 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUTG: Towards a Unified View of Snapshot and Event Based Models for Temporal Graphs
Jul 17, 2024



Temporal graphs have gained increasing importance due to their ability to model dynamically evolving relationships. These graphs can be represented through either a stream of edge events or a sequence of graph snapshots. Until now, the development of machine learning methods for both types has occurred largely in isolation, resulting in limited experimental comparison and theoretical crosspollination between the two. In this paper, we introduce Unified Temporal Graph (UTG), a framework that unifies snapshot-based and event-based machine learning models under a single umbrella, enabling models developed for one representation to be applied effectively to datasets of the other. We also propose a novel UTG training procedure to boost the performance of snapshot-based models in the streaming setting. We comprehensively evaluate both snapshot and event-based models across both types of temporal graphs on the temporal link prediction task. Our main findings are threefold: first, when combined with UTG training, snapshotbased models can perform competitively with event-based models such as TGN and GraphMixer even on event datasets. Second, snapshot-based models are at least an order of magnitude faster than most event-based models during inference. Third, while event-based methods such as NAT and DyGFormer outperforms snapshotbased methods on both types of temporal graphs, this is because they leverage joint neighborhood structural features thus emphasizing the potential to incorporate these features into snapshot-based models as well. These findings highlight the importance of comparing model architectures independent of the data format and suggest the potential of combining the efficiency of snapshot-based models with the performance of event-based models in the future.
TGB 2.0: A Benchmark for Learning on Temporal Knowledge Graphs and Heterogeneous Graphs
Jun 14, 2024Multi-relational temporal graphs are powerful tools for modeling real-world data, capturing the evolving and interconnected nature of entities over time. Recently, many novel models are proposed for ML on such graphs intensifying the need for robust evaluation and standardized benchmark datasets. However, the availability of such resources remains scarce and evaluation faces added complexity due to reproducibility issues in experimental protocols. To address these challenges, we introduce Temporal Graph Benchmark 2.0 (TGB 2.0), a novel benchmarking framework tailored for evaluating methods for predicting future links on Temporal Knowledge Graphs and Temporal Heterogeneous Graphs with a focus on large-scale datasets, extending the Temporal Graph Benchmark. TGB 2.0 facilitates comprehensive evaluations by presenting eight novel datasets spanning five domains with up to 53 million edges. TGB 2.0 datasets are significantly larger than existing datasets in terms of number of nodes, edges, or timestamps. In addition, TGB 2.0 provides a reproducible and realistic evaluation pipeline for multi-relational temporal graphs. Through extensive experimentation, we observe that 1) leveraging edge-type information is crucial to obtain high performance, 2) simple heuristic baselines are often competitive with more complex methods, 3) most methods fail to run on our largest datasets, highlighting the need for research on more scalable methods.
Towards Neural Scaling Laws for Foundation Models on Temporal Graphs
Jun 14, 2024



The field of temporal graph learning aims to learn from evolving network data to forecast future interactions. Given a collection of observed temporal graphs, is it possible to predict the evolution of an unseen network from the same domain? To answer this question, we first present the Temporal Graph Scaling (TGS) dataset, a large collection of temporal graphs consisting of eighty-four ERC20 token transaction networks collected from 2017 to 2023. Next, we evaluate the transferability of Temporal Graph Neural Networks (TGNNs) for the temporal graph property prediction task by pre-training on a collection of up to sixty-four token transaction networks and then evaluating the downstream performance on twenty unseen token networks. We find that the neural scaling law observed in NLP and Computer Vision also applies in temporal graph learning, where pre-training on greater number of networks leads to improved downstream performance. To the best of our knowledge, this is the first empirical demonstration of the transferability of temporal graphs learning. On downstream token networks, the largest pre-trained model outperforms single model TGNNs on thirteen unseen test networks. Therefore, we believe that this is a promising first step towards building foundation models for temporal graphs.
Temporal Graph Rewiring with Expander Graphs
Jun 04, 2024Evolving relations in real-world networks are often modelled by temporal graphs. Graph rewiring techniques have been utilised on Graph Neural Networks (GNNs) to improve expressiveness and increase model performance. In this work, we propose Temporal Graph Rewiring (TGR), the first approach for graph rewiring on temporal graphs. TGR enables communication between temporally distant nodes in a continuous time dynamic graph by utilising expander graph propagation to construct a message passing highway for message passing between distant nodes. Expander graphs are suitable candidates for rewiring as they help overcome the oversquashing problem often observed in GNNs. On the public tgbl-wiki benchmark, we show that TGR improves the performance of a widely used TGN model by a significant margin. Our code repository is accessible at https://anonymous.4open.science/r/TGR-254C.
On the Scalability of GNNs for Molecular Graphs
Apr 17, 2024



