 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue
May 12, 2022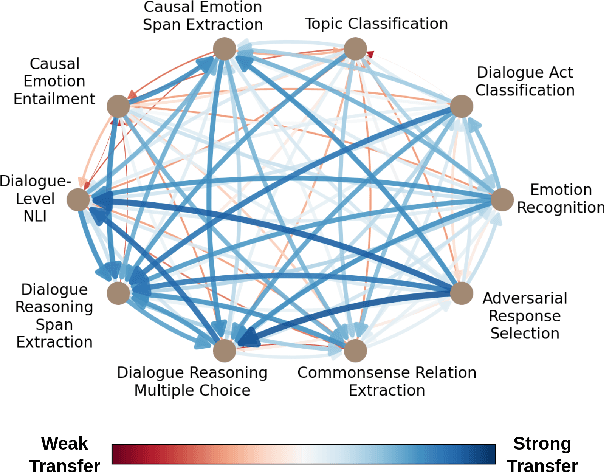
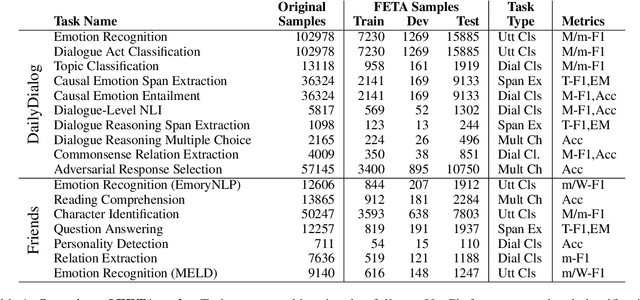
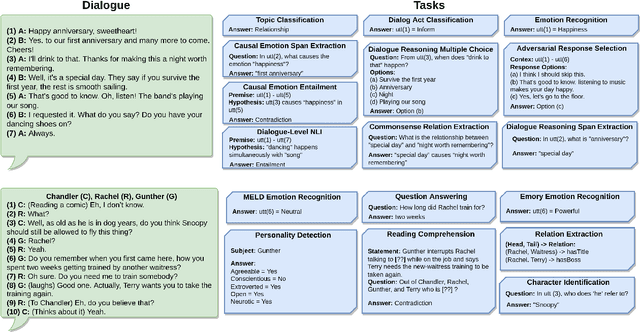

Task transfer, transferring knowledge contained in related tasks, holds the promise of reducing the quantity of labeled data required to fine-tune language models. Dialogue understanding encompasses many diverse tasks, yet task transfer has not been thoroughly studied in conversational AI. This work explores conversational task transfer by introducing FETA: a benchmark for few-sample task transfer in open-domain dialogue. FETA contains two underlying sets of conversations upon which there are 10 and 7 tasks annotated, enabling the study of intra-dataset task transfer; task transfer without domain adaptation. We utilize three popular language models and three learning algorithms to analyze the transferability between 132 source-target task pairs and create a baseline for future work. We run experiments in the single- and multi-source settings and report valuable findings, e.g., most performance trends are model-specific, and span extraction and multiple-choice tasks benefit the most from task transfer. In addition to task transfer, FETA can be a valuable resource for future research into the efficiency and generalizability of pre-training datasets and model architectures, as well as for learning settings such as continual and multitask learning.
