 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Large Language Reasoning Models via Extreme-Ratio Chain-of-Thought Compression
Feb 09, 2026Chain-of-Thought (CoT) reasoning successfully enhances the reasoning capabilities of Large Language Models (LLMs), yet it incurs substantial computational overhead for inference. Existing CoT compression methods often suffer from a critical loss of logical fidelity at high compression ratios, resulting in significant performance degradation. To achieve high-fidelity, fast reasoning, we propose a novel EXTreme-RAtio Chain-of-Thought Compression framework, termed Extra-CoT, which aggressively reduces the token budget while preserving answer accuracy. To generate reliable, high-fidelity supervision, we first train a dedicated semantically-preserved compressor on mathematical CoT data with fine-grained annotations. An LLM is then fine-tuned on these compressed pairs via a mixed-ratio supervised fine-tuning (SFT), teaching it to follow a spectrum of compression budgets and providing a stable initialization for reinforcement learning (RL). We further propose Constrained and Hierarchical Ratio Policy Optimization (CHRPO) to explicitly incentivize question-solving ability under lower budgets by a hierarchical reward. Experiments on three mathematical reasoning benchmarks show the superiority of Extra-CoT. For example, on MATH-500 using Qwen3-1.7B, Extra-CoT achieves over 73\% token reduction with an accuracy improvement of 0.6\%, significantly outperforming state-of-the-art (SOTA) methods.
Spurious Rewards Paradox: Mechanistically Understanding How RLVR Activates Memorization Shortcuts in LLMs
Jan 16, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is highly effective for enhancing LLM reasoning, yet recent evidence shows models like Qwen 2.5 achieve significant gains even with spurious or incorrect rewards. We investigate this phenomenon and identify a "Perplexity Paradox": spurious RLVR triggers a divergence where answer-token perplexity drops while prompt-side coherence degrades, suggesting the model is bypassing reasoning in favor of memorization. Using Path Patching, Logit Lens, JSD analysis, and Neural Differential Equations, we uncover a hidden Anchor-Adapter circuit that facilitates this shortcut. We localize a Functional Anchor in the middle layers (L18-20) that triggers the retrieval of memorized solutions, followed by Structural Adapters in later layers (L21+) that transform representations to accommodate the shortcut signal. Finally, we demonstrate that scaling specific MLP keys within this circuit allows for bidirectional causal steering-artificially amplifying or suppressing contamination-driven performance. Our results provide a mechanistic roadmap for identifying and mitigating data contamination in RLVR-tuned models. Code is available at https://github.com/idwts/How-RLVR-Activates-Memorization-Shortcuts.
Evaluating the Effectiveness of Linguistic Knowledge in Pretrained Language Models: A Case Study of Universal Dependencies
Jun 05, 2025Universal Dependencies (UD), while widely regarded as the most successful linguistic framework for cross-lingual syntactic representation, remains underexplored in terms of its effectiveness. This paper addresses this gap by integrating UD into pretrained language models and assesses if UD can improve their performance on a cross-lingual adversarial paraphrase identification task. Experimental results show that incorporation of UD yields significant improvements in accuracy and $F_1$ scores, with average gains of 3.85\% and 6.08\% respectively. These enhancements reduce the performance gap between pretrained models and large language models in some language pairs, and even outperform the latter in some others. Furthermore, the UD-based similarity score between a given language and English is positively correlated to the performance of models in that language. Both findings highlight the validity and potential of UD in out-of-domain tasks.
SparseFormer: Detecting Objects in HRW Shots via Sparse Vision Transformer
Feb 11, 2025Recent years have seen an increase in the use of gigapixel-level image and video capture systems and benchmarks with high-resolution wide (HRW) shots. However, unlike close-up shots in the MS COCO dataset, the higher resolution and wider field of view raise unique challenges, such as extreme sparsity and huge scale changes, causing existing close-up detectors inaccuracy and inefficiency. In this paper, we present a novel model-agnostic sparse vision transformer, dubbed SparseFormer, to bridge the gap of object detection between close-up and HRW shots. The proposed SparseFormer selectively uses attentive tokens to scrutinize the sparsely distributed windows that may contain objects. In this way, it can jointly explore global and local attention by fusing coarse- and fine-grained features to handle huge scale changes. SparseFormer also benefits from a novel Cross-slice non-maximum suppression (C-NMS) algorithm to precisely localize objects from noisy windows and a simple yet effective multi-scale strategy to improve accuracy. Extensive experiments on two HRW benchmarks, PANDA and DOTA-v1.0, demonstrate that the proposed SparseFormer significantly improves detection accuracy (up to 5.8%) and speed (up to 3x) over the state-of-the-art approaches.
