 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Win-win Deal: Towards Sparse and Robust Pre-trained Language Models
Oct 11, 2022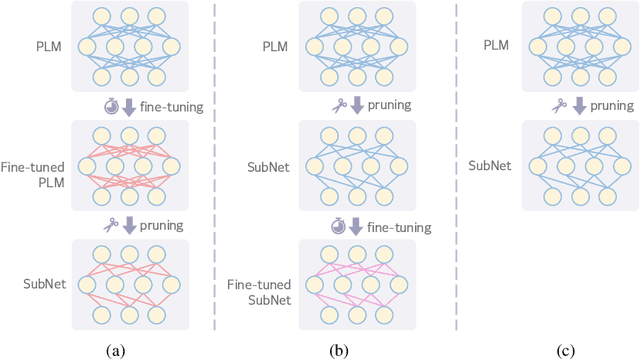

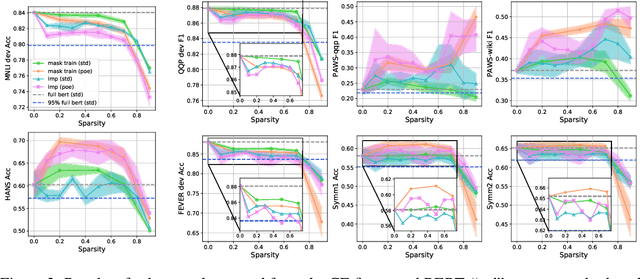
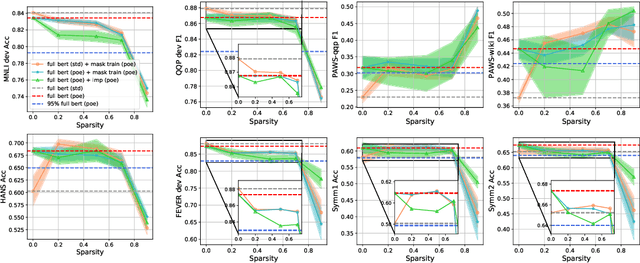
Despite the remarkable success of pre-trained language models (PLMs), they still face two challenges: First, large-scale PLMs are inefficient in terms of memory footprint and computation. Second, on the downstream tasks, PLMs tend to rely on the dataset bias and struggle to generalize to out-of-distribution (OOD) data. In response to the efficiency problem, recent studies show that dense PLMs can be replaced with sparse subnetworks without hurting the performance. Such subnetworks can be found in three scenarios: 1) the fine-tuned PLMs, 2) the raw PLMs and then fine-tuned in isolation, and even inside 3) PLMs without any parameter fine-tuning. However, these results are only obtained in the in-distribution (ID) setting. In this paper, we extend the study on PLMs subnetworks to the OOD setting, investigating whether sparsity and robustness to dataset bias can be achieved simultaneously. To this end, we conduct extensive experiments with the pre-trained BERT model on three natural language understanding (NLU) tasks. Our results demonstrate that \textbf{sparse and robust subnetworks (SRNets) can consistently be found in BERT}, across the aforementioned three scenarios, using different training and compression methods. Furthermore, we explore the upper bound of SRNets using the OOD information and show that \textbf{there exist sparse and almost unbiased BERT subnetworks}. Finally, we present 1) an analytical study that provides insights on how to promote the efficiency of SRNets searching process and 2) a solution to improve subnetworks' performance at high sparsity. The code is available at https://github.com/llyx97/sparse-and-robust-PLM.
