 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Shapley Explanation via Contributive Cooperator Selection
Jun 17, 2022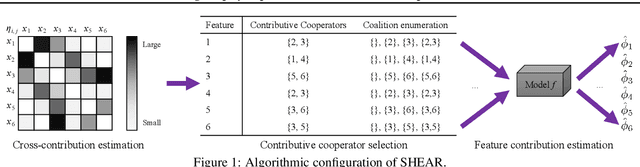
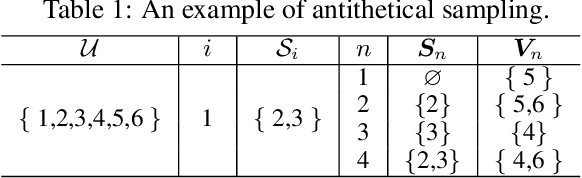
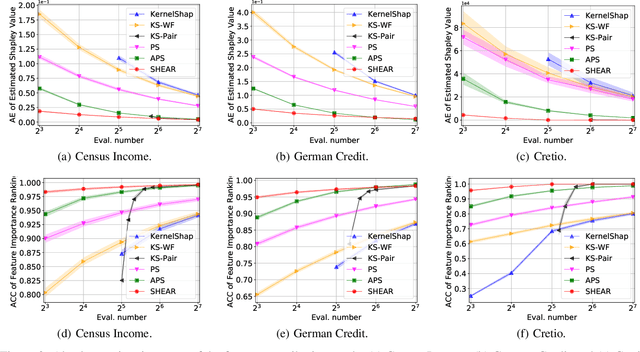

Even though Shapley value provides an effective explanation for a DNN model prediction, the computation relies on the enumeration of all possible input feature coalitions, which leads to the exponentially growing complexity. To address this problem, we propose a novel method SHEAR to significantly accelerate the Shapley explanation for DNN models, where only a few coalitions of input features are involved in the computation. The selection of the feature coalitions follows our proposed Shapley chain rule to minimize the absolute error from the ground-truth Shapley values, such that the computation can be both efficient and accurate. To demonstrate the effectiveness, we comprehensively evaluate SHEAR across multiple metrics including the absolute error from the ground-truth Shapley value, the faithfulness of the explanations, and running speed. The experimental results indicate SHEAR consistently outperforms state-of-the-art baseline methods across different evaluation metrics, which demonstrates its potentials in real-world applications where the computational resource is limited.
Auto-PINN: Understanding and Optimizing Physics-Informed Neural Architecture
May 27, 2022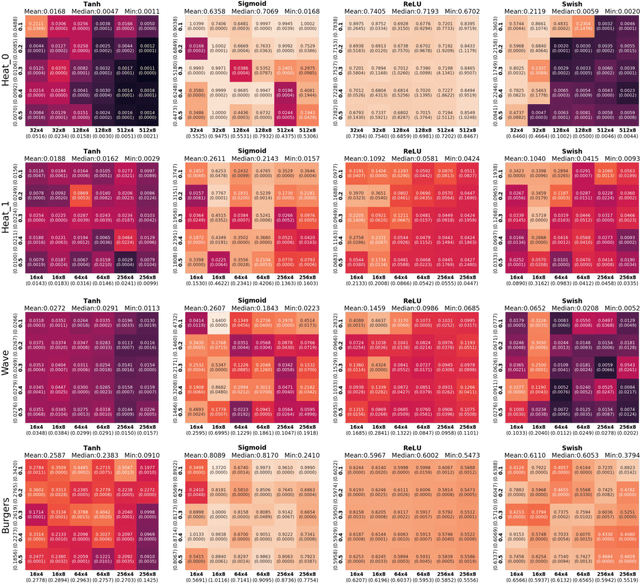
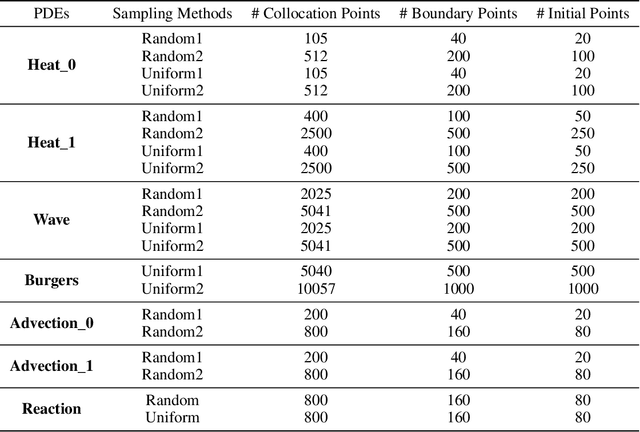

Physics-informed neural networks (PINNs) are revolutionizing science and engineering practice by bringing together the power of deep learning to bear on scientific computation. In forward modeling problems, PINNs are meshless partial differential equation (PDE) solvers that can handle irregular, high-dimensional physical domains. Naturally, the neural architecture hyperparameters have a large impact on the efficiency and accuracy of the PINN solver. However, this remains an open and challenging problem because of the large search space and the difficulty of