 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Visual Object Tracking via Few-Shot Learning
Mar 18, 2021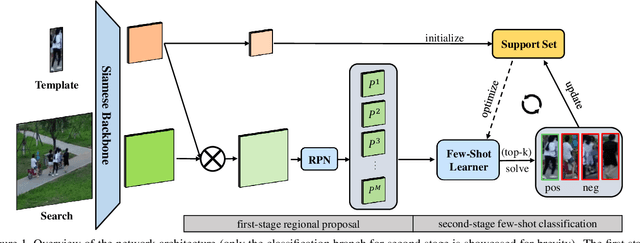
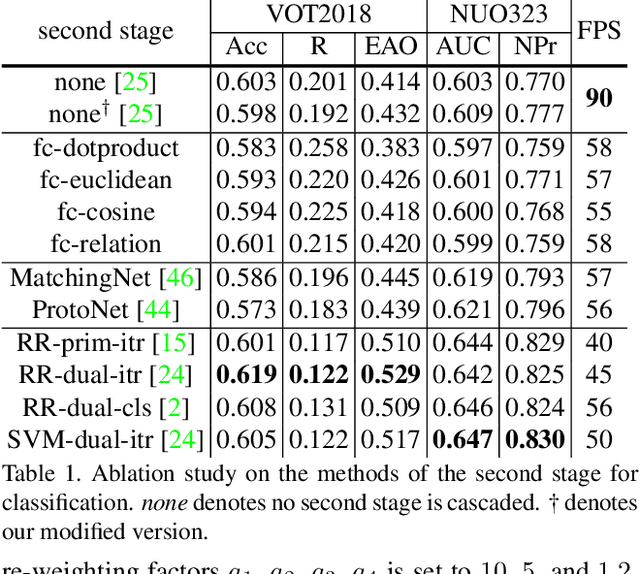
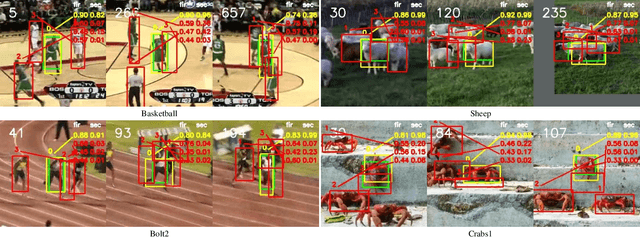

Visual Object Tracking (VOT) can be seen as an extended task of Few-Shot Learning (FSL). While the concept of FSL is not new in tracking and has been previously applied by prior works, most of them are tailored to fit specific types of FSL algorithms and may sacrifice running speed. In this work, we propose a generalized two-stage framework that is capable of employing a large variety of FSL algorithms while presenting faster adaptation speed. The first stage uses a Siamese Regional Proposal Network to efficiently propose the potential candidates and the second stage reformulates the task of classifying these candidates to a few-shot classification problem. Following such a coarse-to-fine pipeline, the first stage proposes informative sparse samples for the second stage, where a large variety of FSL algorithms can be conducted more conveniently and efficiently. As substantiation of the second stage, we systematically investigate several forms of optimization-based few-shot learners from previous works with different objective functions, optimization methods, or solution space. Beyond that, our framework also entails a direct application of the majority of other FSL algorithms to visual tracking, enabling mutual communication between researchers on these two topics. Extensive experiments on the major benchmarks, VOT2018, OTB2015, NFS, UAV123, TrackingNet, and GOT-10k are conducted, demonstrating a desirable performance gain and a real-time speed.
