 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUPS: Point Cloud Unified Panoptic Segmentation
Feb 28, 2023Point cloud panoptic segmentation is a challenging task that seeks a holistic solution for both semantic and instance segmentation to predict groupings of coherent points. Previous approaches treat semantic and instance segmentation as surrogate tasks, and they either use clustering methods or bounding boxes to gather instance groupings with costly computation and hand-crafted designs in the instance segmentation task. In this paper, we propose a simple but effective point cloud unified panoptic segmentation (PUPS) framework, which use a set of point-level classifiers to directly predict semantic and instance groupings in an end-to-end manner. To realize PUPS, we introduce bipartite matching to our training pipeline so that our classifiers are able to exclusively predict groupings of instances, getting rid of hand-crafted designs, e.g. anchors and Non-Maximum Suppression (NMS). In order to achieve better grouping results, we utilize a transformer decoder to iteratively refine the point classifiers and develop a context-aware CutMix augmentation to overcome the class imbalance problem. As a result, PUPS achieves 1st place on the leader board of SemanticKITTI panoptic segmentation task and state-of-the-art results on nuScenes.
DeSTSeg: Segmentation Guided Denoising Student-Teacher for Anomaly Detection
Nov 21, 2022Visual anomaly detection, an important problem in computer vision, is usually formulated as a one-class classification and segmentation task. The student-teacher (S-T) framework has proved to be effective in solving this challenge. However, previous works based on S-T only empirically applied constraints on normal data and fused multi-level information. In this study, we propose an improved model called DeSTSeg, which integrates a pre-trained teacher network, a denoising student encoder-decoder, and a segmentation network into one framework. First, to strengthen the constraints on anomalous data, we introduce a denoising procedure that allows the student network to learn more robust representations. From synthetically corrupted normal images, we train the student network to match the teacher network feature of the same images without corruption. Second, to fuse the multi-level S-T features adaptively, we train a segmentation network with rich supervision from synthetic anomaly masks, achieving a substantial performance improvement. Experiments on the industrial inspection benchmark dataset demonstrate that our method achieves state-of-the-art performance, 98.6% on image-level ROC, 75.8% on pixel-level average precision, and 76.4% on instance-level average precision.
Adaptive Edge-to-Edge Interaction Learning for Point Cloud Analysis
Nov 20, 2022Recent years have witnessed the great success of deep learning on various point cloud analysis tasks, e.g., classification and semantic segmentation. Since point cloud data is sparse and irregularly distributed, one key issue for point cloud data processing is extracting useful information from local regions. To achieve this, previous works mainly extract the points' features from local regions by learning the relation between each pair of adjacent points. However, these works ignore the relation between edges in local regions, which encodes the local shape information. Associating the neighbouring edges could potentially make the point-to-point relation more aware of the local structure and more robust. To explore the role of the relation between edges, this paper proposes a novel Adaptive Edge-to-Edge Interaction Learning module, which aims to enhance the point-to-point relation through modelling the edge-to-edge interaction in the local region adaptively. We further extend the module to a symmetric version to capture the local structure more thoroughly. Taking advantage of the proposed modules, we develop two networks for segmentation and shape classification tasks, respectively. Various experiments on several public point cloud datasets demonstrate the effectiveness of our method for point cloud analysis.