KETOD: Knowledge-Enriched Task-Oriented Dialogue
May 11, 2022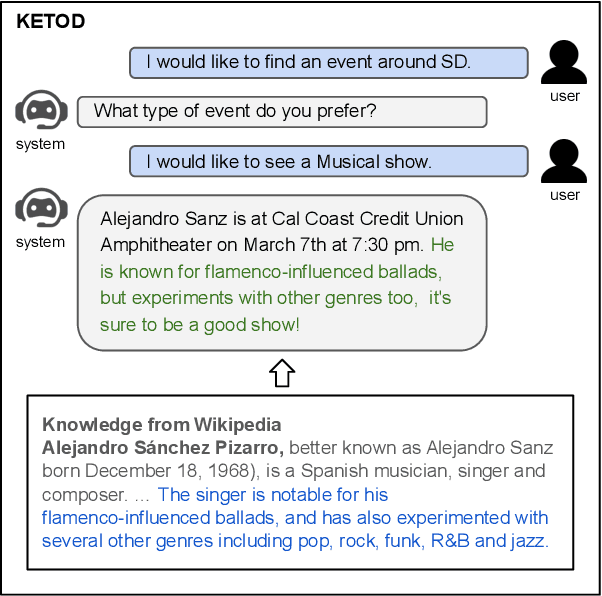

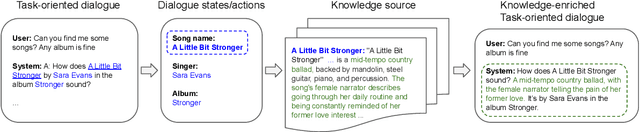
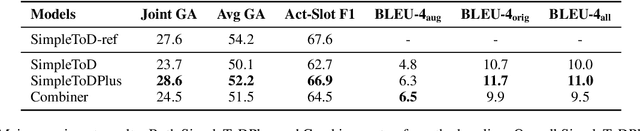
Existing studies in dialogue system research mostly treat task-oriented dialogue and chit-chat as separate domains. Towards building a human-like assistant that can converse naturally and seamlessly with users, it is important to build a dialogue system that conducts both types of conversations effectively. In this work, we investigate how task-oriented dialogue and knowledge-grounded chit-chat can be effectively integrated into a single model. To this end, we create a new dataset, KETOD (Knowledge-Enriched Task-Oriented Dialogue), where we naturally enrich task-oriented dialogues with chit-chat based on relevant entity knowledge. We also propose two new models, SimpleToDPlus and Combiner, for the proposed task. Experimental results on both automatic and human evaluations show that the proposed methods can significantly improve the performance in knowledge-enriched response generation while maintaining a competitive task-oriented dialog performance. We believe our new dataset will be a valuable resource for future studies. Our dataset and code are publicly available at \url{https://github.com/facebookresearch/ketod}.
HybriDialogue: An Information-Seeking Dialogue Dataset Grounded on Tabular and Textual Data
Apr 28, 2022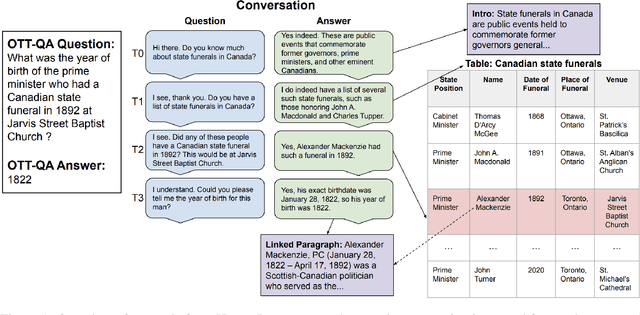
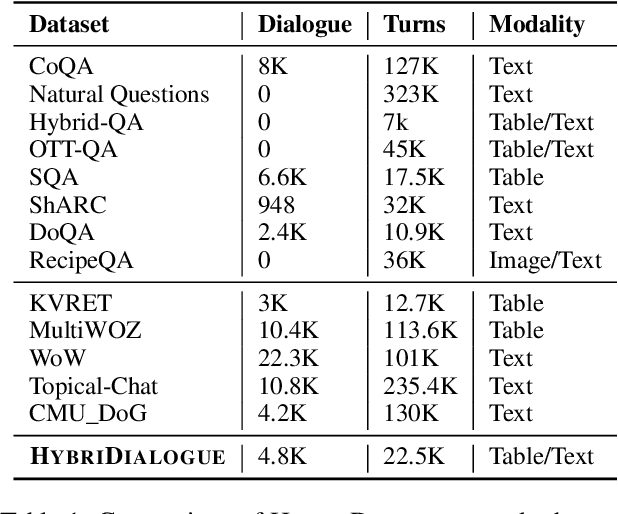
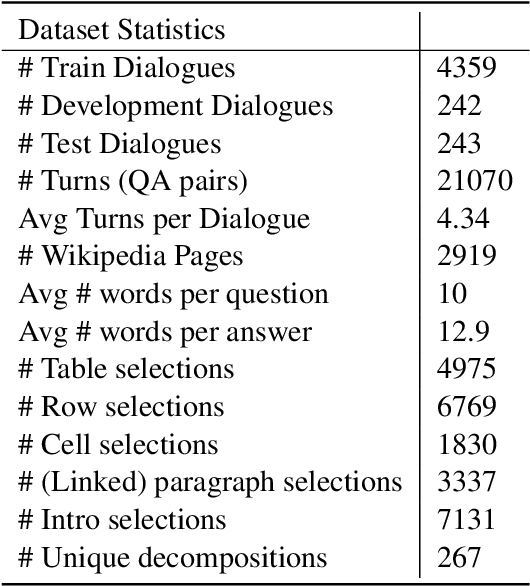
A pressing challenge in current dialogue systems is to successfully converse with users on topics with information distributed across different modalities. Previous work in multiturn dialogue systems has primarily focused on either text or table information. In more realistic scenarios, having a joint understanding of both is critical as knowledge is typically distributed over both unstructured and structured forms. We present a new dialogue dataset, HybriDialogue, which consists