Higher Performance Visual Tracking with Dual-Modal Localization
Mar 18, 2021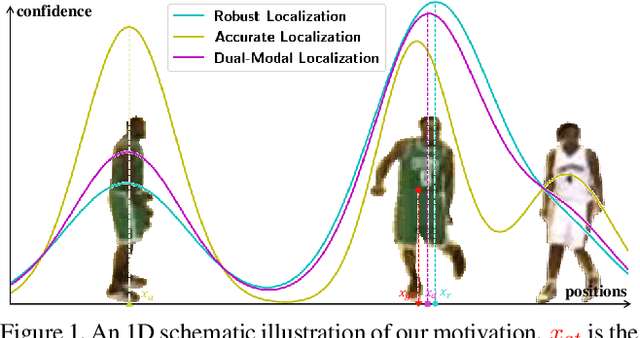

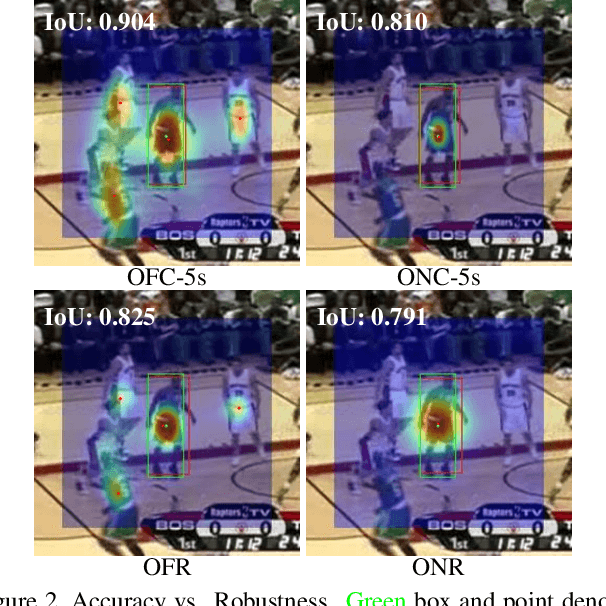
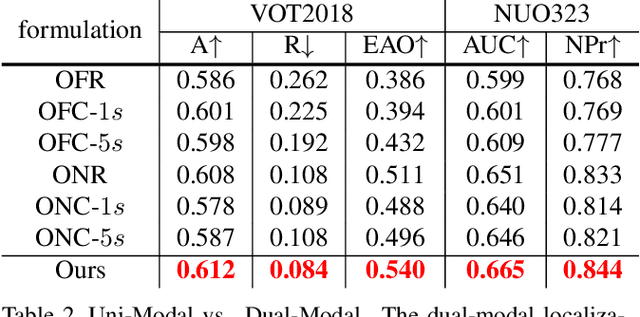
Visual Object Tracking (VOT) has synchronous needs for both robustness and accuracy. While most existing works fail to operate simultaneously on both, we investigate in this work the problem of conflicting performance between accuracy and robustness. We first conduct a systematic comparison among existing methods and analyze their restrictions in terms of accuracy and robustness. Specifically, 4 formulations-offline classification (OFC), offline regression (OFR), online classification (ONC), and online regression (ONR)-are considered, categorized by the existence of online update and the types of supervision signal. To account for the problem, we resort to the idea of ensemble and propose a dual-modal framework for target localization, consisting of robust localization suppressing distractors via ONR and the accurate localization attending to the target center precisely via OFC. To yield a final representation (i.e, bounding box), we propose a simple but effective score voting strategy to involve adjacent predictions such that the final representation does not commit to a single location. Operating beyond the real-time demand, our proposed method is further validated on 8 datasets-VOT2018, VOT2019, OTB2015, NFS, UAV123, LaSOT, TrackingNet, and GOT-10k, achieving state-of-the-art performance.