Adma-GAN: Attribute-Driven Memory Augmented GANs for Text-to-Image Generation
Sep 28, 2022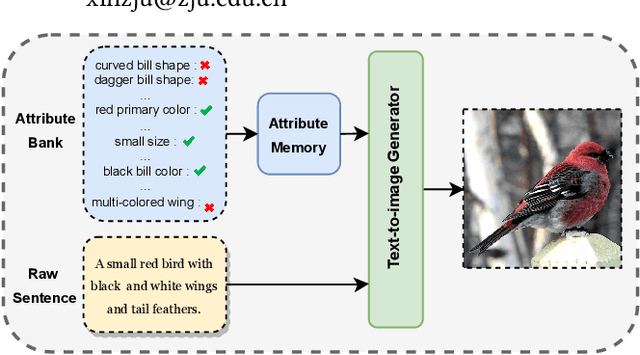
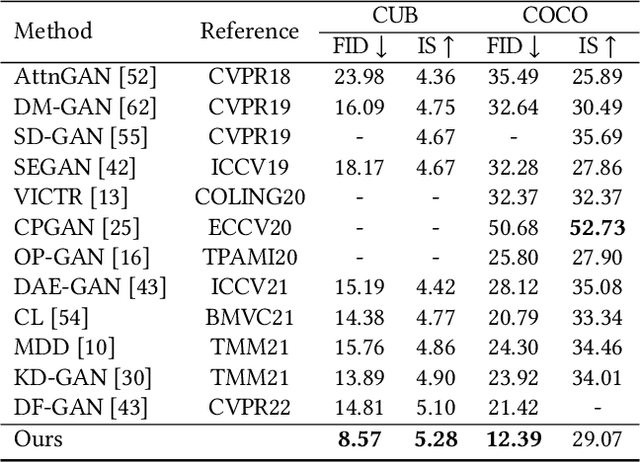
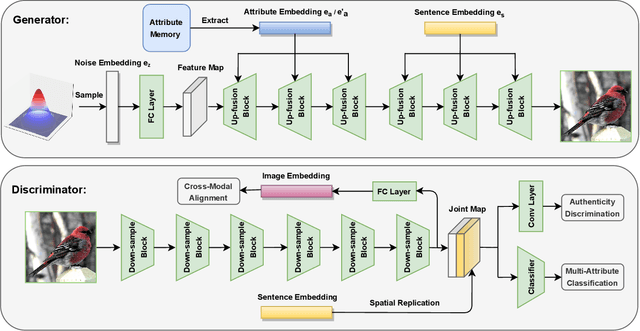
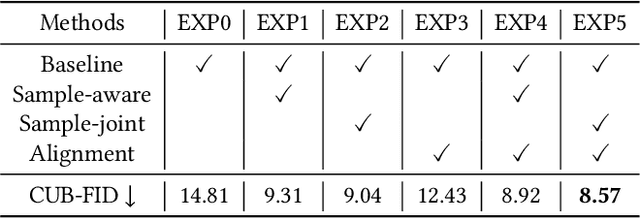
As a challenging task, text-to-image generation aims to generate photo-realistic and semantically consistent images according to the given text descriptions. Existing methods mainly extract the text information from only one sentence to represent an image and the text representation effects the quality of the generated image well. However, directly utilizing the limited information in one sentence misses some key attribute descriptions, which are the crucial factors to describe an image accurately. To alleviate the above problem, we propose an effective text representation method with the complements of attribute information. Firstly, we construct an attribute memory to jointly control the text-to-image generation with sentence input. Secondly, we explore two update mechanisms, sample-aware and sample-joint mechanisms, to dynamically optimize a generalized attribute memory. Furthermore, we design an attribute-sentence-joint conditional generator learning scheme to align the feature embeddings among multiple representations, which promotes the cross-modal network training. Experimental results illustrate that the proposed method obtains substantial performance improvements on both the CUB (FID from 14.81 to 8.57) and COCO (FID from 21.42 to 12.39) datasets.
UniFormer: Unified Multi-view Fusion Transformer for Spatial-Temporal Representation in Bird's-Eye-View
Jul 18, 2022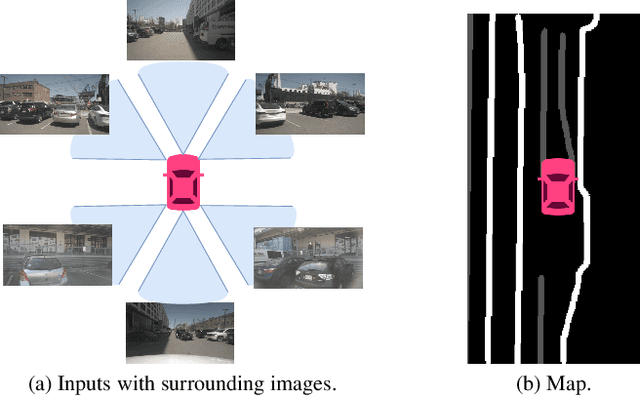

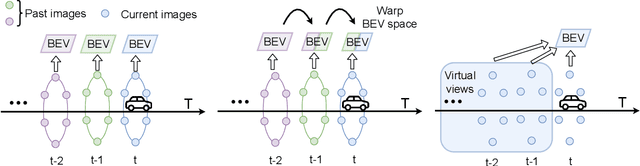
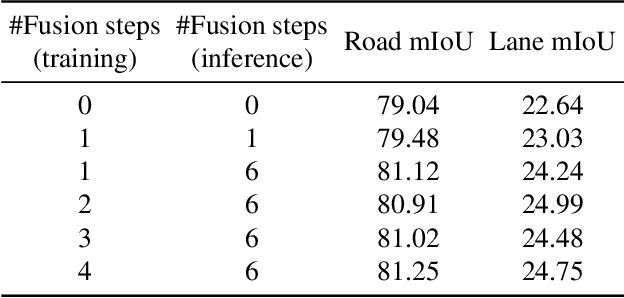
Bird's eye view (BEV) representation is a new perception formulation for autonomous driving, which is based on spatial fusion. Further, temporal fusion is also introduced in BEV representation and gains great success. In this work, we propose a new method that unifies both spatial and temporal fusion and merges them into a unified mathematical formulation. The unified fusion could not only provide a new perspective on BEV fusion but also brings new capabilities. With