 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMAGaze: Gaze Estimation Based on Feature Disentanglement and Multi-Scale Attention
Apr 15, 2025Gaze estimation, which predicts gaze direction, commonly faces the challenge of interference from complex gaze-irrelevant information in face images. In this work, we propose DMAGaze, a novel gaze estimation framework that exploits information from facial images in three aspects: gaze-relevant global features (disentangled from facial image), local eye features (extracted from cropped eye patch), and head pose estimation features, to improve overall performance. Firstly, we design a new continuous mask-based Disentangler to accurately disentangle gaze-relevant and gaze-irrelevant information in facial images by achieving the dual-branch disentanglement goal through separately reconstructing the eye and non-eye regions. Furthermore, we introduce a new cascaded attention module named Multi-Scale Global Local Attention Module (MS-GLAM). Through a customized cascaded attention structure, it effectively focuses on global and local information at multiple scales, further enhancing the information from the Disentangler. Finally, the global gaze-relevant features disentangled by the upper face branch, combined with head pose and local eye features, are passed through the detection head for high-precision gaze estimation. Our proposed DMAGaze has been extensively validated on two mainstream public datasets, achieving state-of-the-art performance.
DGFM: Full Body Dance Generation Driven by Music Foundation Models
Feb 27, 2025In music-driven dance motion generation, most existing methods use hand-crafted features and neglect that music foundation models have profoundly impacted cross-modal content generation. To bridge this gap, we propose a diffusion-based method that generates dance movements conditioned on text and music. Our approach extracts music features by combining high-level features obtained by music foundation model with hand-crafted features, thereby enhancing the quality of generated dance sequences. This method effectively leverages the advantages of high-level semantic information and low-level temporal details to improve the model's capability in music feature understanding. To show the merits of the proposed method, we compare it with four music foundation models and two sets of hand-crafted music features. The results demonstrate that our method obtains the most realistic dance sequences and achieves the best match with the input music.
GCDance: Genre-Controlled 3D Full Body Dance Generation Driven By Music
Feb 25, 2025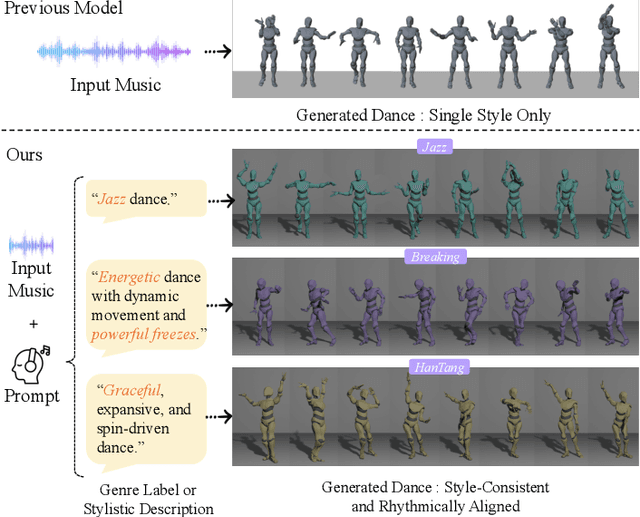
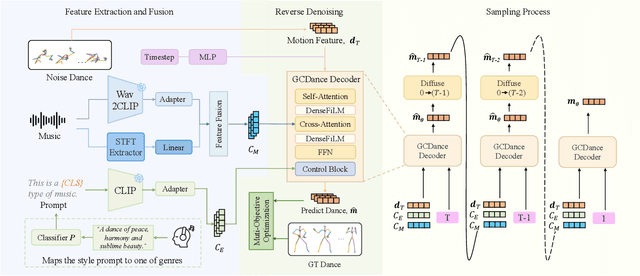
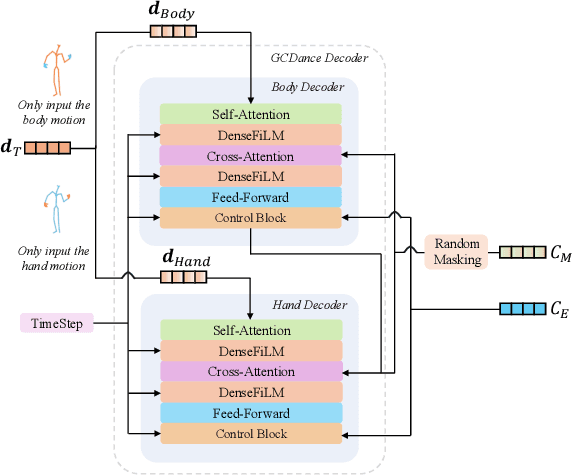
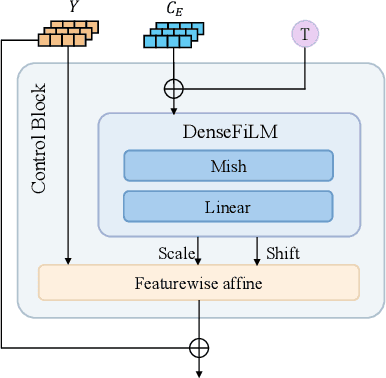
Generating high-quality full-body dance sequences from music is a challenging task as it requires strict adherence to genre-specific choreography. Moreover, the generated sequences must be both physically realistic and precisely synchronized with the beats and rhythm of the music. To overcome these challenges, we propose GCDance, a classifier-free diffusion framework for generating genre-specific dance motions conditioned on both music and textual prompts. Specifically, our approach extracts music features by combining high-level pre-trained music foundation model features with hand-crafted features for multi-granularity feature fusion. To achieve genre controllability, we leverage CLIP to efficiently embed genre-based textual prompt representations at each time step within our dance generation pipeline. Our GCDance framework can generate diverse dance styles from the same piece of music while ensuring coherence with the rhythm and melody of the music. Extensive experimental results obtained on the FineDance dataset demonstrate that GCDance significantly outperforms the existing state-of-the-art approaches, which also achieve competitive results on the AIST++ dataset. Our ablation and inference time analysis demonstrate that GCDance provides an effective solution for high-quality music-driven dance generation.
The ICME 2025 Audio Encoder Capability Challenge
Jan 25, 2025This challenge aims to evaluate the capabilities of audio encoders, especially in the context of multi-task learning and real-world applications. Participants are invited to submit pre-trained audio encoders that map raw waveforms to continuous embeddings. These encoders will be tested across diverse tasks including speech, environmental sounds, and music, with a focus on real-world usability. The challenge features two tracks: Track A for parameterized evaluation, and Track B for parameter-free evaluation. This challenge provides a platform for evaluating and advancing the state-of-the-art in audio encoder design.
Graph-Enhanced Dual-Stream Feature Fusion with Pre-Trained Model for Acoustic Traffic Monitoring
Dec 26, 2024



