 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtualPose: Learning Generalizable 3D Human Pose Models from Virtual Data
Jul 20, 2022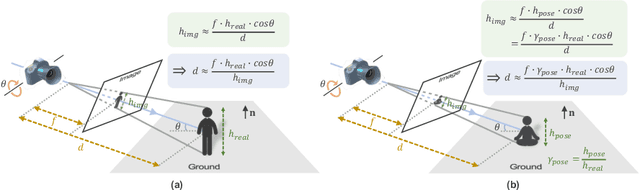
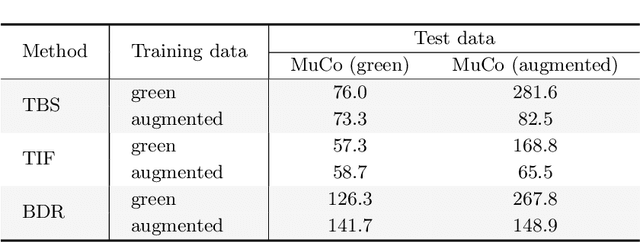
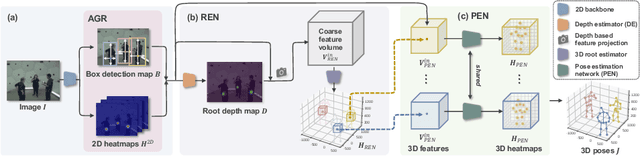
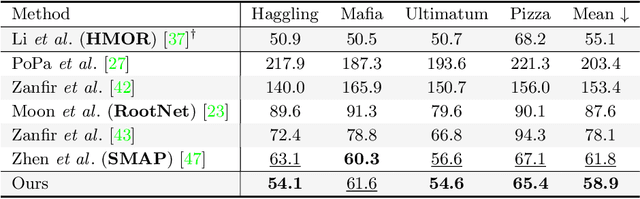
While monocular 3D pose estimation seems to have achieved very accurate results on the public datasets, their generalization ability is largely overlooked. In this work, we perform a systematic evaluation of the existing methods and find that they get notably larger errors when tested on different cameras, human poses and appearance. To address the problem, we introduce VirtualPose, a two-stage learning framework to exploit the hidden "free lunch" specific to this task, i.e. generating infinite number of poses and cameras for training models at no cost. To that end, the first stage transforms images to abstract geometry representations (AGR), and then the second maps them to 3D poses. It addresses the generalization issue from two aspects: (1) the first stage can be trained on diverse 2D datasets to reduce the risk of over-fitting to limited appearance; (2) the second stage can be trained on diverse AGR synthesized from a large number of virtual cameras and poses. It outperforms the SOTA methods without using any paired images and 3D poses from the benchmarks, which paves the way for practical applications. Code is available at https://github.com/wkom/VirtualPose.