the proposed unified spatial-temporal fusion, our method could support long-range fusion, which is hard to achieve in conventional BEV methods. Moreover, the BEV fusion in our work is temporal-adaptive, and the weights of temporal fusion are learnable. In contrast, conventional methods mainly use fixed and equal weights for temporal fusion. Besides, the proposed unified fusion could avoid information lost in conventional BEV fusion methods and make full use of features. Extensive experiments and ablation studies on the NuScenes dataset show the effectiveness of the proposed method and our method gains the state-of-the-art performance in the map segmentation task.
Dynamic Low-Resolution Distillation for Cost-Efficient End-to-End Text Spotting
Jul 15, 2022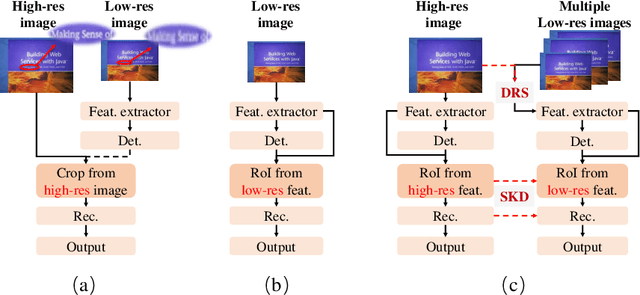
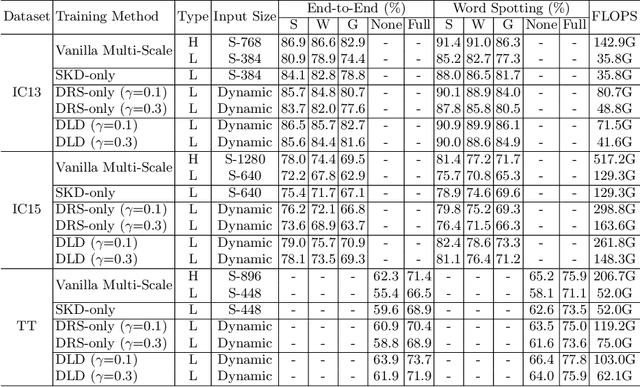
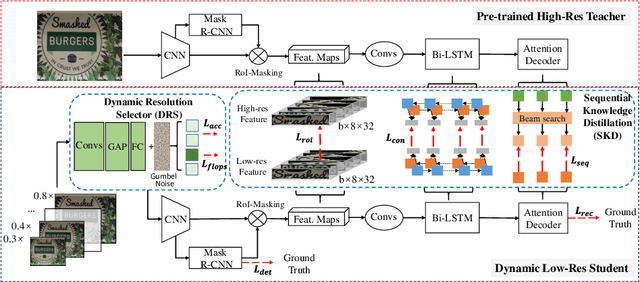
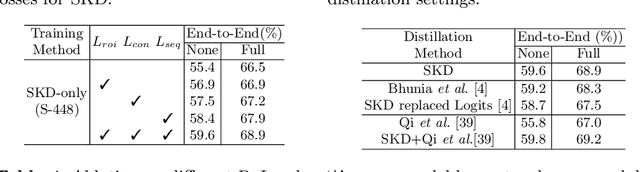
End-to-end text spotting has attached great attention recently due to its benefits on global optimization and high maintainability for real applications. However, the input scale has always been a tough trade-off since recognizing a small text instance usually requires enlarging the whole image, which brings high computational costs. In this paper, to address this problem, we propose a novel cost-efficient Dynamic Low-resolution Distillation (DLD) text spotting framework, which aims to infer images in different small but recognizable resolutions and achieve a better balance between accuracy and efficiency. Concretely, we adopt a resolution selector to dynamically decide the input resolutions for different images, which is constraint by both inference accuracy and computational cost. Another sequential knowledge distillation strategy is conducted on the text recognition branch, making the low-res input obtains comparable performance to a high-res image. The proposed method can be optimized end-to-end and adopted in any current text spotting framework to improve the practicability. Extensive experiments on several text spotting benchmarks show that the proposed method vastly improves the usability of low-res models. The code is available at https://github.com/hikopensource/DAVAR-Lab-OCR/.