Learning Statistical Texture for Semantic Segmentation
Mar 06, 2021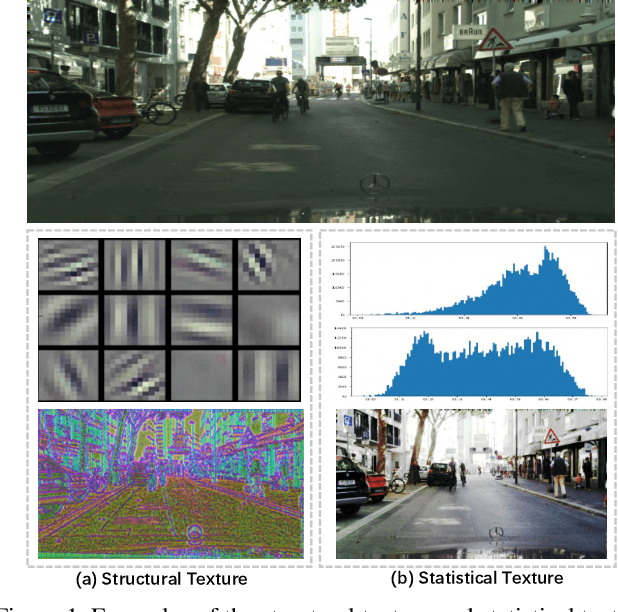
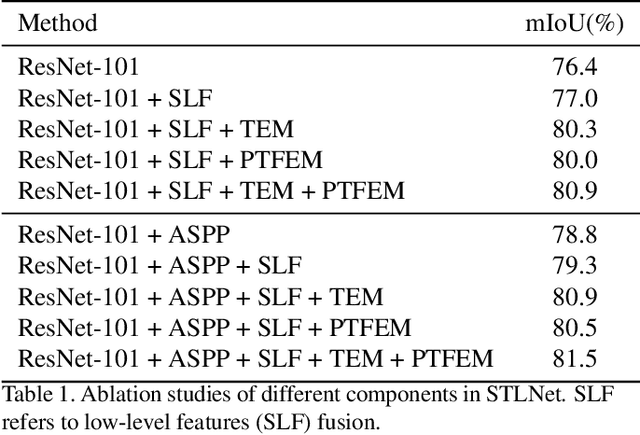
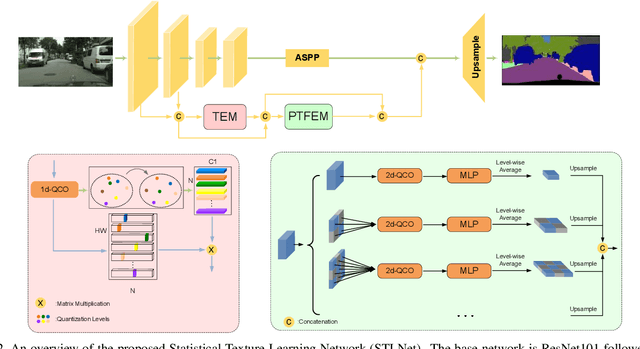

Existing semantic segmentation works mainly focus on learning the contextual information in high-level semantic features with CNNs. In order to maintain a precise boundary, low-level texture features are directly skip-connected into the deeper layers. Nevertheless, texture features are not only about local structure, but also include global statistical knowledge of the input image. In this paper, we fully take advantages of the low-level texture features and propose a novel Statistical Texture Learning Network (STLNet) for semantic segmentation. For the first time, STLNet analyzes the distribution of low level information and efficiently utilizes them for the task. Specifically, a novel Quantization and Counting Operator (QCO) is designed to describe the texture information in a statistical manner. Based on QCO, two modules are introduced: (1) Texture Enhance Module (TEM), to capture texture-related information and enhance the texture details; (2) Pyramid Texture Feature Extraction Module (PTFEM), to effectively extract the statistical texture features from multiple scales. Through extensive experiments, we show that the proposed STLNet achieves state-of-the-art performance on three semantic segmentation benchmarks: Cityscapes, PASCAL Context and ADE20K.