Towards Robust Visual Question Answering: Making the Most of Biased Samples via Contrastive Learning
Oct 10, 2022
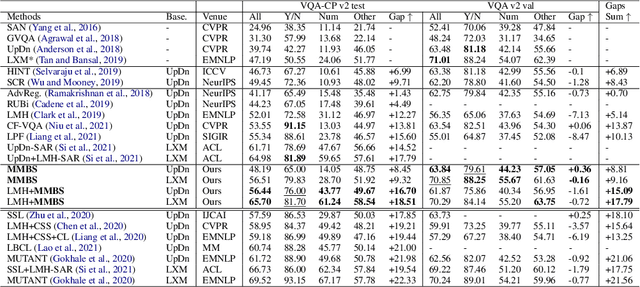
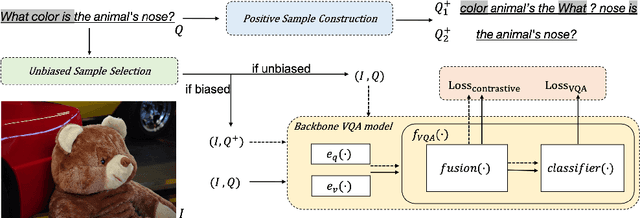
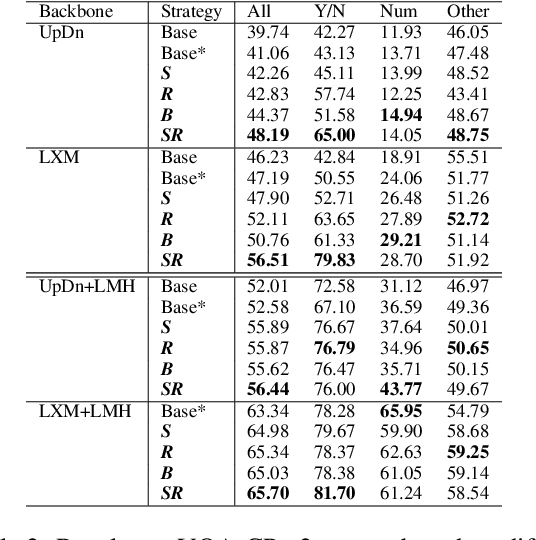
Models for Visual Question Answering (VQA) often rely on the spurious correlations, i.e., the language priors, that appear in the biased samples of training set, which make them brittle against the out-of-distribution (OOD) test data. Recent methods have achieved promising progress in overcoming this problem by reducing the impact of biased samples on model training. However, these models reveal a trade-off that the improvements on OOD data severely sacrifice the performance on the in-distribution (ID) data (which is dominated by the biased samples). Therefore, we propose a novel contrastive learning approach, MMBS, for building robust VQA models by Making the Most of Biased Samples. Specifically, we construct positive samples for contrastive learning by eliminating the information related to spurious correlation from the original training samples and explore several strategies to use the constructed positive samples for training. Instead of undermining the importance of biased samples in model training, our approach precisely exploits the biased samples for unbiased information that contributes to reasoning. The proposed method is compatible with various VQA backbones. We validate our contributions by achieving competitive performance on the OOD dataset VQA-CP v2 while preserving robust performance on the ID dataset VQA v2.
Language Prior Is Not the Only Shortcut: A Benchmark for Shortcut Learning in VQA
Oct 10, 2022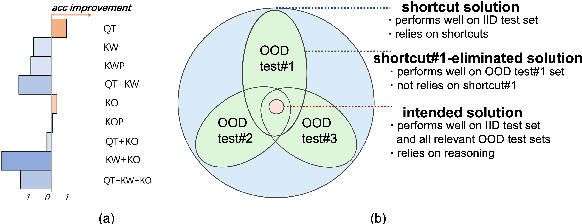
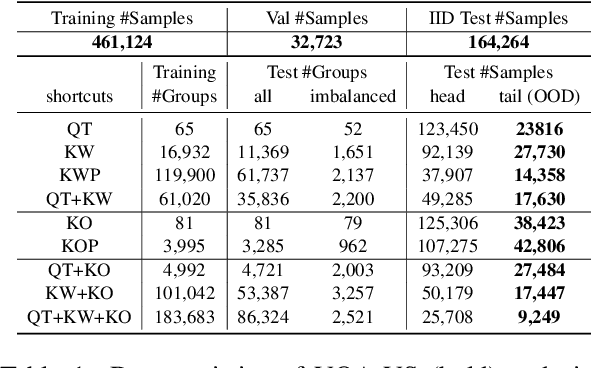
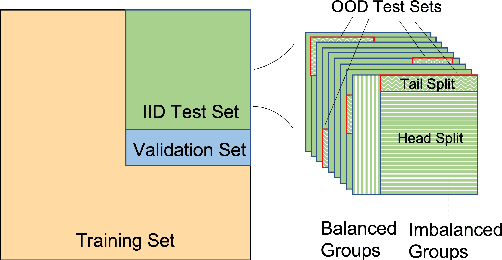
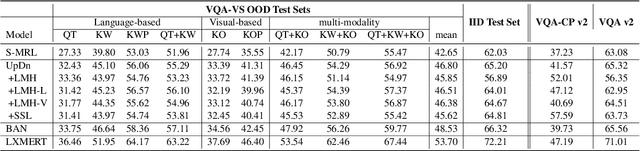
Visual Question Answering (VQA) models are prone to learn the shortcut solution formed by dataset biases rather than the intended solution. To evaluate the VQA models' reasoning ability beyond shortcut learning, the VQA-CP v2 dataset introduces a distribution shift between the training and test set given a question type. In this way, the model cannot use the training set shortcut (from question type to answer) to perform well