Entropy-driven Sampling and Training Scheme for Conditional Diffusion Generation
Jun 27, 2022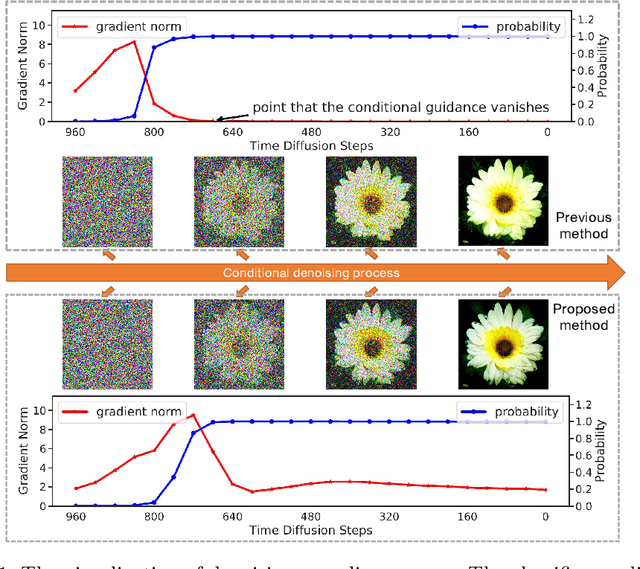
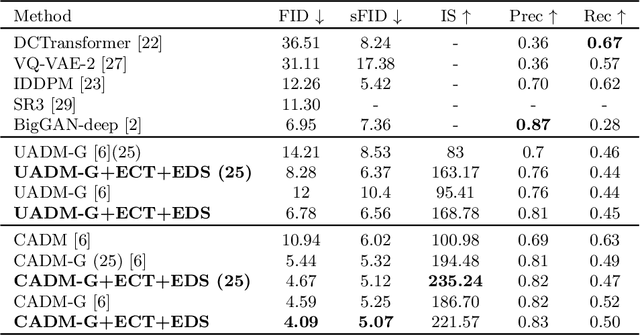
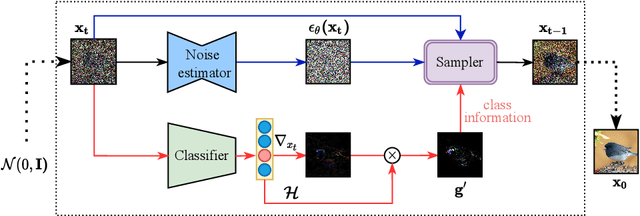
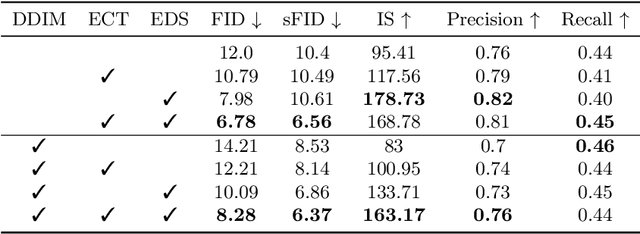
Denoising Diffusion Probabilistic Model (DDPM) is able to make flexible conditional image generation from prior noise to real data, by introducing an independent noise-aware classifier to provide conditional gradient guidance at each time step of denoising process. However, due to the ability of classifier to easily discriminate an incompletely generated image only with high-level structure, the gradient, which is a kind of class information guidance, tends to vanish early, leading to the collapse from conditional generation process into the unconditional process. To address this problem, we propose two simple but effective approaches from two perspectives. For sampling procedure, we introduce the entropy of predicted distribution as the measure of guidance vanishing level and propose an entropy-aware scaling method to adaptively recover the conditional semantic guidance. For training stage, we propose the entropy-aware optimization objectives to alleviate the overconfident prediction for noisy data.On ImageNet1000 256x256, with our proposed sampling scheme and trained classifier, the pretrained conditional and unconditional DDPM model can achieve 10.89% (4.59 to 4.09) and 43.5% (12 to 6.78) FID improvement respectively.