ReSTR: Convolution-free Referring Image Segmentation Using Transformers
Mar 31, 2022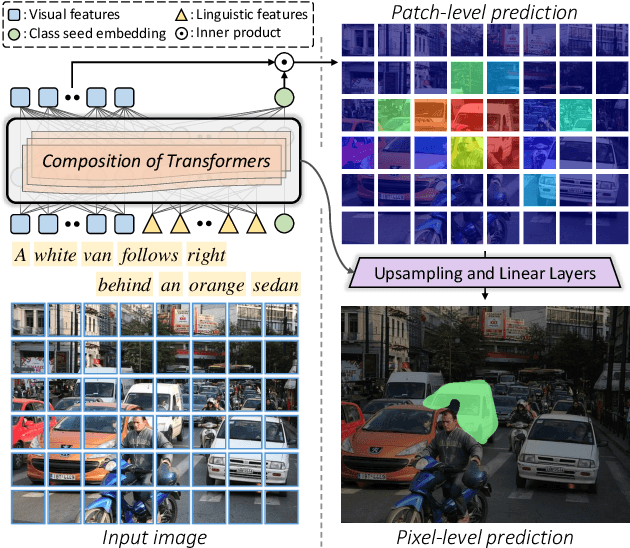
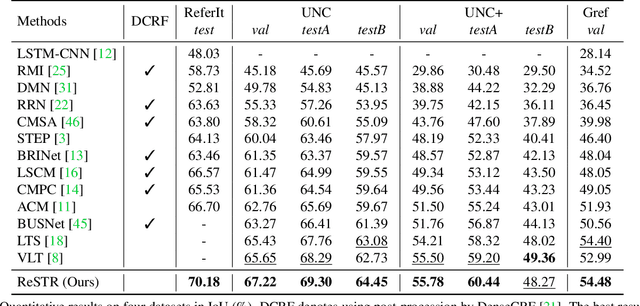
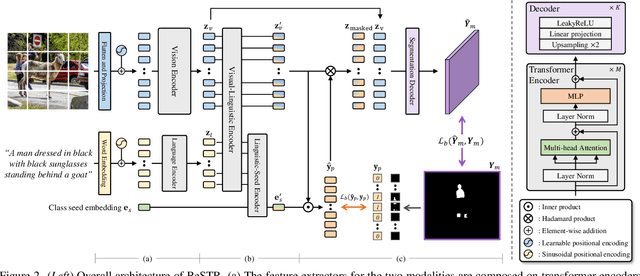
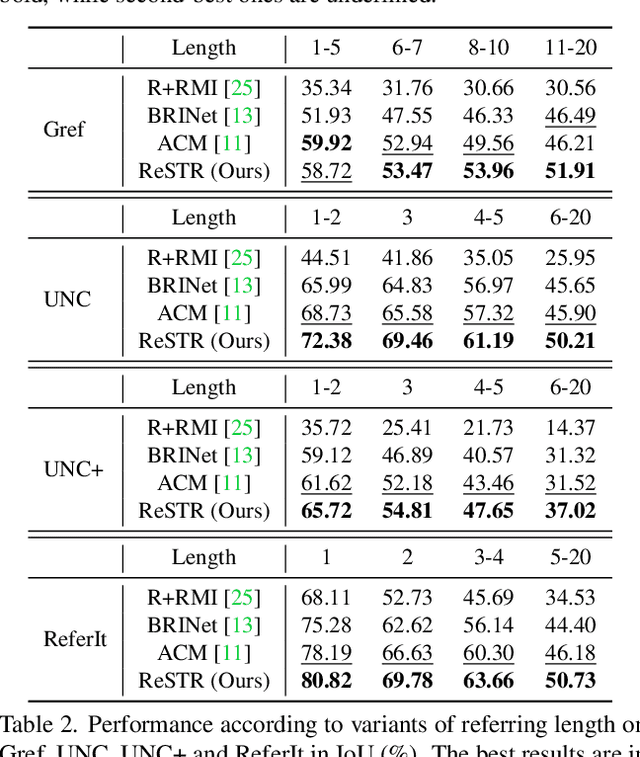
Referring image segmentation is an advanced semantic segmentation task where target is not a predefined class but is described in natural language. Most of existing methods for this task rely heavily on convolutional neural networks, which however have trouble capturing long-range dependencies between entities in the language expression and are not flexible enough for modeling interactions between the two different modalities. To address these issues, we present the first convolution-free model for referring image segmentation using transformers, dubbed ReSTR. Since it extracts features of both modalities through transformer encoders, it can capture long-range dependencies between entities within each modality. Also, ReSTR fuses features of the two modalities by a self-attention encoder, which enables flexible and adaptive interactions between the two modalities in the fusion process. The fused features are fed to a segmentation module, which works adaptively according to the image and language expression in hand. ReSTR is evaluated and compared with previous work on all public benchmarks, where it outperforms all existing models.
