 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuMoS: A Framework for Preserving Security of Quantum Machine Learning Model
Apr 23, 2023



Security has always been a critical issue in machine learning (ML) applications. Due to the high cost of model training -- such as collecting relevant samples, labeling data, and consuming computing power -- model-stealing attack is one of the most fundamental but vitally important issues. When it comes to quantum computing, such a quantum machine learning (QML) model-stealing attack also exists and it is even more severe because the traditional encryption method can hardly be directly applied to quantum computation. On the other hand, due to the limited quantum computing resources, the monetary cost of training QML model can be even higher than classical ones in the near term. Therefore, a well-tuned QML model developed by a company can be delegated to a quantum cloud provider as a service to be used by ordinary users. In this case, the QML model will be leaked if the cloud provider is under attack. To address such a problem, we propose a novel framework, namely QuMoS, to preserve model security. Instead of applying encryption algorithms, we propose to distribute the QML model to multiple physically isolated quantum cloud providers. As such, even if the adversary in one provider can obtain a partial model, the information of the full model is maintained in the QML service company. Although promising, we observed an arbitrary model design under distributed settings cannot provide model security. We further developed a reinforcement learning-based security engine, which can automatically optimize the model design under the distributed setting, such that a good trade-off between model performance and security can be made. Experimental results on four datasets show that the model design proposed by QuMoS can achieve a close accuracy to the model designed with neural architecture search under centralized settings while providing the highest security than the baselines.
All-in-One: A Highly Representative DNN Pruning Framework for Edge Devices with Dynamic Power Management
Dec 09, 2022



During the deployment of deep neural networks (DNNs) on edge devices, many research efforts are devoted to the limited hardware resource. However, little attention is paid to the influence of dynamic power management. As edge devices typically only have a budget of energy with batteries (rather than almost unlimited energy support on servers or workstations), their dynamic power management often changes the execution frequency as in the widely-used dynamic voltage and frequency scaling (DVFS) technique. This leads to highly unstable inference speed performance, especially for computation-intensive DNN models, which can harm user experience and waste hardware resources. We firstly identify this problem and then propose All-in-One, a highly representative pruning framework to work with dynamic power management using DVFS. The framework can use only one set of model weights and soft masks (together with other auxiliary parameters of negligible storage) to represent multiple models of various pruning ratios. By re-configuring the model to the corresponding pruning ratio for a specific execution frequency (and voltage), we are able to achieve stable inference speed, i.e., keeping the difference in speed performance under various execution frequencies as small as possible. Our experiments demonstrate that our method not only achieves high accuracy for multiple models of different pruning ratios, but also reduces their variance of inference latency for various frequencies, with minimal memory consumption of only one model and one soft mask.
QuEst: Graph Transformer for Quantum Circuit Reliability Estimation
Oct 30, 2022Among different quantum algorithms, PQC for QML show promises on near-term devices. To facilitate the QML and PQC research, a recent python library called TorchQuantum has been released. It can construct, simulate, and train PQC for machine learning tasks with high speed and convenient debugging supports. Besides quantum for ML, we want to raise the community's attention on the reversed direction: ML for quantum. Specifically, the TorchQuantum library also supports using data-driven ML models to solve problems in quantum system research, such as predicting the impact of quantum noise on circuit fidelity and improving the quantum circuit compilation efficiency. This paper presents a case study of the ML for quantum part. Since estimating the noise impact on circuit reliability is an essential step toward understanding and mitigating noise, we propose to leverage classical ML to predict noise impact on circuit fidelity. Inspired by the natural graph representation of quantum circuits, we propose to leverage a graph transformer model to predict the noisy circuit fidelity. We firstly collect a large dataset with a variety of quantum circuits and obtain their fidelity on noisy simulators and real machines. Then we embed each circuit into a graph with gate and noise properties as node features, and adopt a graph transformer to predict the fidelity. Evaluated on 5 thousand random and algorithm circuits, the graph transformer predictor can provide accurate fidelity estimation with RMSE error 0.04 and outperform a simple neural network-based model by 0.02 on average. It can achieve 0.99 and 0.95 R$^2$ scores for random and algorithm circuits, respectively. Compared with circuit simulators, the predictor has over 200X speedup for estimating the fidelity.