on the test set. However, VQA-CP v2 only considers one type of shortcut and thus still cannot guarantee that the model relies on the intended solution rather than a solution specific to this shortcut. To overcome this limitation, we propose a new dataset that considers varying types of shortcuts by constructing different distribution shifts in multiple OOD test sets. In addition, we overcome the three troubling practices in the use of VQA-CP v2, e.g., selecting models using OOD test sets, and further standardize OOD evaluation procedure. Our benchmark provides a more rigorous and comprehensive testbed for shortcut learning in VQA. We benchmark recent methods and find that methods specifically designed for particular shortcuts fail to simultaneously generalize to our varying OOD test sets. We also systematically study the varying shortcuts and provide several valuable findings, which may promote the exploration of shortcut learning in VQA.
Towards Practical Differential Privacy in Data Analysis: Understanding the Effect of Epsilon on Utility in Private ERM
Jun 06, 2022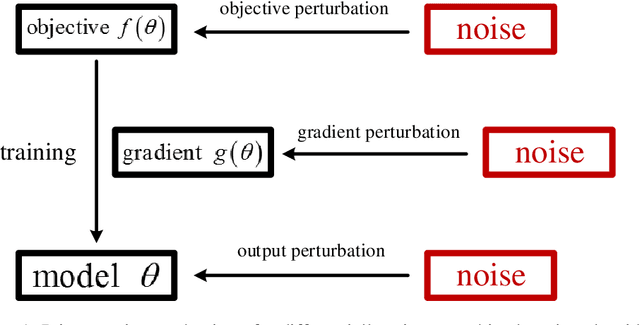

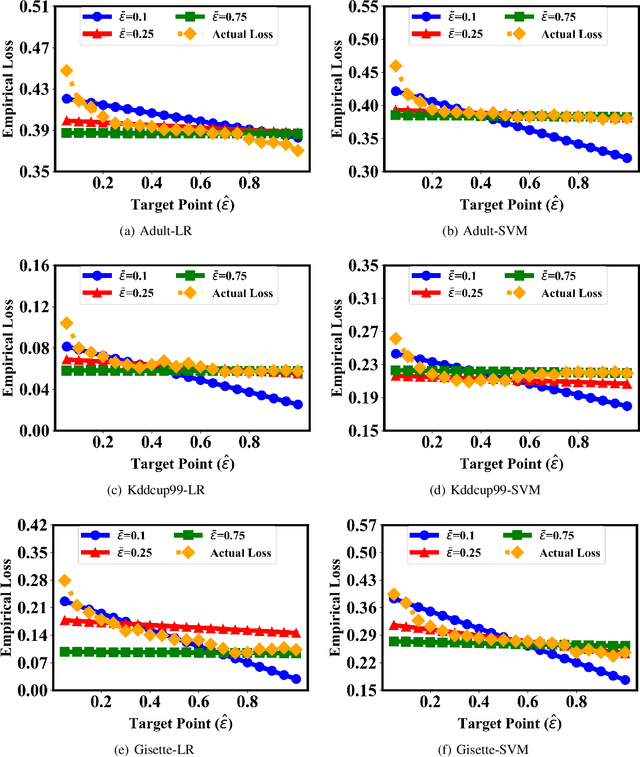

In this paper, we focus our attention on private Empirical Risk Minimization (ERM), which is one of the most commonly used data analysis method. We take the first step towards solving the above problem by theoretically exploring the effect of epsilon (the parameter of differential privacy that determines the strength of privacy guarantee) on utility of the learning model. We trace the change of utility with modification of epsilon and reveal an established relationship between epsilon and utility. We then formalize this relationship and propose a practical approach for estimating the utility under an arbitrary value of epsilon. Both theoretical analysis and experimental results demonstrate high estimation accuracy and broad applicability of our approach in practical applications. As providing algorithms with strong utility guarantees that also give privacy when possible becomes more and more accepted, our approach would have high practical value and may be likely to be adopted by companies and organizations that would like to preserve privacy but are unwilling to compromise on utility.