of crowdsourced natural conversations grounded on both Wikipedia text and tables. The conversations are created through the decomposition of complex multihop questions into simple, realistic multiturn dialogue interactions. We propose retrieval, system state tracking, and dialogue response generation tasks for our dataset and conduct baseline experiments for each. Our results show that there is still ample opportunity for improvement, demonstrating the importance of building stronger dialogue systems that can reason over the complex setting of information-seeking dialogue grounded on tables and text.
Imagination-Augmented Natural Language Understanding
Apr 21, 2022
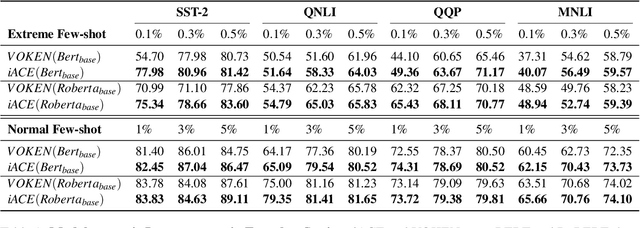
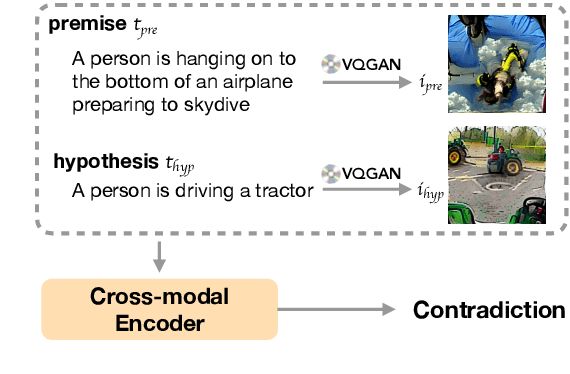
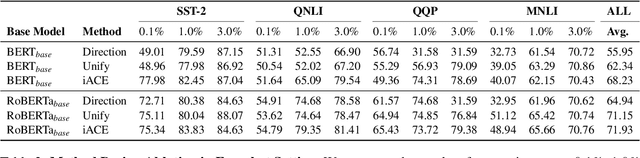
Human brains integrate linguistic and perceptual information simultaneously to understand natural language, and hold the critical ability to render imaginations. Such abilities enable us to construct new abstract concepts or concrete objects, and are essential in involving practical knowledge to solve problems in low-resource scenarios. However, most existing methods for Natural Language Understanding (NLU) are mainly focused on textual signals. They do not simulate human visual imagination ability, which hinders models from inferring and learning efficiently from limited data samples. Therefore, we introduce an Imagination-Augmented Cross-modal Encoder (iACE) to solve natural language understanding tasks from a novel learning perspective -- imagination-augmented cross-modal understanding. iACE enables visual imagination with external knowledge transferred from the powerful generative and pre-trained vision-and-language models. Extensive experiments on GLUE and SWAG show that iACE achieves consistent improvement over visually-supervised pre-trained models. More importantly, results in extreme and normal few-shot settings validate the effectiveness of iACE in low-resource natural language understanding circumstances.