Correlation-Aware Deep Tracking
Mar 03, 2022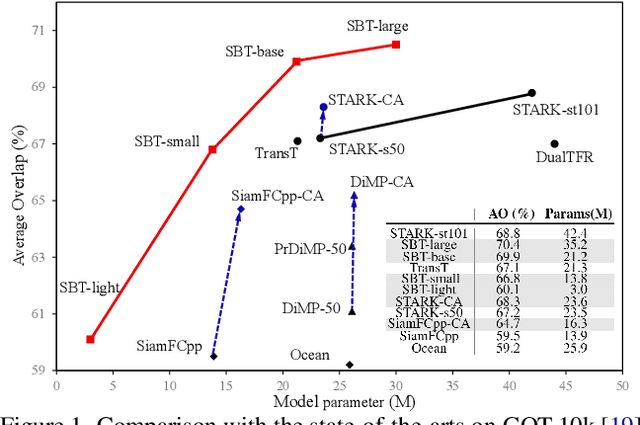

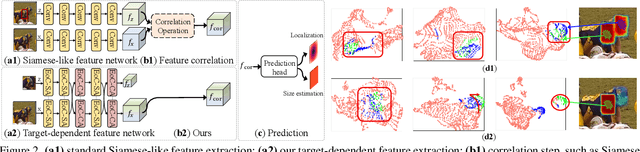
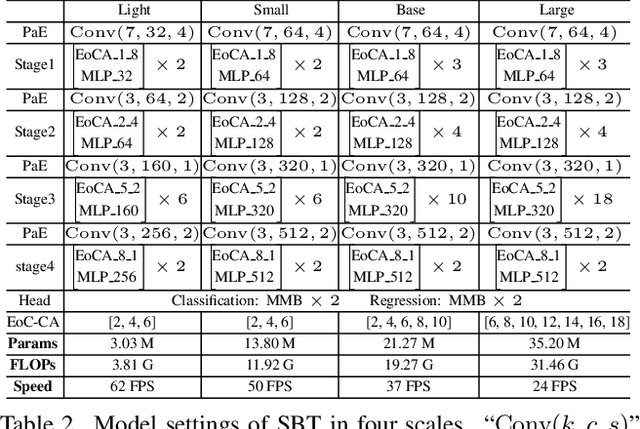
Robustness and discrimination power are two fundamental requirements in visual object tracking. In most tracking paradigms, we find that the features extracted by the popular Siamese-like networks cannot fully discriminatively model the tracked targets and distractor objects, hindering them from simultaneously meeting these two requirements. While most methods focus on designing robust correlation operations, we propose a novel target-dependent feature network inspired by the self-/cross-attention scheme. In contrast to the Siamese-like feature extraction, our network deeply embeds cross-image feature correlation in multiple layers of the feature network. By extensively matching the features of the two images through multiple layers, it is able to suppress non-target features, resulting in instance-varying feature extraction. The output features of the search image can be directly used for predicting target locations without extra correlation step. Moreover, our model can be flexibly pre-trained on abundant unpaired images, leading to notably faster convergence than the existing methods. Extensive experiments show our method achieves the state-of-the-art results while running at real-time. Our feature networks also can be applied to existing tracking pipelines seamlessly to raise the tracking performance. Code will be available.
Retriever: Learning Content-Style Representation as a Token-Level Bipartite Graph
Feb 24, 2022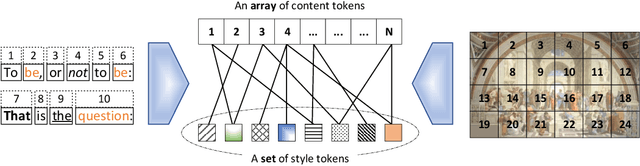
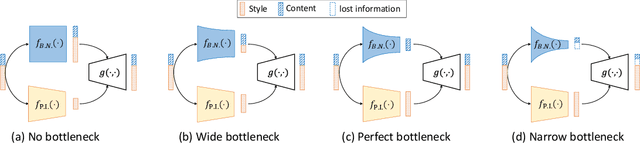

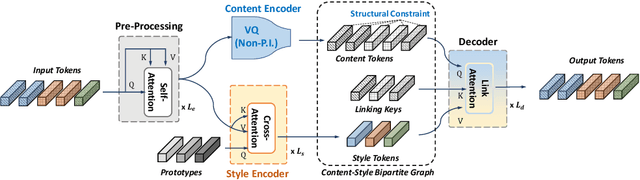
This paper addresses the unsupervised learning of content-style decomposed representation. We first give a definition of style and then model the content-style representation as a token-level bipartite graph. An unsupervised framework, named Retriever, is proposed to learn such representations. First, a cross-attention module is employed to retrieve permutation invariant (P.I.) information, defined as style, from the input data. Second, a vector quantization (VQ) module is used, together with man-induced constraints, to produce interpretable content tokens. Last, an innovative link attention module serves as the decoder to reconstruct data from the decomposed content and style, with the help of the linking keys. Being modal-agnostic, the proposed Retriever is evaluated in both speech and image domains. The state-of-the-art zero-shot voice conversion performance confirms the disentangling ability of our framework. Top performance is also achieved in the part discovery task for images, verifying the interpretability of our representation. In addition, the vivid part-based style transfer quality demonstrates the potential of Retriever to support various fascinating generative tasks. Project page at https://ydcustc.github.io/retriever-demo/.