UNITS: Unsupervised Intermediate Training Stage for Scene Text Detection
May 10, 2022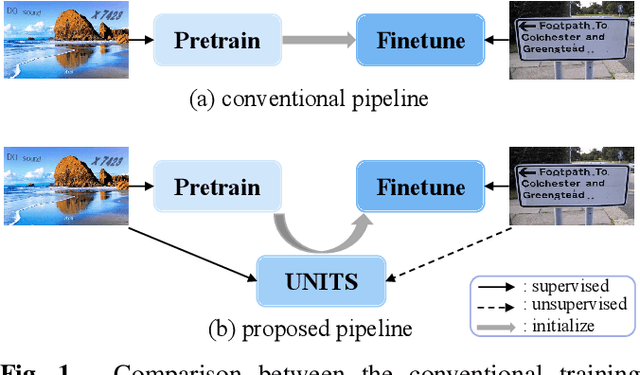
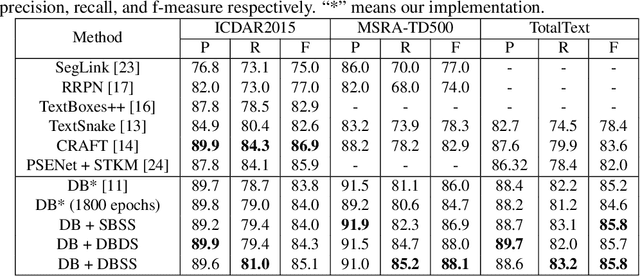
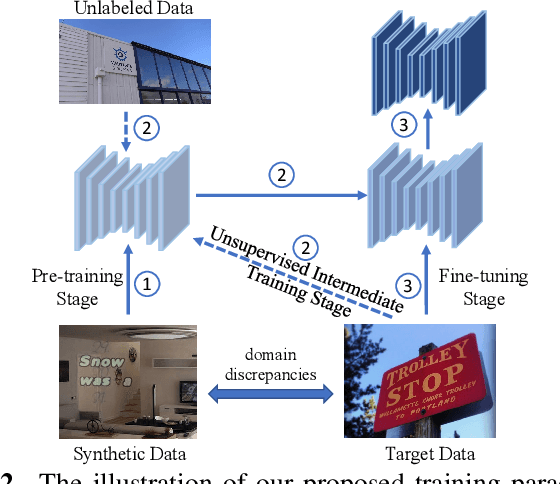
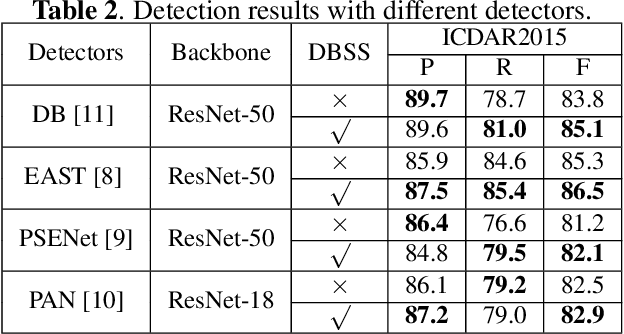
Recent scene text detection methods are almost based on deep learning and data-driven. Synthetic data is commonly adopted for pre-training due to expensive annotation cost. However, there are obvious domain discrepancies between synthetic data and real-world data. It may lead to sub-optimal performance to directly adopt the model initialized by synthetic data in the fine-tuning stage. In this paper, we propose a new training paradigm for scene text detection, which introduces an \textbf{UN}supervised \textbf{I}ntermediate \textbf{T}raining \textbf{S}tage (UNITS) that builds a buffer path to real-world data and can alleviate the gap between the pre-training stage and fine-tuning stage. Three training strategies are further explored to perceive information from real-world data in an unsupervised way. With UNITS, scene text detectors are improved without introducing any parameters and computations during inference. Extensive experimental results show consistent performance improvements on three public datasets.