End-to-end Dense Video Captioning as Sequence Generation
Apr 18, 2022

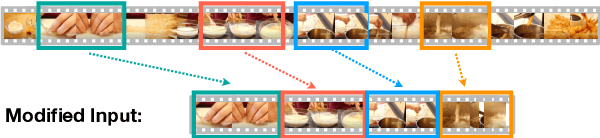
Dense video captioning aims to identify the events of interest in an input video, and generate descriptive captions for each event. Previous approaches usually follow a two-stage generative process, which first proposes a segment for each event, then renders a caption for each identified segment. Recent advances in large-scale sequence generation pretraining have seen great success in unifying task formulation for a great variety of tasks, but so far, more complex tasks such as dense video captioning are not able to fully utilize this powerful paradigm. In this work, we show how to model the two subtasks of dense video captioning jointly as one sequence generation task, and simultaneously predict the events and the corresponding descriptions. Experiments on YouCook2 and ViTT show encouraging results and indicate the feasibility of training complex tasks such as end-to-end dense video captioning integrated into large-scale pre-trained models.
Towards Large-Scale Interpretable Knowledge Graph Reasoning for Dialogue Systems
Mar 20, 2022
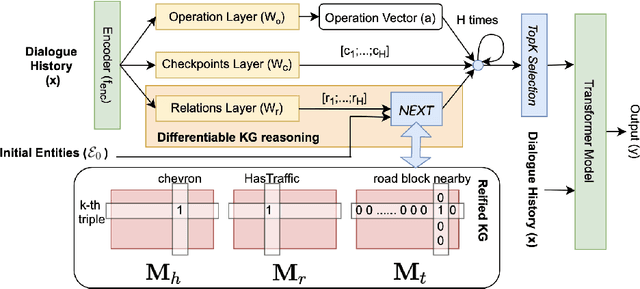
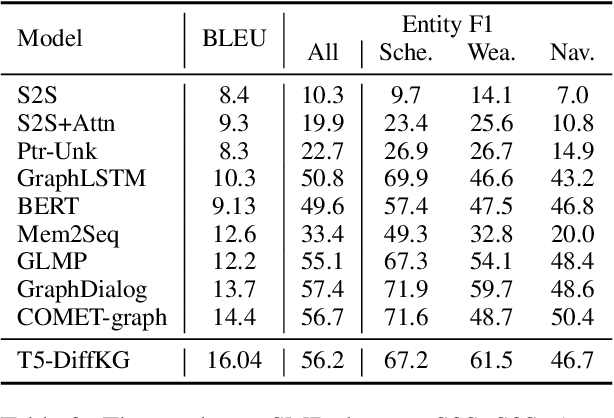
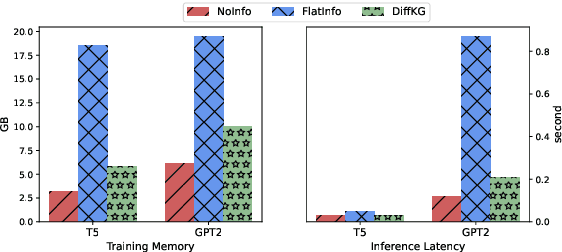
Users interacting with voice assistants today need to phrase their requests in a very specific manner to elicit an appropriate response. This limits the user experience, and is partly due to the lack of reasoning capabilities of dialogue platforms and the hand-crafted rules that require extensive labor. One possible way to improve user experience and relieve the manual efforts of designers is to build an end-to-end dialogue system that can do reasoning itself while perceiving user's utterances. In this work, we propose a novel method to incorporate the knowledge reasoning capability into dialogue systems in a more scalable and generalizable manner. Our proposed method allows a single transformer model to directly walk on a large-scale knowledge graph to generate responses. To the best of our knowledge, this is the first work to have transformer models generate responses by reasoning over differentiable knowledge graphs. We investigate the reasoning abilities of the proposed method on both task-oriented and domain-specific chit-chat dialogues. Empirical results show that this method can effectively and efficiently incorporate a knowledge graph into a dialogue system with fully-interpretable reasoning paths.