Scaling deep learning models has been at the heart of recent revolutions in language modelling and image generation. Practitioners have observed a strong relationship between model size, dataset size, and performance. However, structure-based architectures such as Graph Neural Networks (GNNs) are yet to show the benefits of scale mainly due to the lower efficiency of sparse operations, large data requirements, and lack of clarity about the effectiveness of various architectures. We address this drawback of GNNs by studying their scaling behavior. Specifically, we analyze message-passing networks, graph Transformers, and hybrid architectures on the largest public collection of 2D molecular graphs. For the first time, we observe that GNNs benefit tremendously from the increasing scale of depth, width, number of molecules, number of labels, and the diversity in the pretraining datasets, resulting in a 30.25% improvement when scaling to 1 billion parameters and 28.98% improvement when increasing size of dataset to eightfold. We further demonstrate strong finetuning scaling behavior on 38 tasks, outclassing previous large models. We hope that our work paves the way for an era where foundational GNNs drive pharmaceutical drug discovery.
Temporal Graph Analysis with TGX
Feb 06, 2024



Real-world networks, with their evolving relations, are best captured as temporal graphs. However, existing software libraries are largely designed for static graphs where the dynamic nature of temporal graphs is ignored. Bridging this gap, we introduce TGX, a Python package specially designed for analysis of temporal networks that encompasses an automated pipeline for data loading, data processing, and analysis of evolving graphs. TGX provides access to eleven built-in datasets and eight external Temporal Graph Benchmark (TGB) datasets as well as any novel datasets in the .csv format. Beyond data loading, TGX facilitates data processing functionalities such as discretization of temporal graphs and node subsampling to accelerate working with larger datasets. For comprehensive investigation, TGX offers network analysis by providing a diverse set of measures, including average node degree and the evolving number of nodes and edges per timestamp. Additionally, the package consolidates meaningful visualization plots indicating the evolution of temporal patterns, such as Temporal Edge Appearance (TEA) and Temporal Edge Trafficc (TET) plots. The TGX package is a robust tool for examining the features of temporal graphs and can be used in various areas like studying social networks, citation networks, and tracking user interactions. We plan to continuously support and update TGX based on community feedback. TGX is publicly available on: https://github.com/ComplexData-MILA/TGX.
Towards Temporal Edge Regression: A Case Study on Agriculture Trade Between Nations
Aug 15, 2023



Recently, Graph Neural Networks (GNNs) have shown promising performance in tasks on dynamic graphs such as node classification, link prediction and graph regression. However, few work has studied the temporal edge regression task which has important real-world applications. In this paper, we explore the application of GNNs to edge regression tasks in both static and dynamic settings, focusing on predicting food and agriculture trade values between nations. We introduce three simple yet strong baselines and comprehensively evaluate one static and three dynamic GNN models using the UN Trade dataset. Our experimental results reveal that the baselines exhibit remarkably strong performance across various settings, highlighting the inadequacy of existing GNNs. We also find that TGN outperforms other GNN models, suggesting TGN is a more appropriate choice for edge regression tasks. Moreover, we note that the proportion of negative edges in the training samples significantly affects the test performance. The companion source code can be found at: https://github.com/scylj1/GNN_Edge_Regression.
Temporal Graph Benchmark for Machine Learning on Temporal Graphs
Jul 03, 2023



We present the Temporal Graph Benchmark (TGB), a collection of challenging and diverse benchmark datasets for realistic, reproducible, and robust evaluation of machine learning models on temporal graphs. TGB datasets are of large scale, spanning years in duration, incorporate both node and edge-level prediction tasks and cover a diverse set of domains including social, trade, transaction, and transportation networks. For both tasks, we design evaluation protocols based on realistic use-cases. We extensively benchmark each dataset and find that the performance of common models can vary drastically across datasets. In addition, on dynamic node property prediction tasks, we show that simple methods often achieve superior performance compared to existing temporal graph models. We believe that these findings open up opportunities for future research on temporal graphs. Finally, TGB provides an automated machine learning pipeline for reproducible and accessible temporal graph research, including data loading, experiment setup and performance evaluation. TGB will be maintained and updated on a regular basis and welcomes community feedback. TGB datasets, data loaders, example codes, evaluation setup, and leaderboards are publicly available at https://tgb.complexdatalab.com/ .
Towards Improved Illicit Node Detection with Positive-Unlabelled Learning
Mar 15, 2023