Towards Real-Time Temporal Graph Learning
Oct 12, 2022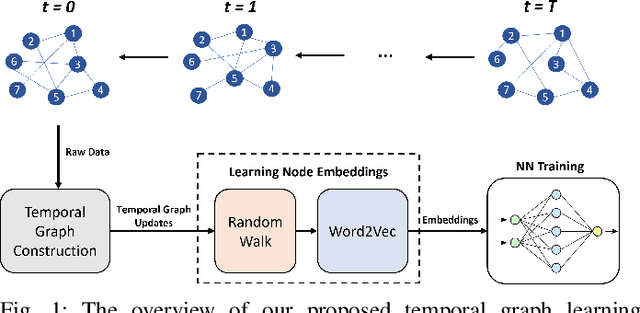
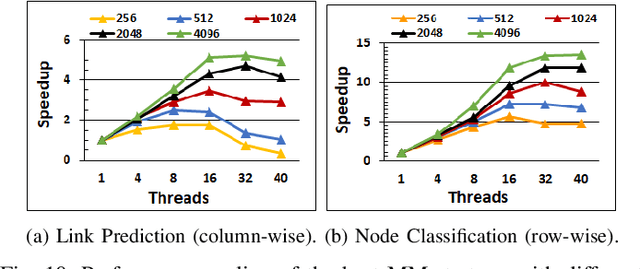
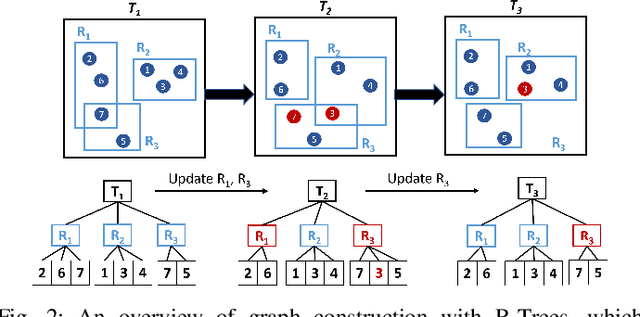
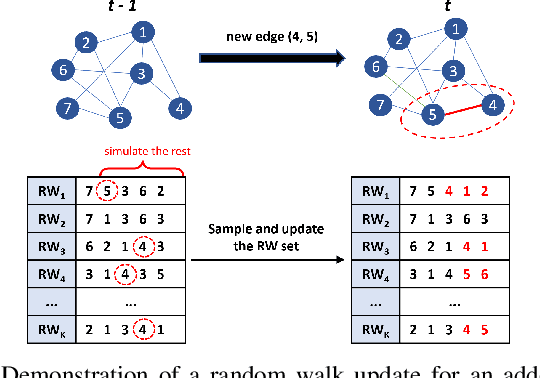
In recent years, graph representation learning has gained significant popularity, which aims to generate node embeddings that capture features of graphs. One of the methods to achieve this is employing a technique called random walks that captures node sequences in a graph and then learns embeddings for each node using a natural language processing technique called Word2Vec. These embeddings are then used for deep learning on graph data for classification tasks, such as link prediction or node classification. Prior work operates on pre-collected temporal graph data and is not designed to handle updates on a graph in real-time. Real world graphs change dynamically and their entire temporal updates are not available upfront. In this paper, we propose an end-to-end graph learning pipeline that performs temporal graph construction, creates low-dimensional node embeddings, and trains multi-layer neural network models in an online setting. The training of the neural network models is identified as the main performance bottleneck as it performs repeated matrix operations on many sequentially connected low-dimensional kernels. We propose to unlock fine-grain parallelism in these low-dimensional kernels to boost performance of model training.
