 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMG-TSD: Multi-Granularity Time Series Diffusion Models with Guided Learning Process
Mar 09, 2024



Recently, diffusion probabilistic models have attracted attention in generative time series forecasting due to their remarkable capacity to generate high-fidelity samples. However, the effective utilization of their strong modeling ability in the probabilistic time series forecasting task remains an open question, partially due to the challenge of instability arising from their stochastic nature. To address this challenge, we introduce a novel Multi-Granularity Time Series Diffusion (MG-TSD) model, which achieves state-of-the-art predictive performance by leveraging the inherent granularity levels within the data as given targets at intermediate diffusion steps to guide the learning process of diffusion models. The way to construct the targets is motivated by the observation that the forward process of the diffusion model, which sequentially corrupts the data distribution to a standard normal distribution, intuitively aligns with the process of smoothing fine-grained data into a coarse-grained representation, both of which result in a gradual loss of fine distribution features. In the study, we derive a novel multi-granularity guidance diffusion loss function and propose a concise implementation method to effectively utilize coarse-grained data across various granularity levels. More importantly, our approach does not rely on additional external data, making it versatile and applicable across various domains. Extensive experiments conducted on real-world datasets demonstrate that our MG-TSD model outperforms existing time series prediction methods.
Leveraging Large Language Model for Automatic Evolving of Industrial Data-Centric R&D Cycle
Oct 17, 2023



In the wake of relentless digital transformation, data-driven solutions are emerging as powerful tools to address multifarious industrial tasks such as forecasting, anomaly detection, planning, and even complex decision-making. Although data-centric R&D has been pivotal in harnessing these solutions, it often comes with significant costs in terms of human, computational, and time resources. This paper delves into the potential of large language models (LLMs) to expedite the evolution cycle of data-centric R&D. Assessing the foundational elements of data-centric R&D, including heterogeneous task-related data, multi-facet domain knowledge, and diverse computing-functional tools, we explore how well LLMs can understand domain-specific requirements, generate professional ideas, utilize domain-specific tools to conduct experiments, interpret results, and incorporate knowledge from past endeavors to tackle new challenges. We take quantitative investment research as a typical example of industrial data-centric R&D scenario and verified our proposed framework upon our full-stack open-sourced quantitative research platform Qlib and obtained promising results which shed light on our vision of automatic evolving of industrial data-centric R&D cycle.
Microstructure-Empowered Stock Factor Extraction and Utilization
Aug 16, 2023High-frequency quantitative investment is a crucial aspect of stock investment. Notably, order flow data plays a critical role as it provides the most detailed level of information among high-frequency trading data, including comprehensive data from the order book and transaction records at the tick level. The order flow data is extremely valuable for market analysis as it equips traders with essential insights for making informed decisions. However, extracting and effectively utilizing order flow data present challenges due to the large volume of data involved and the limitations of traditional factor mining techniques, which are primarily designed for coarser-level stock data. To address these challenges, we propose a novel framework that aims to effectively extract essential factors from order flow data for diverse downstream tasks across different granularities and scenarios. Our method consists of a Context Encoder and an Factor Extractor. The Context Encoder learns an embedding for the current order flow data segment's context by considering both the expected and actual market state. In addition, the Factor Extractor uses unsupervised learning methods to select such important signals that are most distinct from the majority within the given context. The extracted factors are then utilized for downstream tasks. In empirical studies, our proposed framework efficiently handles an entire year of stock order flow data across diverse scenarios, offering a broader range of applications compared to existing tick-level approaches that are limited to only a few days of stock data. We demonstrate that our method extracts superior factors from order flow data, enabling significant improvement for stock trend prediction and order execution tasks at the second and minute level.