Context-Aware Graph Convolution Network for Target Re-identification
Dec 09, 2020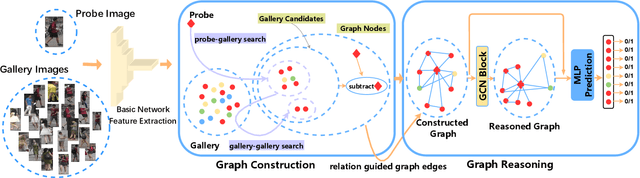
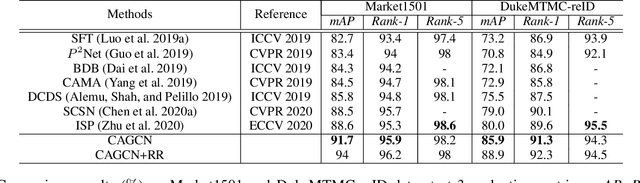

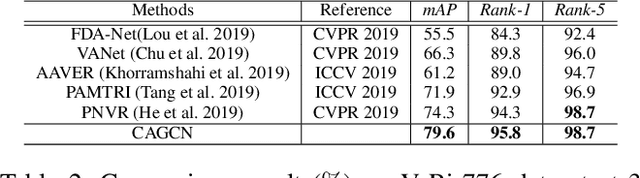
Most existing re-identification methods focus on learning robust and discriminative features with deep convolution networks. However, many of them consider content similarity separately and fail to utilize the context information of the query and gallery sets, e.g. probe-gallery and gallery-gallery relations, thus hard samples may not be well solved due tothe limited or even misleading information. In this paper,we present a novel Context-Aware Graph Convolution Net-work (CAGCN), where the probe-gallery relations are encoded into the graph nodes and the graph edge connections are well controlled by the gallery-gallery relations. In this way, hard samples can be addressed with the context information flows among other easy samples during the graph reasoning. Specifically, we adopt an effective hard gallery sampler to obtain high recall for positive samples while keeping a reasonable graph size, which can also weaken the imbalanced problem in training process with low computation complexity. Experiments show that the proposed method achieves state-of-the-art performance on both person and vehicle re-identification datasets in a plug and play fashion with limited overhead.
SAMOT: Switcher-Aware Multi-Object Tracking and Still Another MOT Measure
Sep 22, 2020
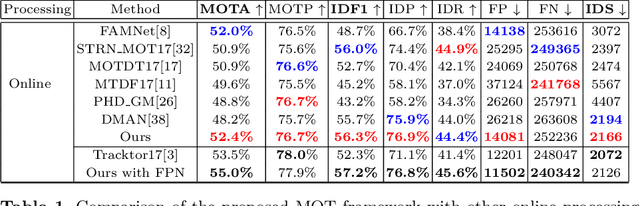
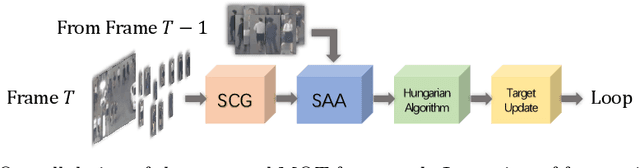
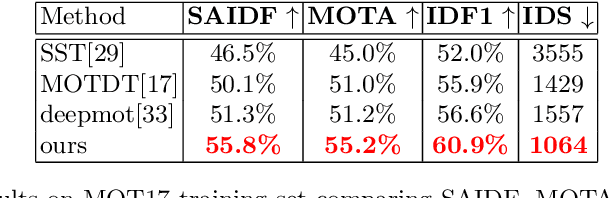
Multi-Object Tracking (MOT) is a popular topic in computer vision. However, identity issue, i.e., an object is wrongly associated with another object of a different identity, still remains to be a challenging problem. To address it, switchers, i.e., confusing targets thatmay cause identity issues, should be focused. Based on this motivation,this paper proposes a novel switcher-aware framework for multi-object tracking, which consists of Spatial Conflict Graph model (SCG) and Switcher-Aware Association (SAA). The SCG eliminates spatial switch-ers within one frame by building a conflict graph and working out the optimal subgraph. The SAA utilizes additional information from potential temporal switcher across frames, enabling more accurate data association. Besides, we propose a new MOT evaluation measure, Still Another IDF score (SAIDF), aiming to focus more on identity issues.This new measure may overcome some problems of the previous measures and provide a better insight for identity issues in MOT. Finally,the proposed framework is tested under both the traditional measures and the new measure we proposed. Extensive experiments show that ourmethod achieves competitive results on all measure.