Towards Sparsification of Graph Neural Networks
Sep 11, 2022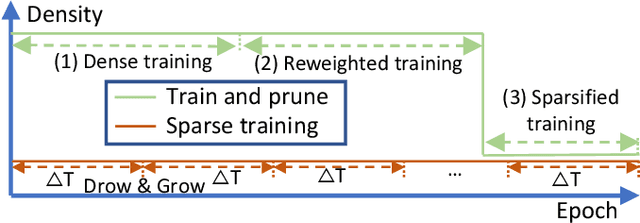
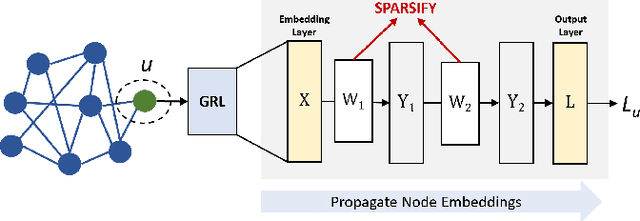
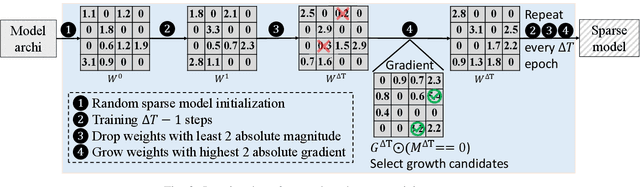

As real-world graphs expand in size, larger GNN models with billions of parameters are deployed. High parameter count in such models makes training and inference on graphs expensive and challenging. To reduce the computational and memory costs of GNNs, optimization methods such as pruning the redundant nodes and edges in input graphs have been commonly adopted. However, model compression, which directly targets the sparsification of model layers, has been mostly limited to traditional Deep Neural Networks (DNNs) used for tasks such as image classification and object detection. In this paper, we utilize two state-of-the-art model compression methods (1) train and prune and (2) sparse training for the sparsification of weight layers in GNNs. We evaluate and compare the efficiency of both methods in terms of accuracy, training sparsity, and training FLOPs on real-world graphs. Our experimental results show that on the ia-email, wiki-talk, and stackoverflow datasets for link prediction, sparse training with much lower training FLOPs achieves a comparable accuracy with the train and prune method. On the brain dataset for node classification, sparse training uses a lower number FLOPs (less than 1/7 FLOPs of train and prune method) and preserves a much better accuracy performance under extreme model sparsity.
A Length Adaptive Algorithm-Hardware Co-design of Transformer on FPGA Through Sparse Attention and Dynamic Pipelining