Learning Multi-Agent Intention-Aware Communication for Optimal Multi-Order Execution in Finance
Jul 06, 2023



Order execution is a fundamental task in quantitative finance, aiming at finishing acquisition or liquidation for a number of trading orders of the specific assets. Recent advance in model-free reinforcement learning (RL) provides a data-driven solution to the order execution problem. However, the existing works always optimize execution for an individual order, overlooking the practice that multiple orders are specified to execute simultaneously, resulting in suboptimality and bias. In this paper, we first present a multi-agent RL (MARL) method for multi-order execution considering practical constraints. Specifically, we treat every agent as an individual operator to trade one specific order, while keeping communicating with each other and collaborating for maximizing the overall profits. Nevertheless, the existing MARL algorithms often incorporate communication among agents by exchanging only the information of their partial observations, which is inefficient in complicated financial market. To improve collaboration, we then propose a learnable multi-round communication protocol, for the agents communicating the intended actions with each other and refining accordingly. It is optimized through a novel action value attribution method which is provably consistent with the original learning objective yet more efficient. The experiments on the data from two real-world markets have illustrated superior performance with significantly better collaboration effectiveness achieved by our method.
Scalable and Safe Remediation of Defective Actions in Self-Learning Conversational Systems
May 17, 2023



Off-Policy reinforcement learning has been a driving force for the state-of-the-art conversational AIs leading to more natural humanagent interactions and improving the user satisfaction for goal-oriented agents. However, in large-scale commercial settings, it is often challenging to balance between policy improvements and experience continuity on the broad spectrum of applications handled by such system. In the literature, off-policy evaluation and guard-railing on aggregate statistics has been commonly used to address this problem. In this paper, we propose a method for curating and leveraging high-precision samples sourced from historical regression incident reports to validate, safe-guard, and improve policies prior to the online deployment. We conducted extensive experiments using data from a real-world conversational system and actual regression incidents. The proposed method is currently deployed in our production system to protect customers against broken experiences and enable long-term policy improvements.
Learning Differential Operators for Interpretable Time Series Modeling
Sep 03, 2022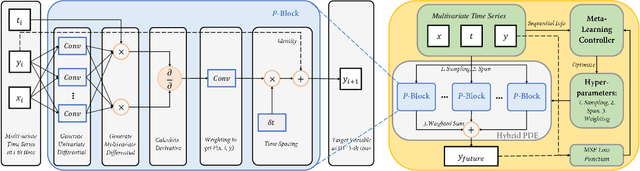


Modeling sequential patterns from data is at the core of various time series forecasting tasks. Deep learning models have greatly outperformed many traditional models, but these black-box models generally lack explainability in prediction and decision making. To reveal the underlying trend with understandable mathematical expressions, scientists and economists tend to use partial differential equations (PDEs) to explain the highly nonlinear dynamics of sequential patterns. However, it usually requires domain expert knowledge and a series of simplified assumptions, which is not always practical and can deviate from the ever-changing world. Is it possible to learn the differential relations from data dynamically to explain the time-evolving dynamics? In this work, we propose an learning framework that can automatically obtain interpretable PDE models from sequential data. Particularly, this framework is comprised of learnable differential blocks, named $P$-blocks, which is proved to be able to approximate any time-evolving complex continuous functions in theory. Moreover, to capture the dynamics shift, this framework introduces a meta-learning controller to dynamically optimize the hyper-parameters of a hybrid PDE model. Extensive experiments on times series forecasting of financial, engineering, and health data show that our model can provide valuable interpretability and achieve comparable performance to state-of-the-art models. From empirical studies, we find that learning a few differential operators may capture the major trend of sequential dynamics without massive computational complexity.