Neutral Utterances are Also Causes: Enhancing Conversational Causal Emotion Entailment with Social Commonsense Knowledge
May 07, 2022
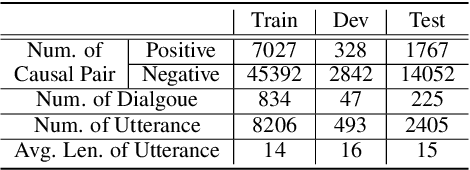
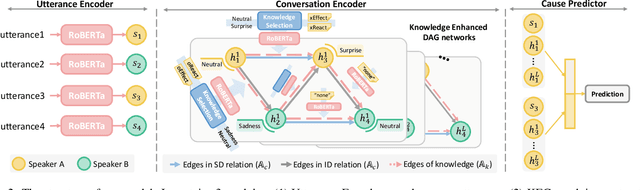
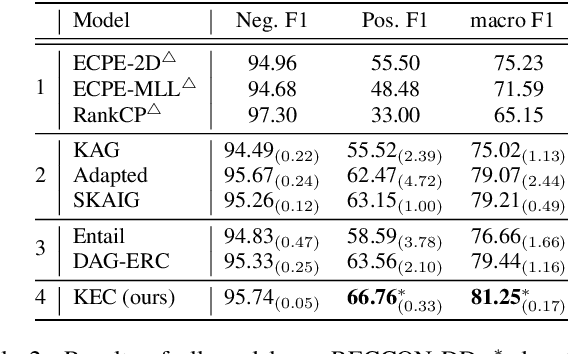
Conversational Causal Emotion Entailment aims to detect causal utterances for a non-neutral targeted utterance from a conversation. In this work, we build conversations as graphs to overcome implicit contextual modelling of the original entailment style. Following the previous work, we further introduce the emotion information into graphs. Emotion information can markedly promote the detection of causal utterances whose emotion is the same as the targeted utterance. However, it is still hard to detect causal utterances with different emotions, especially neutral ones. The reason is that models are limited in reasoning causal clues and passing them between utterances. To alleviate this problem, we introduce social commonsense knowledge (CSK) and propose a Knowledge Enhanced Conversation graph (KEC). KEC propagates the CSK between two utterances. As not all CSK is emotionally suitable for utterances, we therefore propose a sentiment-realized knowledge selecting strategy to filter CSK. To process KEC, we further construct the Knowledge Enhanced Directed Acyclic Graph networks. Experimental results show that our method outperforms baselines and infers more causes with different emotions from the targeted utterance.
Learning to Win Lottery Tickets in BERT Transfer via Task-agnostic Mask Training
Apr 24, 2022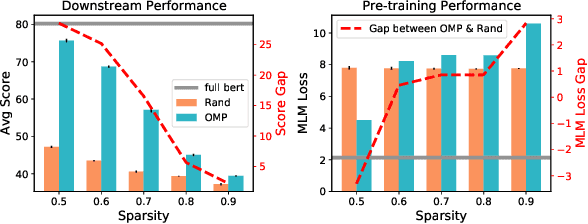
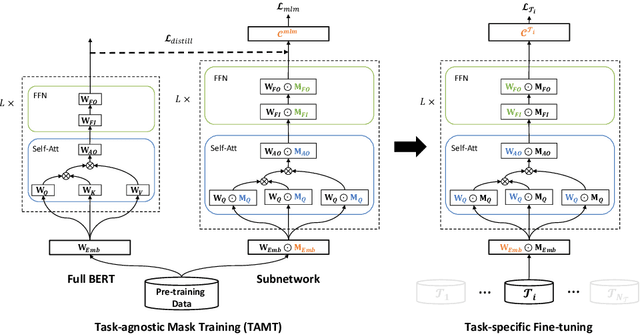

Recent studies on the lottery ticket hypothesis (LTH) show that pre-trained language models (PLMs) like BERT contain matching subnetworks that have similar transfer learning performance as the original PLM. These subnetworks are found using magnitude-based pruning. In this paper, we find that the BERT subnetworks have even more potential than these studies have shown. Firstly, we discover that the success of magnitude pruning can be attributed to the preserved pre-training performance, which correlates with the downstream transferability. Inspired by this, we propose to directly optimize the subnetwork structure towards the pre-training objectives, which can better preserve the pre-training performance. Specifically, we train binary masks over model weights on the pre-training tasks, with the aim of preserving the universal transferability of the subnetwork, which is agnostic to any specific downstream tasks. We then fine-tune the subnetworks on the GLUE benchmark and the SQuAD dataset. The results show that, compared with magnitude pruning, mask training can effectively find BERT subnetworks with improved overall performance on downstream tasks. Moreover, our method is also more efficient in searching subnetworks and more advantageous when fine-tuning within a certain range of data scarcity. Our code is available at https://github.com/llyx97/TAMT.
