 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Dimensional Non-Line-of-Sight Scene Estimation from a Single Edge Occluder
Jun 16, 2020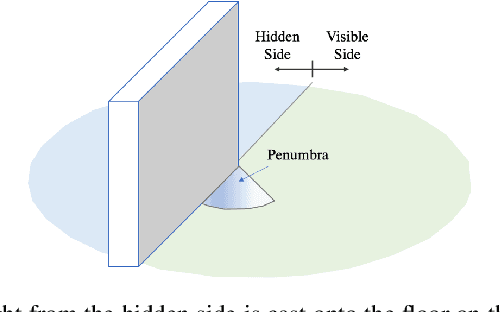
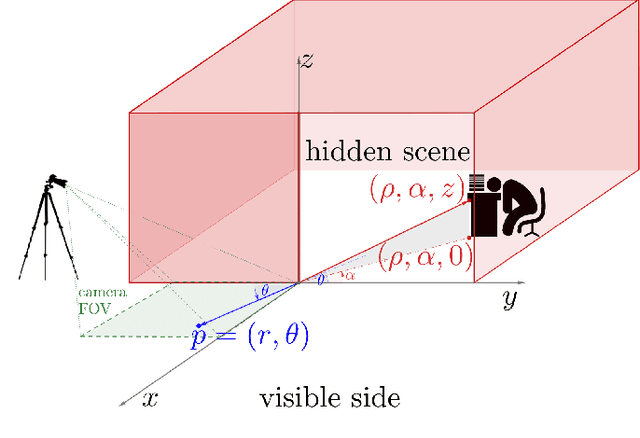
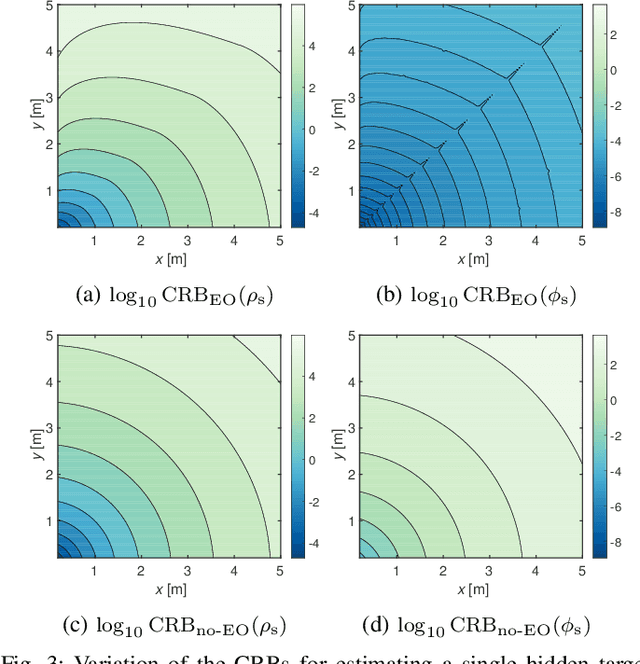
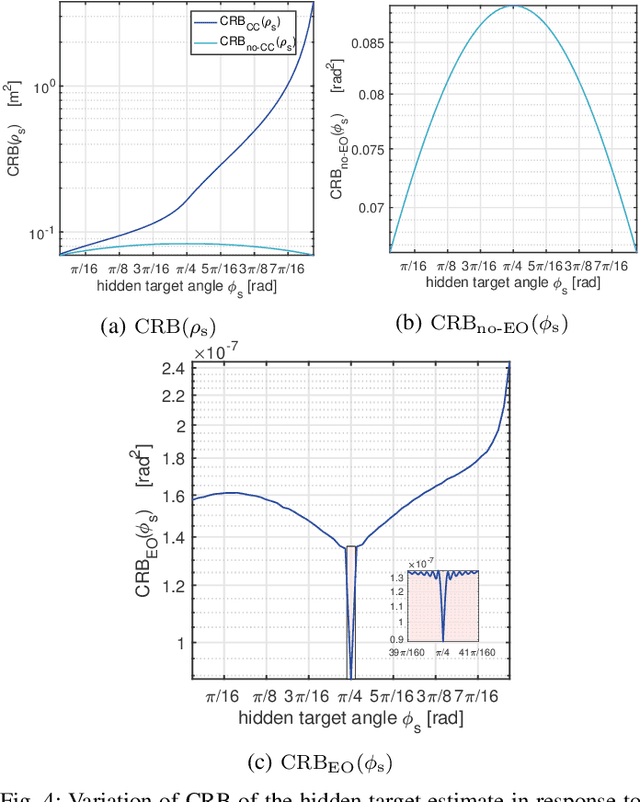
Passive non-line-of-sight imaging methods are often faster and stealthier than their active counterparts, requiring less complex and costly equipment. However, many of these methods exploit motion of an occluder or the hidden scene, or require knowledge or calibration of complicated occluders. The edge of a wall is a known and ubiquitous occluding structure that may be used as an aperture to image the region hidden behind it. Light from around the corner is cast onto the floor forming a fan-like penumbra rather than a sharp shadow. Subtle variations in the penumbra contain a remarkable amount of information about the hidden scene. Previous work has leveraged the vertical nature of the edge to demonstrate 1D (in angle measured around the corner) reconstructions of moving and stationary hidden scenery from as little as a single photograph of the penumbra. In this work, we introduce a second reconstruction dimension: range measured from the edge. We derive a new forward model, accounting for radial falloff, and propose two inversion algorithms to form 2D reconstructions from a single photograph of the penumbra. Performances of both algorithms are demonstrated on experimental data corresponding to several different hidden scene configurations. A Cramer-Rao bound analysis further demonstrates the feasibility (and utility) of the 2D corner camera.
SpeedNet: Learning the Speediness in Videos
