 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Jan 06, 2026In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
TGB 2.0: A Benchmark for Learning on Temporal Knowledge Graphs and Heterogeneous Graphs
Jun 14, 2024Multi-relational temporal graphs are powerful tools for modeling real-world data, capturing the evolving and interconnected nature of entities over time. Recently, many novel models are proposed for ML on such graphs intensifying the need for robust evaluation and standardized benchmark datasets. However, the availability of such resources remains scarce and evaluation faces added complexity due to reproducibility issues in experimental protocols. To address these challenges, we introduce Temporal Graph Benchmark 2.0 (TGB 2.0), a novel benchmarking framework tailored for evaluating methods for predicting future links on Temporal Knowledge Graphs and Temporal Heterogeneous Graphs with a focus on large-scale datasets, extending the Temporal Graph Benchmark. TGB 2.0 facilitates comprehensive evaluations by presenting eight novel datasets spanning five domains with up to 53 million edges. TGB 2.0 datasets are significantly larger than existing datasets in terms of number of nodes, edges, or timestamps. In addition, TGB 2.0 provides a reproducible and realistic evaluation pipeline for multi-relational temporal graphs. Through extensive experimentation, we observe that 1) leveraging edge-type information is crucial to obtain high performance, 2) simple heuristic baselines are often competitive with more complex methods, 3) most methods fail to run on our largest datasets, highlighting the need for research on more scalable methods.
Temporal Graph Benchmark for Machine Learning on Temporal Graphs
Jul 03, 2023



We present the Temporal Graph Benchmark (TGB), a collection of challenging and diverse benchmark datasets for realistic, reproducible, and robust evaluation of machine learning models on temporal graphs. TGB datasets are of large scale, spanning years in duration, incorporate both node and edge-level prediction tasks and cover a diverse set of domains including social, trade, transaction, and transportation networks. For both tasks, we design evaluation protocols based on realistic use-cases. We extensively benchmark each dataset and find that the performance of common models can vary drastically across datasets. In addition, on dynamic node property prediction tasks, we show that simple methods often achieve superior performance compared to existing temporal graph models. We believe that these findings open up opportunities for future research on temporal graphs. Finally, TGB provides an automated machine learning pipeline for reproducible and accessible temporal graph research, including data loading, experiment setup and performance evaluation. TGB will be maintained and updated on a regular basis and welcomes community feedback. TGB datasets, data loaders, example codes, evaluation setup, and leaderboards are publicly available at https://tgb.complexdatalab.com/ .
Fast and Attributed Change Detection on Dynamic Graphs with Density of States
May 15, 2023



