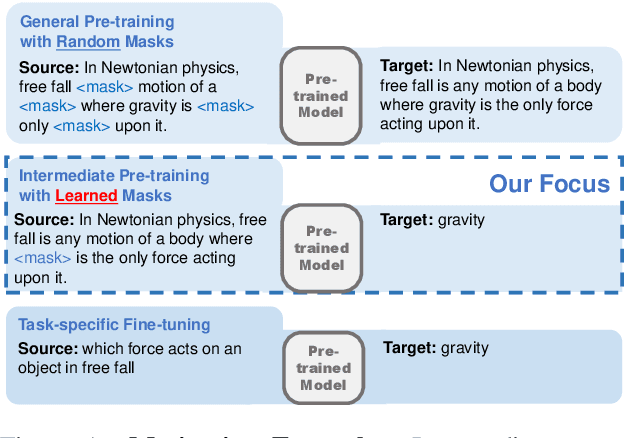

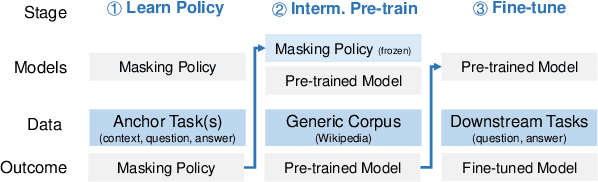

Closed-book question-answering (QA) is a challenging task that requires a model to directly answer questions without access to external knowledge. It has been shown that directly fine-tuning pre-trained language models with (question, answer) examples yields surprisingly competitive performance, which is further improved upon through adding an intermediate pre-training stage between general pre-training and fine-tuning. Prior work used a heuristic during this intermediate stage, whereby named entities and dates are masked, and the model is trained to recover these tokens. In this paper, we aim to learn the optimal masking strategy for the intermediate pre-training stage. We first train our masking policy to extract spans that are likely to be tested, using supervision from the downstream task itself, then deploy the learned policy during intermediate pre-training. Thus, our policy packs task-relevant knowledge into the parameters of a language model. Our approach is particularly effective on TriviaQA, outperforming strong heuristics when used to pre-train BART.
DEER: A Data Efficient Language Model for Event Temporal Reasoning
Dec 30, 2020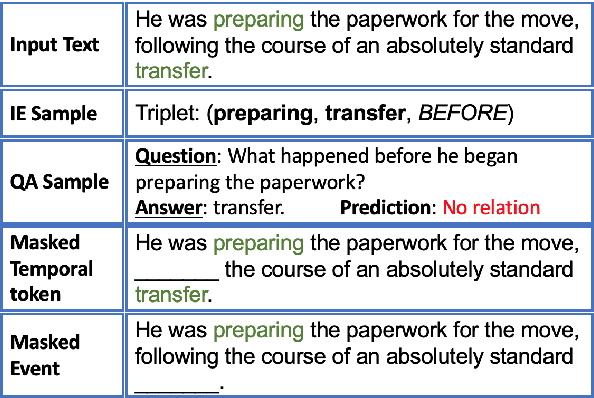
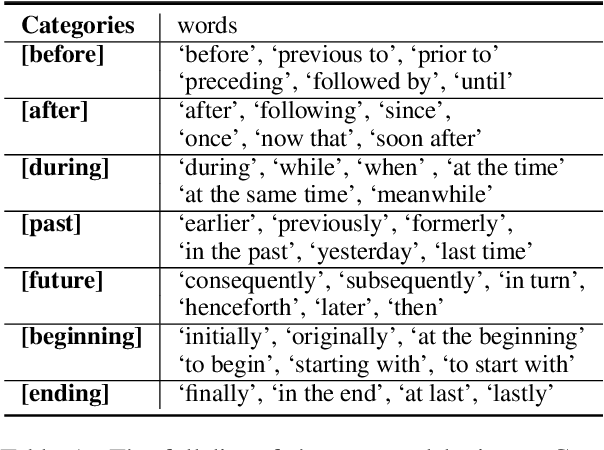
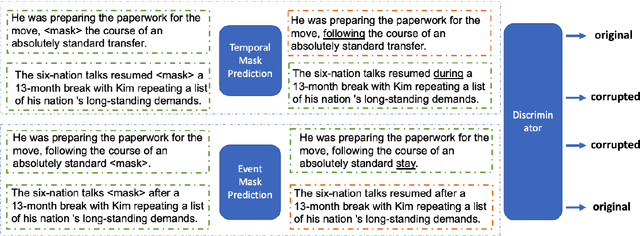
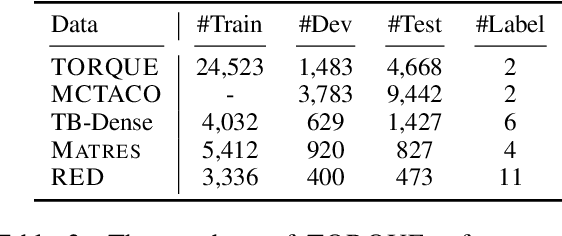
Pretrained language models (LMs) such as BERT, RoBERTa, and ELECTRA are effective at improving the performances of a variety of downstream NLP tasks. Recently, researchers have incorporated domain and task-specific knowledge in these LMs' training objectives and further enhanced models' capability of handling downstream tasks. However, none of these LMs are designed specifically for event temporal reasoning. We propose DEER, a language model that is trained to focus on event temporal relations and performs better under low-resource settings than original LMs. More specifically, we create a large number of training samples to simulate the machine reading comprehension and information extraction tasks for event temporal understanding and leverage a generator-discriminator structure to reinforce the LMs' capability of event temporal reasoning. Our experimental results show that DEER can achieve SOTA results and works particularly well in low-resource settings across 5 widely used datasets.