Addressing Issues of Cross-Linguality in Open-Retrieval Question Answering Systems For Emergent Domains
Jan 26, 2022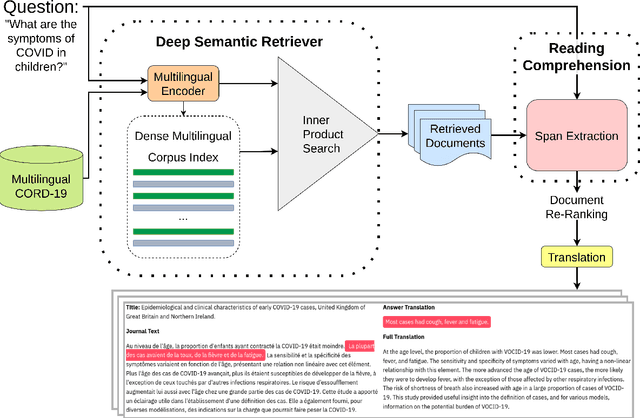
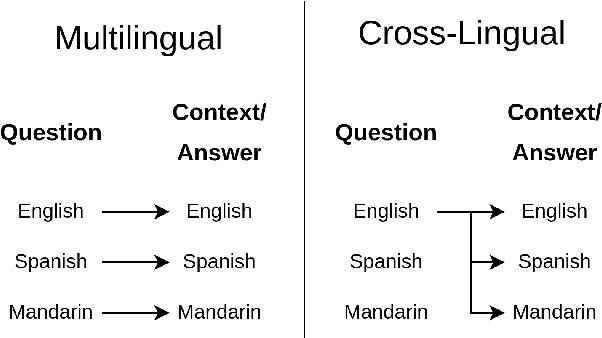

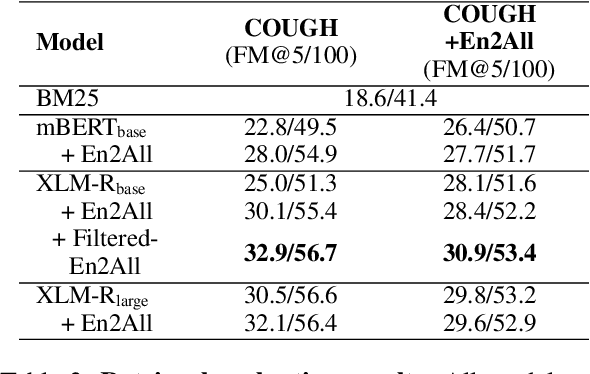
Open-retrieval question answering systems are generally trained and tested on large datasets in well-established domains. However, low-resource settings such as new and emerging domains would especially benefit from reliable question answering systems. Furthermore, multilingual and cross-lingual resources in emergent domains are scarce, leading to few or no such systems. In this paper, we demonstrate a cross-lingual open-retrieval question answering system for the emergent domain of COVID-19. Our system adopts a corpus of scientific articles to ensure that retrieved documents are reliable. To address the scarcity of cross-lingual training data in emergent domains, we present a method utilizing automatic translation, alignment, and filtering to produce English-to-all datasets. We show that a deep semantic retriever greatly benefits from training on our English-to-all data and significantly outperforms a BM25 baseline in the cross-lingual setting. We illustrate the capabilities of our system with examples and release all code necessary to train and deploy such a system.