identifying a proper search objective for PDEs. Here, we propose Auto-PINN, the first systematic, automated hyperparameter optimization approach for PINNs, which employs Neural Architecture Search (NAS) techniques to PINN design. Auto-PINN avoids manually or exhaustively searching the hyperparameter space associated with PINNs. A comprehensive set of pre-experiments using standard PDE benchmarks allows us to probe the structure-performance relationship in PINNs. We find that the different hyperparameters can be decoupled, and that the training loss function of PINNs is a good search objective. Comparison experiments with baseline methods demonstrate that Auto-PINN produces neural architectures with superior stability and accuracy over alternative baselines.
G-Mixup: Graph Data Augmentation for Graph Classification
Feb 16, 2022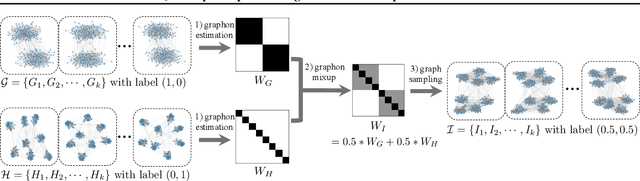

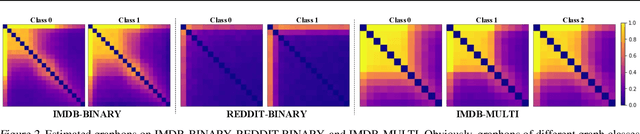
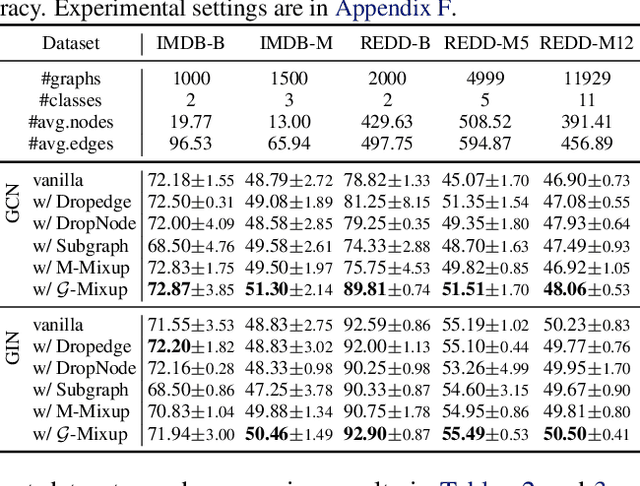
This work develops \emph{mixup for graph data}. Mixup has shown superiority in improving the generalization and robustness of neural networks by interpolating features and labels between two random samples. Traditionally, Mixup can work on regular, grid-like, and Euclidean data such as image or tabular data. However, it is challenging to directly adopt Mixup to augment graph data because different graphs typically: 1) have different numbers of nodes; 2) are not readily aligned; and 3) have unique typologies in non-Euclidean space. To this end, we propose $\mathcal{G}$-Mixup to augment graphs for graph classification by interpolating the generator (i.e., graphon) of different classes of graphs. Specifically, we first use graphs within the same class to estimate a graphon. Then, instead of directly manipulating graphs, we interpolate graphons of different classes in the Euclidean space to get mixed graphons, where the synthetic graphs are generated through sampling based on the mixed graphons. Extensive experiments show that $\mathcal{G}$-Mixup substantially improves the generalization and robustness of GNNs.