Aug 07, 2022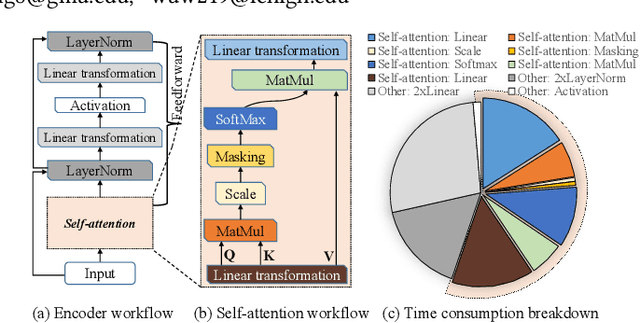
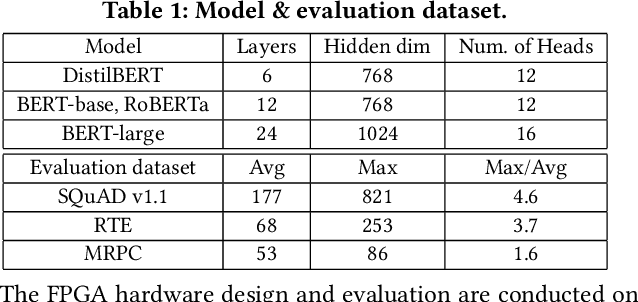
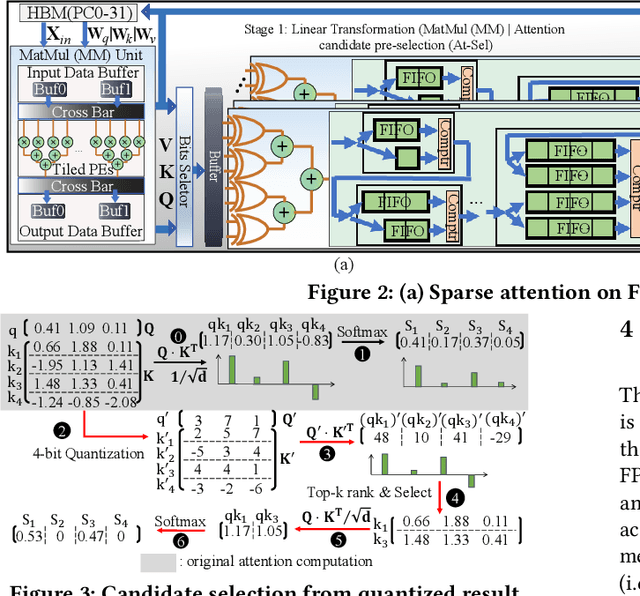
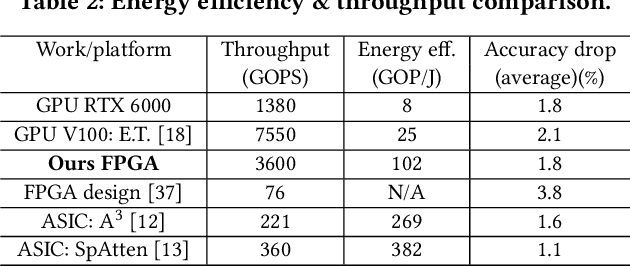
Transformers are considered one of the most important deep learning models since 2018, in part because it establishes state-of-the-art (SOTA) records and could potentially replace existing Deep Neural Networks (DNNs). Despite the remarkable triumphs, the prolonged turnaround time of Transformer models is a widely recognized roadblock. The variety of sequence lengths imposes additional computing overhead where inputs need to be zero-padded to the maximum sentence length in the batch to accommodate the parallel computing platforms. This paper targets the field-programmable gate array (FPGA) and proposes a coherent sequence length adaptive algorithm-hardware co-design for Transformer acceleration. Particularly, we develop a hardware-friendly sparse attention operator and a length-aware hardware resource scheduling algorithm. The proposed sparse attention operator brings the complexity of attention-based models down to linear complexity and alleviates the off-chip memory traffic. The proposed length-aware resource hardware scheduling algorithm dynamically allocates the hardware resources to fill up the pipeline slots and eliminates bubbles for NLP tasks. Experiments show that our design has very small accuracy loss and has 80.2 $\times$ and 2.6 $\times$ speedup compared to CPU and GPU implementation, and 4 $\times$ higher energy efficiency than state-of-the-art GPU accelerator optimized via CUBLAS GEMM.