Learning Contextualized Knowledge Structures for Commonsense Reasoning
Oct 24, 2020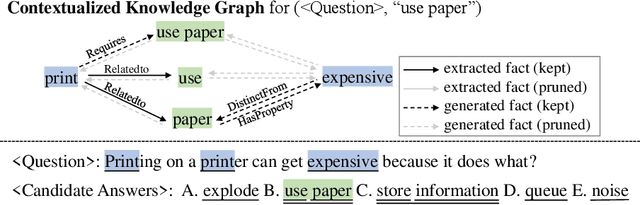
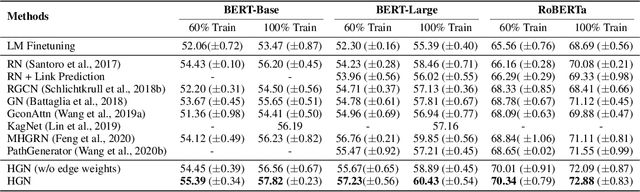
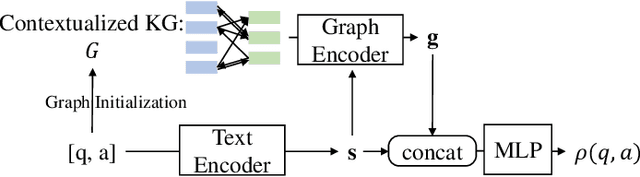
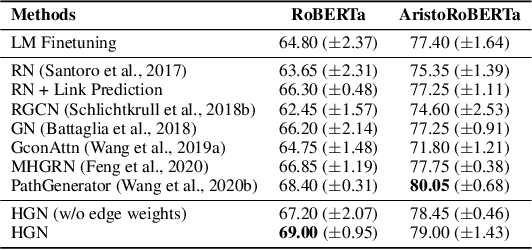
Recently, neural-symbolic architectures have achieved success on commonsense reasoning through effectively encoding relational structures retrieved from external knowledge graphs (KGs) and obtained state-of-the-art results in tasks such as (commonsense) question answering and natural language inference. However, these methods rely on quality and contextualized knowledge structures (i.e., fact triples) that are retrieved at the pre-processing stage but overlook challenges caused by incompleteness of a KG, limited expressiveness of its relations, and retrieved facts irrelevant to the reasoning context. In this paper, we present a novel neural-symbolic model, named Hybrid Graph Network (HGN), which jointly generates feature representations for new triples (as a complement to existing edges in the KG), determines the relevance of the triples to the reasoning context, and learns graph module parameters for encoding the relational information. Our model learns a compact graph structure (comprising both extracted and generated edges) through filtering edges that are unhelpful to the reasoning process. We show marked improvement on three commonsense reasoning benchmarks and demonstrate the superiority of the learned graph structures with user studies.
Learning to Deceive Knowledge Graph Augmented Models via Targeted Perturbation
Oct 24, 2020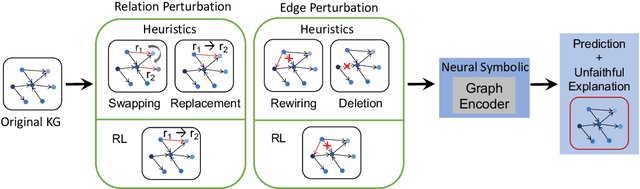
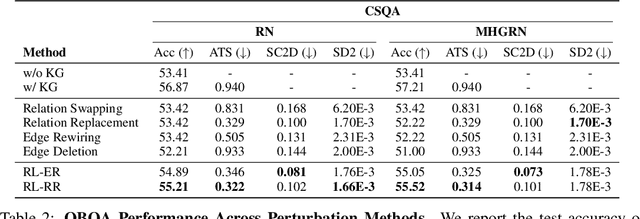
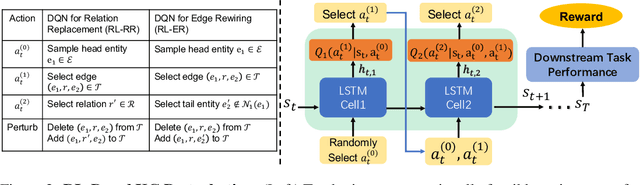
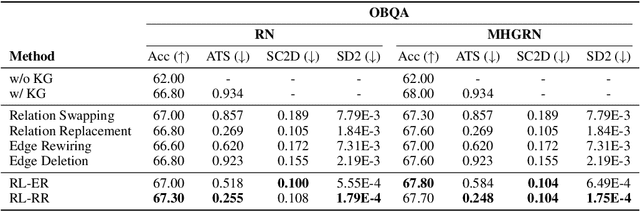
Symbolic knowledge (e.g., entities, relations, and facts in a knowledge graph) has become an increasingly popular component of neural-symbolic models applied to machine learning tasks, such as question answering and recommender systems. Besides improving downstream performance, these symbolic structures (and their associated attention weights) are often used to help explain the model's predictions and provide "insights" to practitioners. In this paper, we question the faithfulness of such symbolic explanations. We demonstrate that, through a learned strategy (or even simple heuristics), one can produce deceptively perturbed symbolic structures which maintain the downstream performance of the original structure while significantly deviating from the original semantics. In particular, we train a reinforcement learning policy to manipulate relation types or edge connections in a knowledge graph, such that the resulting downstream performance is maximally preserved. Across multiple models and tasks, our approach drastically alters knowledge graphs with little to no drop in performance. These results raise doubts about the faithfulness of explanations provided by learned symbolic structures and the reliability of current neural-symbolic models in leveraging symbolic knowledge.