Microphone array techniques are widely used in sound source localization and smart city acoustic-based traffic monitoring, but these applications face significant challenges due to the scarcity of labeled real-world traffic audio data and the complexity and diversity of application scenarios. The DCASE Challenge's Task 10 focuses on using multi-channel audio signals to count vehicles (cars or commercial vehicles) and identify their directions (left-to-right or vice versa). In this paper, we propose a graph-enhanced dual-stream feature fusion network (GEDF-Net) for acoustic traffic monitoring, which simultaneously considers vehicle type and direction to improve detection. We propose a graph-enhanced dual-stream feature fusion strategy which consists of a vehicle type feature extraction (VTFE) branch, a vehicle direction feature extraction (VDFE) branch, and a frame-level feature fusion module to combine the type and direction feature for enhanced performance. A pre-trained model (PANNs) is used in the VTFE branch to mitigate data scarcity and enhance the type features, followed by a graph attention mechanism to exploit temporal relationships and highlight important audio events within these features. The frame-level fusion of direction and type features enables fine-grained feature representation, resulting in better detection performance. Experiments demonstrate the effectiveness of our proposed method. GEDF-Net is our submission that achieved 1st place in the DCASE 2024 Challenge Task 10.
AudioSetCaps: An Enriched Audio-Caption Dataset using Automated Generation Pipeline with Large Audio and Language Models
Nov 28, 2024



With the emergence of audio-language models, constructing large-scale paired audio-language datasets has become essential yet challenging for model development, primarily due to the time-intensive and labour-heavy demands involved. While large language models (LLMs) have improved the efficiency of synthetic audio caption generation, current approaches struggle to effectively extract and incorporate detailed audio information. In this paper, we propose an automated pipeline that integrates audio-language models for fine-grained content extraction, LLMs for synthetic caption generation, and a contrastive language-audio pretraining (CLAP) model-based refinement process to improve the quality of captions. Specifically, we employ prompt chaining techniques in the content extraction stage to obtain accurate and fine-grained audio information, while we use the refinement process to mitigate potential hallucinations in the generated captions. Leveraging the AudioSet dataset and the proposed approach, we create AudioSetCaps, a dataset comprising 1.9 million audio-caption pairs, the largest audio-caption dataset at the time of writing. The models trained with AudioSetCaps achieve state-of-the-art performance on audio-text retrieval with R@1 scores of 46.3% for text-to-audio and 59.7% for audio-to-text retrieval and automated audio captioning with the CIDEr score of 84.8. As our approach has shown promising results with AudioSetCaps, we create another dataset containing 4.1 million synthetic audio-language pairs based on the Youtube-8M and VGGSound datasets. To facilitate research in audio-language learning, we have made our pipeline, datasets with 6 million audio-language pairs, and pre-trained models publicly available at https://github.com/JishengBai/AudioSetCaps.
PSELDNets: Pre-trained Neural Networks on Large-scale Synthetic Datasets for Sound Event Localization and Detection
Nov 10, 2024