Apr 13, 2020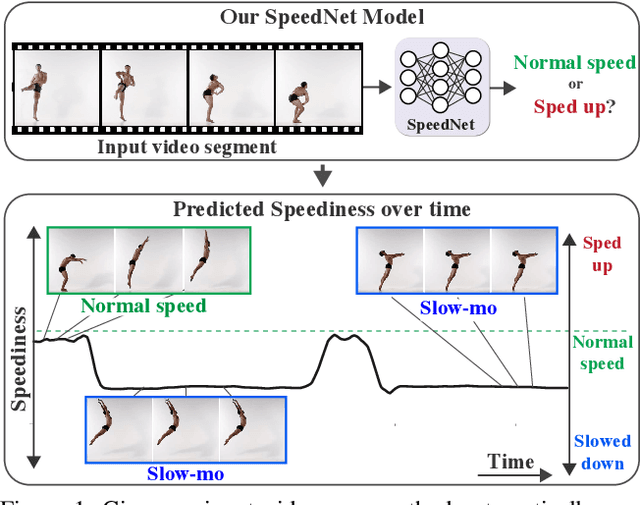
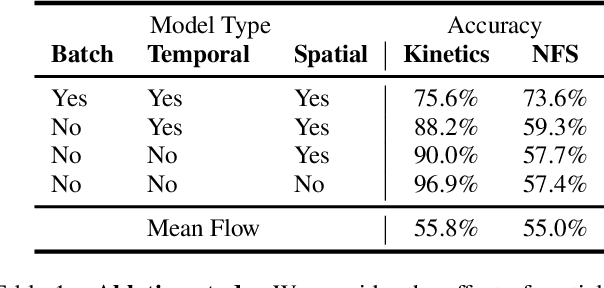
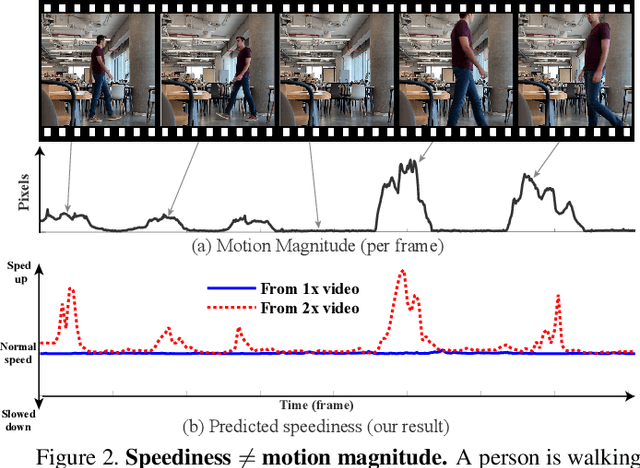
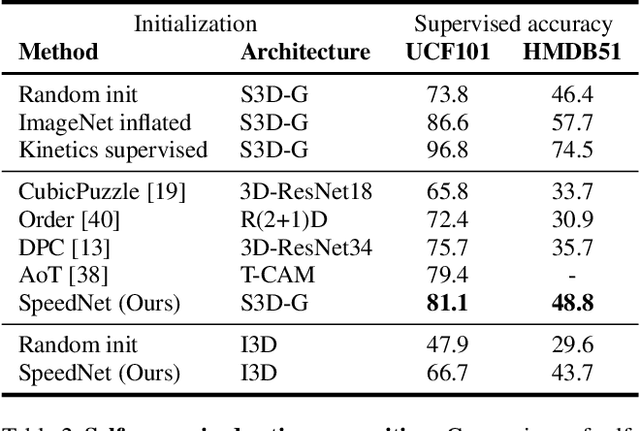
We wish to automatically predict the "speediness" of moving objects in videos---whether they move faster, at, or slower than their "natural" speed. The core component in our approach is SpeedNet---a novel deep network trained to detect if a video is playing at normal rate, or if it is sped up. SpeedNet is trained on a large corpus of natural videos in a self-supervised manner, without requiring any manual annotations. We show how this single, binary classification network can be used to detect arbitrary rates of speediness of objects. We demonstrate prediction results by SpeedNet on a wide range of videos containing complex natural motions, and examine the visual cues it utilizes for making those predictions. Importantly, we show that through predicting the speed of videos, the model learns a powerful and meaningful space-time representation that goes beyond simple motion cues. We demonstrate how those learned features can boost the performance of self-supervised action recognition, and can be used for video retrieval. Furthermore, we also apply SpeedNet for generating time-varying, adaptive video speedups, which can allow viewers to watch videos faster, but with less of the jittery, unnatural motions typical to videos that are sped up uniformly.
Semantic Pyramid for Image Generation
Mar 16, 2020

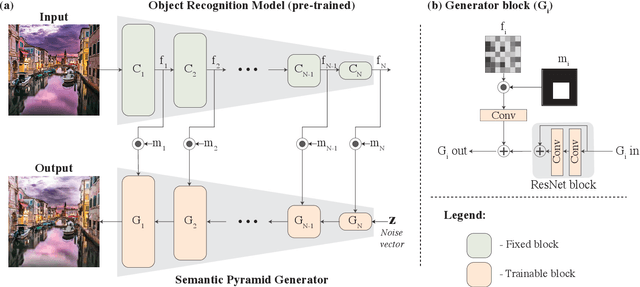