How can we detect traffic disturbances from international flight transportation logs or changes to collaboration dynamics in academic networks? These problems can be formulated as detecting anomalous change points in a dynamic graph. Current solutions do not scale well to large real-world graphs, lack robustness to large amounts of node additions/deletions, and overlook changes in node attributes. To address these limitations, we propose a novel spectral method: Scalable Change Point Detection (SCPD). SCPD generates an embedding for each graph snapshot by efficiently approximating the distribution of the Laplacian spectrum at each step. SCPD can also capture shifts in node attributes by tracking correlations between attributes and eigenvectors. Through extensive experiments using synthetic and real-world data, we show that SCPD (a) achieves state-of-the art performance, (b) is significantly faster than the state-of-the-art methods and can easily process millions of edges in a few CPU minutes, (c) can effectively tackle a large quantity of node attributes, additions or deletions and (d) discovers interesting events in large real-world graphs. The code is publicly available at https://github.com/shenyangHuang/SCPD.git
The Surprising Performance of Simple Baselines for Misinformation Detection
Apr 14, 2021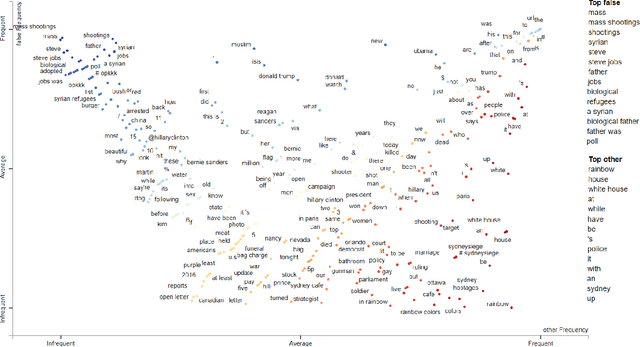
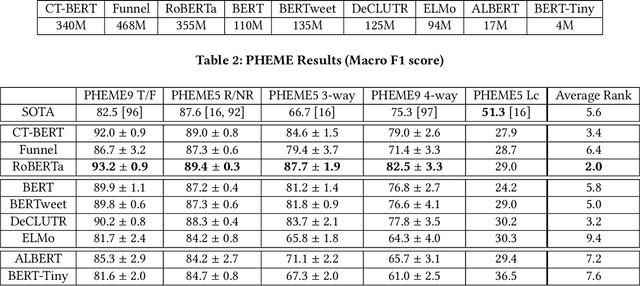
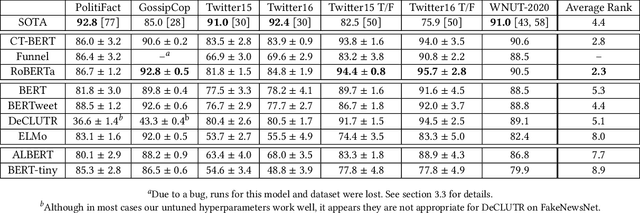
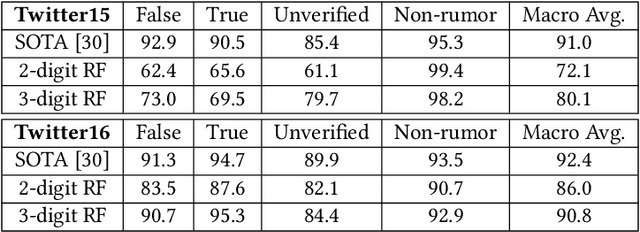
As social media becomes increasingly prominent in our day to day lives, it is increasingly important to detect informative content and prevent the spread of disinformation and unverified rumours. While many sophisticated and successful models have been proposed in the literature, they are often compared with older NLP baselines such as SVMs, CNNs, and LSTMs. In this paper, we examine the performance of a broad set of modern transformer-based language models and show that with basic fine-tuning, these models are competitive with and can even significantly outperform recently proposed state-of-the-art methods. We present our framework as a baseline for creating and evaluating new methods for misinformation detection. We further study a comprehensive set of benchmark datasets, and discuss potential data leakage and the need for careful design of the experiments and understanding of datasets to account for confounding variables. As an extreme case example, we show that classifying only based on the first three digits of tweet ids, which contain information on the date, gives state-of-the-art performance on a commonly used benchmark dataset for fake news detection --Twitter16. We provide a simple tool to detect this problem and suggest steps to mitigate it in future datasets.
Linking Social Media Posts to News with Siamese Transformers
Jan 10, 2020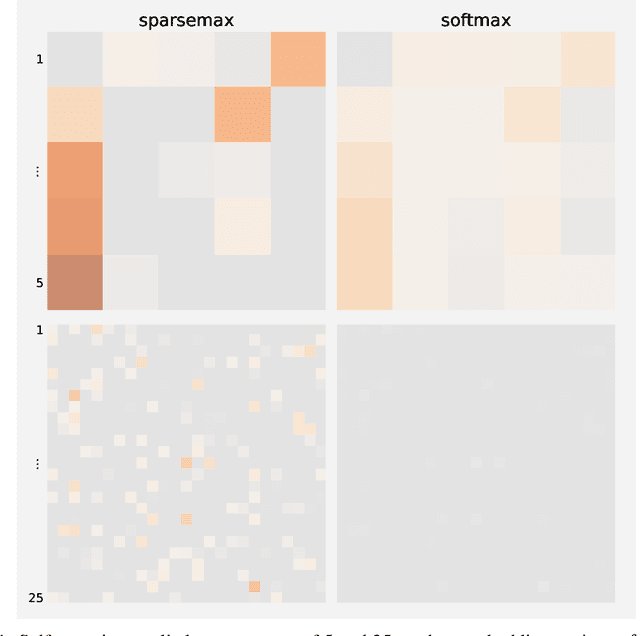
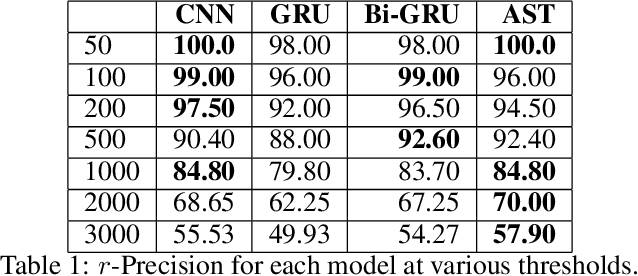
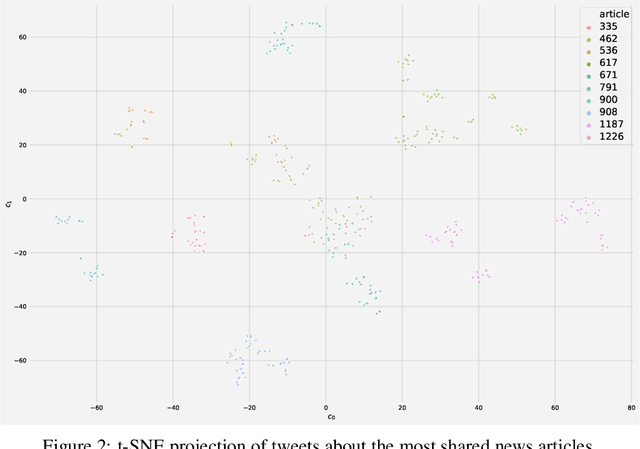
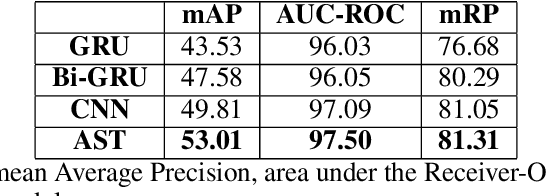
Many computational social science projects examine online discourse surrounding a specific trending topic. These works often involve the acquisition of large-scale corpora relevant to the event in question to analyze aspects of the response to the event. Keyword searches present a precision-recall trade-off and crowd-sourced annotations, while effective, are costly. This work aims to enable automatic and accurate ad-hoc retrieval of comments discussing a trending topic from a large corpus, using only a handful of seed news articles.
