 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXpert++: Approximating the CheXpert labeler for Speed,Differentiability, and Probabilistic Output
Jun 26, 2020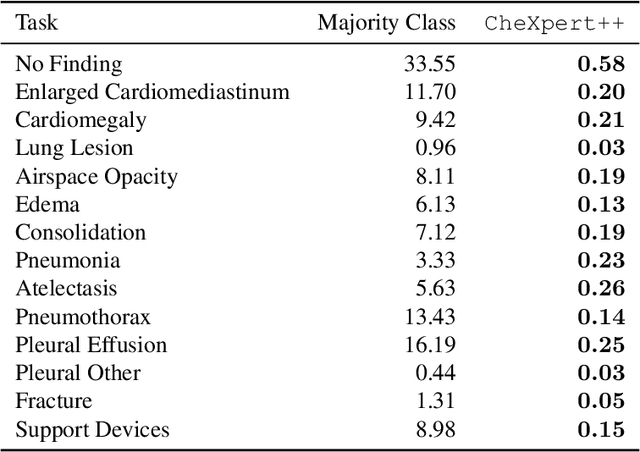
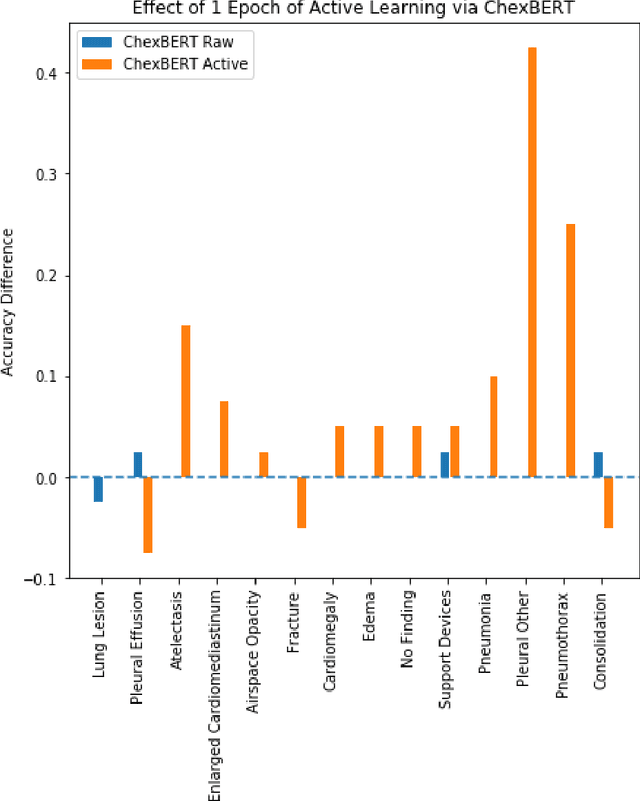
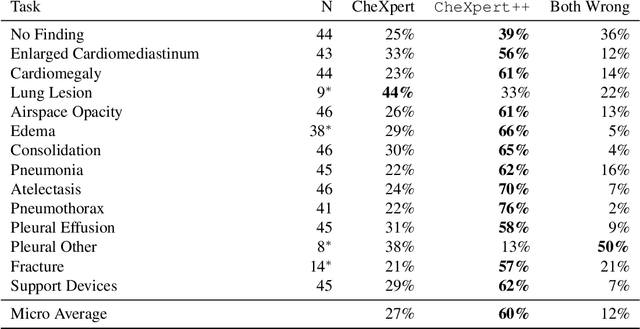
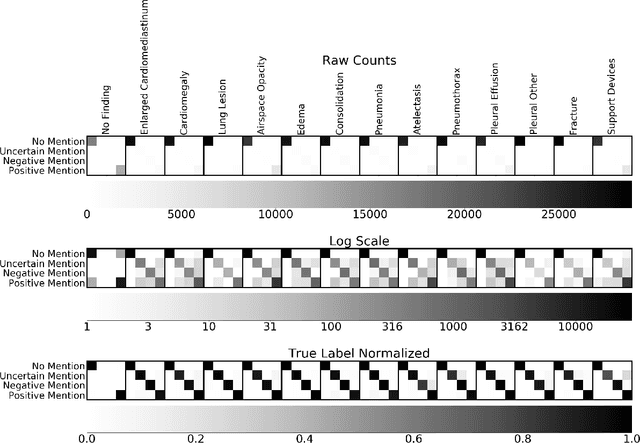
It is often infeasible or impossible to obtain ground truth labels for medical data. To circumvent this, one may build rule-based or other expert-knowledge driven labelers to ingest data and yield silver labels absent any ground-truth training data. One popular such labeler is CheXpert, a labeler that produces diagnostic labels for chest X-ray radiology reports. CheXpert is very useful, but is relatively computationally slow, especially when integrated with end-to-end neural pipelines, is non-differentiable so can't be used in any applications that require gradients to flow through the labeler, and does not yield probabilistic outputs, which limits our ability to improve the quality of the silver labeler through techniques such as active learning. In this work, we solve all three of these problems with $\texttt{CheXpert++}$, a BERT-based, high-fidelity approximation to CheXpert. $\texttt{CheXpert++}$ achieves 99.81\% parity with CheXpert, which means it can be reliably used as a drop-in replacement for CheXpert, all while being significantly faster, fully differentiable, and probabilistic in output. Error analysis of $\texttt{CheXpert++}$ also demonstrates that $\texttt{CheXpert++}$ has a tendency to actually correct errors in the CheXpert labels, with $\texttt{CheXpert++}$ labels being more often preferred by a clinician over CheXpert labels (when they disagree) on all but one disease task. To