Collaborative Distillation in the Parameter and Spectrum Domains for Video Action Recognition
Sep 15, 2020
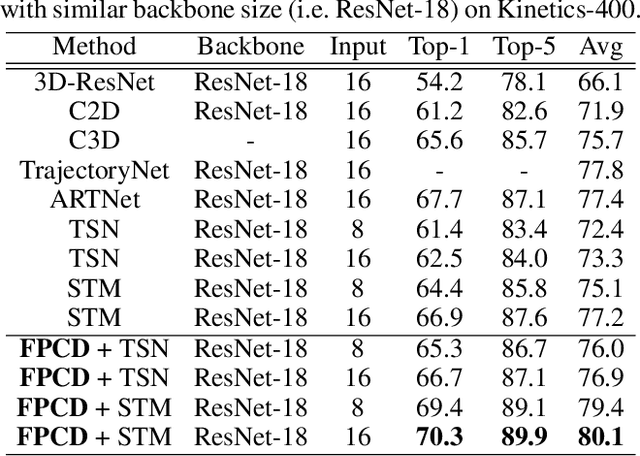
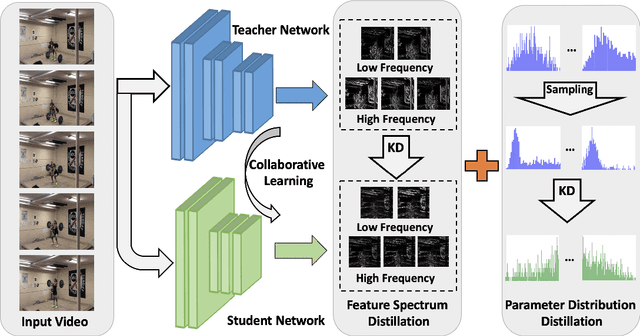
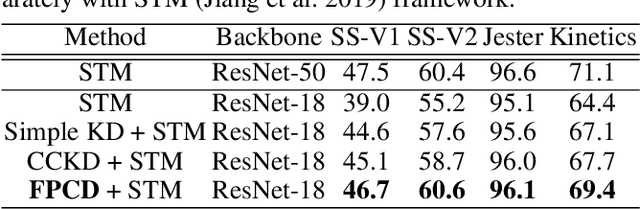
Recent years have witnessed the significant progress of action recognition task with deep networks. However, most of current video networks require large memory and computational resources, which hinders their applications in practice. Existing knowledge distillation methods are limited to the image-level spatial domain, ignoring the temporal and frequency information which provide structural knowledge and are important for video analysis. This paper explores how to train small and efficient networks for action recognition. Specifically, we propose two distillation strategies in the frequency domain, namely the feature spectrum and parameter distribution distillations respectively. Our insight is that appealing performance of action recognition requires \textit{explicitly} modeling the temporal frequency spectrum of video features. Therefore, we introduce a spectrum loss that enforces the student network to mimic the temporal frequency spectrum from the teacher network, instead of \textit{implicitly} distilling features as many previous works. Second, the parameter frequency distribution is further adopted to guide the student network to learn the appearance modeling process from the teacher. Besides, a collaborative learning strategy is presented to optimize the training process from a probabilistic view. Extensive experiments are conducted on several action recognition benchmarks, such as Kinetics, Something-Something, and Jester, which consistently verify effectiveness of our approach, and demonstrate that our method can achieve higher performance than state-of-the-art methods with the same backbone.