When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism
Jan 26, 2022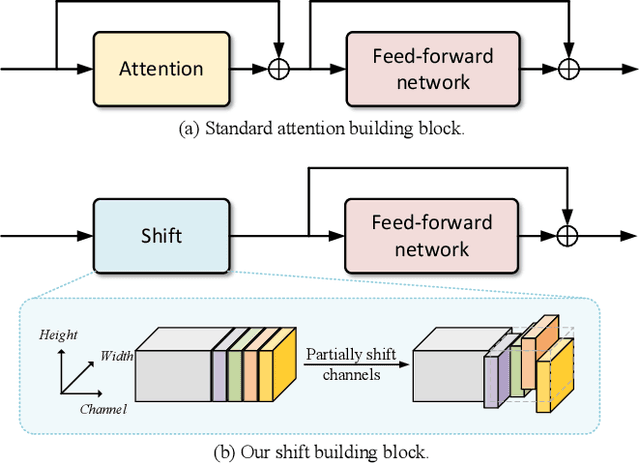
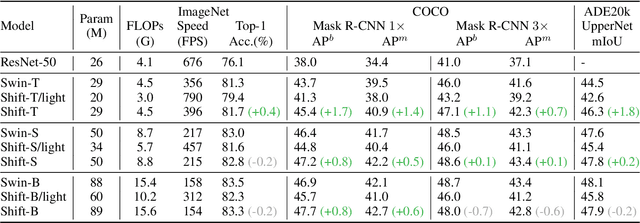
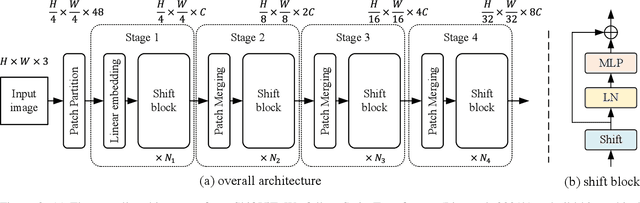
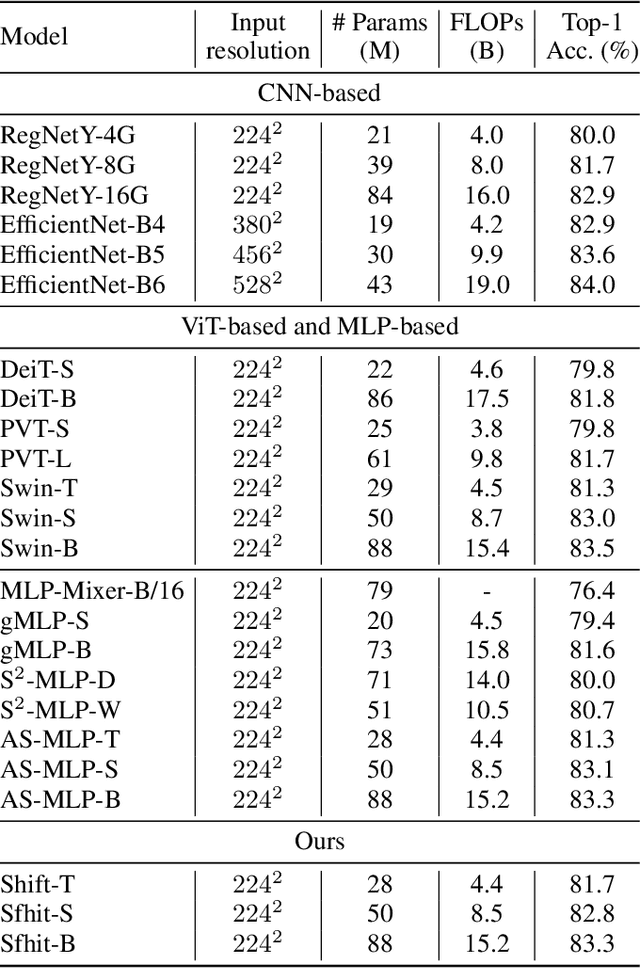
Attention mechanism has been widely believed as the key to success of vision transformers (ViTs), since it provides a flexible and powerful way to model spatial relationships. However, is the attention mechanism truly an indispensable part of ViT? Can it be replaced by some other alternatives? To demystify the role of attention mechanism, we simplify it into an extremely simple case: ZERO FLOP and ZERO parameter. Concretely, we revisit the shift operation. It does not contain any parameter or arithmetic calculation. The only operation is to exchange a small portion of the channels between neighboring features. Based on this simple operation, we construct a new backbone network, namely ShiftViT, where the attention layers in ViT are substituted by shift operations. Surprisingly, ShiftViT works quite well in several mainstream tasks, e.g., classification, detection, and segmentation. The performance is on par with or even better than the strong baseline Swin Transformer. These results suggest that the attention mechanism might not be the vital factor that makes ViT successful. It can be even replaced by a zero-parameter operation. We should pay more attentions to the remaining parts of ViT in the future work. Code is available at github.com/microsoft/SPACH.