Ultra Fast Deep Lane Detection with Hybrid Anchor Driven Ordinal Classification
Jun 15, 2022
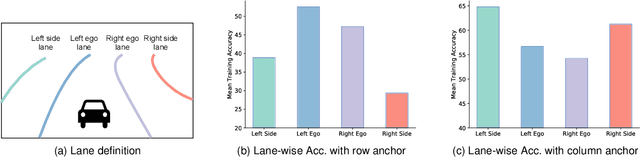

Modern methods mainly regard lane detection as a problem of pixel-wise segmentation, which is struggling to address the problems of efficiency and challenging scenarios like severe occlusions and extreme lighting conditions. Inspired by human perception, the recognition of lanes under severe occlusions and extreme lighting conditions is mainly based on contextual and global information. Motivated by this observation, we propose a novel, simple, yet effective formulation aiming at ultra fast speed and the problem of challenging scenarios. Specifically, we treat the process of lane detection as an anchor-driven ordinal classification problem using global features. First, we represent lanes with sparse coordinates on a series of hybrid (row and column) anchors. With the help of the anchor-driven representation, we then reformulate the lane detection task as an ordinal classification problem to get the coordinates of lanes. Our method could significantly reduce the computational cost with the anchor-driven representation. Using the large receptive field property of the ordinal classification formulation, we could also handle challenging scenarios. Extensive experiments on four lane detection datasets show that our method could achieve state-of-the-art performance in terms of both speed and accuracy. A lightweight version could even achieve 300+ frames per second(FPS). Our code is at https://github.com/cfzd/Ultra-Fast-Lane-Detection-v2.
MonoGround: Detecting Monocular 3D Objects from the Ground
Jun 15, 2022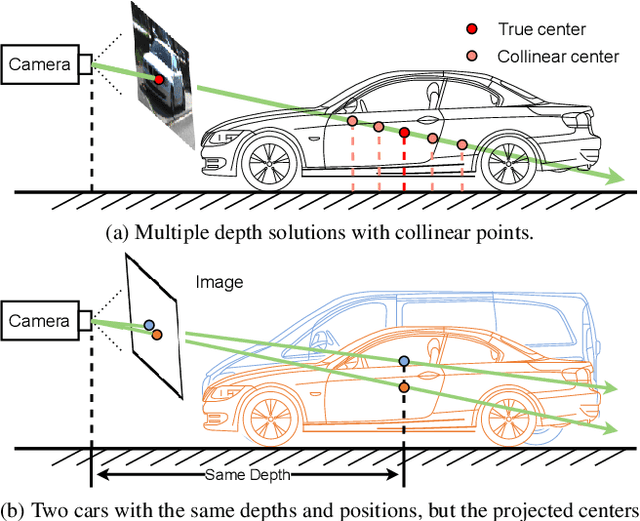
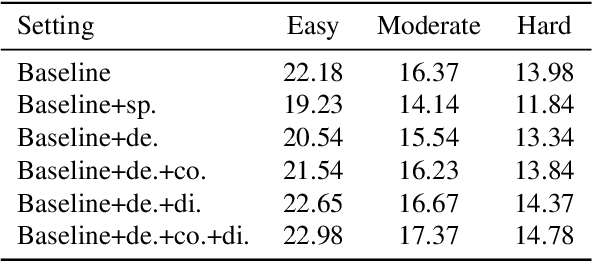
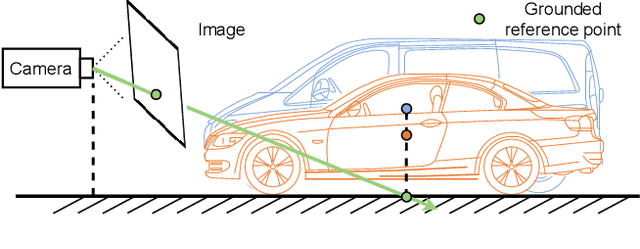
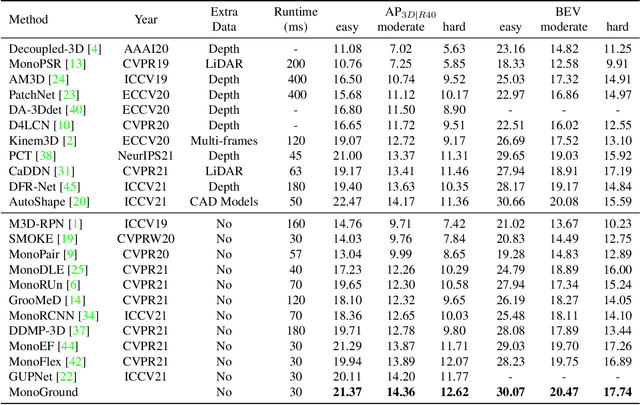
Monocular 3D object detection has attracted great attention for its advantages in simplicity and cost. Due to the ill-posed 2D to 3D mapping essence from the monocular imaging process, monocular 3D object detection suffers from inaccurate depth estimation and thus has poor 3D detection results. To alleviate this problem, we propose to introduce the ground plane as a prior in the monocular 3d object detection. The ground plane prior serves as an additional geometric