Quantum Neural Network Compression
Jul 05, 2022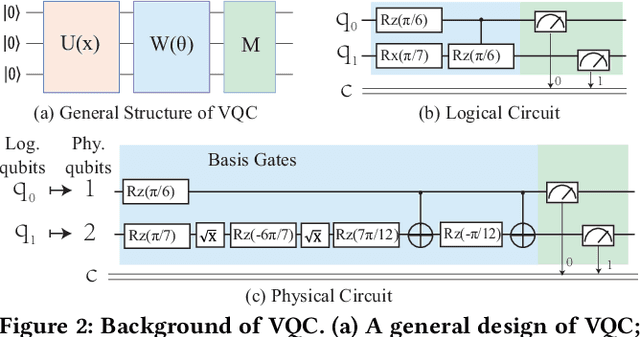
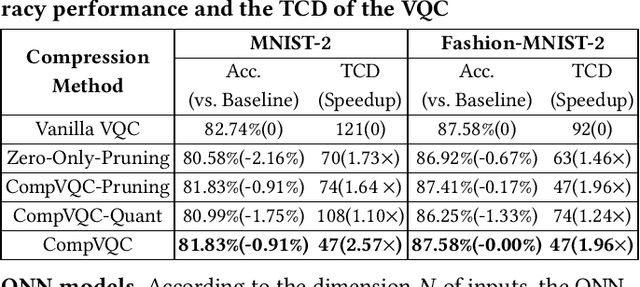
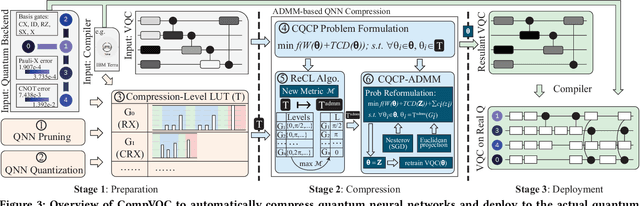
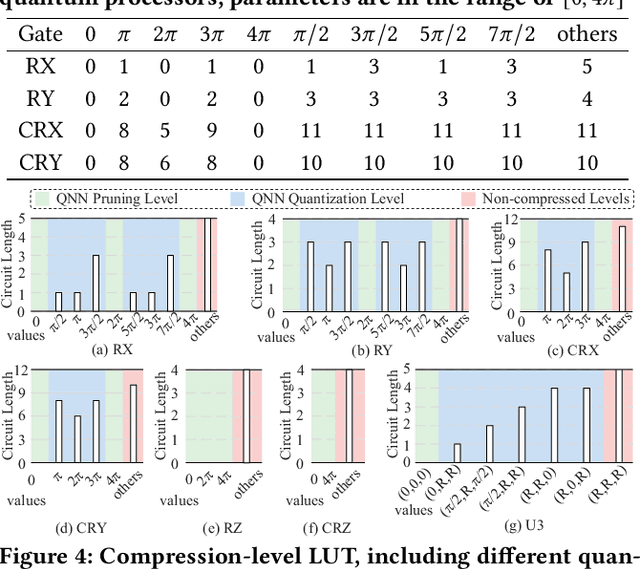
Model compression, such as pruning and quantization, has been widely applied to optimize neural networks on resource-limited classical devices. Recently, there are growing interest in variational quantum circuits (VQC), that is, a type of neural network on quantum computers (a.k.a., quantum neural networks). It is well known that the near-term quantum devices have high noise and limited resources (i.e., quantum bits, qubits); yet, how to compress quantum neural networks has not been thoroughly studied. One might think it is straightforward to apply the classical compression techniques to quantum scenarios. However, this paper reveals that there exist differences between the compression of quantum and classical neural networks. Based on our observations, we claim that the compilation/traspilation has to be involved in the compression process. On top of this, we propose the very first systematical framework, namely CompVQC, to compress quantum neural networks (QNNs).In CompVQC, the key component is a novel compression algorithm, which is based on the alternating direction method of multipliers (ADMM) approach. Experiments demonstrate the advantage of the CompVQC, reducing the circuit depth (almost over 2.5 %) with a negligible accuracy drop (<1%), which outperforms other competitors. Another promising truth is our CompVQC can indeed promote the robustness of the QNN on the near-term noisy quantum devices.