Lifelong Unsupervised Domain Adaptive Person Re-identification with Coordinated Anti-forgetting and Adaptation
Dec 13, 2021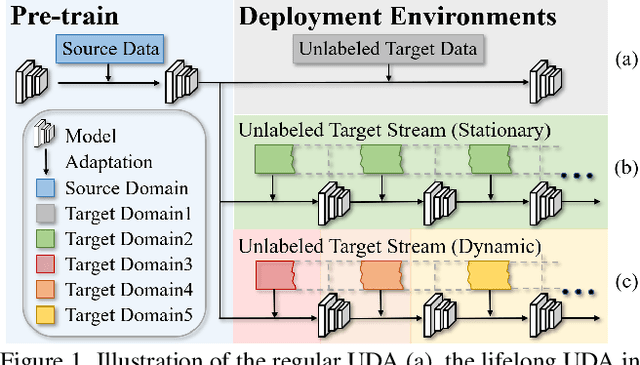

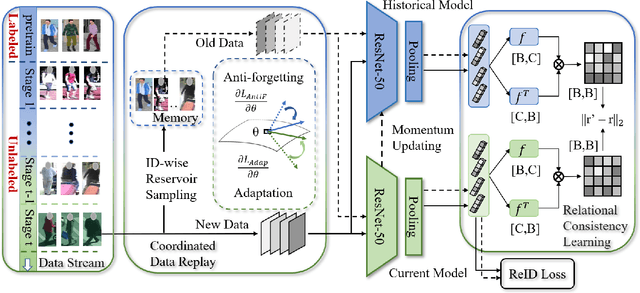
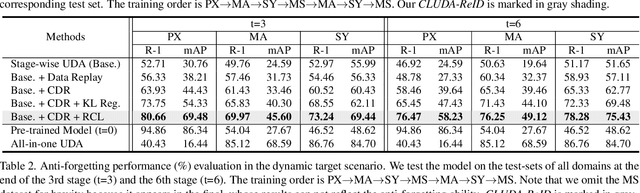
Unsupervised domain adaptive person re-identification (ReID) has been extensively investigated to mitigate the adverse effects of domain gaps. Those works assume the target domain data can be accessible all at once. However, for the real-world streaming data, this hinders the timely adaptation to changing data statistics and sufficient exploitation of increasing samples. In this paper, to address more practical scenarios, we propose a new task, Lifelong Unsupervised Domain Adaptive (LUDA) person ReID. This is challenging because it requires the model to continuously adapt to unlabeled data of the target environments while alleviating catastrophic forgetting for such a fine-grained person retrieval task. We design an effective scheme for this task, dubbed CLUDA-ReID, where the anti-forgetting is harmoniously coordinated with the adaptation. Specifically, a meta-based Coordinated Data Replay strategy is proposed to replay old data and update the network with a coordinated optimization direction for both adaptation and memorization. Moreover, we propose Relational Consistency Learning for old knowledge distillation/inheritance in line with the objective of retrieval-based tasks. We set up two evaluation settings to simulate the practical application scenarios. Extensive experiments demonstrate the effectiveness of our CLUDA-ReID for both scenarios with stationary target streams and scenarios with dynamic target streams.
