 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPI 2022 Challenge on Quad-Bayer Re-mosaic: Dataset and Report
Sep 15, 2022



Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge, including five tracks focusing on novel image sensors and imaging algorithms. In this paper, Quad Joint Remosaic and Denoise, one of the five tracks, working on the interpolation of Quad CFA to Bayer at full resolution, is introduced. The participants were provided a new dataset, including 70 (training) and 15 (validation) scenes of high-quality Quad and Bayer pairs. In addition, for each scene, Quad of different noise levels was provided at 0dB, 24dB, and 42dB. All the data were captured using a Quad sensor in both outdoor and indoor conditions. The final results are evaluated using objective metrics, including PSNR, SSIM, LPIPS, and KLD. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
MIPI 2022 Challenge on RGB+ToF Depth Completion: Dataset and Report
Sep 15, 2022
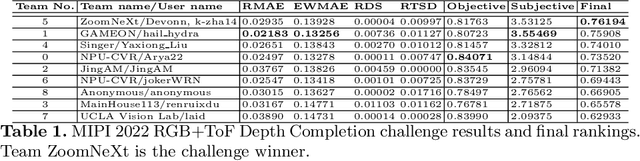
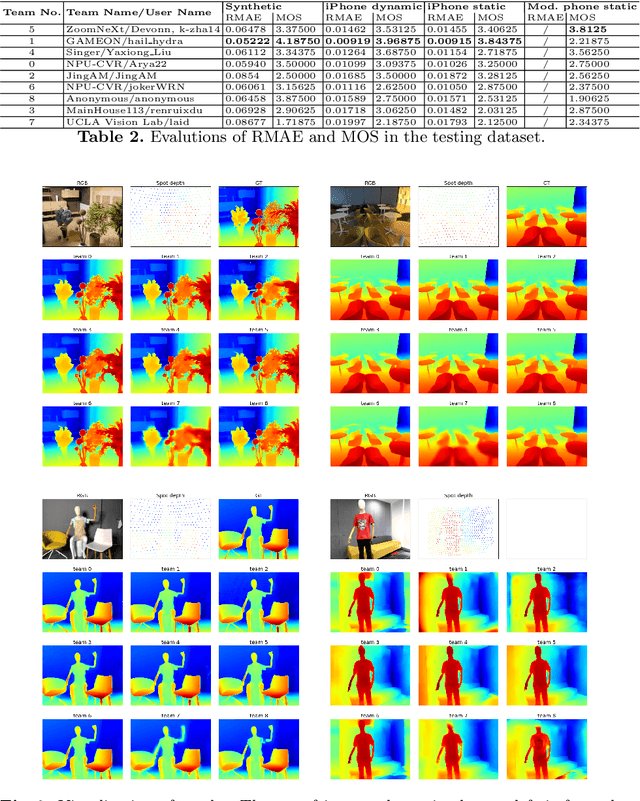
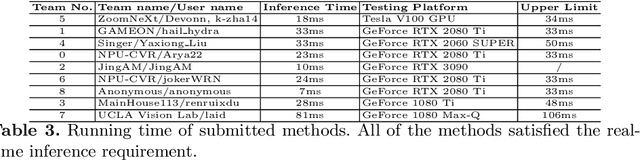
Developing and integrating advanced image sensors with novel algorithms in camera systems is prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGB+ToF Depth Completion, one of the five tracks, working on the fusion of RGB sensor and ToF sensor (with spot illumination) is introduced. The participants were provided with a new dataset called TetrasRGBD, which contains 18k pairs of high-quality synthetic RGB+Depth training data and 2.3k pairs of testing data from mixed sources. All the data are collected in an indoor scenario. We require that the running time of all methods should be real-time on desktop GPUs. The final results are evaluated using objective metrics and Mean Opinion Score (MOS) subjectively. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
MIPI 2022 Challenge on Under-Display Camera Image Restoration: Methods and Results
Sep 15, 2022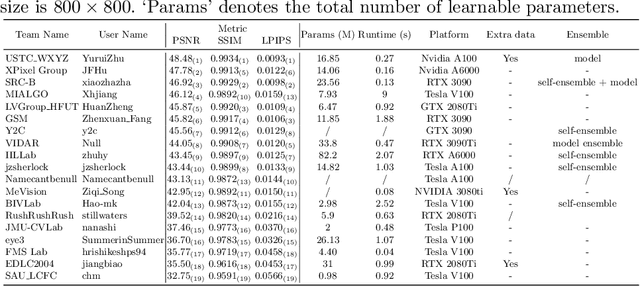
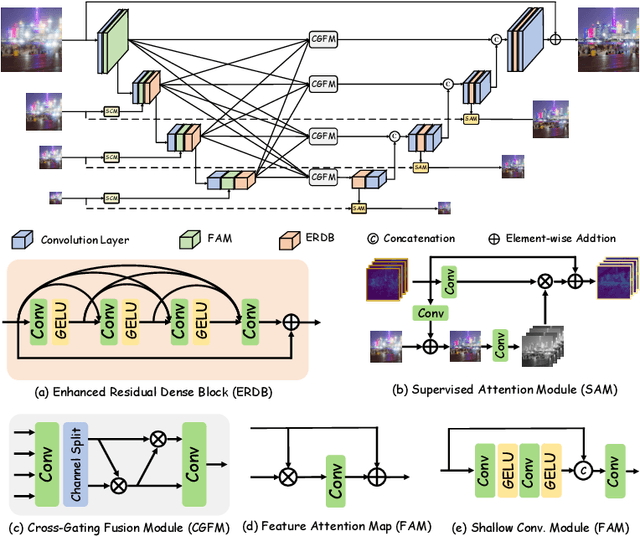
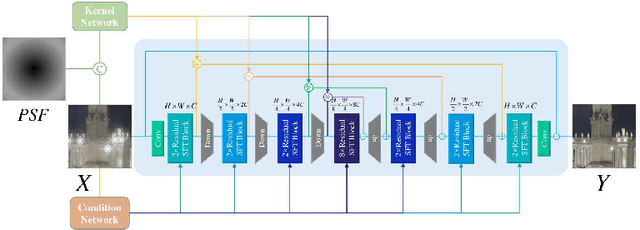
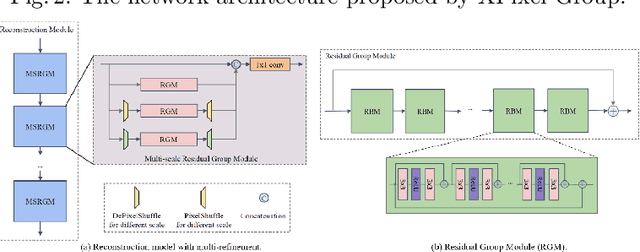