Sound event localization and detection (SELD) has seen substantial advancements through learning-based methods. These systems, typically trained from scratch on specific datasets, have shown considerable generalization capabilities. Recently, deep neural networks trained on large-scale datasets have achieved remarkable success in the sound event classification (SEC) field, prompting an open question of whether these advancements can be extended to develop general-purpose SELD models. In this paper, leveraging the power of pre-trained SEC models, we propose pre-trained SELD networks (PSELDNets) on large-scale synthetic datasets. These synthetic datasets, generated by convolving sound events with simulated spatial room impulse responses (SRIRs), contain 1,167 hours of audio clips with an ontology of 170 sound classes. These PSELDNets are transferred to downstream SELD tasks. When we adapt PSELDNets to specific scenarios, particularly in low-resource data cases, we introduce a data-efficient fine-tuning method, AdapterBit. PSELDNets are evaluated on a synthetic-test-set using collected SRIRs from TAU Spatial Room Impulse Response Database (TAU-SRIR DB) and achieve satisfactory performance. We also conduct our experiments to validate the transferability of PSELDNets to three publicly available datasets and our own collected audio recordings. Results demonstrate that PSELDNets surpass state-of-the-art systems across all publicly available datasets. Given the need for direction-of-arrival estimation, SELD generally relies on sufficient multi-channel audio clips. However, incorporating the AdapterBit, PSELDNets show more efficient adaptability to various tasks using minimal multi-channel or even just monophonic audio clips, outperforming the traditional fine-tuning approaches.
Differentiable Interacting Multiple Model Particle Filtering
Oct 01, 2024


We propose a sequential Monte Carlo algorithm for parameter learning when the studied model exhibits random discontinuous jumps in behaviour. To facilitate the learning of high dimensional parameter sets, such as those associated to neural networks, we adopt the emerging framework of differentiable particle filtering, wherein parameters are trained by gradient descent. We design a new differentiable interacting multiple model particle filter to be capable of learning the individual behavioural regimes and the model which controls the jumping simultaneously. In contrast to previous approaches, our algorithm allows control of the computational effort assigned per regime whilst using the probability of being in a given regime to guide sampling. Furthermore, we develop a new gradient estimator that has a lower variance than established approaches and remains fast to compute, for which we prove consistency. We establish new theoretical results of the presented algorithms and demonstrate superior numerical performance compared to the previous state-of-the-art algorithms.
FlowSep: Language-Queried Sound Separation with Rectified Flow Matching
Sep 11, 2024



Language-queried audio source separation (LASS) focuses on separating sounds using textual descriptions of the desired sources. Current methods mainly use discriminative approaches, such as time-frequency masking, to separate target sounds and minimize interference from other sources. However, these models face challenges when separating overlapping soundtracks, which may lead to artifacts such as spectral holes or incomplete separation. Rectified flow matching (RFM), a generative model that establishes linear relations between the distribution of data and noise, offers superior theoretical properties and simplicity, but has not yet been explored in sound separation. In this work, we introduce FlowSep, a new generative model based on RFM for LASS tasks. FlowSep learns linear flow trajectories from noise to target source features within the variational autoencoder (VAE) latent space. During inference, the RFM-generated latent features are reconstructed into a mel-spectrogram via the pre-trained VAE decoder, followed by a pre-trained vocoder to synthesize the waveform. Trained on 1,680 hours of audio data, FlowSep outperforms the state-of-the-art models across multiple benchmarks, as evaluated with subjective and objective metrics. Additionally, our results show that FlowSep surpasses a diffusion-based LASS model in both separation quality and inference efficiency, highlighting its strong potential for audio source separation tasks. Code, pre-trained models and demos can be found at: https://audio-agi.github.io/FlowSep_demo/.
Efficient Audio Captioning with Encoder-Level Knowledge Distillation
Jul 19, 2024



Significant improvement has been achieved in automated audio captioning (AAC) with recent models. However, these models have become increasingly large as their performance is enhanced. In this work, we propose a knowledge distillation (KD) framework for AAC. Our analysis shows that in the encoder-decoder based AAC models, it is more effective to distill knowledge into the encoder as compared with the decoder. To this end, we incorporate encoder-level KD loss into training, in addition to the standard supervised loss and sequence-level KD loss. We investigate two encoder-level KD methods, based on mean squared error (MSE) loss and contrastive loss, respectively. Experimental results demonstrate that contrastive KD is more robust than MSE KD, exhibiting superior performance in data-scarce situations. By leveraging audio-only data into training in the KD framework, our student model achieves competitive performance, with an inference speed that is 19 times faster\footnote{An online demo is available at \url{https://huggingface.co/spaces/wsntxxn/efficient_audio_captioning}}.