We present a novel GAN-based model that utilizes the space of deep features learned by a pre-trained classification model. Inspired by classical image pyramid representations, we construct our model as a Semantic Generation Pyramid -- a hierarchical framework which leverages the continuum of semantic information encapsulated in such deep features; this ranges from low level information contained in fine features to high level, semantic information contained in deeper features. More specifically, given a set of features extracted from a reference image, our model generates diverse image samples, each with matching features at each semantic level of the classification model. We demonstrate that our model results in a versatile and flexible framework that can be used in various classic and novel image generation tasks. These include: generating images with a controllable extent of semantic similarity to a reference image, and different manipulation tasks such as semantically-controlled inpainting and compositing; all achieved with the same model, with no further training.
Computational Mirrors: Blind Inverse Light Transport by Deep Matrix Factorization
Dec 05, 2019

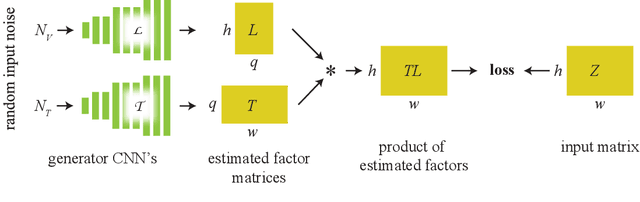

We recover a video of the motion taking place in a hidden scene by observing changes in indirect illumination in a nearby uncalibrated visible region. We solve this problem by factoring the observed video into a matrix product between the unknown hidden scene video and an unknown light transport matrix. This task is extremely ill-posed, as any non-negative factorization will satisfy the data. Inspired by recent work on the Deep Image Prior, we parameterize the factor matrices using randomly initialized convolutional neural networks trained in a one-off manner, and show that this results in decompositions that reflect the true motion in the hidden scene.