Large Language Models as Code Executors: An Exploratory Study
Oct 10, 2024



The capabilities of Large Language Models (LLMs) have significantly evolved, extending from natural language processing to complex tasks like code understanding and generation. We expand the scope of LLMs' capabilities to a broader context, using LLMs to execute code snippets to obtain the output. This paper pioneers the exploration of LLMs as code executors, where code snippets are directly fed to the models for execution, and outputs are returned. We are the first to comprehensively examine this feasibility across various LLMs, including OpenAI's o1, GPT-4o, GPT-3.5, DeepSeek, and Qwen-Coder. Notably, the o1 model achieved over 90% accuracy in code execution, while others demonstrated lower accuracy levels. Furthermore, we introduce an Iterative Instruction Prompting (IIP) technique that processes code snippets line by line, enhancing the accuracy of weaker models by an average of 7.22% (with the highest improvement of 18.96%) and an absolute average improvement of 3.86% against CoT prompting (with the highest improvement of 19.46%). Our study not only highlights the transformative potential of LLMs in coding but also lays the groundwork for future advancements in automated programming and the completion of complex tasks.
SaccadeDet: A Novel Dual-Stage Architecture for Rapid and Accurate Detection in Gigapixel Images
Jul 25, 2024The advancement of deep learning in object detection has predominantly focused on megapixel images, leaving a critical gap in the efficient processing of gigapixel images. These super high-resolution images present unique challenges due to their immense size and computational demands. To address this, we introduce 'SaccadeDet', an innovative architecture for gigapixel-level object detection, inspired by the human eye saccadic movement. The cornerstone of SaccadeDet is its ability to strategically select and process image regions, dramatically reducing computational load. This is achieved through a two-stage process: the 'saccade' stage, which identifies regions of probable interest, and the 'gaze' stage, which refines detection in these targeted areas. Our approach, evaluated on the PANDA dataset, not only achieves an 8x speed increase over the state-of-the-art methods but also demonstrates significant potential in gigapixel-level pathology analysis through its application to Whole Slide Imaging.
* This paper is accepted to ECML-PKDD 2024
OPAM: Online Purchasing-behavior Analysis using Machine learning
Feb 02, 2021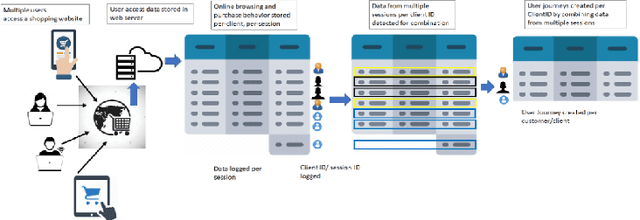

Customer purchasing behavior analysis plays a key role in developing insightful communication strategies between online vendors and their customers. To support the recent increase in online shopping trends, in this work, we present a customer purchasing behavior analysis system using supervised, unsupervised and semi-supervised learning methods. The proposed system analyzes session and user-journey level purchasing behaviors to identify customer categories/clusters that can be useful for targeted consumer insights at scale. We observe higher sensitivity to the design of online shopping portals for session-level purchasing prediction with accuracy/recall in range 91-98%/73-99%, respectively. The user-journey level analysis demonstrates five unique user clusters, wherein 'New Shoppers' are most predictable and 'Impulsive Shoppers' are most unique with low viewing and high carting behaviors for purchases. Further, cluster transformation metrics and partial label learning demonstrates the robustness of each user cluster to new/unlabelled events. Thus, customer clusters can aid strategic targeted nudge models.