BSN++: Complementary Boundary Regressor with Scale-Balanced Relation Modeling for Temporal Action Proposal Generation
Sep 15, 2020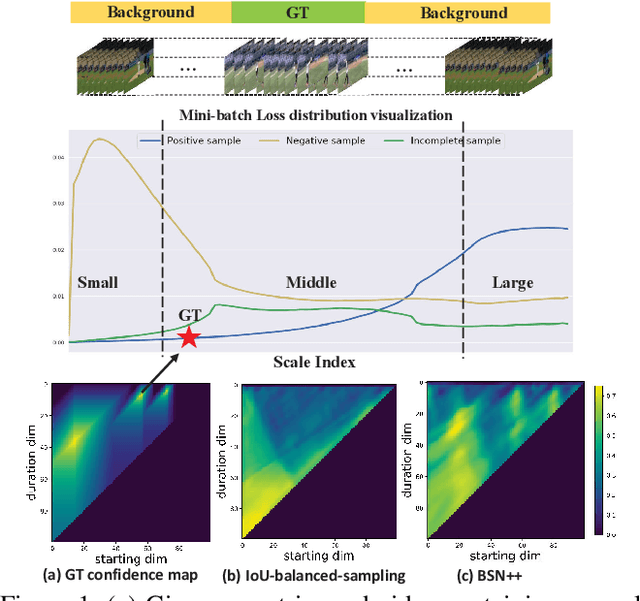

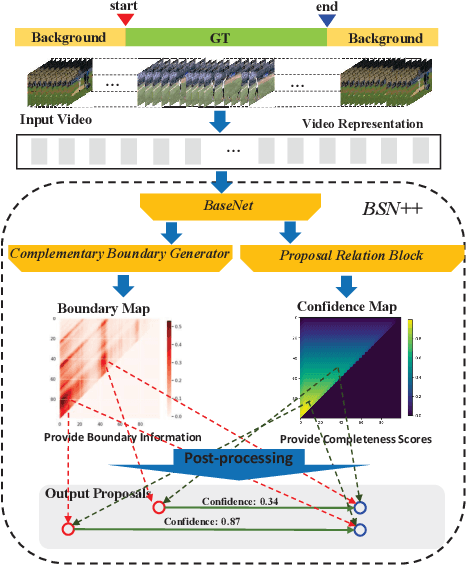
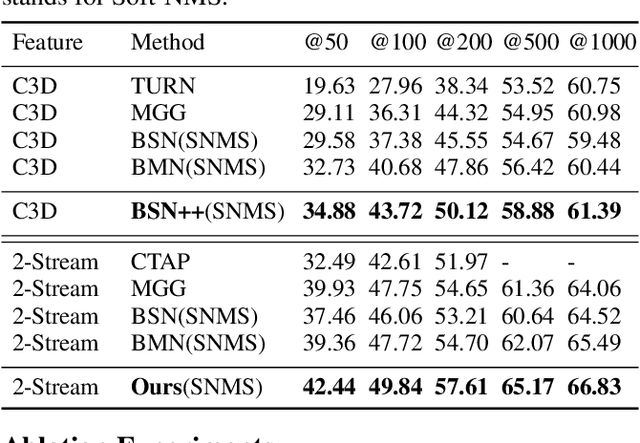
Generating human action proposals in untrimmed videos is an important yet challenging task with wide applications. Current methods often suffer from the noisy boundary locations and the inferior quality of confidence scores used for proposal retrieving. In this paper, we present BSN++, a new framework which exploits complementary boundary regressor and relation modeling for temporal proposal generation. First, we propose a novel boundary regressor based on the complementary characteristics of both starting and ending boundary classifiers. Specifically, we utilize the U-shaped architecture with nested skip connections to capture rich contexts and introduce bi-directional boundary matching mechanism to improve boundary precision. Second, to account for the proposal-proposal relations ignored in previous methods, we devise a proposal relation block to which includes two self-attention modules from the aspects of position and channel. Furthermore, we find that there inevitably exists data imbalanced problems in the positive/negative proposals and temporal durations, which harm the model performance on tail distributions. To relieve this issue, we introduce the scale-balanced re-sampling strategy. Extensive experiments are conducted on two popular benchmarks: ActivityNet-1.3 and THUMOS14, which demonstrate that BSN++ achieves the state-of-the-art performance.