BED: A Real-Time Object Detection System for Edge Devices
Feb 14, 2022


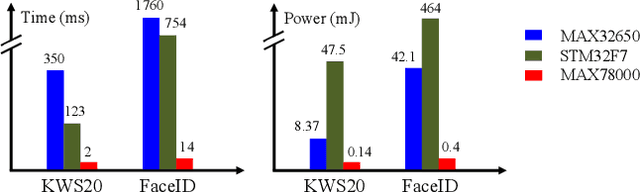
Deploying machine learning models to edge devices has many real-world applications, especially for the scenarios that demand low latency, low power, or data privacy. However, it requires substantial research and engineering efforts due to the limited computational resources and memory of edge devices. In this demo, we present BED, an object detection system for edge devices practiced on the MAX78000 DNN accelerator. BED integrates on-device DNN inference with a camera and a screen for image acquisition and output exhibition, respectively. Experiment results indicate BED can provide accurate detection with an only 300KB tiny DNN model.
Geometric Graph Representation Learning via Maximizing Rate Reduction
Feb 13, 2022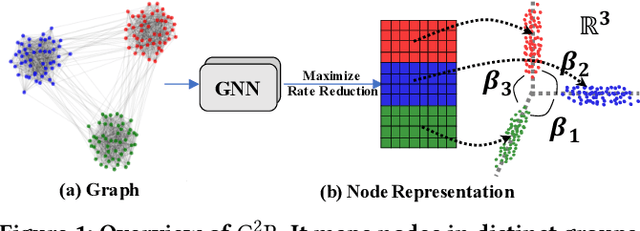
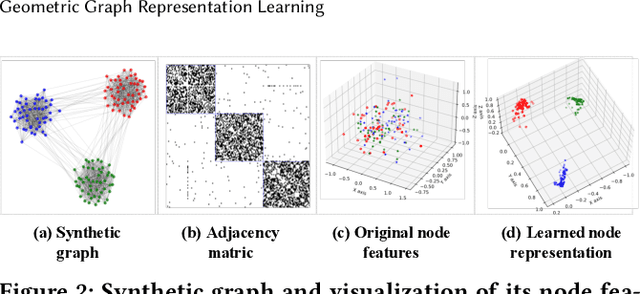

Learning discriminative node representations benefits various downstream tasks in graph analysis such as community detection and node classification. Existing graph representation learning methods (e.g., based on random walk and contrastive learning) are limited to maximizing the local similarity of connected nodes. Such pair-wise learning schemes could fail to capture the global distribution of representations, since it has no explicit constraints on the global geometric properties of representation space. To this end, we propose Geometric Graph Representation Learning (G2R) to learn node representations in an unsupervised manner via maximizing rate reduction. In this way, G2R maps nodes in distinct groups (implicitly stored in the adjacency matrix) into different subspaces, while each subspace is compact and different subspaces are dispersedly distributed. G2R adopts a graph neural network as the encoder and maximizes the rate reduction with the adjacency matrix. Furthermore, we theoretically and empirically demonstrate that rate reduction maximization is equivalent to maximizing the principal angles between different subspaces. Experiments on real-world datasets show that G2R outperforms various baselines on node classification and community detection tasks.