Towards Applicable Reinforcement Learning: Improving the Generalization and Sample Efficiency with Policy Ensemble
May 19, 2022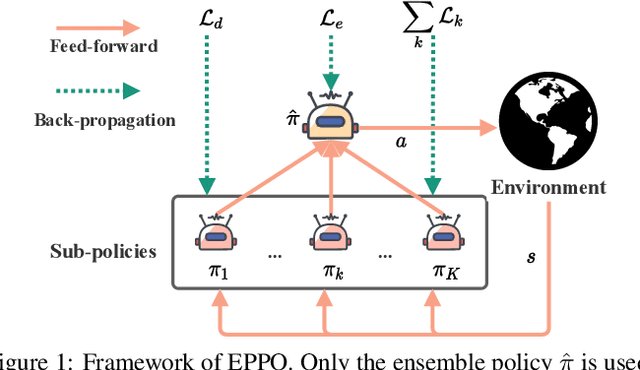
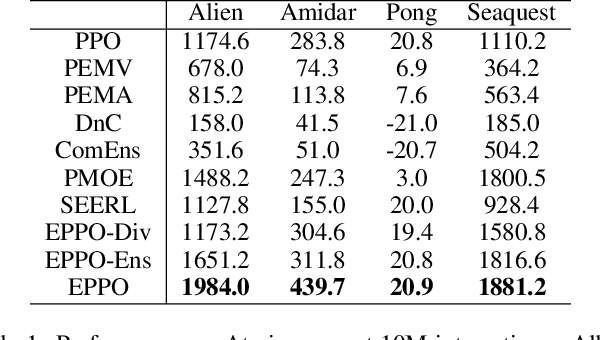
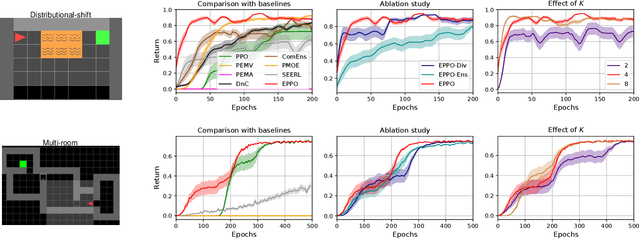
It is challenging for reinforcement learning (RL) algorithms to succeed in real-world applications like financial trading and logistic system due to the noisy observation and environment shifting between training and evaluation. Thus, it requires both high sample efficiency and generalization for resolving real-world tasks. However, directly applying typical RL algorithms can lead to poor performance in such scenarios. Considering the great performance of ensemble methods on both accuracy and generalization in supervised learning (SL), we design a robust and applicable method named Ensemble Proximal Policy Optimization (EPPO), which learns ensemble policies in an end-to-end manner. Notably, EPPO combines each policy and the policy ensemble organically and optimizes both simultaneously. In addition, EPPO adopts a diversity enhancement regularization over the policy space which helps to generalize to unseen states and promotes exploration. We theoretically prove EPPO increases exploration efficacy, and through comprehensive experimental evaluations on various tasks, we demonstrate that EPPO achieves higher efficiency and is robust for real-world applications compared with vanilla policy optimization algorithms and other ensemble methods. Code and supplemental materials are available at https://seqml.github.io/eppo.
DDG-DA: Data Distribution Generation for Predictable Concept Drift Adaptation
Jan 11, 2022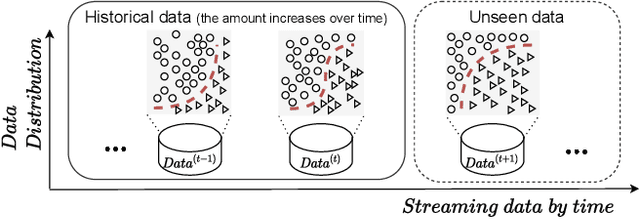
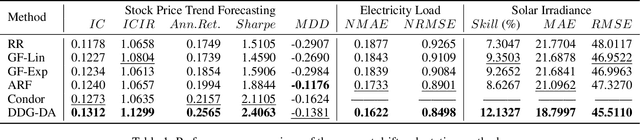
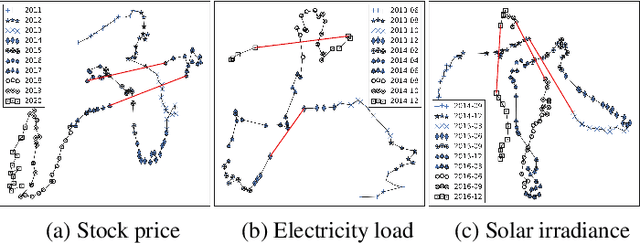
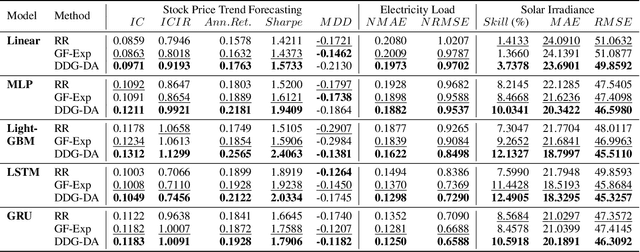
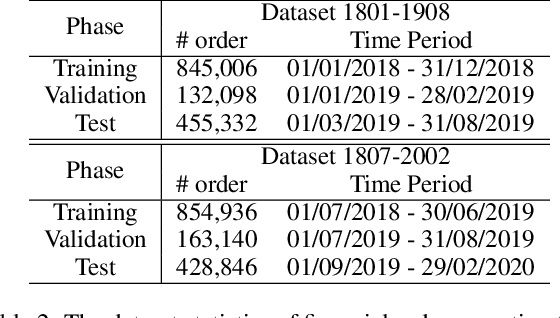