SelectAugment: Hierarchical Deterministic Sample Selection for Data Augmentation
Dec 06, 2021
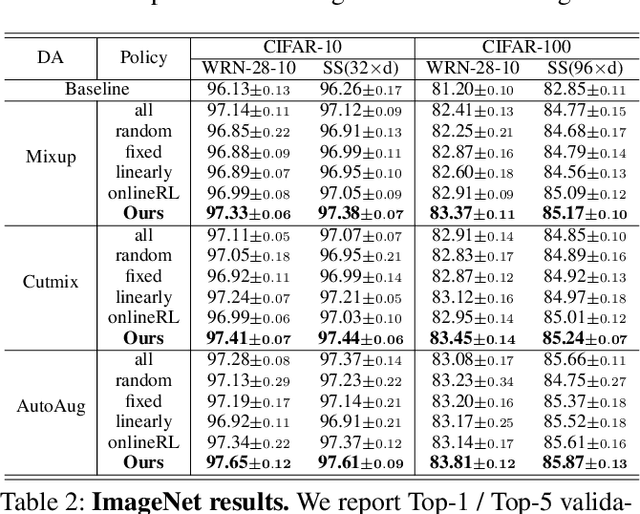
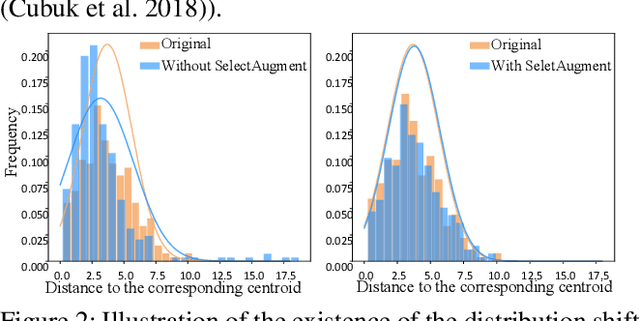
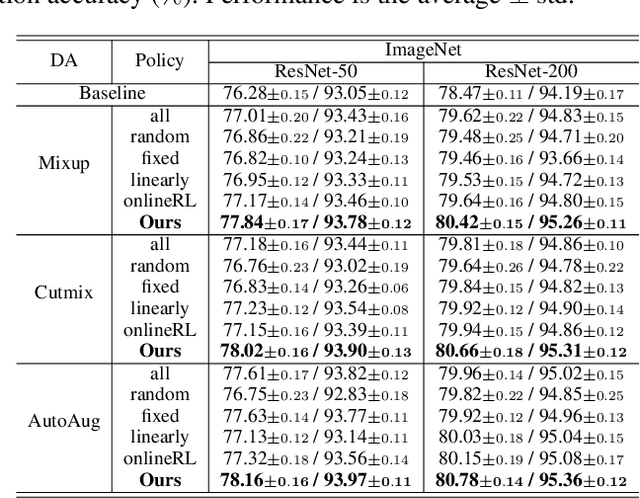
Data augmentation (DA) has been widely investigated to facilitate model optimization in many tasks. However, in most cases, data augmentation is randomly performed for each training sample with a certain probability, which might incur content destruction and visual ambiguities. To eliminate this, in this paper, we propose an effective approach, dubbed SelectAugment, to select samples to be augmented in a deterministic and online manner based on the sample contents and the network training status. Specifically, in each batch, we first determine the augmentation ratio, and then decide whether to augment each training sample under this ratio. We model this process as a two-step Markov decision process and adopt Hierarchical Reinforcement Learning (HRL) to learn the augmentation policy. In this way, the negative effects of the randomness in selecting samples to augment can be effectively alleviated and the effectiveness of DA is improved. Extensive experiments demonstrate that our proposed SelectAugment can be adapted upon numerous commonly used DA methods, e.g., Mixup, Cutmix, AutoAugment, etc, and improve their performance on multiple benchmark datasets of image classification and fine-grained image recognition.