Sharper Utility Bounds for Differentially Private Models
Apr 22, 2022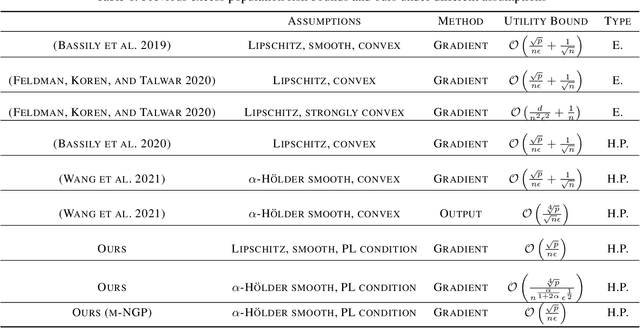
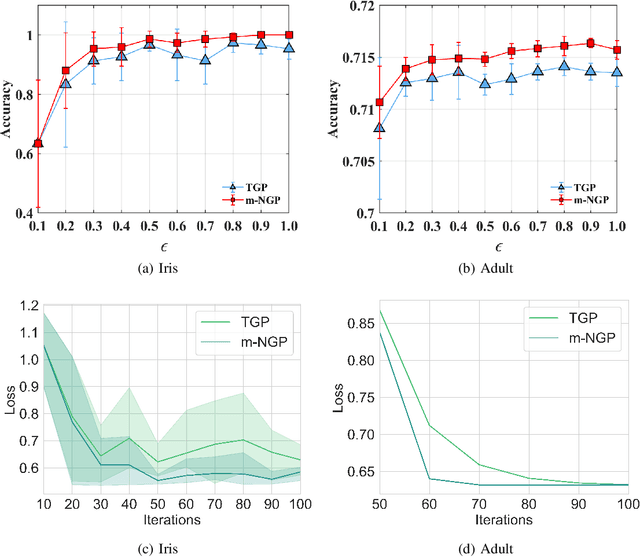
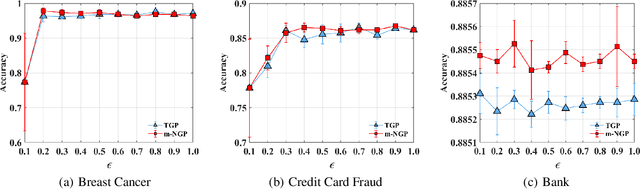
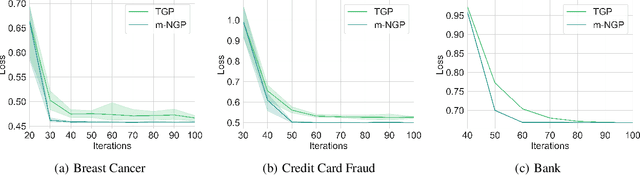
In this paper, by introducing Generalized Bernstein condition, we propose the first $\mathcal{O}\big(\frac{\sqrt{p}}{n\epsilon}\big)$ high probability excess population risk bound for differentially private algorithms under the assumptions $G$-Lipschitz, $L$-smooth, and Polyak-{\L}ojasiewicz condition, based on gradient perturbation method. If we replace the properties $G$-Lipschitz and $L$-smooth by $\alpha$-H{\"o}lder smoothness (which can be used in non-smooth setting), the high probability bound comes to $\mathcal{O}\big(n^{-\frac{\alpha}{1+2\alpha}}\big)$ w.r.t $n$, which cannot achieve $\mathcal{O}\left(1/n\right)$ when $\alpha\in(0,1]$. To solve this problem, we propose a variant of gradient perturbation method, \textbf{max$\{1,g\}$-Normalized Gradient Perturbation} (m-NGP). We further show that by normalization, the high probability excess population risk bound under assumptions $\alpha$-H{\"o}lder smooth and Polyak-{\L}ojasiewicz condition can achieve $\mathcal{O}\big(\frac{\sqrt{p}}{n\epsilon}\big)$, which is the first $\mathcal{O}\left(1/n\right)$ high probability excess population risk bound w.r.t $n$ for differentially private algorithms under non-smooth conditions. Moreover, we evaluate the performance of the new proposed algorithm m-NGP, the experimental results show that m-NGP improves the performance of the differentially private model over real datasets. It demonstrates that m-NGP improves the utility bound and the accuracy of the DP model on real datasets simultaneously.