In many real-world scenarios, we often deal with streaming data that is sequentially collected over time. Due to the non-stationary nature of the environment, the streaming data distribution may change in unpredictable ways, which is known as concept drift. To handle concept drift, previous methods first detect when/where the concept drift happens and then adapt models to fit the distribution of the latest data. However, there are still many cases that some underlying factors of environment evolution are predictable, making it possible to model the future concept drift trend of the streaming data, while such cases are not fully explored in previous work. In this paper, we propose a novel method DDG-DA, that can effectively forecast the evolution of data distribution and improve the performance of models. Specifically, we first train a predictor to estimate the future data distribution, then leverage it to generate training samples, and finally train models on the generated data. We conduct experiments on three real-world tasks (forecasting on stock price trend, electricity load and solar irradiance) and obtain significant improvement on multiple widely-used models.
SHGNN: Structure-Aware Heterogeneous Graph Neural Network
Dec 14, 2021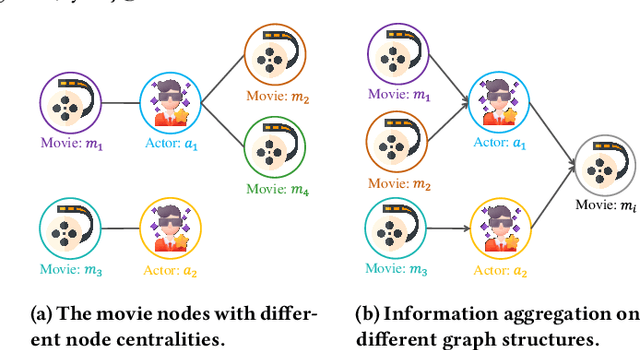
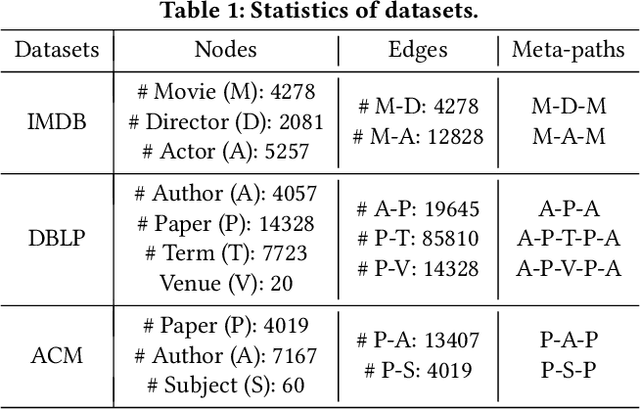
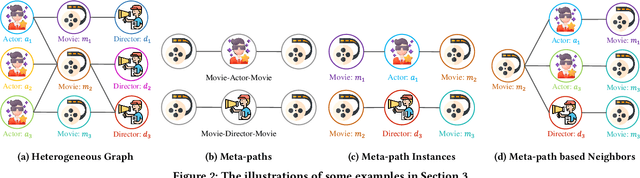
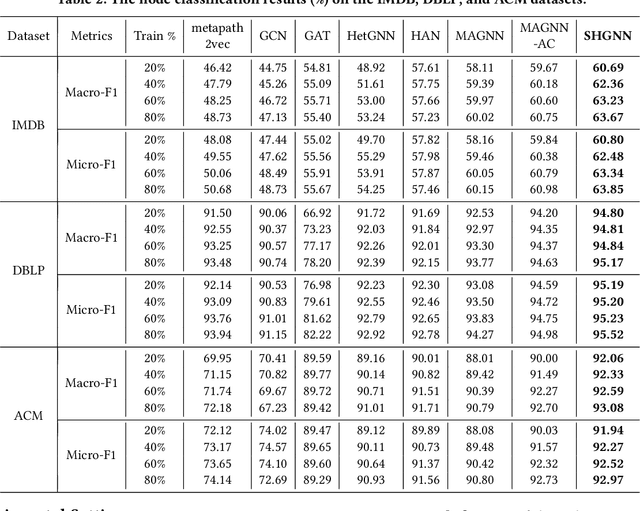
Many real-world graphs (networks) are heterogeneous with different types of nodes and edges. Heterogeneous graph embedding, aiming at learning the low-dimensional node representations of a heterogeneous graph, is vital for various downstream applications. Many meta-path based embedding methods have been proposed to learn the semantic information of heterogeneous graphs in recent years. However, most of the existing techniques overlook the graph structure information when learning the heterogeneous graph embeddings. This paper proposes a novel