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge including five tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Under-Display Camera (UDC) Image Restoration track on MIPI 2022. In total, 167 participants were successfully registered, and 19 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Under-Display Camera Image Restoration. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
Exploring the Effectiveness of Video Perceptual Representation in Blind Video Quality Assessment
Jul 08, 2022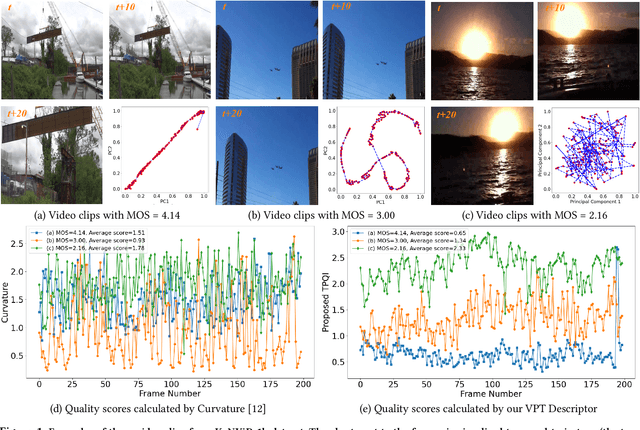
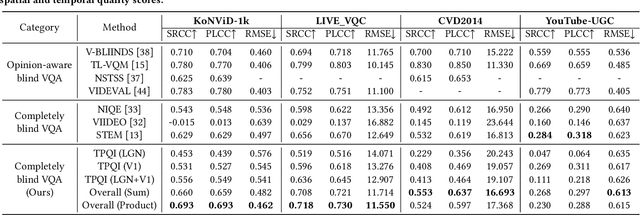
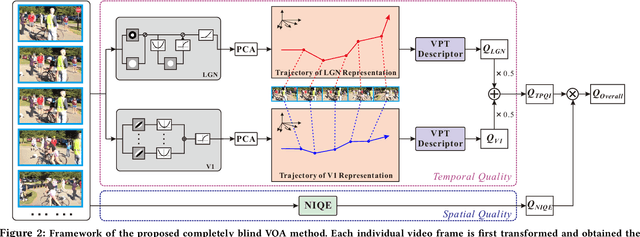
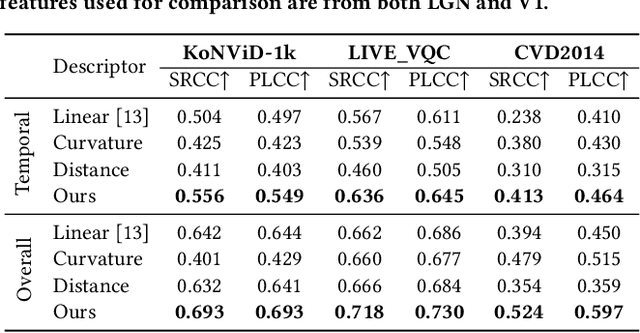
With the rapid growth of in-the-wild videos taken by non-specialists, blind video quality assessment (VQA) has become a challenging and demanding problem. Although lots of efforts have been made to solve this problem, it remains unclear how the human visual system (HVS) relates to the temporal quality of videos. Meanwhile, recent work has found that the frames of natural video transformed into the perceptual domain of the HVS tend to form a straight trajectory of the representations. With the obtained insight that distortion impairs the perceived video quality and results in a curved trajectory of the perceptual representation, we propose a temporal perceptual quality index (TPQI) to measure the temporal distortion by describing the graphic morphology of the representation. Specifically, we first extract the video perceptual representations from the lateral geniculate nucleus (LGN) and primary visual area (V1) of the HVS, and then measure the straightness and compactness of their trajectories to quantify the degradation in naturalness and content continuity of video. Experiments show that the perceptual representation in the HVS is an effective way of predicting subjective temporal quality, and thus TPQI can, for the first time, achieve comparable performance to the spatial quality metric and be even more effective in assessing videos with large temporal variations. We further demonstrate that by combining with NIQE, a spatial quality metric, TPQI can achieve top performance over popular in-the-wild video datasets. More importantly, TPQI does not require any additional information beyond the video being evaluated and thus can be applied to any datasets without parameter tuning. Source code is available at https://github.com/UoLMM/TPQI-VQA.