Stability and Generalization of Differentially Private Minimax Problems
Apr 11, 2022
In the field of machine learning, many problems can be formulated as the minimax problem, including reinforcement learning, generative adversarial networks, to just name a few. So the minimax problem has attracted a huge amount of attentions from researchers in recent decades. However, there is relatively little work on studying the privacy of the general minimax paradigm. In this paper, we focus on the privacy of the general minimax setting, combining differential privacy together with minimax optimization paradigm. Besides, via algorithmic stability theory, we theoretically analyze the high probability generalization performance of the differentially private minimax algorithm under the strongly-convex-strongly-concave condition. To the best of our knowledge, this is the first time to analyze the generalization performance of general minimax paradigm, taking differential privacy into account.
Towards Escaping from Language Bias and OCR Error: Semantics-Centered Text Visual Question Answering
Mar 24, 2022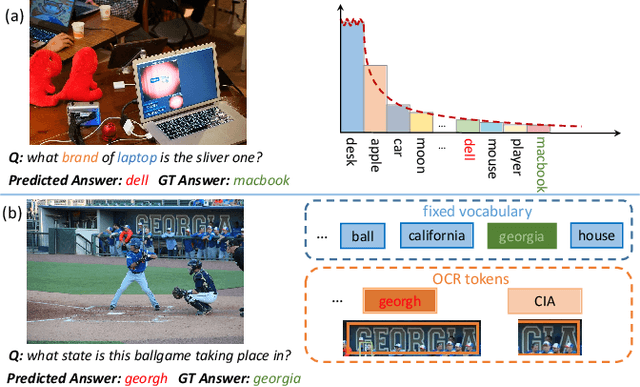

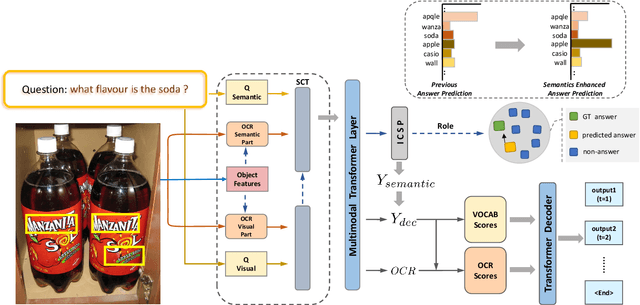

Texts in scene images convey critical information for scene understanding and reasoning. The abilities of reading and reasoning matter for the model in the text-based visual question answering (TextVQA) process. However, current TextVQA models do not center on the text and suffer from several limitations. The model is easily dominated by language biases and optical character recognition (OCR) errors due to the absence of semantic guidance in the answer prediction process. In this paper, we propose a novel Semantics-Centered Network (SC-Net) that consists of an instance-level contrastive semantic prediction module (ICSP) and a semantics-centered transformer module (SCT). Equipped with the two modules, the semantics-centered model can resist the language biases and the accumulated errors from OCR. Extensive experiments on TextVQA and ST-VQA datasets show the effectiveness of our model. SC-Net surpasses previous works with a noticeable margin and is more reasonable for the TextVQA task.