Learning Tracking Representations via Dual-Branch Fully Transformer Networks
Dec 05, 2021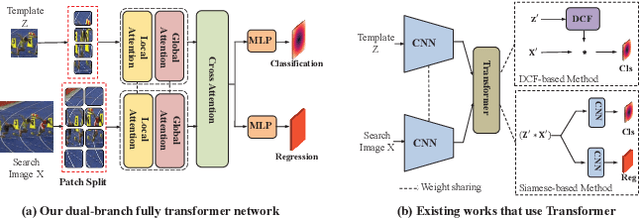

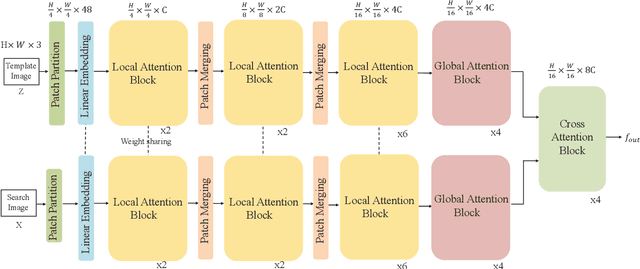
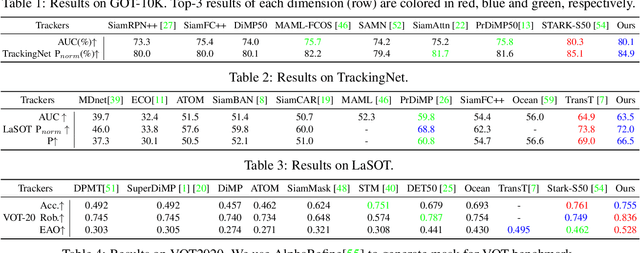
We present a Siamese-like Dual-branch network based on solely Transformers for tracking. Given a template and a search image, we divide them into non-overlapping patches and extract a feature vector for each patch based on its matching results with others within an attention window. For each token, we estimate whether it contains the target object and the corresponding size. The advantage of the approach is that the features are learned from matching, and ultimately, for matching. So the features are aligned with the object tracking task. The method achieves better or comparable results as the best-performing methods which first use CNN to extract features and then use Transformer to fuse them. It outperforms the state-of-the-art methods on the GOT-10k and VOT2020 benchmarks. In addition, the method achieves real-time inference speed (about $40$ fps) on one GPU. The code and models will be released.
Confounder Identification-free Causal Visual Feature Learning
Nov 26, 2021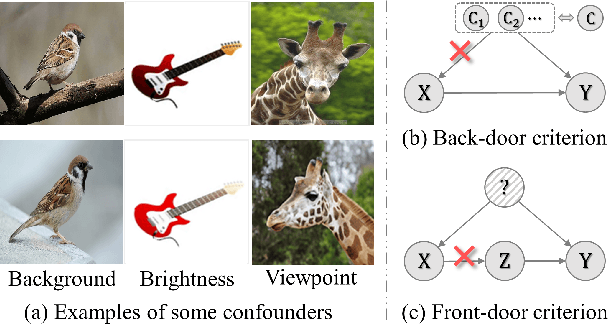
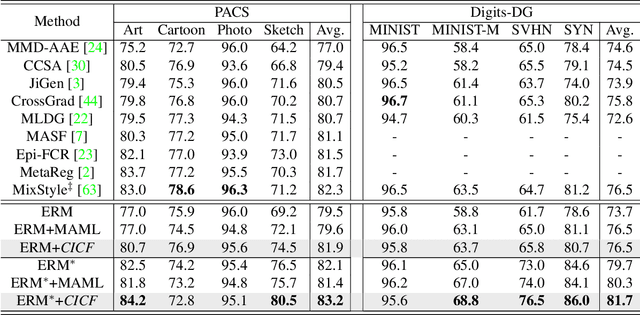
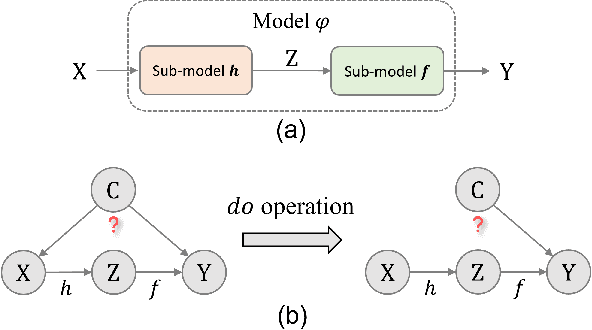
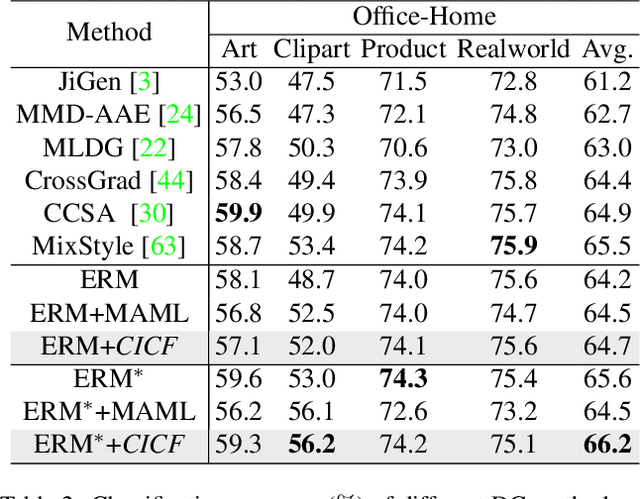
Confounders in deep learning are in general detrimental to model's generalization where they infiltrate feature representations. Therefore, learning causal features that are free of interference from confounders is important. Most previous causal learning based approaches employ back-door criterion to mitigate the adverse effect of certain specific confounder, which require the explicit identification of confounder. However, in real scenarios, confounders are typically diverse and difficult to be identified. In this paper, we propose a novel Confounder Identification-free Causal Visual Feature Learning (CICF) method, which obviates the need for identifying confounders. CICF models the interventions among different samples based on front-door criterion, and then approximates the global-scope intervening effect upon the instance-level interventions from the perspective of optimization. In this way, we aim to find a reliable optimization direction, which avoids the intervening effects of confounders, to learn causal features. Furthermore, we uncover the relation between CICF and the popular meta-learning strategy MAML, and provide an interpretation of why MAML works from the theoretical perspective of causal learning for the first time. Thanks to the effective learning of causal features, our CICF enables models to have superior generalization capability. Extensive experiments on domain generalization benchmark datasets demonstrate the effectiveness of our CICF, which achieves the state-of-the-art performance.