FMP: Toward Fair Graph Message Passing against Topology Bias
Feb 08, 2022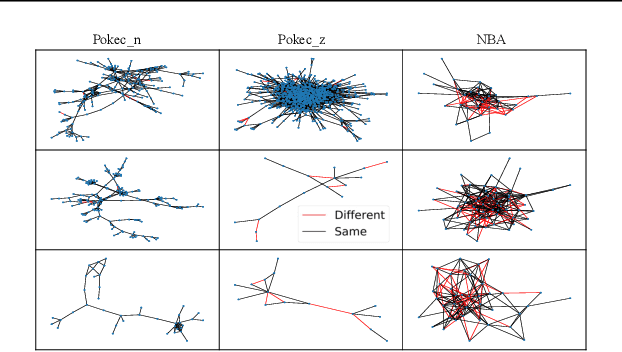

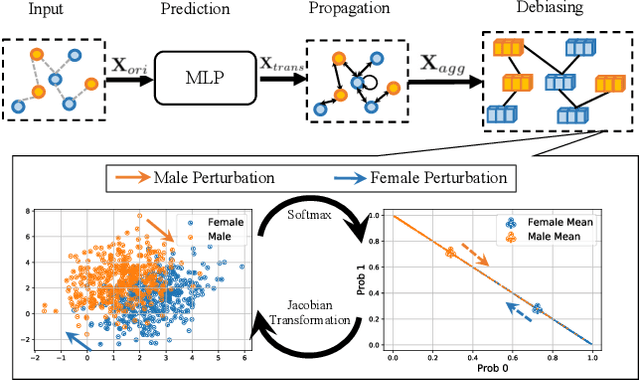

Despite recent advances in achieving fair representations and predictions through regularization, adversarial debiasing, and contrastive learning in graph neural networks (GNNs), the working mechanism (i.e., message passing) behind GNNs inducing unfairness issue remains unknown. In this work, we theoretically and experimentally demonstrate that representative aggregation in message-passing schemes accumulates bias in node representation due to topology bias induced by graph topology. Thus, a \textsf{F}air \textsf{M}essage \textsf{P}assing (FMP) scheme is proposed to aggregate useful information from neighbors but minimize the effect of topology bias in a unified framework considering graph smoothness and fairness objectives. The proposed FMP is effective, transparent, and compatible with back-propagation training. An acceleration approach on gradient calculation is also adopted to improve algorithm efficiency. Experiments on node classification tasks demonstrate that the proposed FMP outperforms the state-of-the-art baselines in effectively and efficiently mitigating bias on three real-world datasets.
Deconfounding to Explanation Evaluation in Graph Neural Networks
Feb 01, 2022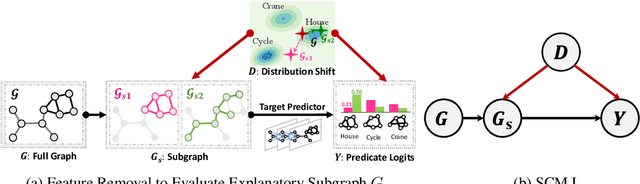
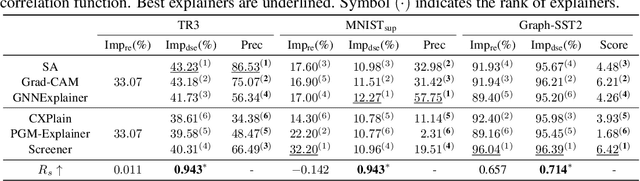
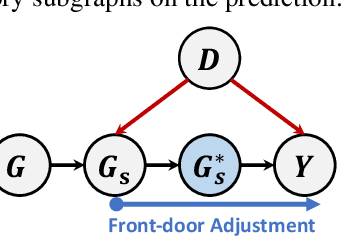

Explainability of graph neural networks (GNNs) aims to answer "Why the GNN made a certain prediction?", which is crucial to interpret the model prediction. The feature attribution framework distributes a GNN's prediction to its input features (e.g., edges), identifying an influential subgraph as the explanation. When evaluating the explanation (i.e., subgraph importance), a standard way is to audit the model prediction based on the subgraph solely. However, we argue that a distribution shift exists between the full graph and the subgraph, causing the out-of-distribution problem. Furthermore, with an in-depth causal analysis, we find the OOD effect acts as the confounder, which brings spurious associations between the subgraph importance and model prediction, making the evaluation less reliable. In this work, we propose Deconfounded Subgraph Evaluation (DSE) which assesses the causal effect of an explanatory subgraph on the model prediction. While the distribution shift is generally intractable, we employ the front-door adjustment and introduce a surrogate variable of the subgraphs. Specifically, we devise a generative model to generate the plausible surrogates that conform to the data distribution, thus approaching the unbiased estimation of subgraph importance. Empirical results demonstrate the effectiveness of DSE in terms of explanation fidelity.
MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs
Jan 07, 2022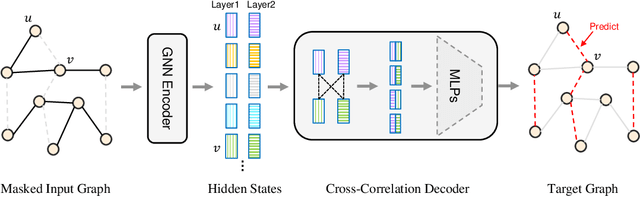
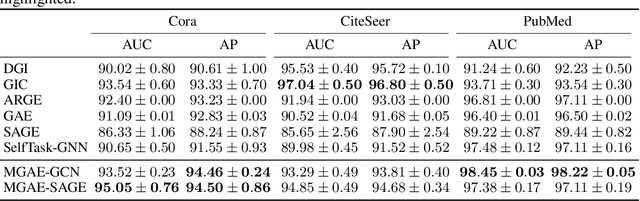
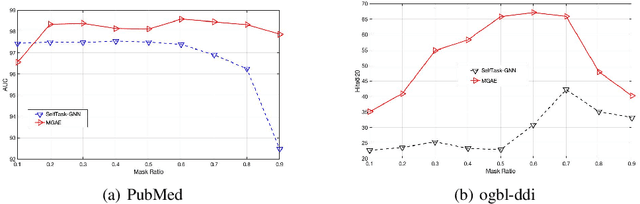
We introduce a novel masked graph autoencoder (MGAE) framework to perform effective learning on graph structure data. Taking insights from self-supervised learning, we randomly mask a large proportion of edges and try to reconstruct these missing edges during training. MGAE has two core designs. First, we find that masking a high ratio of the input graph structure, e.g., $70\%$, yields a nontrivial and meaningful self-supervisory task that benefits downstream applications. Second, we employ a graph neural network (GNN) as an encoder to perform message propagation on the partially-masked graph. To reconstruct the large number of masked edges, a tailored cross-correlation decoder is proposed. It could capture the cross-correlation between the head and tail nodes of anchor edge in multi-granularity. Coupling these two designs enables MGAE to be trained efficiently and effectively. Extensive experiments on multiple open datasets (Planetoid and OGB benchmarks) demonstrate that MGAE generally performs better than state-of-the-art unsupervised learning competitors on link prediction and node classification.