Class-wise Dynamic Graph Convolution for Semantic Segmentation
Jul 19, 2020
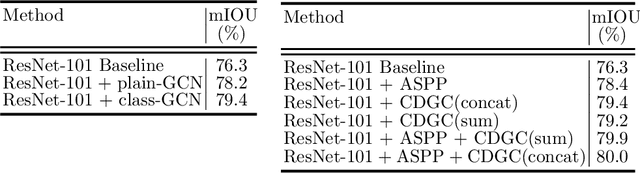
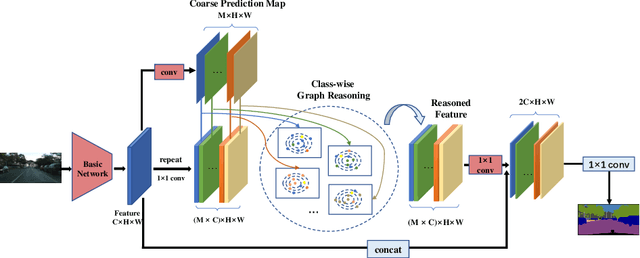
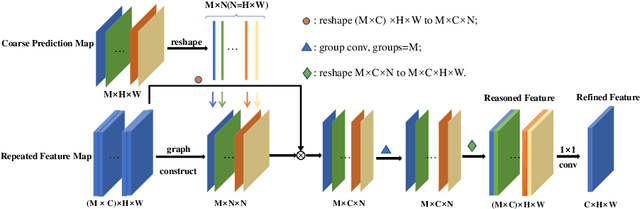
Recent works have made great progress in semantic segmentation by exploiting contextual information in a local or global manner with dilated convolutions, pyramid pooling or self-attention mechanism. In order to avoid potential misleading contextual information aggregation in previous works, we propose a class-wise dynamic graph convolution (CDGC) module to adaptively propagate information. The graph reasoning is performed among pixels in the same class. Based on the proposed CDGC module, we further introduce the Class-wise Dynamic Graph Convolution Network(CDGCNet), which consists of two main parts including the CDGC module and a basic segmentation network, forming a coarse-to-fine paradigm. Specifically, the CDGC module takes the coarse segmentation result as class mask to extract node features for graph construction and performs dynamic graph convolutions on the constructed graph to learn the feature aggregation and weight allocation. Then the refined feature and the original feature are fused to get the final prediction. We conduct extensive experiments on three popular semantic segmentation benchmarks including Cityscapes, PASCAL VOC 2012 and COCO Stuff, and achieve state-of-the-art performance on all three benchmarks.
Hierarchical Feature Embedding for Attribute Recognition
May 23, 2020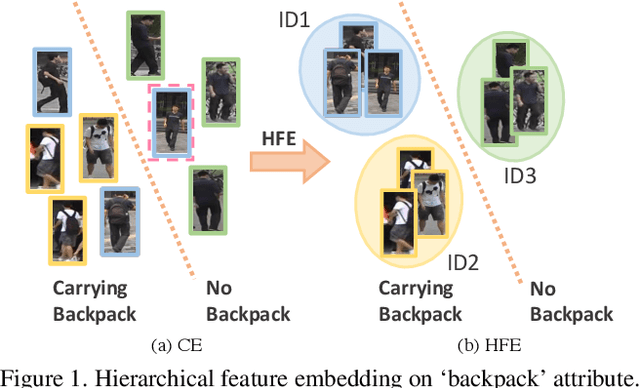

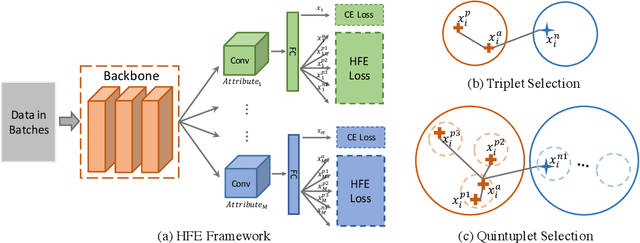
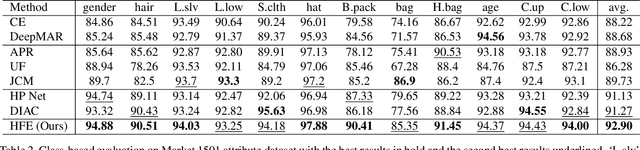
Attribute recognition is a crucial but challenging task due to viewpoint changes, illumination variations and appearance diversities, etc. Most of previous work only consider the attribute-level feature embedding, which might perform poorly in complicated heterogeneous conditions. To address this problem, we propose a hierarchical feature embedding (HFE) framework, which learns a fine-grained feature embedding by combining attribute and ID information. In HFE, we maintain the inter-class and intra-class feature embedding simultaneously. Not only samples with the same attribute but also samples with the same ID are gathered more closely, which could restrict the feature embedding of visually hard samples with regard to attributes and improve the robustness to variant conditions. We establish this hierarchical structure by utilizing HFE loss consisted of attribute-level and ID-level constraints. We also introduce an absolute boundary regularization and a dynamic loss weight as supplementary components to help build up the feature embedding. Experiments show that our method achieves the state-of-the-art results on two pedestrian attribute datasets and a facial attribute dataset.