* 14 pages, 5 figures, Advances in Neural Information Processing Systems 2019
Program-Guided Image Manipulators
Sep 04, 2019

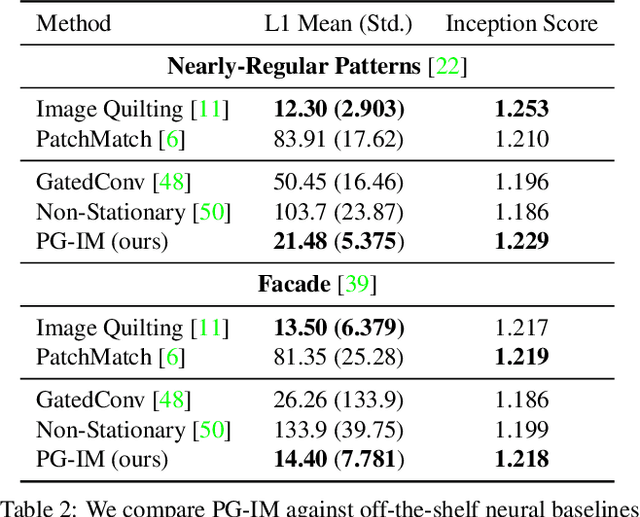

Humans are capable of building holistic representations for images at various levels, from local objects, to pairwise relations, to global structures. The interpretation of structures involves reasoning over repetition and symmetry of the objects in the image. In this paper, we present the Program-Guided Image Manipulator (PG-IM), inducing neuro-symbolic program-like representations to represent and manipulate images. Given an image, PG-IM detects repeated patterns, induces symbolic programs, and manipulates the image using a neural network that is guided by the program. PG-IM learns from a single image, exploiting its internal statistics. Despite trained only on image inpainting, PG-IM is directly capable of extrapolation and regularity editing in a unified framework. Extensive experiments show that PG-IM achieves superior performance on all the tasks.
Visual Deprojection: Probabilistic Recovery of Collapsed Dimensions
Sep 01, 2019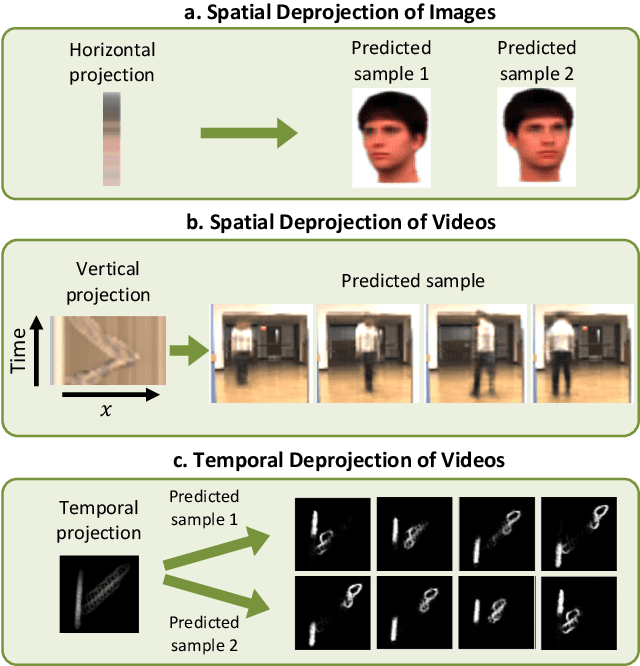
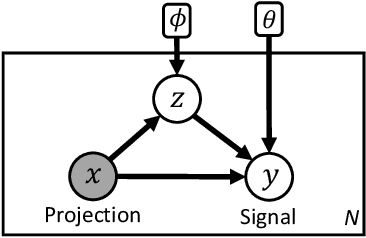
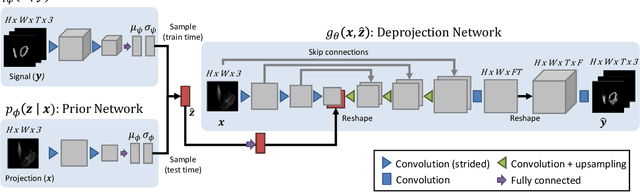

We introduce visual deprojection: the task of recovering an image or video that has been collapsed along a dimension. Projections arise in various contexts, such as long-exposure photography, where a dynamic scene is collapsed in time to produce a motion-blurred image, and corner cameras, where reflected light from a scene is collapsed along a spatial dimension because of an edge occluder to yield a 1D video. Deprojection is ill-posed-- often there are many plausible solutions for a given input. We first propose a probabilistic model capturing the ambiguity of the task. We then present a variational inference strategy using convolutional neural networks as functional approximators. Sampling from the inference network at test time yields plausible candidates from the distribution of original signals that are consistent with a given input projection. We evaluate the method on several datasets for both spatial and temporal deprojection tasks. We first demonstrate the method can recover human gait videos and face images from spatial projections, and then show that it can recover videos of moving digits from dramatically motion-blurred images obtained via temporal projection.