* Will appear on ACM MM 2022
FAST-VQA: Efficient End-to-end Video Quality Assessment with Fragment Sampling
Jul 06, 2022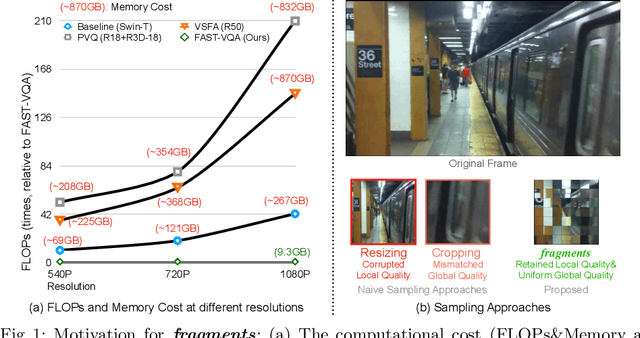


Current deep video quality assessment (VQA) methods are usually with high computational costs when evaluating high-resolution videos. This cost hinders them from learning better video-quality-related representations via end-to-end training. Existing approaches typically consider naive sampling to reduce the computational cost, such as resizing and cropping. However, they obviously corrupt quality-related information in videos and are thus not optimal for learning good representations for VQA. Therefore, there is an eager need to design a new quality-retained sampling scheme for VQA. In this paper, we propose Grid Mini-patch Sampling (GMS), which allows consideration of local quality by sampling patches at their raw resolution and covers global quality with contextual relations via mini-patches sampled in uniform grids. These mini-patches are spliced and aligned temporally, named as fragments. We further build the Fragment Attention Network (FANet) specially designed to accommodate fragments as inputs. Consisting of fragments and FANet, the proposed FrAgment Sample Transformer for VQA (FAST-VQA) enables efficient end-to-end deep VQA and learns effective video-quality-related representations. It improves state-of-the-art accuracy by around 10% while reducing 99.5% FLOPs on 1080P high-resolution videos. The newly learned video-quality-related representations can also be transferred into smaller VQA datasets, boosting performance in these scenarios. Extensive experiments show that FAST-VQA has good performance on inputs of various resolutions while retaining high efficiency. We publish our code at https://github.com/timothyhtimothy/FAST-VQA.