Automatically Identifying Semantic Bias in Crowdsourced Natural Language Inference Datasets
Dec 16, 2021
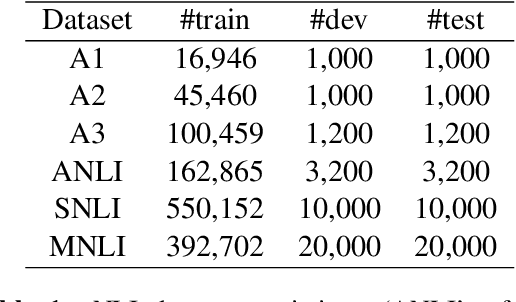
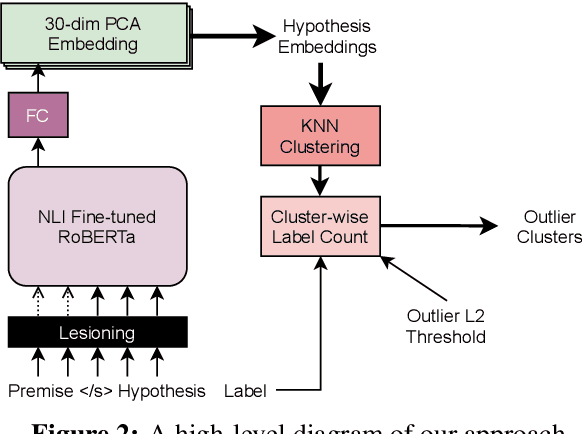
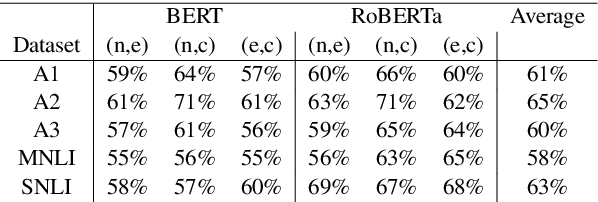
Natural language inference (NLI) is an important task for producing useful models of human language. Unfortunately large-scale NLI dataset production relies on crowdworkers who are prone to introduce biases in the sentences they write. In particular, without quality control they produce hypotheses from which the relational label can be predicted, without the premise, better than chance. We introduce a model-driven, unsupervised technique to find "bias clusters" in a learned embedding space of the hypotheses in NLI datasets, from which interventions and additional rounds of labeling can be performed to ameliorate the semantic bias of the hypothesis distribution of a dataset.
Relational Graph Learning for Grounded Video Description Generation
Dec 02, 2021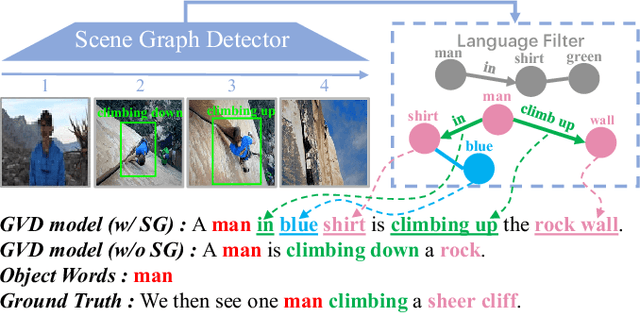
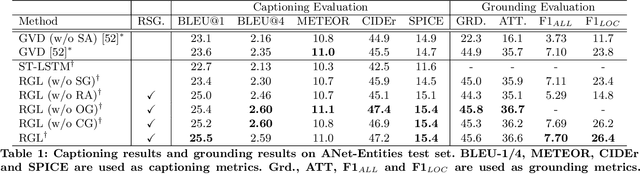
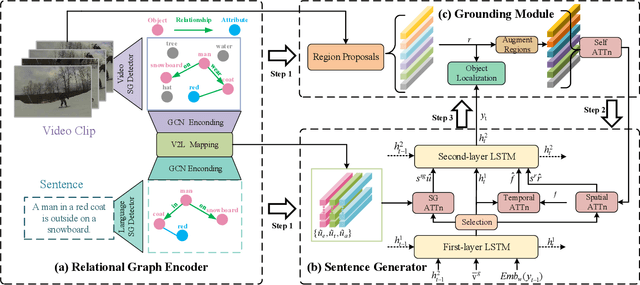
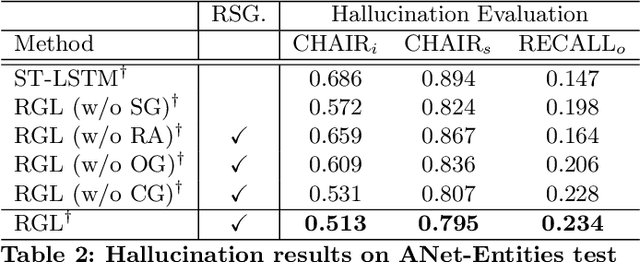
Grounded video description (GVD) encourages captioning models to attend to appropriate video regions (e.g., objects) dynamically and generate a description. Such a setting can help explain the decisions of captioning models and prevents the model from hallucinating object words in its description. However, such design mainly focuses on object word generation and thus may ignore fine-grained information and suffer from missing visual concepts. Moreover, relational words (e.g., "jump left or right") are usual spatio-temporal inference results, i.e., these words cannot be grounded on certain spatial regions. To tackle the above limitations, we design a novel relational graph learning framework for GVD, in which a language-refined scene graph representation is designed to explore fine-grained visual concepts. Furthermore, the refined graph can be regarded as relational inductive knowledge to assist captioning models in selecting the relevant information it needs to generate correct words. We validate the effectiveness of our model through automatic metrics and human evaluation, and the results indicate that our approach can generate more fine-grained and accurate description, and it solves the problem of object hallucination to some extent.
VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling
Nov 24, 2021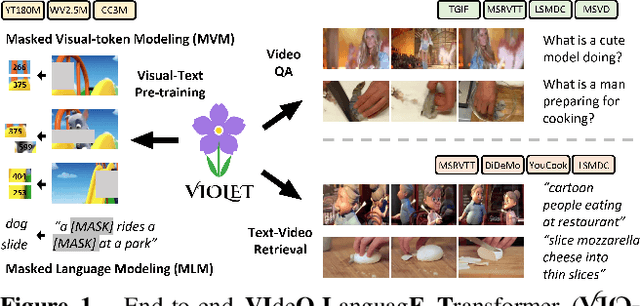
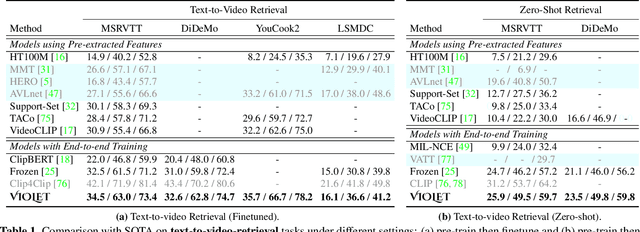
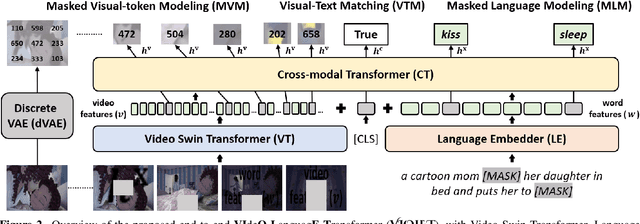
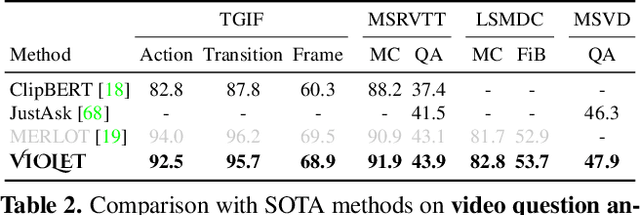
A great challenge in video-language (VidL) modeling lies in the disconnection between fixed video representations extracted from image/video understanding models and downstream VidL data. Recent studies try to mitigate this disconnection via end-to-end training. To make it computationally feasible, prior works tend to "imagify" video inputs, i.e., a handful of sparsely sampled frames are fed into a 2D CNN, followed by a simple mean-pooling or concatenation to obtain the overall video representations. Although achieving promising results, such simple approaches may lose temporal information that is essential for performing downstream VidL tasks. In this work, we present VIOLET, a fully end-to-end VIdeO-LanguagE Transformer, which adopts a video transformer to explicitly model the temporal dynamics of video inputs. Further, unlike previous studies that found pre-training tasks on video inputs (e.g., masked frame modeling) not very effective, we design a new pre-training task, Masked Visual-token Modeling (MVM), for better video modeling. Specifically, the original video frame patches are "tokenized" into discrete visual tokens, and the goal is to recover the original visual tokens based on the masked patches. Comprehensive analysis demonstrates the effectiveness of both explicit temporal modeling via video transformer and MVM. As a result, VIOLET achieves new state-of-the-art performance on 5 video question answering tasks and 4 text-to-video retrieval tasks.