Boundless: Generative Adversarial Networks for Image Extension
Aug 19, 2019
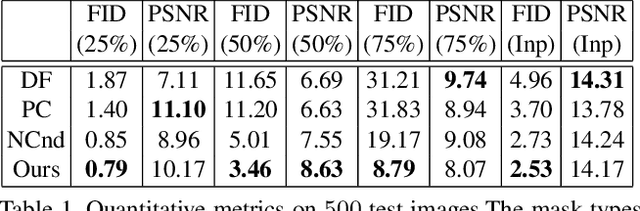
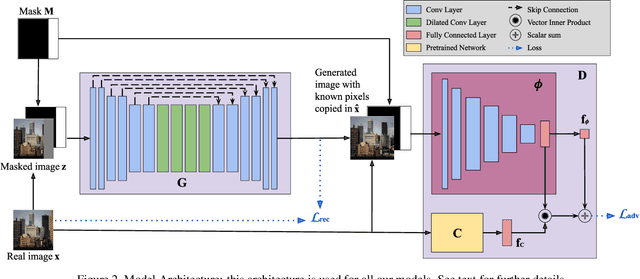
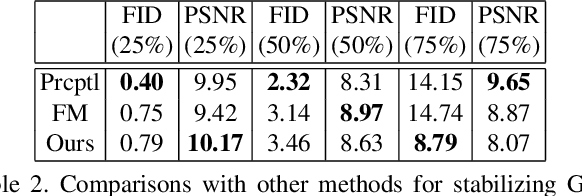
Image extension models have broad applications in image editing, computational photography and computer graphics. While image inpainting has been extensively studied in the literature, it is challenging to directly apply the state-of-the-art inpainting methods to image extension as they tend to generate blurry or repetitive pixels with inconsistent semantics. We introduce semantic conditioning to the discriminator of a generative adversarial network (GAN), and achieve strong results on image extension with coherent semantics and visually pleasing colors and textures. We also show promising results in extreme extensions, such as panorama generation.
Speech2Face: Learning the Face Behind a Voice
May 23, 2019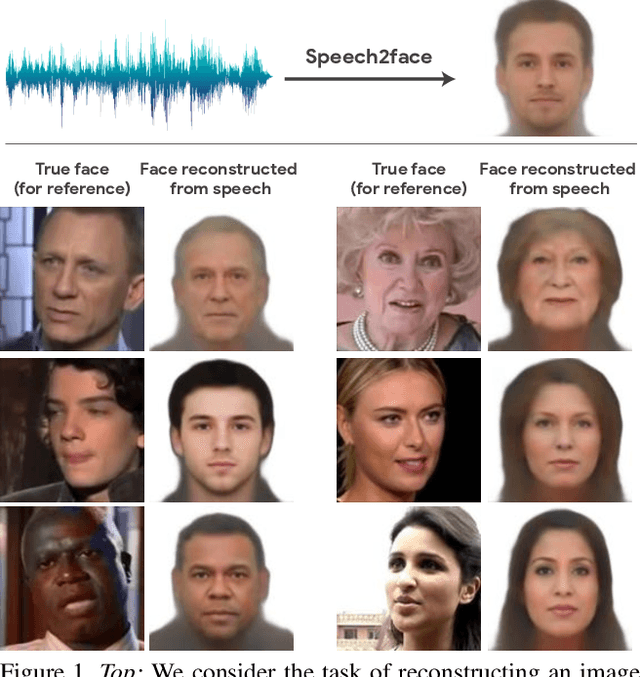

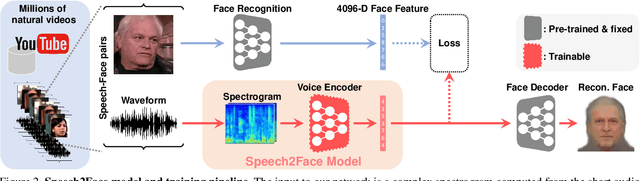
How much can we infer about a person's looks from the way they speak? In this paper, we study the task of reconstructing a facial image of a person from a short audio recording of that person speaking. We design and train a deep neural network to perform this task using millions of natural Internet/YouTube videos of people speaking. During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how--and in what manner--our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.