Categorizing Online Shopping Behavior from Cosmetics to Electronics: An Analytical Framework
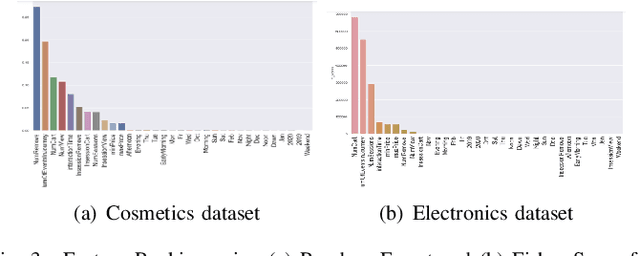
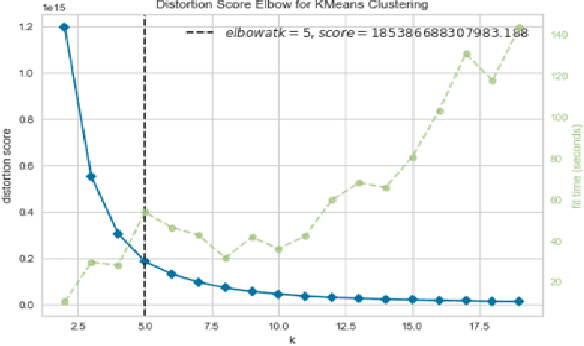
Oct 06, 2020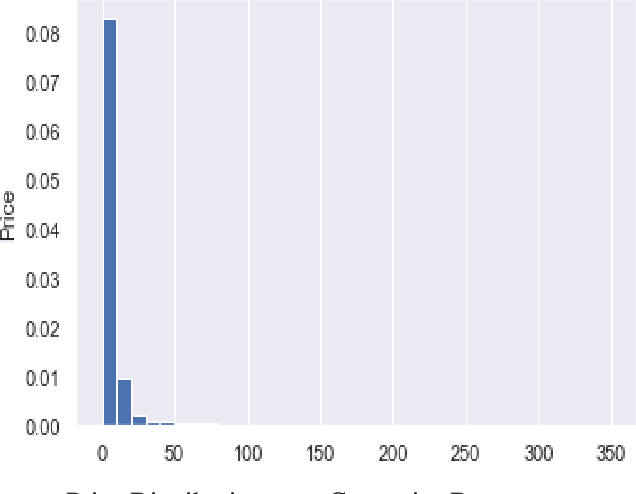
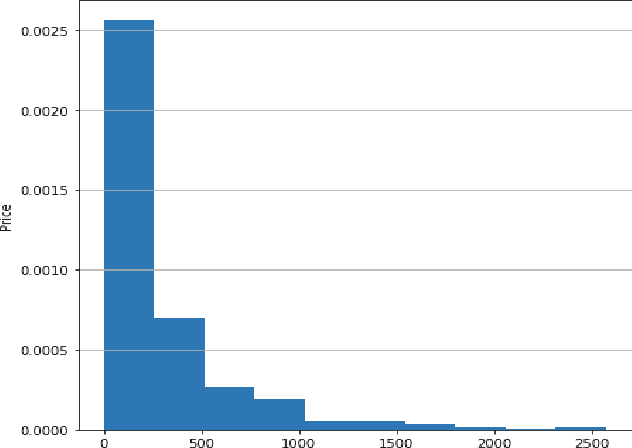
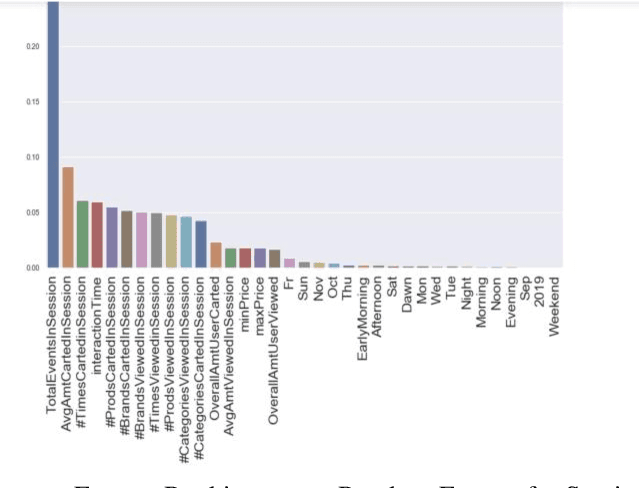
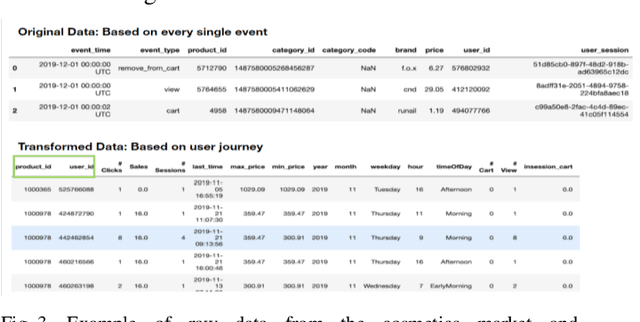
A success factor for modern companies in the age of Digital Marketing is to understand how customers think and behave based on their online shopping patterns. While the conventional method of gathering consumer insights through questionnaires and surveys still form the bases of descriptive analytics for market intelligence units, we propose a machine learning framework to automate this process. In this paper we present a modular consumer data analysis platform that processes session level interaction records between users and products to predict session level, user journey level and customer behavior specific patterns leading towards purchase events. We explore the computational framework and provide test results on two Big data sets-cosmetics and consumer electronics of size 2GB and 15GB, respectively. The proposed system achieves 97-99% classification accuracy and recall for user-journey level purchase predictions and categorizes buying behavior into 5 clusters with increasing purchase ratios for both data sets. Thus, the proposed framework is extendable to other large e-commerce data sets to obtain automated purchase predictions and descriptive consumer insights.
