 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fairness in Personalized Ads Using Impression Variance Aware Reinforcement Learning
Jun 08, 2023



Variances in ad impression outcomes across demographic groups are increasingly considered to be potentially indicative of algorithmic bias in personalized ads systems. While there are many definitions of fairness that could be applicable in the context of personalized systems, we present a framework which we call the Variance Reduction System (VRS) for achieving more equitable outcomes in Meta's ads systems. VRS seeks to achieve a distribution of impressions with respect to selected protected class (PC) attributes that more closely aligns the demographics of an ad's eligible audience (a function of advertiser targeting criteria) with the audience who sees that ad, in a privacy-preserving manner. We first define metrics to quantify fairness gaps in terms of ad impression variances with respect to PC attributes including gender and estimated race. We then present the VRS for re-ranking ads in an impression variance-aware manner. We evaluate VRS via extensive simulations over different parameter choices and study the effect of the VRS on the chosen fairness metric. We finally present online A/B testing results from applying VRS to Meta's ads systems, concluding with a discussion of future work. We have deployed the VRS to all users in the US for housing ads, resulting in significant improvement in our fairness metric. VRS is the first large-scale deployed framework for pursuing fairness for multiple PC attributes in online advertising.
CoRTX: Contrastive Framework for Real-time Explanation
Mar 05, 2023



Recent advancements in explainable machine learning provide effective and faithful solutions for interpreting model behaviors. However, many explanation methods encounter efficiency issues, which largely limit their deployments in practical scenarios. Real-time explainer (RTX) frameworks have thus been proposed to accelerate the model explanation process by learning a one-feed-forward explainer. Existing RTX frameworks typically build the explainer under the supervised learning paradigm, which requires large amounts of explanation labels as the ground truth. Considering that accurate explanation labels are usually hard to obtain due to constrained computational resources and limited human efforts, effective explainer training is still challenging in practice. In this work, we propose a COntrastive Real-Time eXplanation (CoRTX) framework to learn the explanation-oriented representation and relieve the intensive dependence of explainer training on explanation labels. Specifically, we design a synthetic strategy to select positive and negative instances for the learning of explanation. Theoretical analysis show that our selection strategy can benefit the contrastive learning process on explanation tasks. Experimental results on three real-world datasets further demonstrate the efficiency and efficacy of our proposed CoRTX framework.
Accelerating Shapley Explanation via Contributive Cooperator Selection
Jun 17, 2022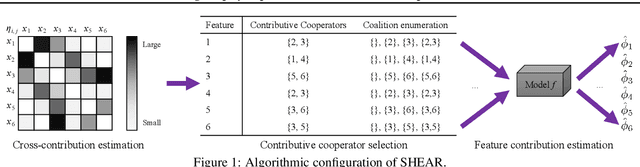
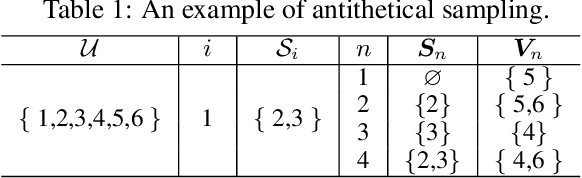
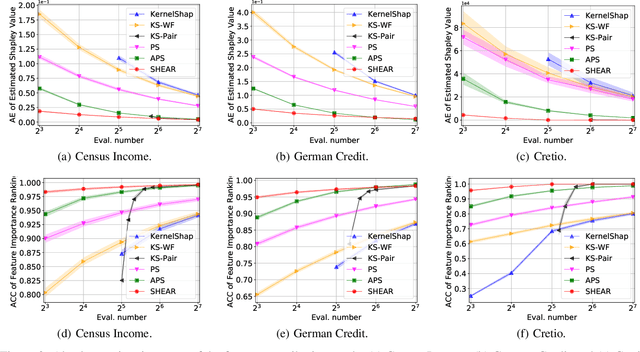

Even though Shapley value provides an effective explanation for a DNN model prediction, the computation relies on the enumeration of all possible input feature coalitions, which leads to the exponentially growing complexity. To address this problem, we propose a novel method SHEAR to significantly accelerate the Shapley explanation for DNN models, where only a few coalitions of input features are involved in the computation. The selection of the feature coalitions follows our proposed Shapley chain rule to minimize the absolute error from the ground-truth Shapley values, such that the computation can be both efficient and accurate. To demonstrate the effectiveness, we comprehensively evaluate SHEAR across multiple metrics including the absolute error from the ground-truth Shapley value, the faithfulness of the explanations, and running speed. The experimental results indicate SHEAR consistently outperforms state-of-the-art baseline methods across different evaluation metrics, which demonstrates its potentials in real-world applications where the computational resource is limited.