* Will appear on ECCV 2022. 14 Pages
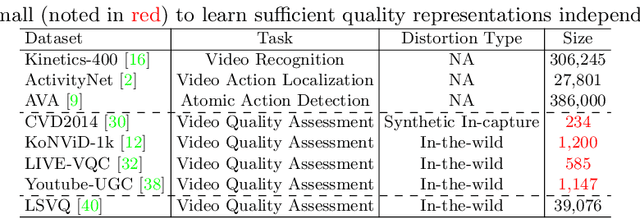
DisCoVQA: Temporal Distortion-Content Transformers for Video Quality Assessment
Jun 20, 2022
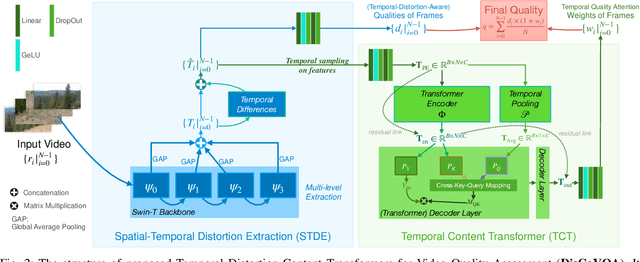
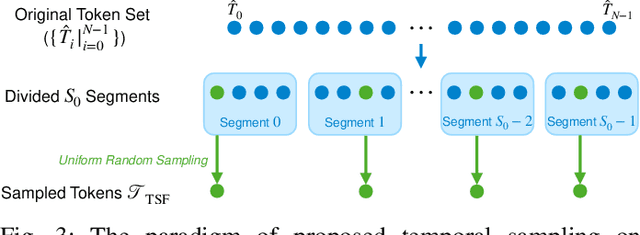
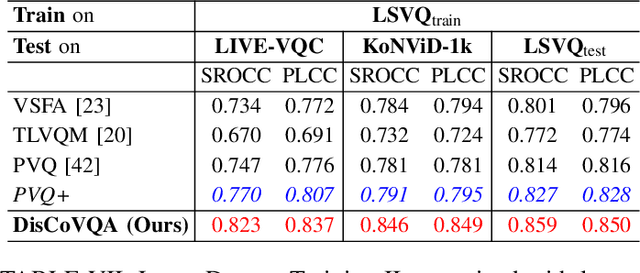
The temporal relationships between frames and their influences on video quality assessment (VQA) are still under-studied in existing works. These relationships lead to two important types of effects for video quality. Firstly, some temporal variations (such as shaking, flicker, and abrupt scene transitions) are causing temporal distortions and lead to extra quality degradations, while other variations (e.g. those related to meaningful happenings) do not. Secondly, the human visual system often has different attention to frames with different contents, resulting in their different importance to the overall video quality. Based on prominent time-series modeling ability of transformers, we propose a novel and effective transformer-based VQA method to tackle these two issues. To better differentiate temporal variations and thus capture the temporal distortions, we design a transformer-based Spatial-Temporal Distortion Extraction (STDE) module. To tackle with temporal quality attention, we propose the encoder-decoder-like temporal content transformer (TCT). We also introduce the temporal sampling on features to reduce the input length for the TCT, so as to improve the learning effectiveness and efficiency of this module. Consisting of the STDE and the TCT, the proposed Temporal Distortion-Content Transformers for Video Quality Assessment (DisCoVQA) reaches state-of-the-art performance on several VQA benchmarks without any extra pre-training datasets and up to 10% better generalization ability than existing methods. We also conduct extensive ablation experiments to prove the effectiveness of each part in our proposed model, and provide visualizations to prove that the proposed modules achieve our intention on modeling these temporal issues. We will publish our codes and pretrained weights later.
FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting
Sep 07, 2021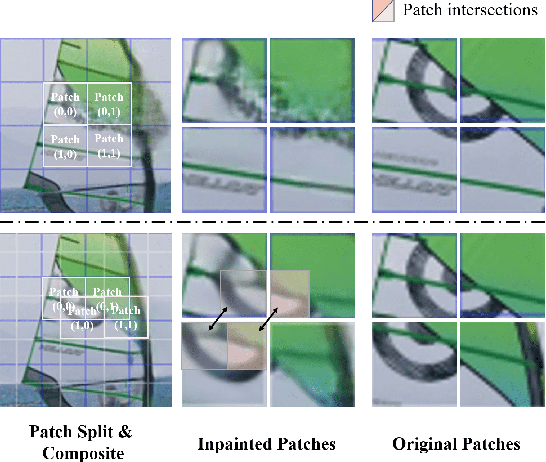
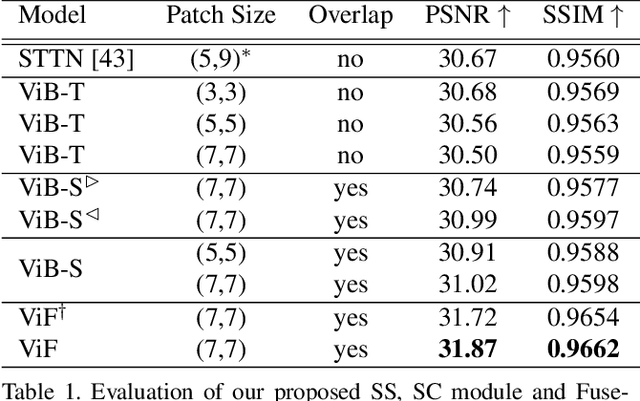
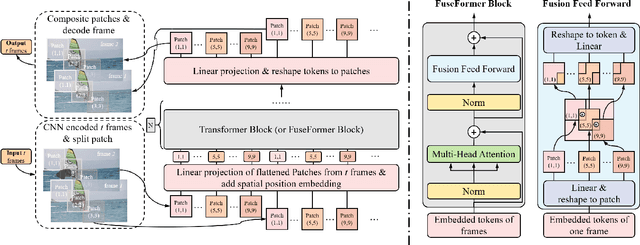
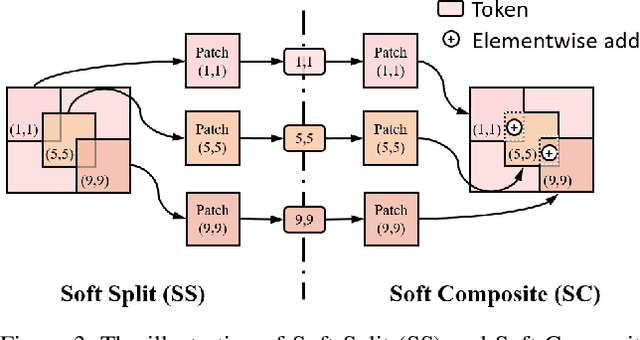
Transformer, as a strong and flexible architecture for modelling long-range relations, has been widely explored in vision tasks. However, when used in video inpainting that requires fine-grained representation, existed method still suffers from yielding blurry edges in detail due to the hard patch splitting. Here we aim to tackle this problem by proposing FuseFormer, a Transformer model designed for video inpainting via fine-grained feature fusion based on novel Soft Split and Soft Composition operations. The soft split divides feature map into many patches with given overlapping interval. On the contrary, the soft composition operates by stitching different patches into a whole feature map where pixels in overlapping regions are summed up. These two modules are first used in tokenization before Transformer layers and de-tokenization after Transformer layers, for effective mapping between tokens and features. Therefore, sub-patch level information interaction is enabled for more effective feature propagation between neighboring patches, resulting in synthesizing vivid content for hole regions in videos. Moreover, in FuseFormer, we elaborately insert the soft composition and soft split into the feed-forward network, enabling the 1D linear layers to have the capability of modelling 2D structure. And, the sub-patch level feature fusion ability is further enhanced. In both quantitative and qualitative evaluations, our proposed FuseFormer surpasses state-of-the-art methods. We also conduct detailed analysis to examine its superiority.