Learning Error-Driven Curriculum for Crowd Counting
Jul 19, 2020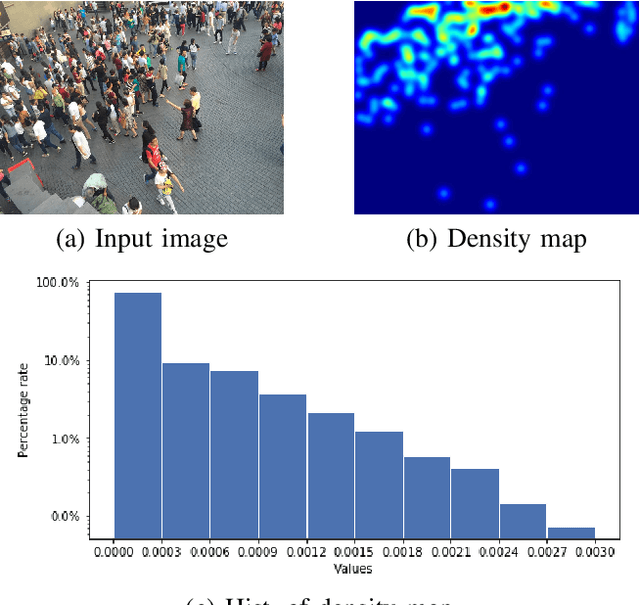
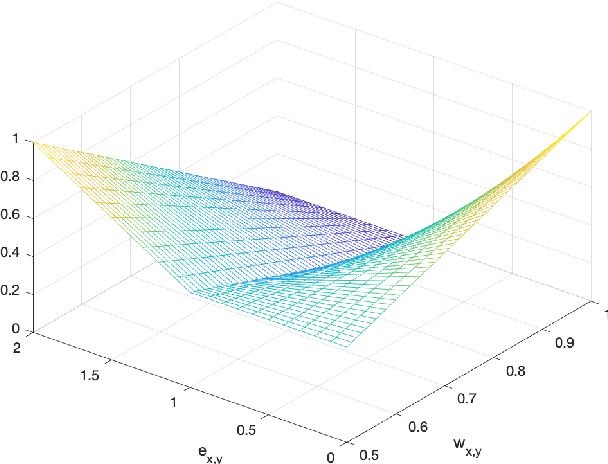
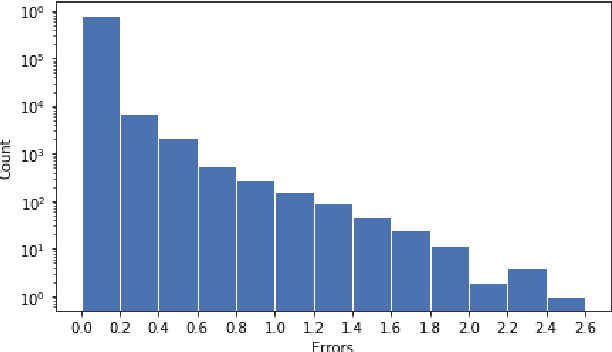
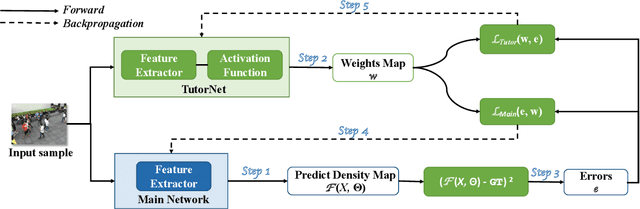
Density regression has been widely employed in crowd counting. However, the frequency imbalance of pixel values in the density map is still an obstacle to improve the performance. In this paper, we propose a novel learning strategy for learning error-driven curriculum, which uses an additional network to supervise the training of the main network. A tutoring network called TutorNet is proposed to repetitively indicate the critical errors of the main network. TutorNet generates pixel-level weights to formulate the curriculum for the main network during training, so that the main network will assign a higher weight to those hard examples than easy examples. Furthermore, we scale the density map by a factor to enlarge the distance among inter-examples, which is well known to improve the performance. Extensive experiments on two challenging benchmark datasets show that our method has achieved state-of-the-art performance.