Learning the Depths of Moving People by Watching Frozen People
Apr 25, 2019



We present a method for predicting dense depth in scenarios where both a monocular camera and people in the scene are freely moving. Existing methods for recovering depth for dynamic, non-rigid objects from monocular video impose strong assumptions on the objects' motion and may only recover sparse depth. In this paper, we take a data-driven approach and learn human depth priors from a new source of data: thousands of Internet videos of people imitating mannequins, i.e., freezing in diverse, natural poses, while a hand-held camera tours the scene. Because people are stationary, training data can be generated using multi-view stereo reconstruction. At inference time, our method uses motion parallax cues from the static areas of the scenes to guide the depth prediction. We demonstrate our method on real-world sequences of complex human actions captured by a moving hand-held camera, show improvement over state-of-the-art monocular depth prediction methods, and show various 3D effects produced using our predicted depth.
Learning Shape Templates with Structured Implicit Functions
Apr 12, 2019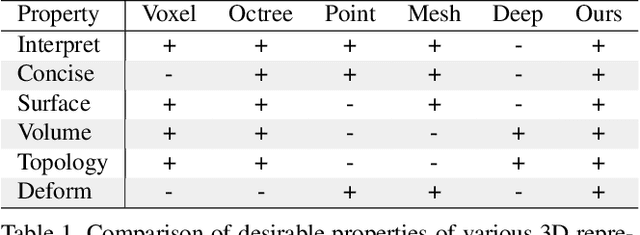

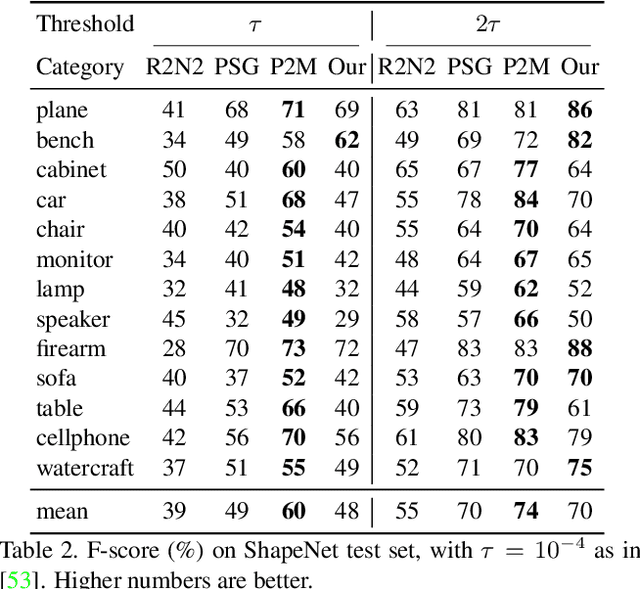

Template 3D shapes are useful for many tasks in graphics and vision, including fitting observation data, analyzing shape collections, and transferring shape attributes. Because of the variety of geometry and topology of real-world shapes, previous methods generally use a library of hand-made templates. In this paper, we investigate learning a general shape template from data. To allow for widely varying geometry and topology, we choose an implicit surface representation based on composition of local shape elements. While long known to computer graphics, this representation has not yet been explored in the context of machine learning for vision. We show that structured implicit functions are suitable for learning and allow a network to smoothly and simultaneously fit multiple classes of shapes. The learned shape template supports applications such as shape exploration, correspondence, abstraction, interpolation, and semantic segmentation from an RGB image.