Structure-Aware Heterogeneous Graph Neural Network (SHGNN) to address the above limitations. In detail, we first utilize a feature propagation module to capture the local structure information of intermediate nodes in the meta-path. Next, we use a tree-attention aggregator to incorporate the graph structure information into the aggregation module on the meta-path. Finally, we leverage a meta-path aggregator to fuse the information aggregated from different meta-paths. We conducted experiments on node classification and clustering tasks and achieved state-of-the-art results on the benchmark datasets, which shows the effectiveness of our proposed method.
KGE-CL: Contrastive Learning of Knowledge Graph Embeddings
Dec 09, 2021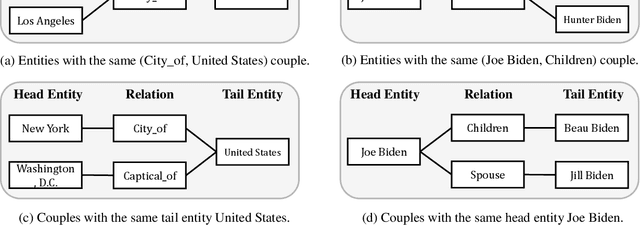

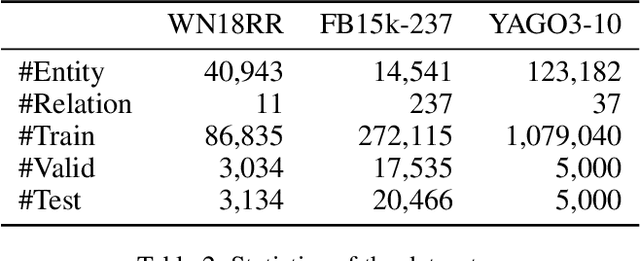
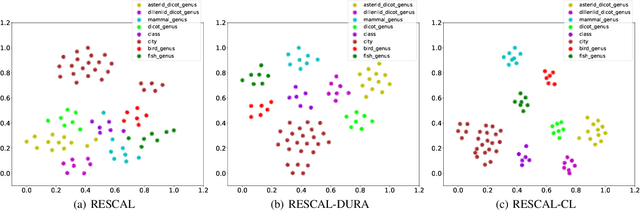
Learning the embeddings of knowledge graphs is vital in artificial intelligence, and can benefit various downstream applications, such as recommendation and question answering. In recent years, many research efforts have been proposed for knowledge graph embedding. However, most previous knowledge graph embedding methods ignore the semantic similarity between the related entities and entity-relation couples in different triples since they separately optimize each triple with the scoring function. To address this problem, we propose a simple yet efficient contrastive learning framework for knowledge graph embeddings, which can shorten the semantic distance of the related entities and entity-relation couples in different triples and thus improve the expressiveness of knowledge graph embeddings. We evaluate our proposed method on three standard knowledge graph benchmarks. It is noteworthy that our method can yield some new state-of-the-art results, achieving 51.2% MRR, 46.8% Hits@1 on the WN18RR dataset, and 59.1% MRR, 51.8% Hits@1 on the YAGO3-10 dataset.