STM: SpatioTemporal and Motion Encoding for Action Recognition
Aug 16, 2019
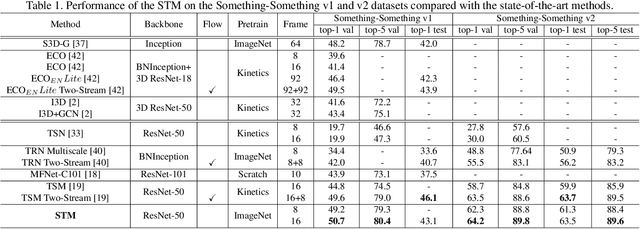
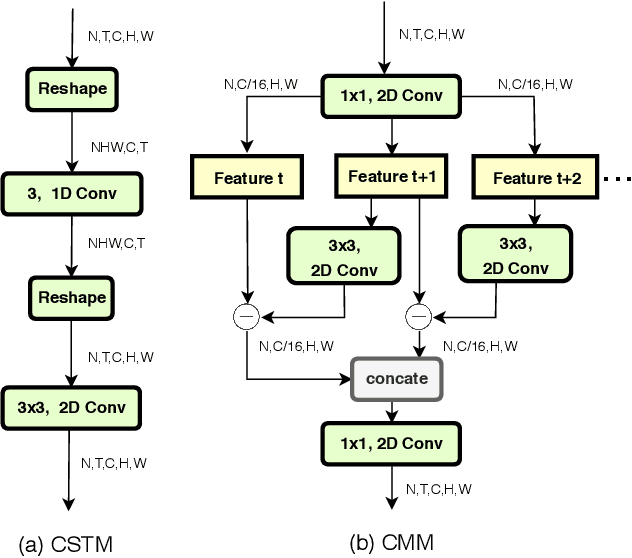
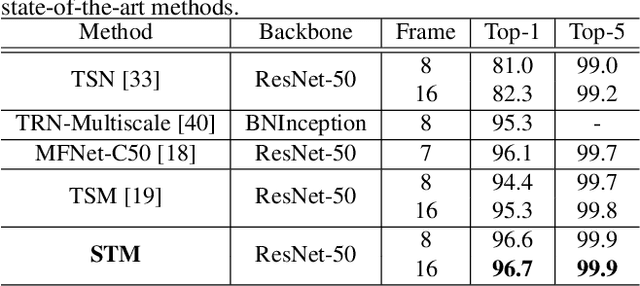
Spatiotemporal and motion features are two complementary and crucial information for video action recognition. Recent state-of-the-art methods adopt a 3D CNN stream to learn spatiotemporal features and another flow stream to learn motion features. In this work, we aim to efficiently encode these two features in a unified 2D framework. To this end, we first propose an STM block, which contains a Channel-wise SpatioTemporal Module (CSTM) to present the spatiotemporal features and a Channel-wise Motion Module (CMM) to efficiently encode motion features. We then replace original residual blocks in the ResNet architecture with STM blcoks to form a simple yet effective STM network by introducing very limited extra computation cost. Extensive experiments demonstrate that the proposed STM network outperforms the state-of-the-art methods on both temporal-related datasets (i.e., Something-Something v1 & v2 and Jester) and scene-related datasets (i.e., Kinetics-400, UCF-101, and HMDB-51) with the help of encoding spatiotemporal and motion features together.