The Larger The Fairer? Small Neural Networks Can Achieve Fairness for Edge Devices
Feb 23, 2022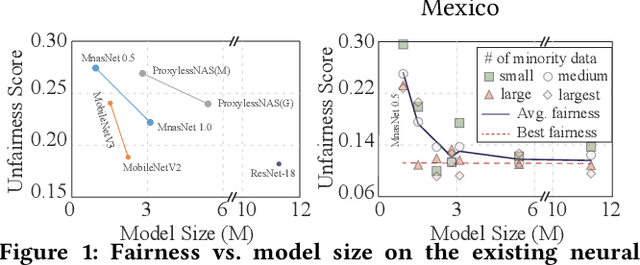
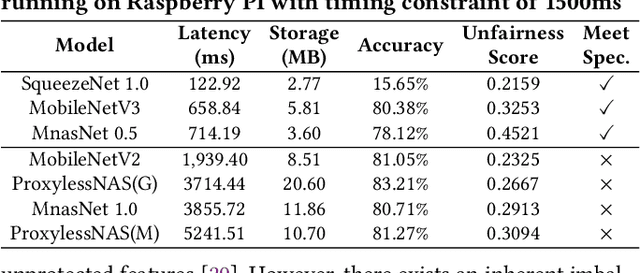
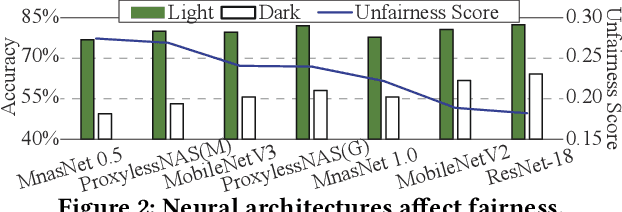
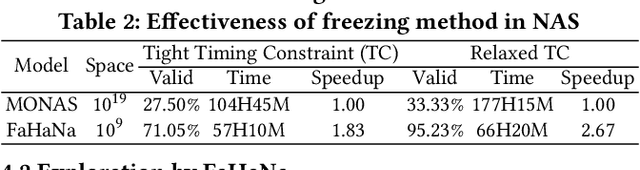
Along with the progress of AI democratization, neural networks are being deployed more frequently in edge devices for a wide range of applications. Fairness concerns gradually emerge in many applications, such as face recognition and mobile medical. One fundamental question arises: what will be the fairest neural architecture for edge devices? By examining the existing neural networks, we observe that larger networks typically are fairer. But, edge devices call for smaller neural architectures to meet hardware specifications. To address this challenge, this work proposes a novel Fairness- and Hardware-aware Neural architecture search framework, namely FaHaNa. Coupled with a model freezing approach, FaHaNa can efficiently search for neural networks with balanced fairness and accuracy, while guaranteed to meet hardware specifications. Results show that FaHaNa can identify a series of neural networks with higher fairness and accuracy on a dermatology dataset. Target edge devices, FaHaNa finds a neural architecture with slightly higher accuracy, 5.28x smaller size, 15.14% higher fairness score, compared with MobileNetV2; meanwhile, on Raspberry PI and Odroid XU-4, it achieves 5.75x and 5.79x speedup.
Automated Architecture Search for Brain-inspired Hyperdimensional Computing
Feb 11, 2022
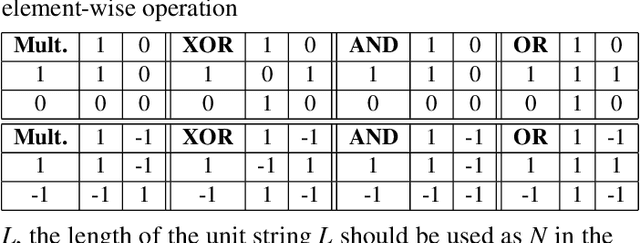
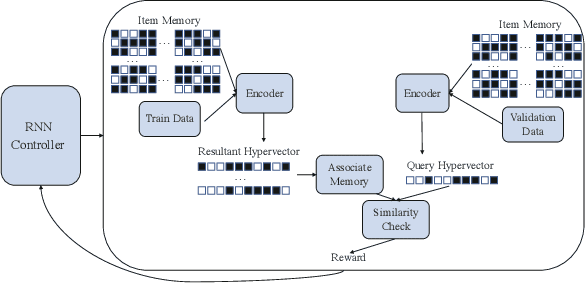
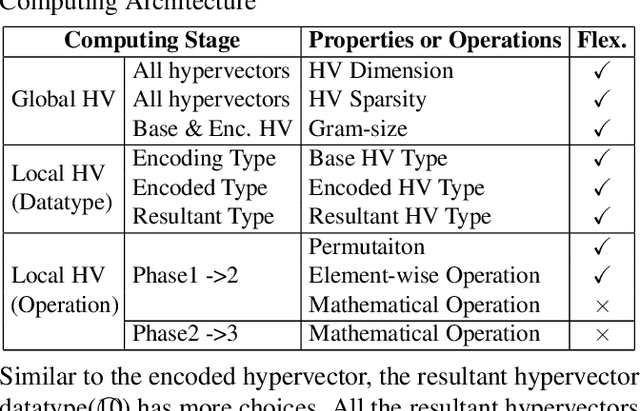
This paper represents the first effort to explore an automated architecture search for hyperdimensional computing (HDC), a type of brain-inspired neural network. Currently, HDC design is largely carried out in an application-specific ad-hoc manner, which significantly limits its application. Furthermore, the approach leads to inferior accuracy and efficiency, which suggests that HDC cannot perform competitively against deep neural networks. Herein, we present a thorough study to formulate an HDC architecture search space. On top of the search space, we apply reinforcement-learning to automatically explore the HDC architectures. The searched HDC architectures show competitive performance on case studies involving