Multi-Scale Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition
Nov 07, 2021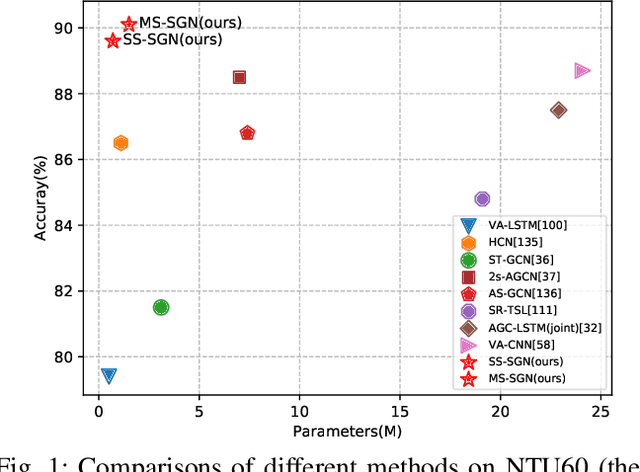

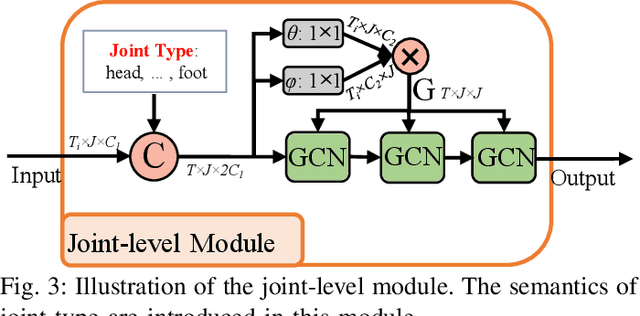
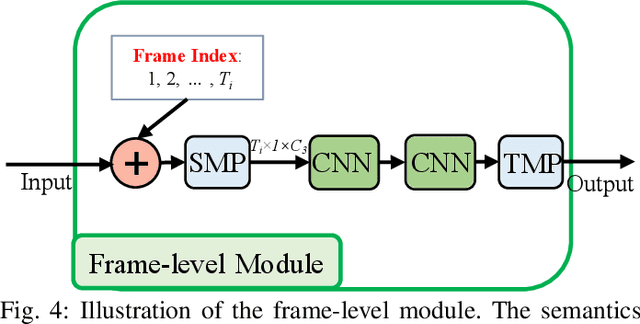
Skeleton data is of low dimension. However, there is a trend of using very deep and complicated feedforward neural networks to model the skeleton sequence without considering the complexity in recent year. In this paper, a simple yet effective multi-scale semantics-guided neural network (MS-SGN) is proposed for skeleton-based action recognition. We explicitly introduce the high level semantics of joints (joint type and frame index) into the network to enhance the feature representation capability of joints. Moreover, a multi-scale strategy is proposed to be robust to the temporal scale variations. In addition, we exploit the relationship of joints hierarchically through two modules, i.e., a joint-level module for modeling the correlations of joints in the same frame and a frame-level module for modeling the temporal dependencies of frames. With an order of magnitude smaller model size than most previous methods, MSSGN achieves the state-of-the-art performance on the NTU60, NTU120, and SYSU datasets.