Dual-Camera Super-Resolution with Aligned Attention Modules
Sep 06, 2021
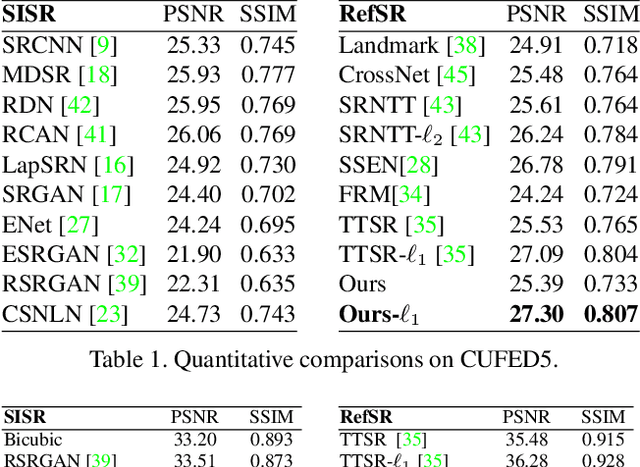
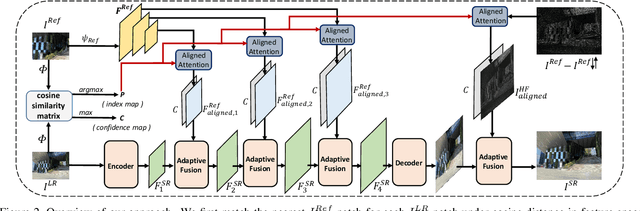
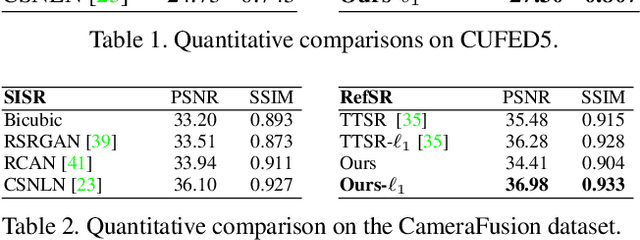
We present a novel approach to reference-based super-resolution (RefSR) with the focus on dual-camera super-resolution (DCSR), which utilizes reference images for high-quality and high-fidelity results. Our proposed method generalizes the standard patch-based feature matching with spatial alignment operations. We further explore the dual-camera super-resolution that is one promising application of RefSR, and build a dataset that consists of 146 image pairs from the main and telephoto cameras in a smartphone. To bridge the domain gaps between real-world images and the training images, we propose a self-supervised domain adaptation strategy for real-world images. Extensive experiments on our dataset and a public benchmark demonstrate clear improvement achieved by our method over state of the art in both quantitative evaluation and visual comparisons.
A Categorized Reflection Removal Dataset with Diverse Real-world Scenes
Aug 07, 2021


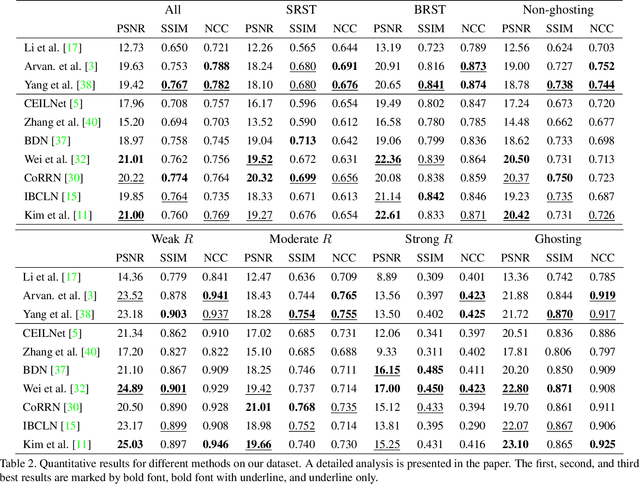
Due to the lack of a large-scale reflection removal dataset with diverse real-world scenes, many existing reflection removal methods are trained on synthetic data plus a small amount of real-world data, which makes it difficult to evaluate the strengths or weaknesses of different reflection removal methods thoroughly. Furthermore, existing real-world benchmarks and datasets do not categorize image data based on the types and appearances of reflection (e.g., smoothness, intensity), making it hard to analyze reflection removal methods. Hence, we construct a new reflection removal dataset that is categorized, diverse, and real-world (CDR). A pipeline based on RAW data is used to capture perfectly aligned input images and transmission images. The dataset is constructed using diverse glass types under various environments to ensure diversity. By analyzing several reflection removal methods and conducting extensive experiments on our dataset, we show that state-of-the-art reflection removal methods generally perform well on blurry reflection but fail in obtaining satisfying performance on other types of real-world reflection. We believe our dataset can help develop novel methods to remove real-world reflection better. Our dataset is available at https://alexzhao-hugga.github.io/Real-World-Reflection-Removal/.