Trouble with the Curve: Predicting Future MLB Players Using Scouting Reports
Oct 21, 2019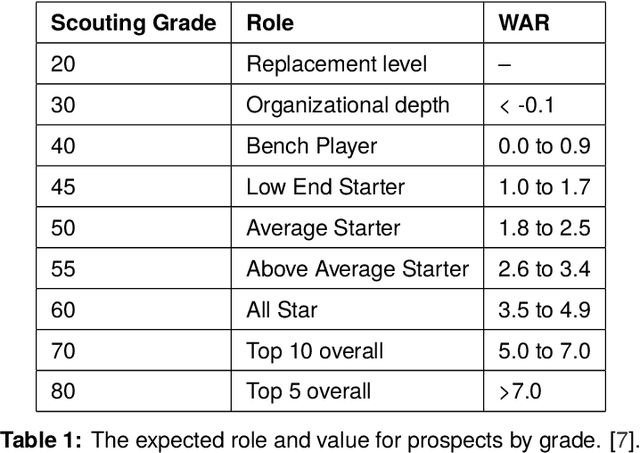
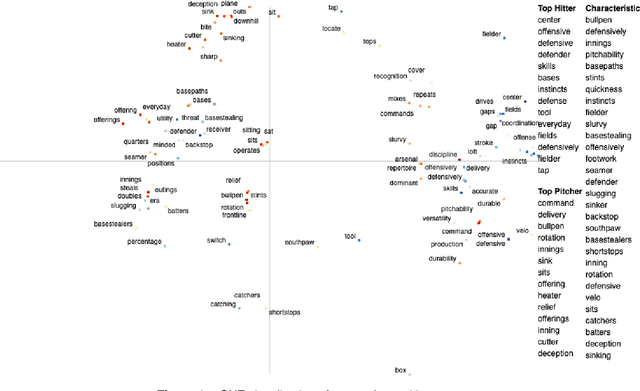
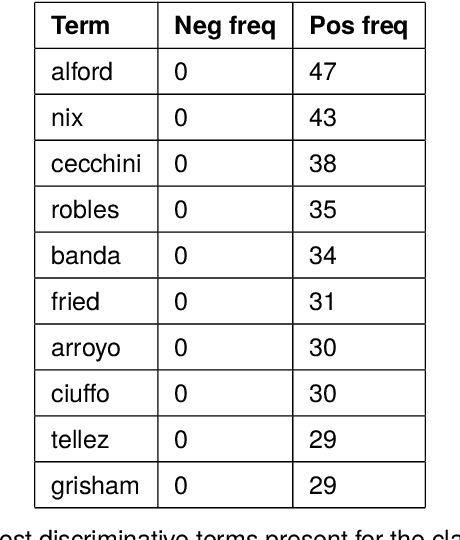

In baseball, a scouting report profiles a player's characteristics and traits, usually intended for use in player valuation. This work presents a first-of-its-kind dataset of almost 10,000 scouting reports for minor league, international, and draft prospects. Compiled from articles posted to MLB.com and Fangraphs.com, each report consists of a written description of the player, numerical grades for several skills, and unique IDs to reference their profiles on popular resources like MLB.com, FanGraphs, and Baseball-Reference. With this dataset, we employ several deep neural networks to predict if minor league players will make the MLB given their scouting report. We open-source this data to share with the community, and present a web application demonstrating language variations in the reports of successful and unsuccessful prospects.