condition to the ill-posed mapping and an extra source in depth estimation. In this way, we can get a more accurate depth estimation from the ground. Meanwhile, to take full advantage of the ground plane prior, we propose a depth-align training strategy and a precise two-stage depth inference method tailored for the ground plane prior. It is worth noting that the introduced ground plane prior requires no extra data sources like LiDAR, stereo images, and depth information. Extensive experiments on the KITTI benchmark show that our method could achieve state-of-the-art results compared with other methods while maintaining a very fast speed. Our code and models are available at https://github.com/cfzd/MonoGround.
F3A-GAN: Facial Flow for Face Animation with Generative Adversarial Networks
May 13, 2022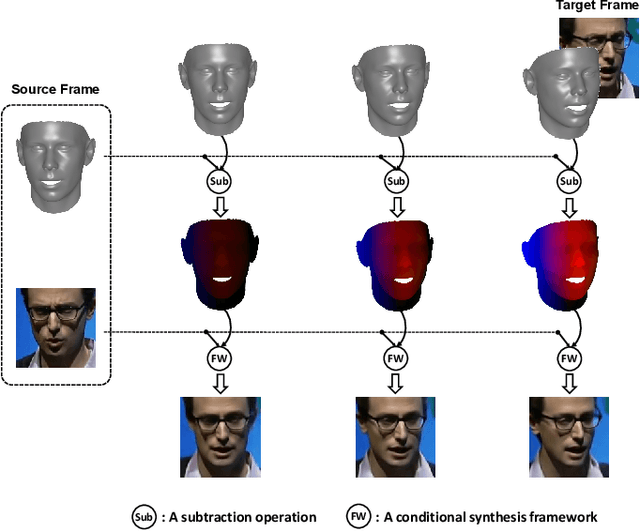



Formulated as a conditional generation problem, face animation aims at synthesizing continuous face images from a single source image driven by a set of conditional face motion. Previous works mainly model the face motion as conditions with 1D or 2D representation (e.g., action units, emotion codes, landmark), which often leads to low-quality results in some complicated scenarios such as continuous generation and largepose transformation. To tackle this problem, the conditions are supposed to meet two requirements, i.e., motion information preserving and geometric continuity. To this end, we propose a novel representation based on a 3D geometric flow, termed facial flow, to represent the natural motion of the human face at any pose. Compared with other previous conditions, the proposed facial flow well controls the continuous changes to the face. After that, in order to utilize the facial flow for face editing, we build a synthesis framework generating continuous images with conditional facial flows. To fully take advantage of the motion information of facial flows, a hierarchical conditional framework is designed to combine the extracted multi-scale appearance features from images and motion features from flows in a hierarchical manner. The framework then decodes multiple fused features back to images progressively. Experimental results demonstrate the effectiveness of our method compared to other state-of-the-art methods.