a drug discovery dataset and a language recognition task. On the Clintox dataset, which tries to learn features from developed drugs that passed/failed clinical trials for toxicity reasons, the searched HDC architecture obtains the state-of-the-art ROC-AUC scores, which are 0.80% higher than the manually designed HDC and 9.75% higher than conventional neural networks. Similar results are achieved on the language recognition task, with 1.27% higher performance than conventional methods.
One Proxy Device Is Enough for Hardware-Aware Neural Architecture Search
Nov 03, 2021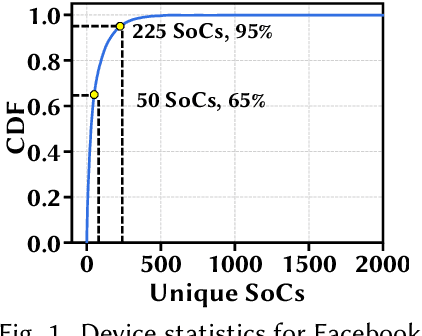
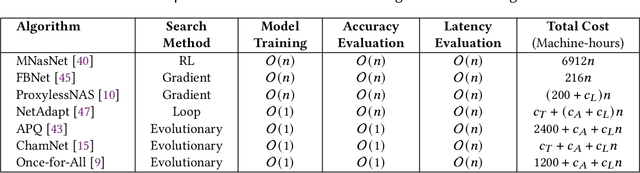

Convolutional neural networks (CNNs) are used in numerous real-world applications such as vision-based autonomous driving and video content analysis. To run CNN inference on various target devices, hardware-aware neural architecture search (NAS) is crucial. A key requirement of efficient hardware-aware NAS is the fast evaluation of inference latencies in order to rank different architectures. While building a latency predictor for each target device has been commonly used in state of the art, this is a very time-consuming process, lacking scalability in the presence of extremely diverse devices. In this work, we address the scalability challenge by exploiting latency monotonicity -- the architecture latency rankings on different devices are often correlated. When strong latency monotonicity exists, we can re-use architectures searched for one proxy device on new target devices, without losing optimality. In the absence of strong latency monotonicity, we propose an efficient proxy adaptation technique to significantly boost the latency monotonicity. Finally, we validate our approach and conduct experiments with devices of different platforms on multiple mainstream search spaces, including MobileNet-V2, MobileNet-V3, NAS-Bench-201, ProxylessNAS and FBNet. Our results highlight that, by using just one proxy device, we can find almost the same Pareto-optimal architectures as the existing per-device NAS, while avoiding the prohibitive cost of building a latency predictor for each device. GitHub: https://github.com/Ren-Research/OneProxy
* Accepted by the ACM SIGMETRICS 2022. Published in the Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 5, no. 3, Article 34, December 2021. GitHub: https://github.com/Ren-Research/OneProxy