further demonstrate the utility of these advantages in this model, we conduct a proof-of-concept active learning study, demonstrating we can improve accuracy on an expert labeled random subset of report sentences by approximately 8\% over raw, unaltered CheXpert by using one-iteration of active-learning inspired re-training. These findings suggest that simple techniques in co-learning and active learning can yield high-quality labelers under minimal, and controllable human labeling demands.
3D-Aware Scene Manipulation via Inverse Graphics
Oct 11, 2018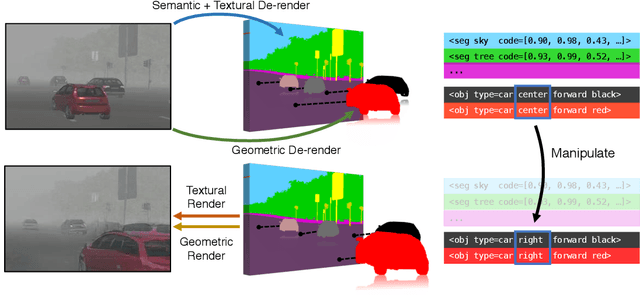

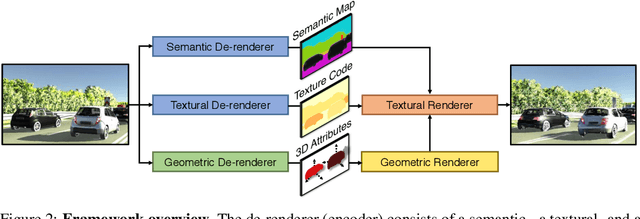
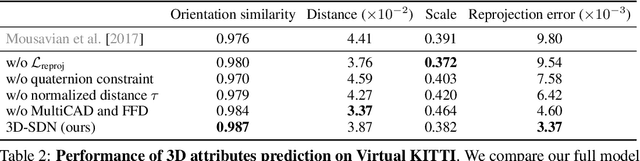
We aim to obtain an interpretable, expressive, and disentangled scene representation that contains comprehensive structural and textural information for each object. Previous scene representations learned by neural networks are often uninterpretable, limited to a single object, or lacking 3D knowledge. In this work, we propose 3D scene de-rendering networks (3D-SDN) to address the above issues by integrating disentangled representations for semantics, geometry, and appearance into a deep generative model. Our scene encoder performs inverse graphics, translating a scene into a structured object-wise representation. Our decoder has two components: a differentiable shape renderer and a neural texture generator. The disentanglement of semantics, geometry, and appearance supports 3D-aware scene manipulation, e.g., rotating and moving objects freely while keeping the consistent shape and texture, and changing the object appearance without affecting its shape. Experiments demonstrate that our editing scheme based on 3D-SDN is superior to its 2D counterpart.