Towards Similarity-Aware Time-Series Classification
Jan 06, 2022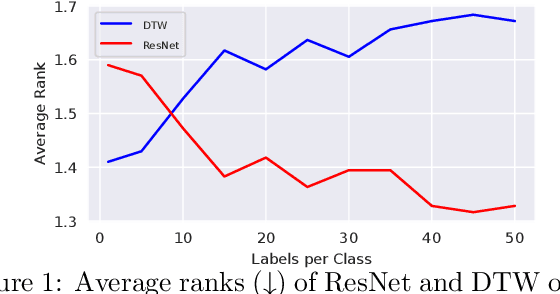

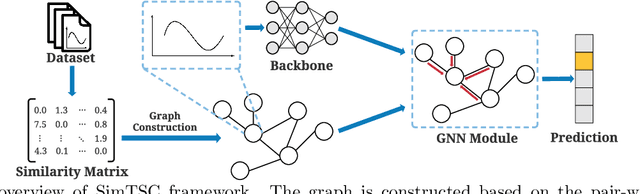
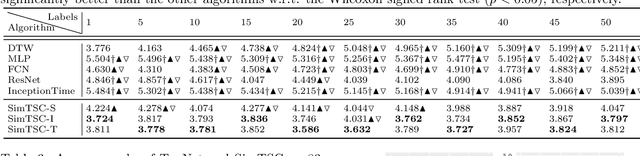
We study time-series classification (TSC), a fundamental task of time-series data mining. Prior work has approached TSC from two major directions: (1) similarity-based methods that classify time-series based on the nearest neighbors, and (2) deep learning models that directly learn the representations for classification in a data-driven manner. Motivated by the different working mechanisms within these two research lines, we aim to connect them in such a way as to jointly model time-series similarities and learn the representations. This is a challenging task because it is unclear how we should efficiently leverage similarity information. To tackle the challenge, we propose Similarity-Aware Time-Series Classification (SimTSC), a conceptually simple and general framework that models similarity information with graph neural networks (GNNs). Specifically, we formulate TSC as a node classification problem in graphs, where the nodes correspond to time-series, and the links correspond to pair-wise similarities. We further design a graph construction strategy and a batch training algorithm with negative sampling to improve training efficiency. We instantiate SimTSC with ResNet as the backbone and Dynamic Time Warping (DTW) as the similarity measure. Extensive experiments on the full UCR datasets and several multivariate datasets demonstrate the effectiveness of incorporating similarity information into deep learning models in both supervised and semi-supervised settings. Our code is available at https://github.com/daochenzha/SimTSC
Defense Against Explanation Manipulation
Nov 08, 2021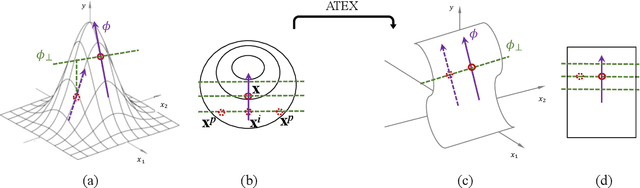
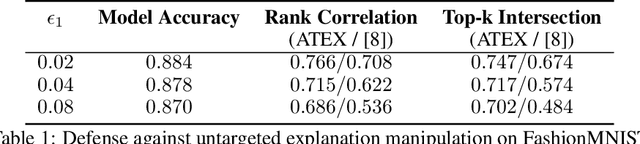
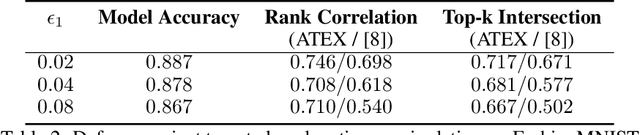
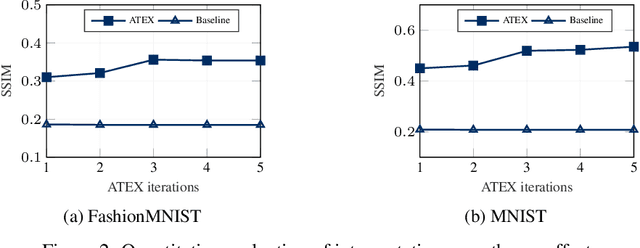
Explainable machine learning attracts increasing attention as it improves transparency of models, which is helpful for machine learning to be trusted in real applications. However, explanation methods have recently been demonstrated to be vulnerable to manipulation, where we can easily change a model's explanation while keeping its prediction constant. To tackle this problem, some efforts have been paid to use more stable explanation methods or to change model configurations. In this work, we tackle the problem from the training perspective, and propose a new training scheme called Adversarial Training on EXplanations (ATEX) to improve the internal explanation stability of a model regardless of the specific explanation method being applied. Instead of directly specifying explanation values over data instances, ATEX only puts requirement on model predictions which avoids involving second-order derivatives in optimization. As a further discussion, we also find that explanation stability is closely related to another property of the model, i.e., the risk of being exposed to adversarial attack. Through experiments, besides showing that ATEX improves model robustness against manipulation targeting explanation, it also brings additional benefits including smoothing explanations and improving the efficacy of adversarial training if applied to the model.