Detecting illicit nodes on blockchain networks is a valuable task for strengthening future regulation. Recent machine learning-based methods proposed to tackle the tasks are using some blockchain transaction datasets with a small portion of samples labeled positive and the rest unlabelled (PU). Albeit the assumption that a random sample of unlabeled nodes are normal nodes is used in some works, we discuss that the label mechanism assumption for the hidden positive labels and its effect on the evaluation metrics is worth considering. We further explore that PU classifiers dealing with potential hidden positive labels can have improved performance compared to regular machine learning models. We test the PU classifiers with a list of graph representation learning methods for obtaining different feature distributions for the same data to have more reliable results.
Active Keyword Selection to Track Evolving Topics on Twitter
Sep 22, 2022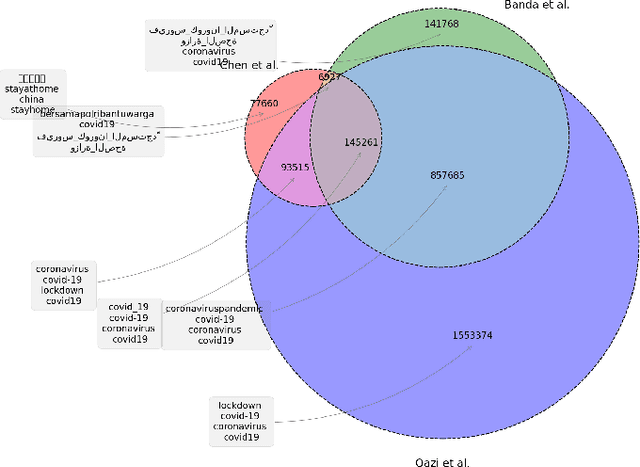
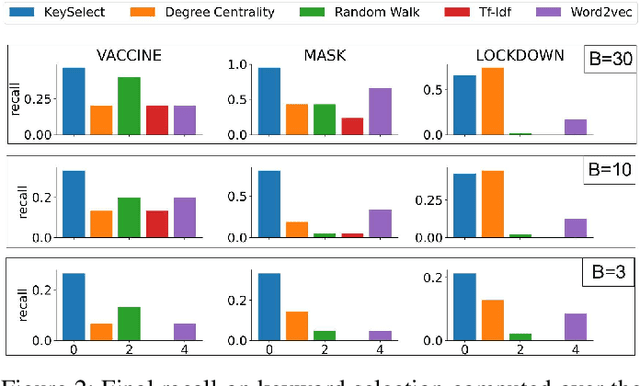
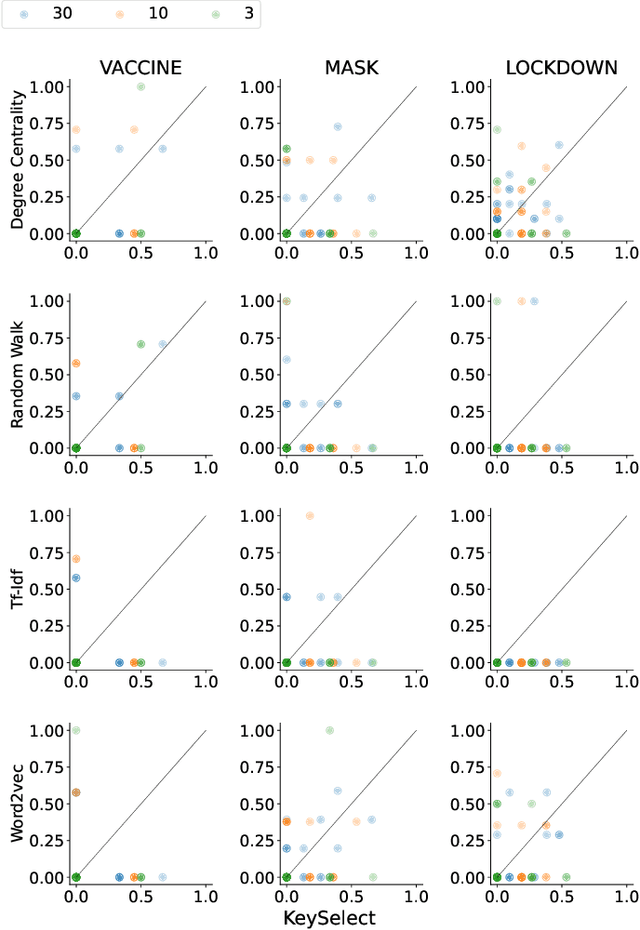
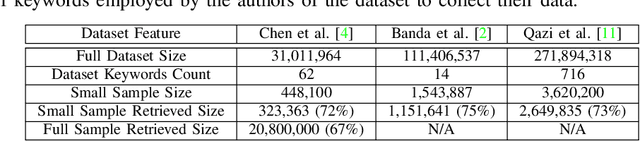
How can we study social interactions on evolving topics at a mass scale? Over the past decade, researchers from diverse fields such as economics, political science, and public health have often done this by querying Twitter's public API endpoints with hand-picked topical keywords to search or stream discussions. However, despite the API's accessibility, it remains difficult to select and update keywords to collect high-quality data relevant to topics of interest. In this paper, we propose an active learning method for rapidly refining query keywords to increase both the yielded topic relevance and dataset size. We leverage a large open-source COVID-19 Twitter dataset to illustrate the applicability of our method in tracking Tweets around the key sub-topics of Vaccine, Mask, and Lockdown. Our experiments show that our method achieves an average topic-related keyword recall 2x higher than baselines. We open-source our code along with a web interface for keyword selection to make data collection from Twitter more systematic for researchers.