Decoupled Spatial-Temporal Transformer for Video Inpainting
Apr 14, 2021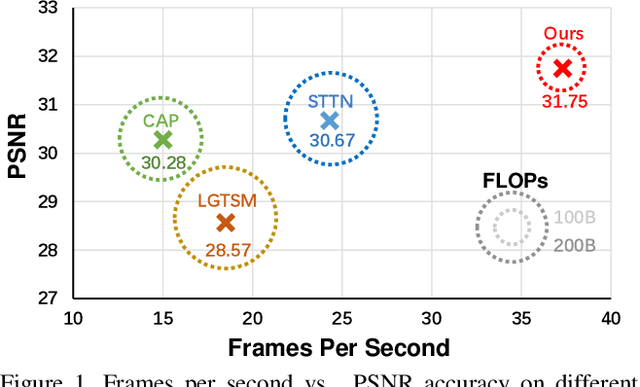
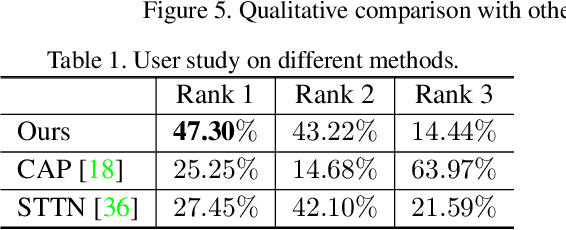

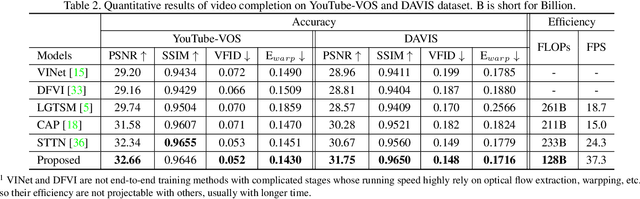
Video inpainting aims to fill the given spatiotemporal holes with realistic appearance but is still a challenging task even with prosperous deep learning approaches. Recent works introduce the promising Transformer architecture into deep video inpainting and achieve better performance. However, it still suffers from synthesizing blurry texture as well as huge computational cost. Towards this end, we propose a novel Decoupled Spatial-Temporal Transformer (DSTT) for improving video inpainting with exceptional efficiency. Our proposed DSTT disentangles the task of learning spatial-temporal attention into 2 sub-tasks: one is for attending temporal object movements on different frames at same spatial locations, which is achieved by temporally-decoupled Transformer block, and the other is for attending similar background textures on same frame of all spatial positions, which is achieved by spatially-decoupled Transformer block. The interweaving stack of such two blocks makes our proposed model attend background textures and moving objects more precisely, and thus the attended plausible and temporally-coherent appearance can be propagated to fill the holes. In addition, a hierarchical encoder is adopted before the stack of Transformer blocks, for learning robust and hierarchical features that maintain multi-level local spatial structure, resulting in the more representative token vectors. Seamless combination of these two novel designs forms a better spatial-temporal attention scheme and our proposed model achieves better performance than state-of-the-art video inpainting approaches with significant boosted efficiency.